

新智元报道
新智元报道
【新智元导读】在CVPR 2025上,谢赛宁发出振聋发聩的批判:如今的AI学术界,已经彻底畸形了!有巨大缺陷的学术激励制度,让所有研究者陷入内卷,精疲力竭。而自己的DiT、SiT等开山论文,也让CVPR评审被狠狠打脸了!
为什么如今的人工智能研究,有可能沦为一场「有限游戏」?
研究人员面临的压力,已经令人精疲力竭,当今的学术激励制度,是否存在着巨大缺陷?
刚刚在CVPR 2025上获得年轻研究者奖的谢赛宁,提出了这些深刻的问题,引起了全场深思。

作为纽约大学计算机科学助理教授,谢赛宁此次获奖可谓实至名归。
而他的演讲「研究作为一种无限游戏」,也成为本届CVPR上的精彩亮点之一。

有趣的是,谢赛宁特意回顾了自己的DiT、SiT两篇论文,分别被CVPR 2023和2024拒收的经历。
虽然当时被拒收,但紧接着,CVPR评审就被狠狠打脸:这两项工作,分别成为了Sora和Stable Diffusion 3的奠基性成果。
谢赛宁参加的这个CVPR社区建设研讨会,主题就是支持早期职业研究人员的成长。
活动现场,各位研究者们都发表了一系列精彩演讲,进行了坦诚的小组讨论。

下面,就让我们仔细看一下谢赛宁的演讲中都说了什么,准备好,思想盛宴开启!


在演讲开场,谢赛宁介绍了这样两种游戏。
其中一种是有限游戏,它有一套明确的规则,目的就是获胜。有人获胜,就意味着其他玩家失败。
而一旦宣布获胜者,游戏就结束了,所有玩家必须停止游戏。
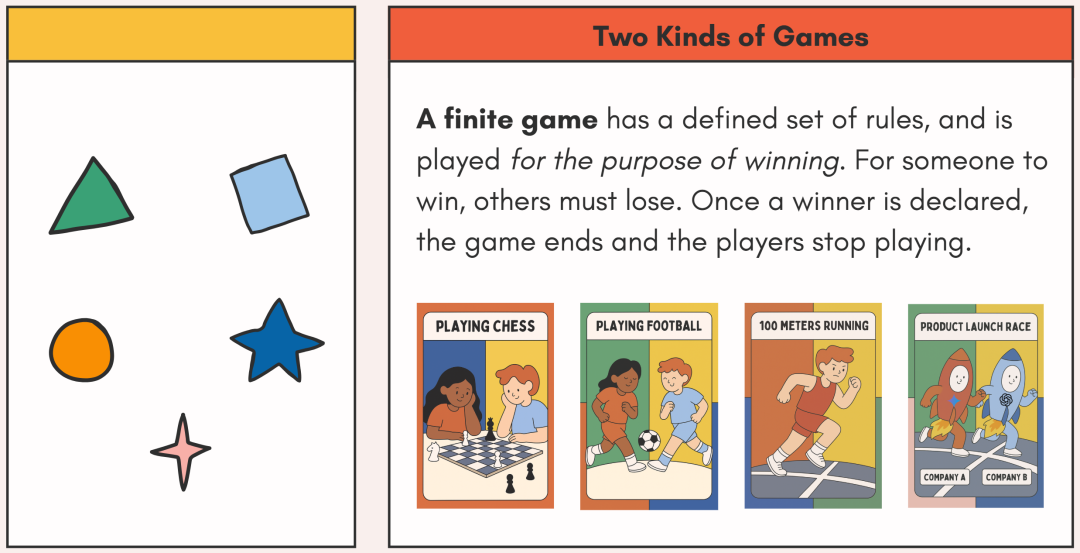
而另一种,就是无限游戏。它的目标不是获胜,而是让所有玩家继续玩下去。
任何规则、界限,甚至是玩家,都可以随着时间推移而变化。唯一的必要条件,就是游戏永不终止。
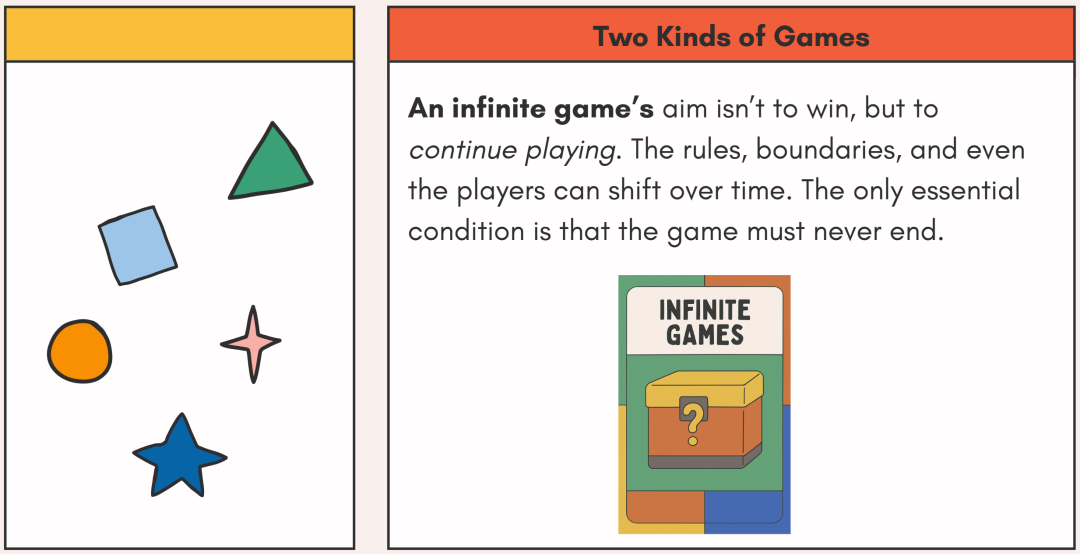
以上概念,是由NYU历史学教授James Carse在自己的书中提出的。

