
昨天,阿里云突发大招,强势开源了全新推理模型通义千问 QwQ-32B。在多个关键基准测试上,其以 32B 的参数量,超越了 OpenAI-o1-mini,比肩 671B 参数的满血版 DeepSeek-R1。QwQ-32B 不仅性能哇塞,在保持强劲性能的同时,它还大幅降低了部署使用成本,在消费级显卡上也能实现本地部署,堪称实力与性价比的典范。
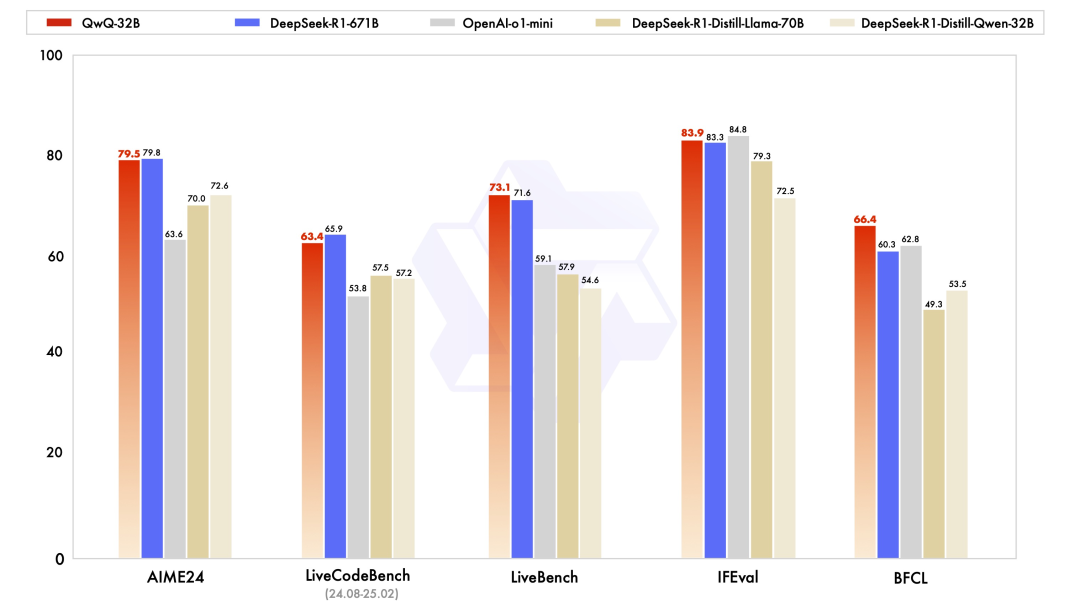
QwQ-32B 在多项基准测试中与 DeepSeek-R1-671B 等推理模型的跑分对比
技术层面,QwQ-32B 在冷启动的基础上采用了两阶段的强化学习法,第一阶段专注于数学和代码任务,借助数学验证器和代码沙盒,着重提升模型的逻辑推理能力。
而第二阶段采用答案验证机制替代传统奖励模型,针对数学问题,依据结果的正确性给予反馈,对于编程任务,则通过测试用例执行服务器实时评估从而提升通用能力。此外,QwQ-32B 还集成了 Agent 相关的功能,使其能够依据环境反馈灵活调整推理过程,显著增强了模型的自主性与适应性。
「使用 vLLM 部署 QwQ-32B」现已上线至 HyperAI超神经官网的「教程」板块,小参数大能量,等你来验证!
