DeepSeek R1 通过整合冷启动数据和多阶段训练,使得其能够进行深度思考和复杂推理。一时间国内外许多团队都在尝试复刻,得到媲美甚至超过 DeepSeek R1 的效果。
就在 Manus 爆火的这几天里,有两家国内公司与推理模型相关的开源工作也不容忽视,非常值得说道说道,今天特工们就来介绍一下。
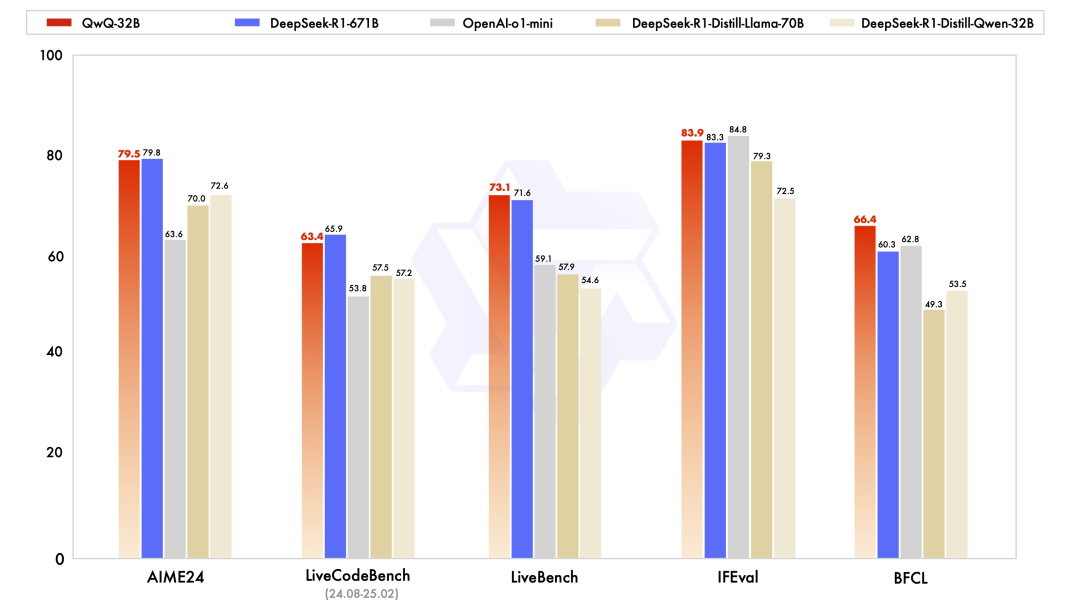
首先是通义团队开源的长推理模型 QwQ-32B,这是一款拥有 320 亿参数的模型,其性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相当。Qwen 团队还配有一篇博客,名称叫“领略强化学习之力”。
Qwen 团队在冷启动的基础上开展了大规模强化学习。与依赖传统的奖励模型不同,其通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。随着训练轮次的推进,在数学和编程领域的性能均表现出持续的提升。
因此,在数学 AIME 2024 评测集和 LiveCodeBench 基准上,QwQ-32B 与 DeepSeek-R1 势均力敌。
虽然表面上热度被 Manus 盖了过去,但其受到海内外开发者的广泛关注和好评如潮。
诚然,QwQ-32B 没有给到太多惊喜,因为 Qwen 之前的开源工作中就已经预告了要推出长推理模型。反倒是 360 让我们感到一些意外。
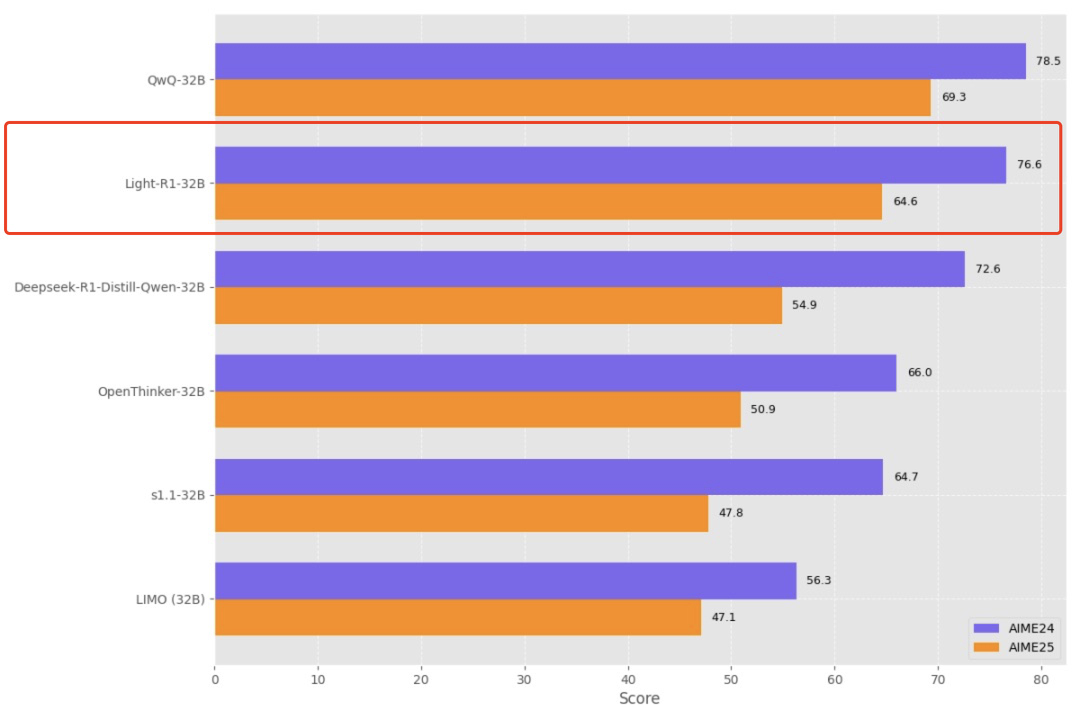
在 Qwen 开源 QwQ 的前两天,360 智脑开源了一个轻量级的长思维链模型 Light-R1-32B,在数学评测领域实现里程碑式突破。
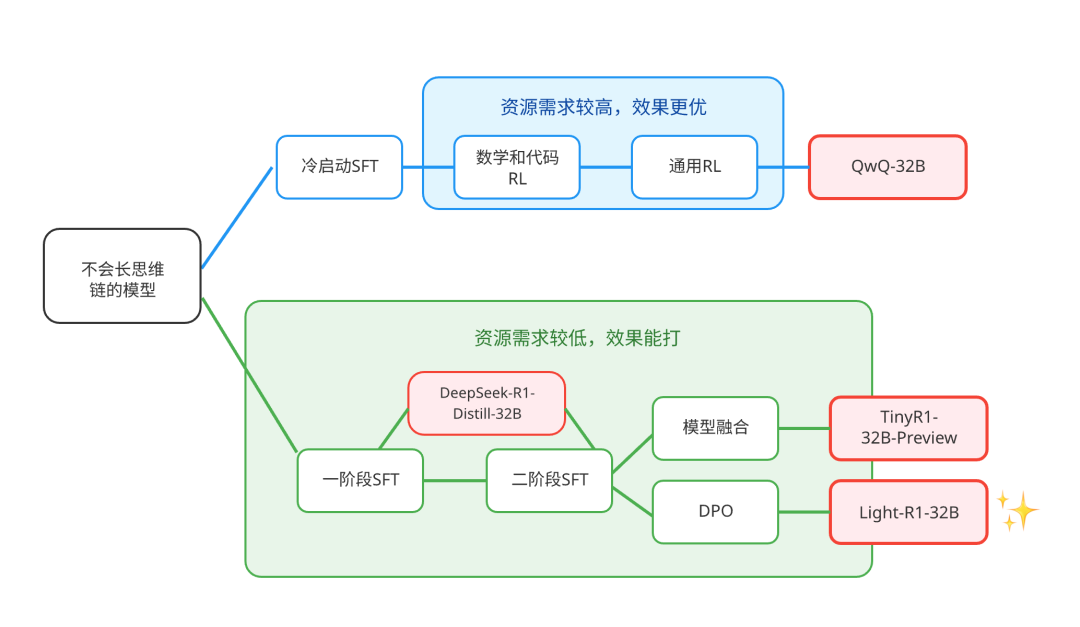