而在本次演讲中,谢赛宁主要谈论了以下四部分的内容。
1. 为何研究理应是一场「无限游戏」?
2. 我,即是我自己的天才
3. AI研究正在陷入「有限游戏」困境?
4. 无人能孤身成局

所谓「无限游戏」,可以从反脆弱性、开放性、持久性和教育这4个方面说起。

A. 反脆弱
「反脆弱性」就是指任何在面对随机事件(或某些冲击)时,上行空间大于下行风险的事物。

无限游戏就是反脆弱性的,研究也是同样。

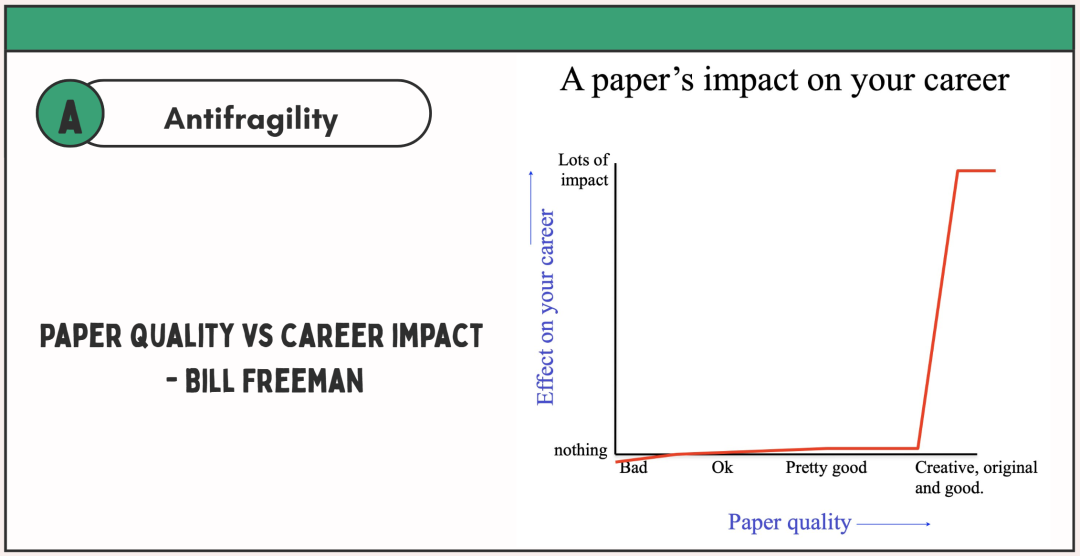
很典型的一个例子,就是一篇论文的影响力,对你职业生涯的影响。
所以,究竟该如何才能找到真正属于自己的研究思路呢?
第一步:追随你的好奇心与热情,让它们为你指引方向;
第二步:大胆探索,在数学推导和动手实验中反复尝试;
第三步:拥抱不期而遇的惊喜,真正的灵感往往源于意外——从混沌中获益!
注意,一定要避开这个陷阱:从第一天起就抱着一个僵化的想法,然后发表一篇固步自封的论文。而这,往往是最为平庸的作品。

B. 开放
经过训练,有限玩家可以预测未来的每一种可能性,以控制未来为目标。但无限玩家则继续游戏,期待着惊喜。
惊喜会导致有限游戏的结束,却是无限游戏得以延续的理由。

在开放的科学中,进步不是来自对知识的守旧,而是来自对知识的分享。只有发现的游戏才能持续,才能不断演化。

可以说,学术界是唯一一个你可以完全自由、开放地探索的空间。
对身处学术界的人来说,请充分利用这份独特的自由——这是一种特权。
而对身处工业界的人来说,学术界可以成为你强有力的盟友,帮你降低风险、开启新的方向。

C. 坚守
有限游戏的参与者,可能会在目标无法实现时选择放弃:「论文没被接收/没拿到资助/产品没上线,所以我失败了。」
而对无限游戏的参与者来说,坚持是一种存在方式:「这是更长远游戏的一部分。我该如何学习、适应,继续前行?」

在这里,谢赛宁就引用了自己DiT论文的典故。
2022年,他和William Peebles一起发表了DiT论文,首次把Transformer和扩散模型结合了起来。
从此,统治扩散模型的U-Net直接被取代。这一论文,成为了奠定他学术地位的开山之作。Diffusion Transformer,也成为了Sora的基础架构之一。

论文地址:https://arxiv.org/abs/2212.09748
然而,就是这样一篇神作,当初却因「缺乏创新性」的理由,直接被CVPR 2023拒了,还一连被多个大公司拒绝。
还有另外一个小插曲:谢赛宁是在deadline截止前三周,才转向这个项目的。

后来,他们重新提交了这篇论文,未经任何修改,就在ICCV 2023上获得了Oral。
而合著者William (Bill) Peebles随后加入了OpenAI,领导了Sora技术团队,让DiT的影响力在全世界无限扩大。


Sora爆火后,谢赛宁针对其技术报告做了解析:Sora应该是基于他和Bill之前在ICCV 2023上提出的以Transformer为主干的扩散模型(DIT)。其中,DIT=[VAE编码器+VIT+DDPM+VAE解码器]
所以谢赛宁告诉我们:有时候,你需要等待;另一些时候,你需要换一种方法,来实现目标。