教程地址:
https://go.hyper.ai/1YmGY
Demo 运行
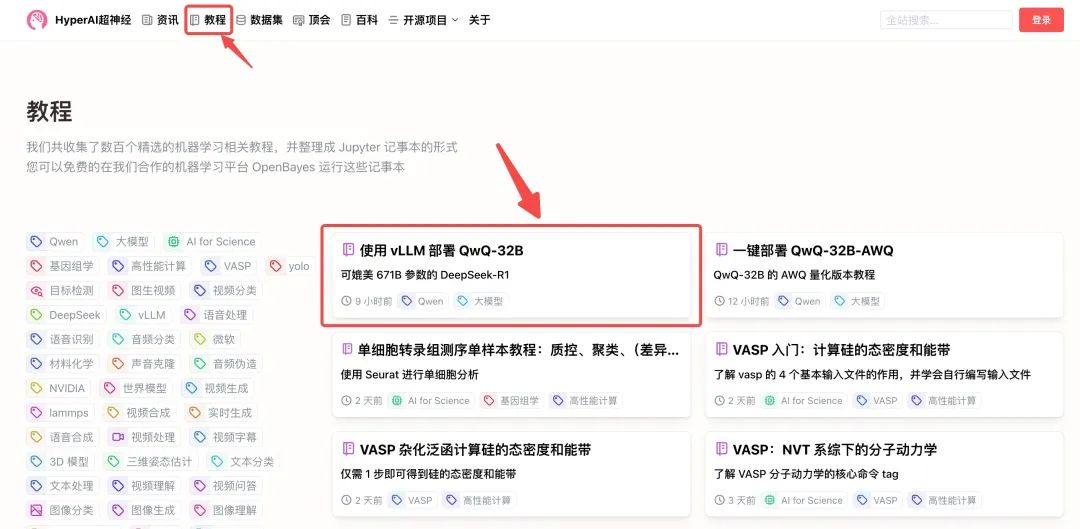
1. 登录 hyper.ai,在「教程」页面,选择「使用 vLLM 部署 QwQ-32B」,点击「在线运行此教程」。
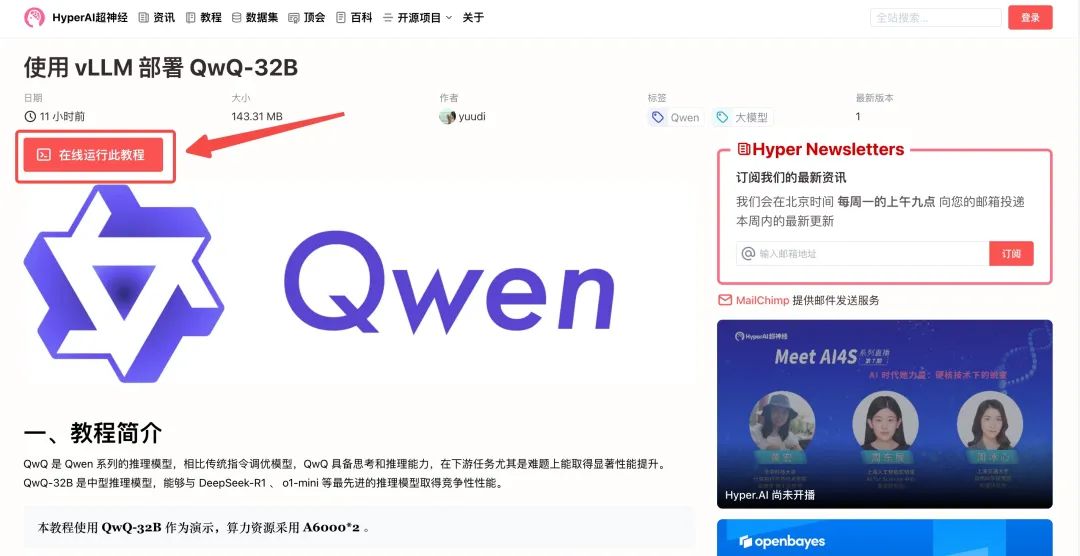
