
 随着机器人技术的不断发展,赋予机器人通用的3D空间理解能力成为实现其在复杂环境中高效操作的关键。上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构联合推出的 SpatialVLA 模型,为这一目标带来了新的突破。SpatialVLA 是一款基于大规模真实机器人数据预训练的视觉–语言–动作(VLA)模型,通过引入 Ego3D 位置编码和自适应动作网格等创新技术,显著提升了机器人的空间理解能力和操作泛化性能。
随着机器人技术的不断发展,赋予机器人通用的3D空间理解能力成为实现其在复杂环境中高效操作的关键。上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构联合推出的 SpatialVLA 模型,为这一目标带来了新的突破。SpatialVLA 是一款基于大规模真实机器人数据预训练的视觉–语言–动作(VLA)模型,通过引入 Ego3D 位置编码和自适应动作网格等创新技术,显著提升了机器人的空间理解能力和操作泛化性能。一、项目概述
在现实世界中,机器人需要在多样化的环境中完成各种任务,如工业制造、物流仓储、服务行业等。然而,传统的机器人操作模型往往依赖于特定任务和环境的定制化设计,缺乏通用性和适应性。为了使机器人能够在未见过的环境中快速适应并执行任务,上海 AI Lab 等机构联合开发了 SpatialVLA 模型。
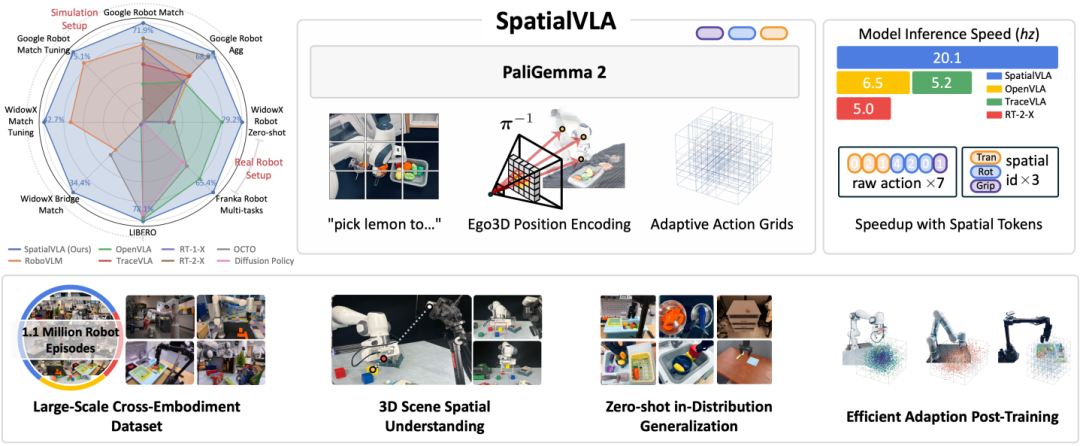
SpatialVLA 的目标是为机器人提供通用的3D空间理解能力,使其能够在多种机器人平台上实现零样本泛化控制,并通过少量微调快速适应新任务和环境。通过大规模真实机器人数据的预训练,模型能够学习到通用的操作策略,从而在复杂环境中实现高效的操作。
二、技术原理
1、Ego3D位置编码
SpatialVLA 通过 Ego3D 位置编码将深度信息与2D语义特征相结合,构建以机器人为中心的3D坐标系。这种编码方式消除了对特定机器人–相机校准的需求,使模型能够感知3D场景结构并适应不同机器人平台。具体来说,模型使用 ZoeDepth 估计深度图,并通过后投影将像素的3D位置与语义特征融合,生成增强的3D空间表示。
2、自适应动作网格
为了将连续的机器人动作离散化,SpatialVLA 引入了自适应动作网格。该技术基于数据分布将动作空间划分为离散的网格,并根据统计动作分布学习空间动作标记。这种离散化方法不仅提高了模型的推理速度,还使得模型能够跨平台泛化动作策略。通过在新环境中重新划分网格,模型可以快速适应新的机器人设置。
3、预训练与微调
SpatialVLA 的训练过程包括预训练和微调两个阶段。在预训练阶段,模型基于 Paligemma2 背骨网络,在包含110万真实机器人演示的跨机器人数据集上进行训练,学习通用的操作策略。在微调阶段,模型可以通过少量数据进行调整,以适应特定的机器人平台或任务。
三、功能特点
1、零样本泛化控制
SpatialVLA 能够在未见过的机器人任务和环境中直接执行操作,无需额外训练。这一特性使得机器人在面对未知场景时能够迅速做出反应并完成任务。
2、高效适应新场景
通过少量数据微调,SpatialVLA 可以快速适应新的机器人平台或任务。这种高效的学习能力大大缩短了机器人部署到新环境的时间成本。
3、强大的空间理解能力
模型具备强大的3D空间理解能力,能够理解复杂的3D空间布局,并执行精准的操作任务,如物体定位、抓取和放置。这使得机器人在复杂环境中操作更加准确和高效。
4、跨机器人平台的通用性
SpatialVLA 支持多种机器人形态和配置,实现通用的操作策略。无论是工业机器人、服务机器人还是其他类型的机器人,都能应用该模型进行操作控制。
5、快速推理与高效动作生成
基于离散化动作空间,SpatialVLA 提高了模型推理速度,适合实时机器人控制。快速的动作生成能力确保了机器人在动态环境中的实时响应。
四、评测结果
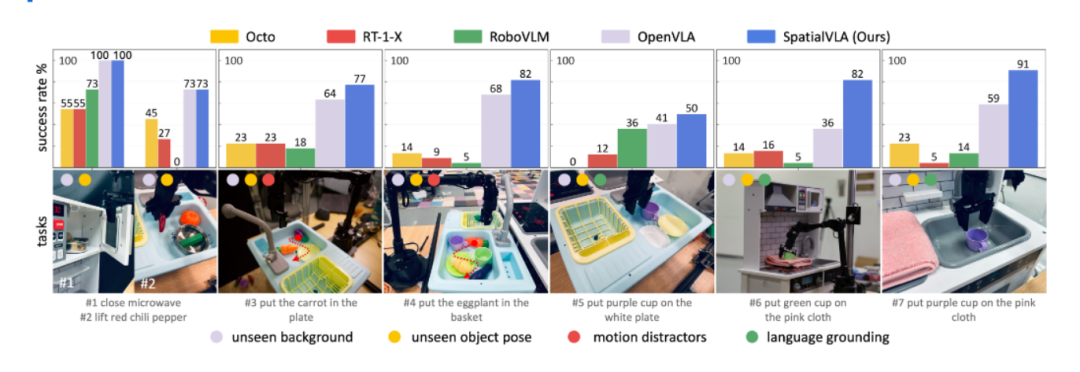
SpatialVLA 在多个评测指标上表现出色。在零样本泛化任务中,模型能够快速适应新环境并完成操作,无需额外训练。在微调后的适应性评测中,使用少量数据即可达到较高的性能水平。空间理解能力评测显示,模型对复杂3D空间布局的解析精准,操作任务执行准确。跨平台通用性评测中,SpatialVLA 在不同机器人平台上均表现出稳定的性能,动作控制流畅自然。快速推理与高效动作生成评测结果表明,模型的推理速度满足实时控制需求,动作生成高效且精准。
五、应用场景
1、工业制造