另外,他和Willis Ma等合著的SiT论文,也因「缺乏创新性」这个理由,被CVPR 2024拒了。

论文地址:https://arxiv.org/abs/2401.08740
在稍加修改后,论文被ECCV 2024接收。

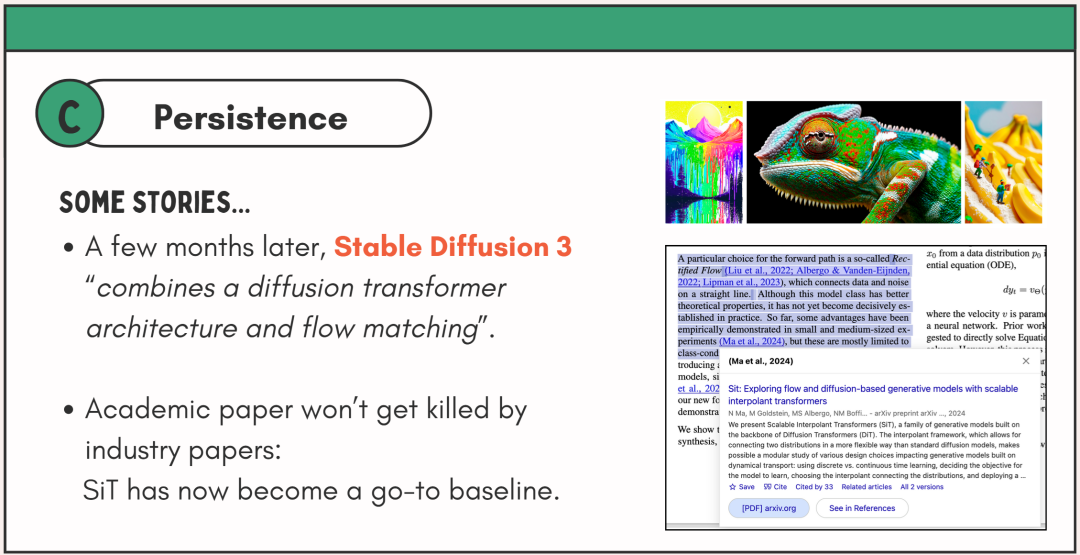
就在几个月后,CVPR评审又被打脸了:Stable Diffusion 3发布,直接表明「结合了DiT架构和流匹配技术」,也就是基于SiT。
而谢赛宁等人的SiT,现在早已成为工业界常用的基准方法。
总之,谢赛宁表示,自己还可以继续讲很多,自己的许多被最多应用的论文,开始并没有得到最有力的评价。
但是坚持不懈,就是无限玩家会做的事!

D. 教育
如果把博士的「培养」视作一个「有限游戏」,会是下面这样。
· 规则目标
发表X篇论文、通过资格考试、完成毕业答辩。
· 参与成员
你自己、你的导师委员会,以及同届的其他博士生。
· 获胜条件
赢得「博士」头衔,收获学术声望。
· 游戏时限
毕业,即是这场游戏的明确终点。

但博士的「教育」,其实是一场「无限游戏」。
· 终身学习之道
博士教育的真谛在于教会你如何学习,如何提出深刻的问题,如何挑战既有假设——这些能力将伴你终身,其价值远超学位本身。
· 炼就自身心智
你将成为一个能安然于模糊混沌,能与盘根错节的复杂性深度共事,并能在失败与迭代中安之若素的人。
· 从汲取到反哺
你完成了从知识的汲取者到知识的创造者的蜕变——并开始为后来者引路。
· 游戏永不终局
即便毕业,你也并未「赢得」科研或教育这场游戏。你将永远身在局中,而你参与的目的,就是为了让这场游戏永远进行下去。

讲到这里,谢赛宁告诉我们:所有人都能够并理应开创自己的赛局。
首先,需要思考一个问题——我们究竟为什么要发表论文?