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
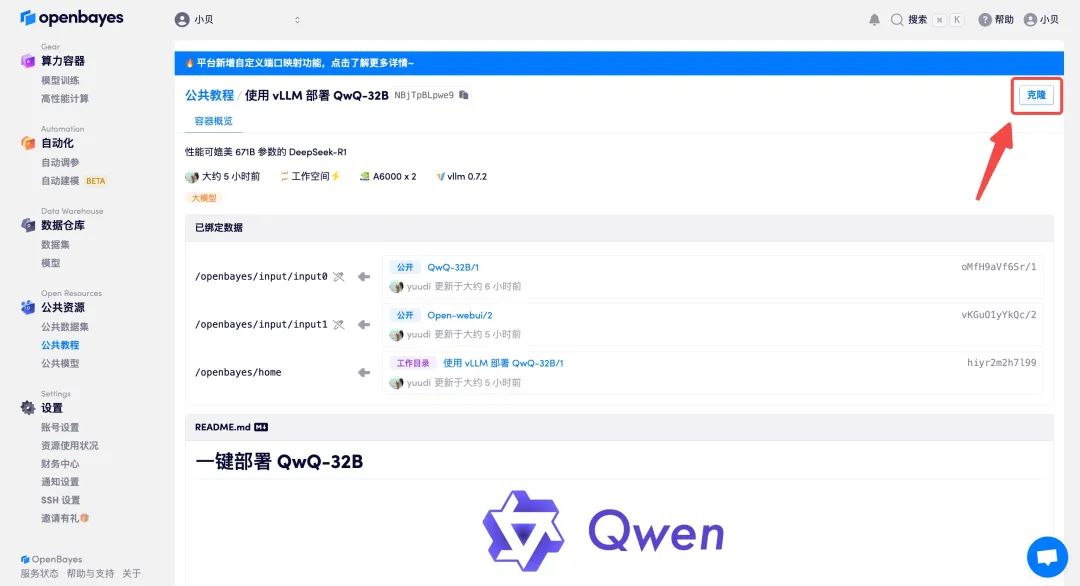
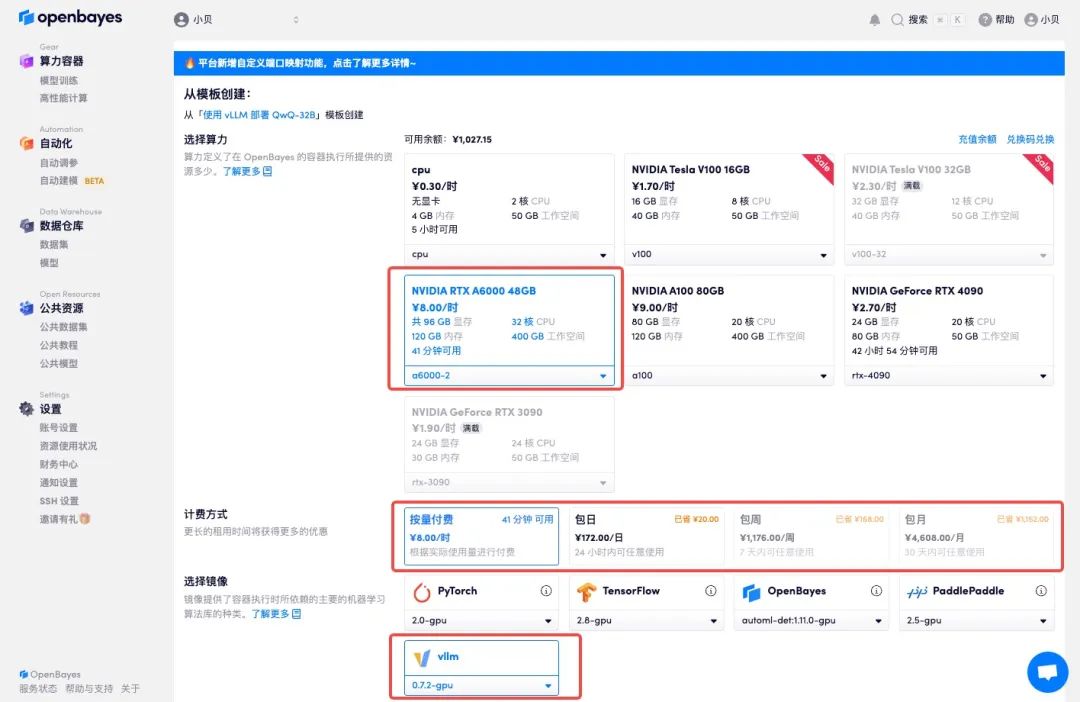
3. 选择「NVIDIA A6000-2」以及「vllm」镜像,OpenBayes 平台上线了新的计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI 超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
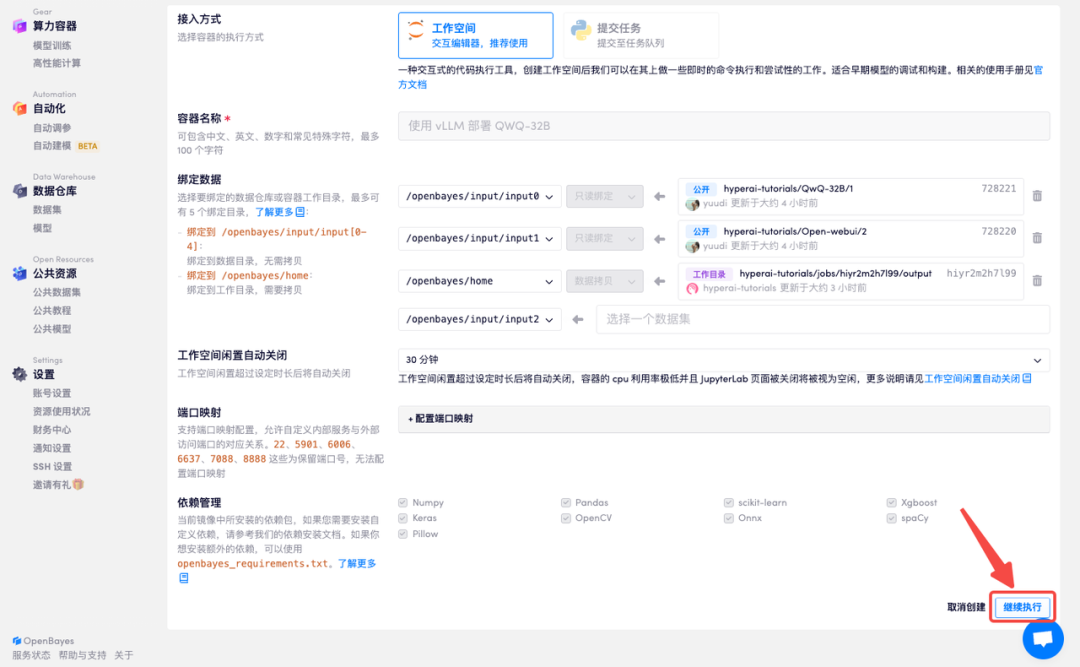
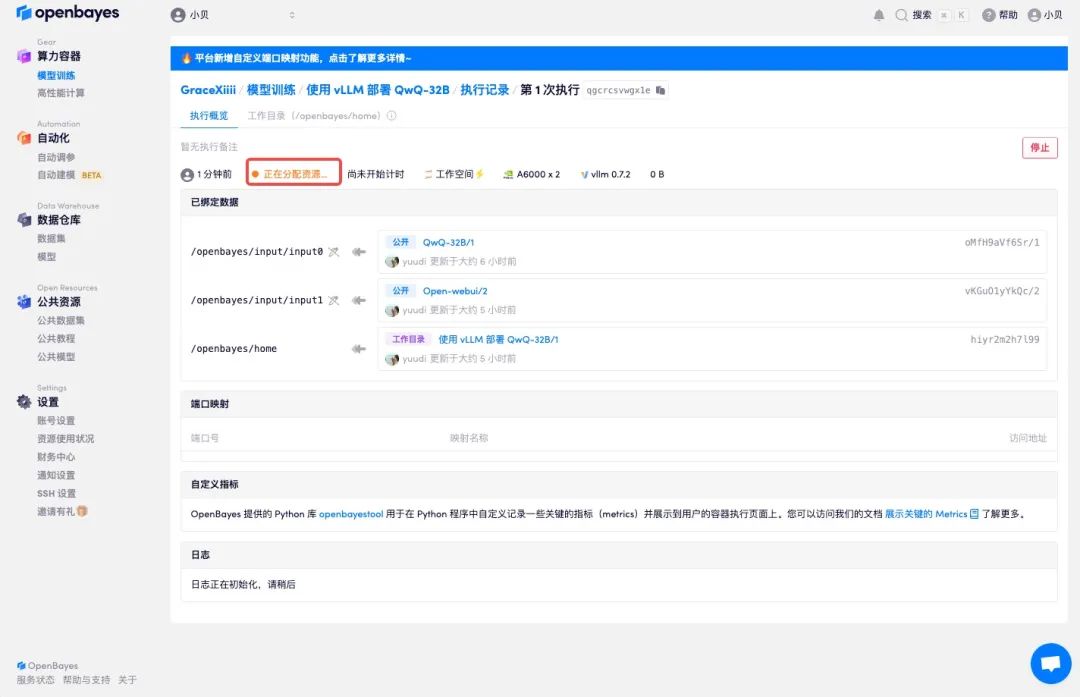
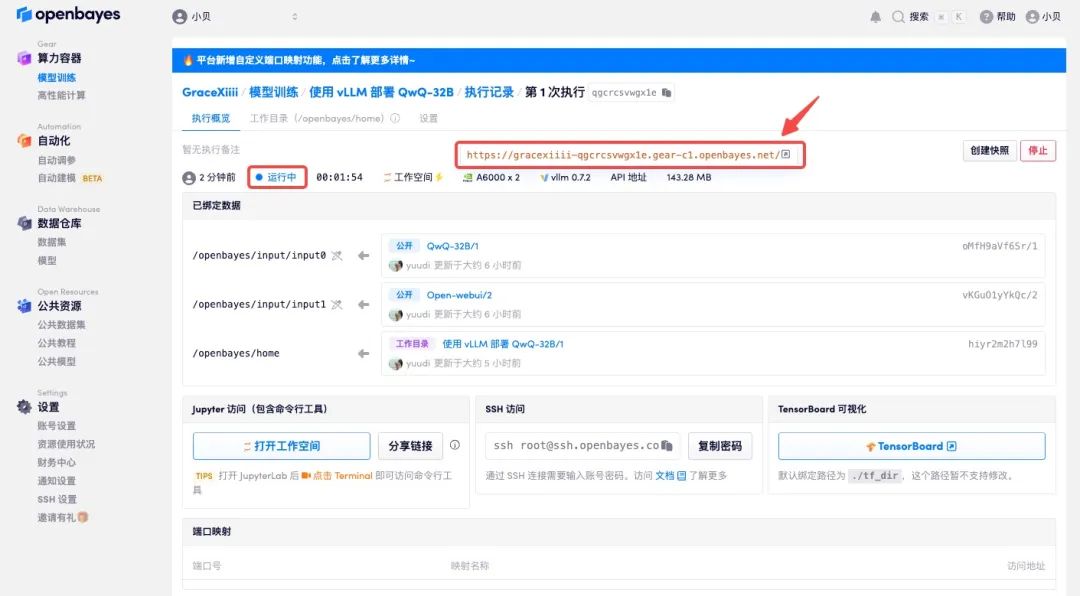
4. 等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果展示
1. 网上关于 QwQ-32B 和 DeepSeek 谁更厉害的话题引发了热议,不如让我们来问问 QwQ-32B 看看它怎么回答。
2. 可以看到 QwQ-32B 会展示完整的思考过程,并且会从多个角度客观给出分析。






戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)