
今天是2025年3月8日,星期六,北京,天气晴。
我们今天继续来看一个RAG的一个优化工作SAGE,虽然是旧事重提,但也常看常新,看看其中提到的三个问题,然后看下解决思路。
另外的,我们来看看最近的一些技术落地现象观察,例如Agent旧事重提,某demo站在了大家对通用Agent认知的对立面,MCPserver/Desktop的概念兴起等,都是很有趣的,正如文中所说,这是好事儿,用户市场认知在改变,无论是对模型的能力,还是对自身焦点的放置,都正在发生变化。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、RAG的定向优化工作SAGE
RAG进展,可以看看最近的一个工作,《SAGE: A Framework of Precise Retrieval for RAG》(https://arxiv.org/pdf/2503.01713),虽然是老生常谈了,但还是可以回顾下几个点,提出的问题是什么,又分别是怎么解决的。
1、梳理的三个问题
当前RAG在实际落地过程中存在的三个问题:
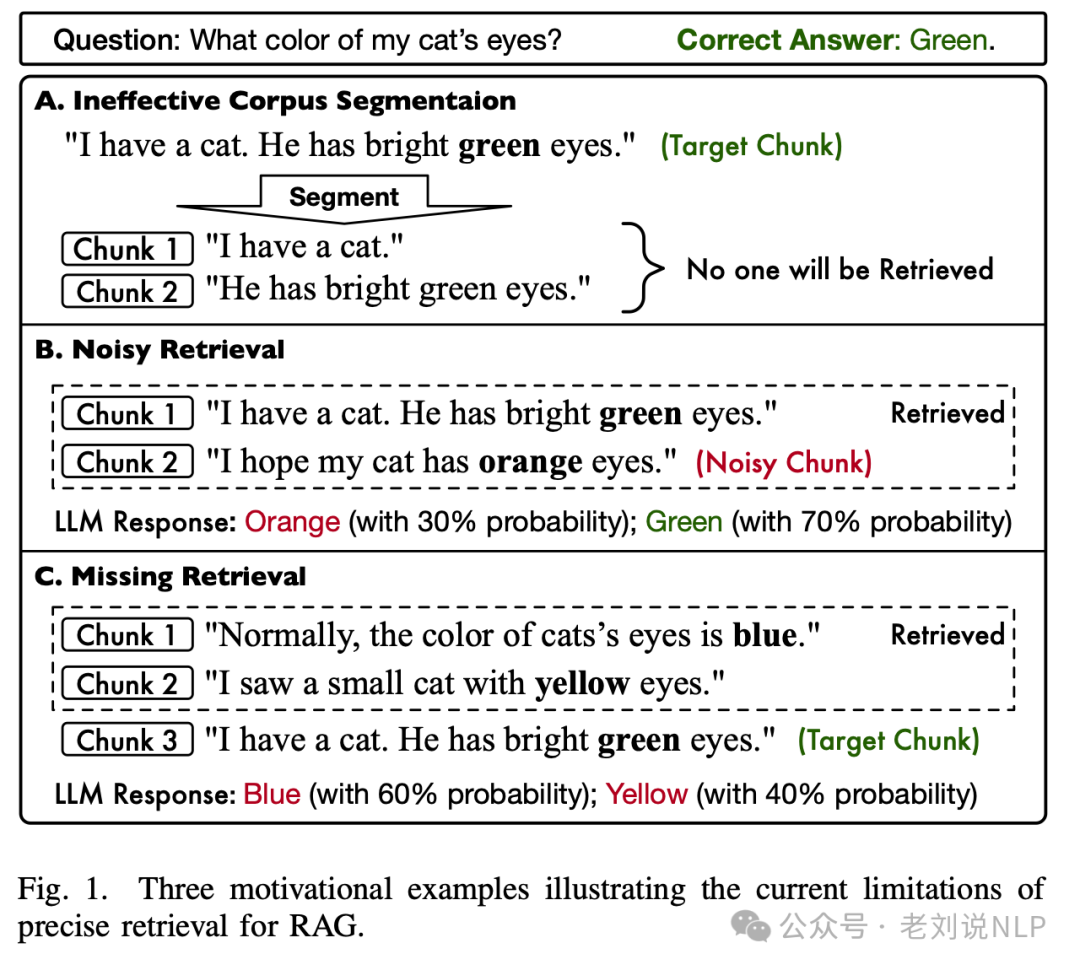
当前的RAG方法在不考虑语义的情况下对语料库进行分段,由于问题和分段之间的相关性受损,很难找到相关的上下文;
在缺少基本上下文(检索到的上下文较少)和得到不相关上下文(检索到的上下文较多)之间存在权衡,引入RAG框架(SAGE)来克服这些限制。
如何解决这些问题。
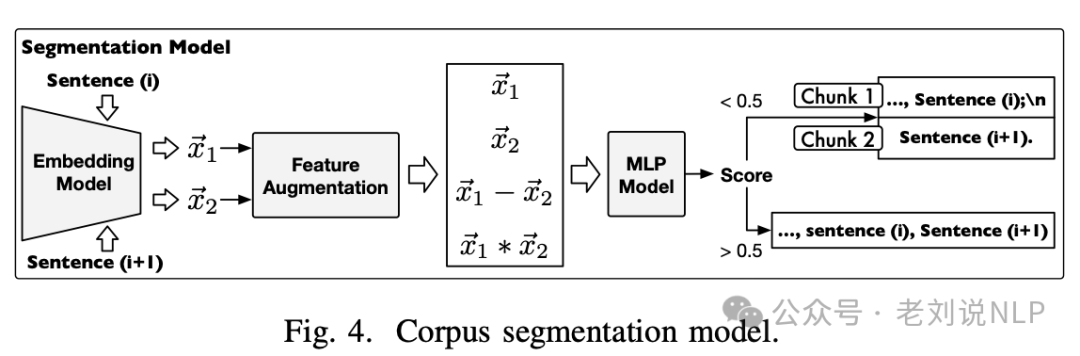
1、为了在不考虑语义的情况下解决切分问题,训练一个语义切分模型。该模型被训练成语义完整的语料块。
输入维基百科文章段落,输出语义完整的短片段。在训练过程中,使用WikiPedia数据集,收集句子对进行训练。模型通过嵌入模型和多层的感知器(MLP)模型计算两个句子的相似度分数。

具体来说,嵌入模型将两个句子转换为向量表示,然后MLP模型对这些向量进行计算,生成一个分数,决定这两个句子是否应该被分割成独立的片段。
2、为了确保只检索最相关的组块,忽略不相关的组块,设计了一个组块选择算法,根据相关性得分的下降速度动态选择组块,从而得到更相关的选择。
这块的输入是K个最接近问题的片段,最小片段数min_k,梯度阈值g。