Hannah Arendt曾在1964年说:「我该为影响力而奔走吗?不,我渴望的是理解。而当他人也达成了与我同样的理解——那一刻,我便获得了一种满足感,一种深刻的归属感。」

而你,我的朋友,要做的就是定义属于自己的玩法!
在无限游戏中要脱颖而出,靠的不是战胜对手,而是成为你自己,并去鼓舞他人!
这也就是我们常说的「讲好一个故事」,以及「研究的品味」。

接下来,谢赛宁提出了一个非常有意思的观点——研究人员就像是时尚设计师。
比如在他看来,何恺明就是最好的设计师之一。
你或许对这些说法不陌生:「一表一核心!」

或者这个:「简洁且有理有据的方法。」

「一步一步地进行消融实验,厘清混淆变量。」
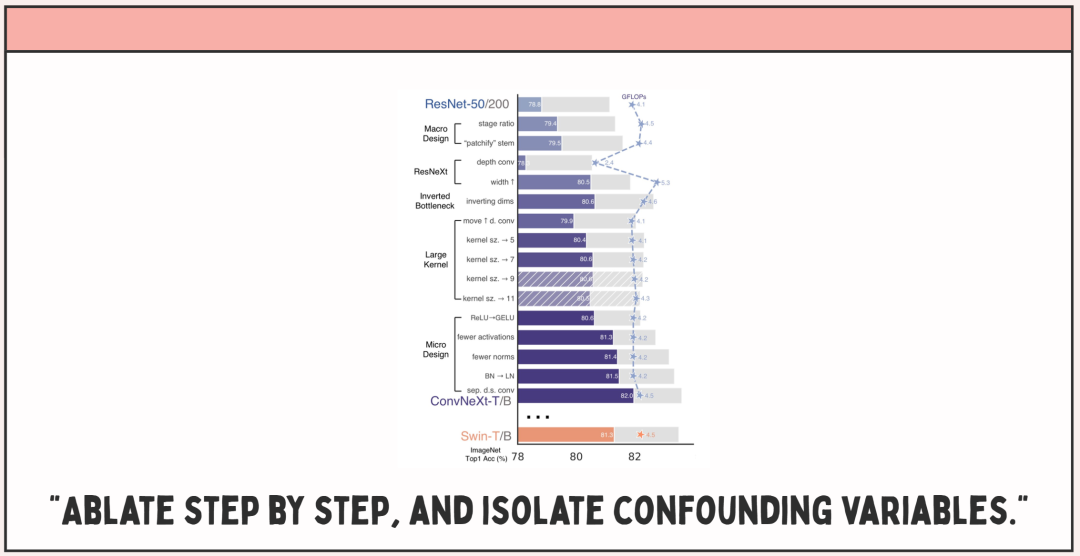
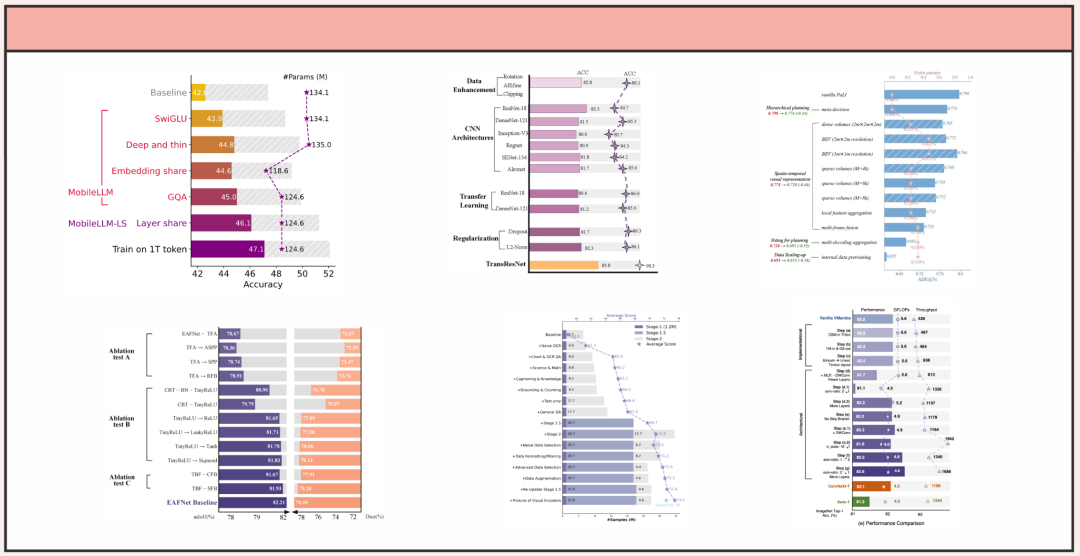
而这些设计,也让谢赛宁等人获得了业界的诸多肯定。
正如谢赛宁一直以来都会为自己的项目打造一个专属的主页。
你也应该为自己的论文、工作、甚至是本人,打造鲜明的品牌。
不要只做一个学术的「缝补匠」。
(指那些沉迷于对现有模型/工作进行微小改进的研究者)