该模型以不会长思维链的 Qwen2.5-32B-Instruct 为起点开始训练,从零复现了长思维链能力。仅通过 7 万条数学数据的两阶段课程学习,通过 SFT 跟老师学,通过 DPO 自我对比学习,在 12 台 H800 GPU 上耗时 6 小时完成训练,成本约 1000 美元。比 QwQ 更早的,首次从零实现了对 DeepSeek-R1-Distill-Qwen-32B 的全面超越。
虽然成绩被后来的 QwQ 追上了,但是仍处于第一梯队,远超上交的 LIMO、李飞飞的 s1.1、斯坦福伯克利等高校的 OpenThinker。此外值得一提的是,Light-R1 直接开源了全套的训练数据、代码和模型,可复现性和可迁移性更强。并且公开全部训练过程中每个阶段的提升,使得优化更透明。
模型仓库:https://huggingface.co/qihoo360/Light-R1-32B
项目地址:https://github.com/Qihoo360/Light-R1
深入了解后发现,360 也一直在做开源贡献。今年 2 月底的时候,360 就已经先和北大联合整了一个 TinyR1-32B-Preview,尝试在用 32B 小模型,去复刻逼近 DeepSeek R1 了。
据悉,Light-R1-32B 和 TinyR1-32B-Preview 都是基于 360 之前开源的长文本训练框架 360-LLaMA-Factory 训练的。得益于开源,又反哺于开源。
BTW,纳米 AI 客户端目前还支持用户上传各种私有模型,比如我们部署一个 ollama 然后按如下配置,就可以在纳米 AI 中测试 Light-R1 了。
之前了解的不够详细,没想到 360 在模型开源和产品开放这一块做的还是挺足的。也同时期待通义、360 等各家国产大模型厂商,后续能够推出更多优秀的开源工作!
(文:特工宇宙)