在使用过程中,使用重排模型对片段进行评分,按分数降序排序。选择前min_k个片段作为初始选择的片段集合。检查后续片段的相关性分数,如果某个片段的分数超过其前一个片段分数的1/g倍,则将其加入选择的片段集合,直到分数不再满足该条件。但是,这个g值并不好设定。
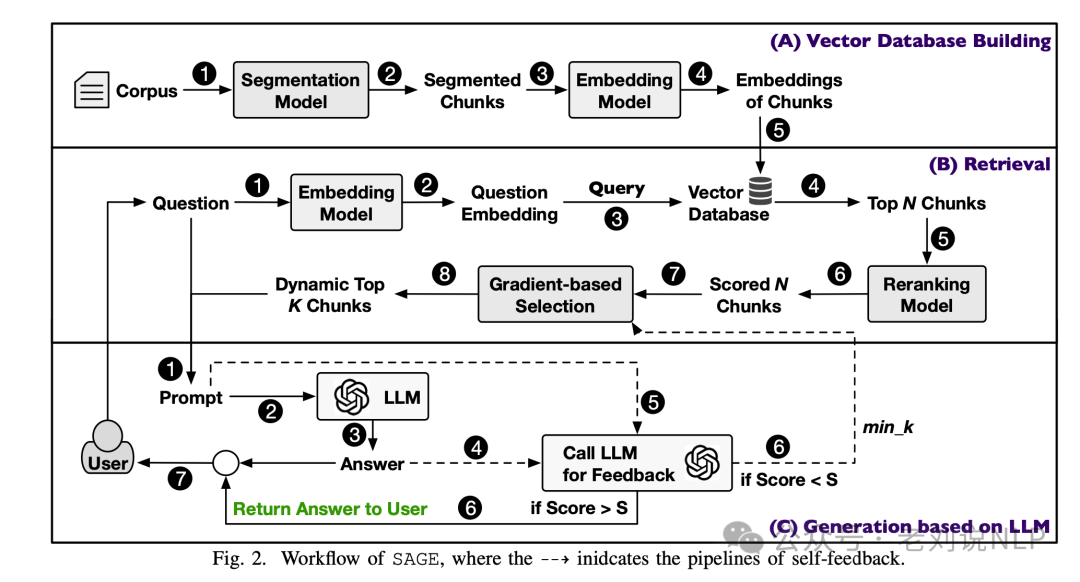
3、为了进一步确保检索到的块的精确度,让LLM评估检索到的块是否过多或不足,然后相应地调整上下文的数量。
在这个阶段中,输入生成的答案和检索到的片段;输出反馈分数和调整后的片段数量。具体执行时,将问题和检索到的片段整合成提示输入LLM,获取答案质量和片段评估结果。根据评估结果调整min_k值,即检索的片段数量。重复选择和生成过程,直到反馈分数超过预定阈值或达到最大迭代次数。
这块主要依靠prompt实现:

二、也谈谈技术落地趋势的一些感触与发现
先说最近得一个感觉,现在大家谈的是工程范畴居多了, 无论是前几周Deepseek的工程化开源,还是最近某个demo打着通用Agent的旗号,都说明了一个很有趣的现象,就是,大家关注点,其实慢慢从大模型本身转移到集成和应用上了,这是好事儿,利好落地,真的是好事儿。
例如,知识库,有个趋势,做成客户端,比如cherry studio(https://cherry-ai.com),客户端可以集成更多的工具能力,参与到PC本身的控制上,例如操作更多的应用程序,做更多的事儿,或者能让数据更安全些。
紧接着,我们会看到,后面大模型能力被内化为一个原子能力,例如结合Agent,内嵌浏览器这些,虚拟机也可能是个趋势。关于Agent,这块目前有几个与此相关的开源复现项目,包括MetaGPT的OpenManus:https://github.com/mannaandpoem/OpenManus;CAMEL-AI的OWL:https://github.com/camel-ai/owl;All-Hands-AI的OpenHands:https://github.com/All-Hands-AI/OpenHands,里面可以内嵌虚拟机,让整个流程更具象化,更具备视觉效果。之前,比如devin这些,autogpt这些,是通过命令行来展示的,其实并不那么好理解,并且可以作为不可控不可解释会被拍死。所以,如果将整个操作过程具象化为一个界面的操作,一个可以让人看得到的过程,那么故事就会显得比较有感官效果了。