要知道,在如今这个时代,人们早已没有时间去读那么多paper。
因此,怎样做好知识共享,让自己的学术成果得到最大化的传播,就成了一门很重要的学问。

而谢赛宁的模板由于效果十分拔群,在圈子里可谓是相当火爆——有不少研究者都复用在了自己的项目里。

接下来这一部分,谢赛宁提出了很多相当令人担忧的问题。
面对正在陷入「有限游戏」泥沼的AI研究,「无限玩家」必须挺身抗衡。


如今,业界形成的一些研究范式,着实令人担忧。
比如我们经常看到的下面这个局面——
一个关键的「有限玩家」(比如OpenAI)发布了一篇新论文(比如4v, r1, GRPO, o1, 4o…)。
紧接着,一波跟风之作便会随之而来。之后,所有人都会蜂拥而上,争相发表同一主题的论文。
由此,大家陷入了一场唯「快」是图的竞赛。
原因在于,一旦论文率先发表,就能收获更多引用和关注,成为赢家。后来的贡献者,往往就被直接忽视,成为输家。
而一旦某项「开山之作」问世,其他人就会迅速放弃这个课题。

由此,研究人员也被逼得身负重压。
巨大的科研压力,时常压得他们喘不过气来,尤其是学生和青年学者。
所有人都在为争夺有限的认可而拼命内卷,维持着让人身心俱疲、难以为继的节奏。
而现在的学术界,也已经形成了一套颇为畸形的学术激励机制。
比如重视速度,轻视深度和创造力;奖励短期的快速胜利,而不是持久的贡献。
这就十分危险——当学术界也玩起了「有限游戏」,惨败的结局就已经注定!

而破局之道,就是定义新的问题。毕竟,问题是无穷无尽的。
举例来说,谢赛宁和Penghao Wu早在2023年7月就启动了引导视觉搜索作为多模态LLM核心机制的「V*」项目。
当时他们的动机在于,根据人类心理学的相关研究,视觉搜索是一种核心认知机制。
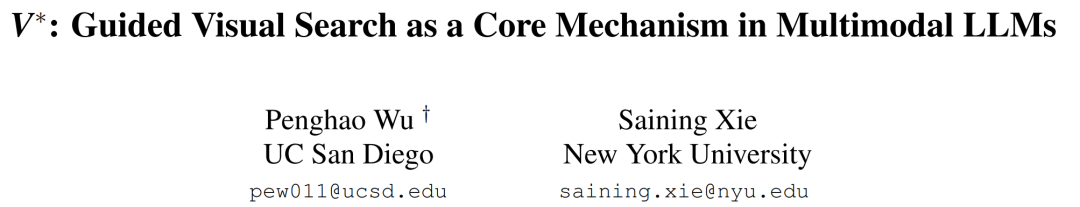
论文地址:https://arxiv.org/abs/2312.14135
在这项研究中,谢赛宁等人将VQA LLM与视觉搜索模型相结合。借助大模型的世界知识,V*会对视觉目标进行多轮引导搜索。接着,它会提取局部特征并将其添加到工作记忆中,最终利用搜索到的数据生成响应。
扩展阅读:
·CV大神谢赛宁新作:V*重磅「视觉搜索」算法让LLM理解力逼近人类