SpatialVLA 可用于自动化装配和零件搬运,快速适应不同生产线,提高生产效率。在工业制造场景中,机器人需要精确地抓取和放置零部件,SpatialVLA 赋予了机器人这种能力,减少了人工干预。
2、物流仓储
在物流仓储中,SpatialVLA 能够精准抓取和搬运货物,适应动态环境,优化物流效率。面对货物位置的变化和仓储布局的调整,模型能够快速做出适应,确保物流操作的顺畅进行。
3、服务行业
SpatialVLA 支持机器人完成递送、清洁和整理任务,理解自然语言指令,适应复杂环境。在酒店、餐厅等服务场所,机器人可以根据顾客的需求进行物品递送和清洁工作,提升服务质量和效率。
4、医疗辅助
在医疗领域,SpatialVLA 可辅助机器人传递手术器械、搬运药品,确保操作精准和安全。医疗机器人需要高度的精准性和可靠性,该模型为医疗辅助机器人提供了可靠的技术支持。
5、教育与研究
SpatialVLA 为教育和研究提供了有力的工具,支持快速开发和测试新机器人应用,助力学术研究。学生和研究人员可以利用该模型探索机器人技术的前沿领域,推动机器人技术的发展。
六、快速使用
1、模型推理
SpatialVLA 基于 Hugging Face Transformers 构建,因此加载模型非常简单。如果你的环境支持 `transformers >= 4.47.0`,可以直接使用以下代码加载模型并进行推理:
import torchfrom PIL import Imagefrom transformers import AutoModel, AutoProcessor# 模型名称或路径model_name_or_path = "IPEC-COMMUNITY/spatialvla-4b-224-pt"# 加载处理器和模型processor = AutoProcessor.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16).eval().cuda()# 以下是一个简单的使用示例,展示如何利用SpatialVLA 进行物体抓取操作:# 加载图像image = Image.open("example.png").convert("RGB")# 定义任务指令prompt = "What action should the robot take to pick the cup?"# 处理输入并生成动作inputs = processor(images=[image], text=prompt, return_tensors="pt")generation_outputs = model.predict_action(inputs)# 解码动作actions = processor.decode_actions(generation_outputs, unnorm_key="bridge_orig/1.0.0")print(actions)
2、模型微调
如果你需要对 SpatialVLA 模型进行微调以适应特定任务或机器人设置,可以参考以下步骤:
1)克隆官方仓库:
git clone https://github.com/SpatialVLA/SpatialVLA.gitcd SpatialVLA
2)安装依赖:
pip install -r requirements.txt3)使用提供的脚本进行微调:
– 全参数微调:
bash scripts/spatialvla_4b_finetune/finetune_full.sh– LoRA 微调(推荐用于小数据集):
bash scripts/spatialvla_4b_finetune/finetune_lora.sh七、结语
SpatialVLA 作为一款由上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构联合推出的空间具身通用操作模型,凭借其强大的3D空间理解能力和通用操作策略,为机器人领域带来了新的技术突破。通过零样本泛化控制、高效适应新场景、跨平台通用性等优势,SpatialVLA 在工业制造、物流仓储、服务行业、医疗辅助和教育研究等多个领域具有广泛的应用前景。
如果你对 SpatialVLA 感兴趣,想要深入了解或在实际项目中应用该模型,可以访问以下相关资料地址。
项目地址
项目官网:https://spatialvla.github.io
GitHub 仓库:https://github.com/SpatialVLA/SpatialVLA
HuggingFace 模型库:https://huggingface.co/IPEC-COMMUNITY/spatialvla-4b-224-pt
arXiv 技术论文:https://arxiv.org/abs/2501.15830
(文:小兵的AI视界)