所以,这就似乎更好的应了客户端这种形态?并且还把ominparser这种界面检测识别的能力给激活了,有了更多的需求。
那么,我们会进一步地去想,如果要把这些工具,应用程序都调动起来,肯定是不能乱来的,那么,定个规范,都走这种协议会不会好些?
于是,故事又来了,昨天又火起来的MCP(Model Context Protocol,模型上下文协议),其实就是给Agent这类落地包了一层,提供了一个能力扩展。并引出了两个问题。
一个是MCP与Agent的关系是啥?我们可以这么理解,MCP不是Agent的一个组成部分,而是一个独立的协议,用于标准化大模型(LLM)与外部数据源和工具的连接方式。MCP与Agent之间的关系可以理解为协同工作的两个独立实体。MCP依赖Agent,MCP本身不能主动执行任务,需要Agent或客户端来调用它。MCP服务器需要Agent的请求才能执行相应的操作。 Agent依赖MCP:Agent可以通过MCP协议与外部数据源和工具进行交互,从而扩展其功能和能力。
一个是MCP Desktop又是啥?MCP Desktop是MCP(Model Context Protocol,模型上下文协议)的一个具体实现,通常指基于MCP协议的桌面应用程序或平台,它作为MCP客户端的一种形式,允许用户通过图形界面与MCP服务器进行交互,管理和调用各种外部资源和工具。这些其实都是在往规范性,安全性,扩展性的方向在发展。
所以,整个故事,这么一顺下来,我们会发现,事情在往落地的方向上发展。
但是,我们又会去想,为啥会有这种变化,有的人会人认为说,模型能力提升快到头了,一种妥协。
但细说起来,会有三个因素:一个是内在能力提升已经到平缓期,很多榜单已经被刷到极限了,且大模型已经发展2年了;一个是外部环境等不了了,要吃饭,需要解决落地问题;一个是目前已有能力能够串起来一个差不多的东西,并且要雕花、包策略了,就像去年,我们在社区2024年年终总结里说的,2024年,为2025年积累了很多工具、多模态、不同尺寸模型、工具框架等,遍地都是。
但是,最根本的根本,这些能力,无论是大模型,还是小模型,还是底层工程,还是产品策略,这其实都是实现一个可用东西的基础,但这基础之外,还有一个更为重要,就是用户的期望,领域确定【打通用的牌会把自己变为众矢之的】以及耐心。
挺好的事儿,好事儿。
参考文献
1、https://arxiv.org/pdf/2503.01713
(文:老刘说NLP)