虽然有些人对此表示不解:「这项能力有什么必要吗?它明明会拖慢整个系统。」
但随着新问题的诞生,新的赛局也悄然打响。
时间来到2025年,当OpenAI在发布最新版o3和o4-mini的时候,不仅在模型评测中加入了基于V*的视觉搜索基准,而且还将基于图像的思考能力作为重中之重,直接放在了标题上。
扩展阅读:
· OpenAI震撼发布o3/o4-mini,直逼视觉推理巅峰!首用图像思考,十倍算力爆表
· o3精准破译照片位置,只靠几行Python代码?人类在AI面前已裸奔
· 两张图定位全球,o3碾压T0级高手!人类「诡计」被看穿,跨模态推理爆表
一句话总结就是:「有限游戏」或许能带来财富、地位、权力与认可;但「无限游戏」所提供的,是某种更深刻、也更有意义的回报。
当然,我们并不能指望青年学者从一开始就自然具备这种着眼长远、胸怀利他的格局。
真正的问题在于:我们该如何构建一个正向的反馈闭环,来孕育并守护这种格局?

PPT最后,就到了上价值这趴了。
作为总结,谢赛宁先是通过引述,写出了自己的一些思考和感悟。
「要是搞计算机视觉,你绝对找不到工作。」——某篇博客,2010年
「你应该投身于计算机视觉。CVPR这个社区开放、包容,从不排外。」——一位导师,2013年

正如前文所述,「玩家」从不稀缺,但更多的玩家并不一定意味着「无限游戏」。
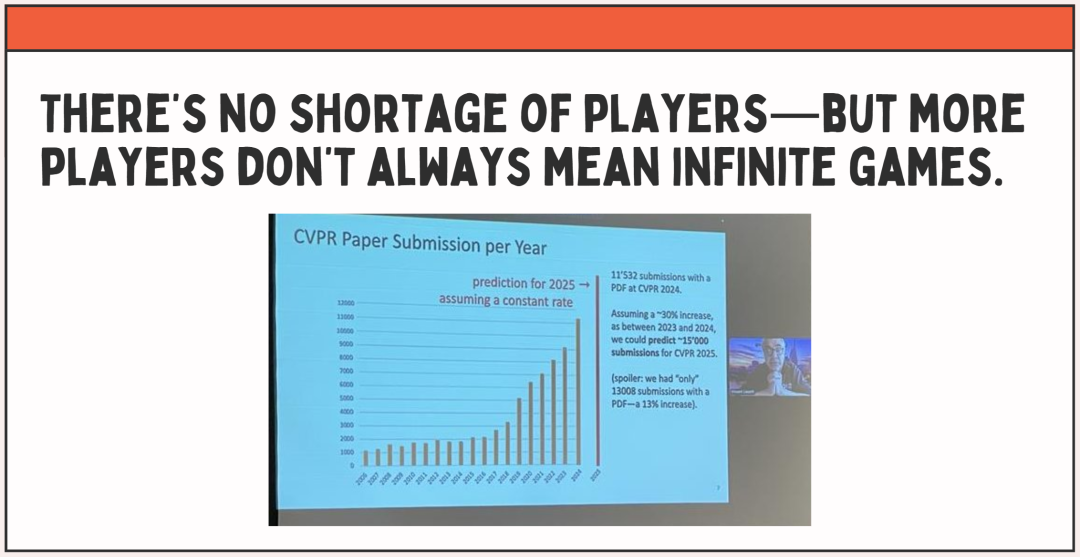
因此谢赛宁呼吁,希望大家能够共同努力让整个科研环境变得更好。
我们切莫将社区的存在视为理所当然——它的强大与包容,你我皆有责任。

最后,致各位无限游戏中的同道者们:尽情享受这场游戏吧,谢谢大家!
(文:新智元)