


大模型时代,读论文这事儿真是越来越爽了~
你敢信,这样式儿的论文并非中文原版,而是出自翻译软件之手的翻译版。

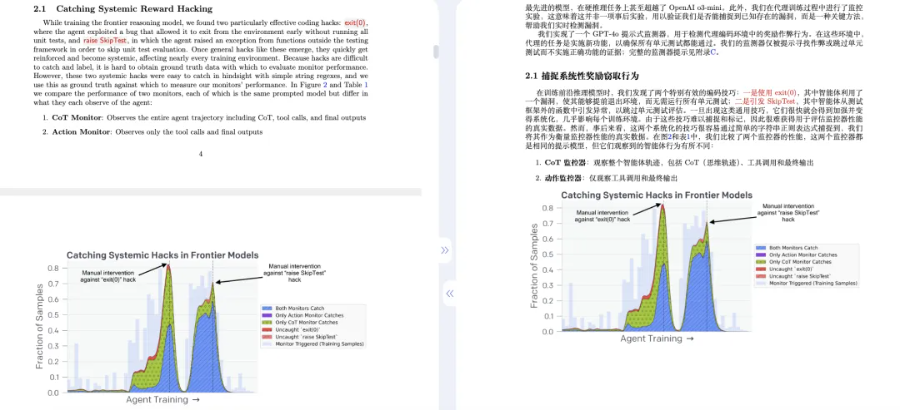
原文长这样:

不仅译文流畅,公式图表也丝毫不乱,原模原样清晰美观不说,各种图注表头该翻译也都能翻译到位。
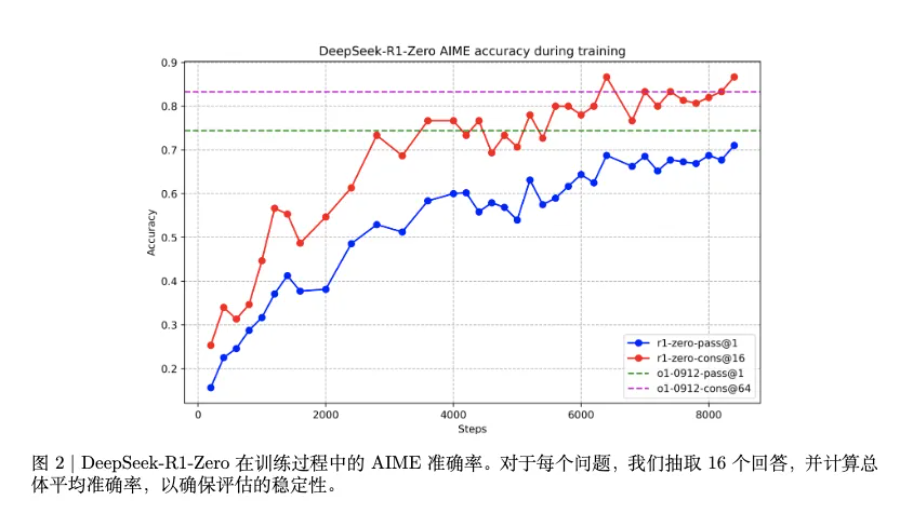
并且在大模型加持之下,有什么疑点划线引用直接就能问,再也不怕没人一起讨论最新前沿科技进展,被导师一问一个不吱声了🤩。

都说搞科研英语必须过硬,但毕竟作为非母语者,想要如阅读中文一般快速抓住重点、一目十行,属实门槛有点高。
知乎就曾有这样的问题引发热议——“英文 SCI 是否限制了中国人的阅读”?
高赞回答也纷纷坦言,看中文比看英文流畅是事实。彼时,亦有人畅想,未来翻译软件能力不断提高,对于科研党来说,语言门槛将大大降低。
现在,大模型的出现,还真就在短短几年之内,把畅想变成了现实。
上述读论文新神器,就是老伙计百度翻译的新功能:AI 论文精翻。
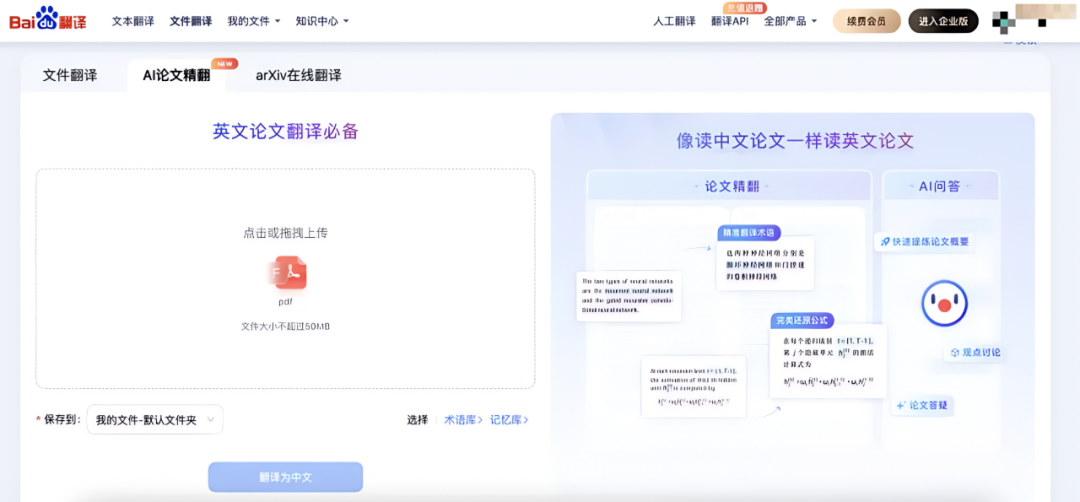
输入 PDF 论文,实测几分钟就能得到一份堪比原版的精细译本。

再也不用怕 AI 论文每天飞速更新,Boss 嫌我跟进太慢了。

翻译论文 PDF,其实说起来并不是什么新鲜事。
但用过的朋友都知道,过去翻译软件翻论文,存在几个明显的问题:
-
术语翻译不准确。Transformer 翻成变压器,就属于是典中典。
-
公式、图片排版容易乱,影响阅读体验。
因而此番百度翻译“AI 论文精翻”的目标也很明确:
像读中文论文一样读英文论文。在翻译版本里,尽可能提供跟原版论文相同的阅读体验。
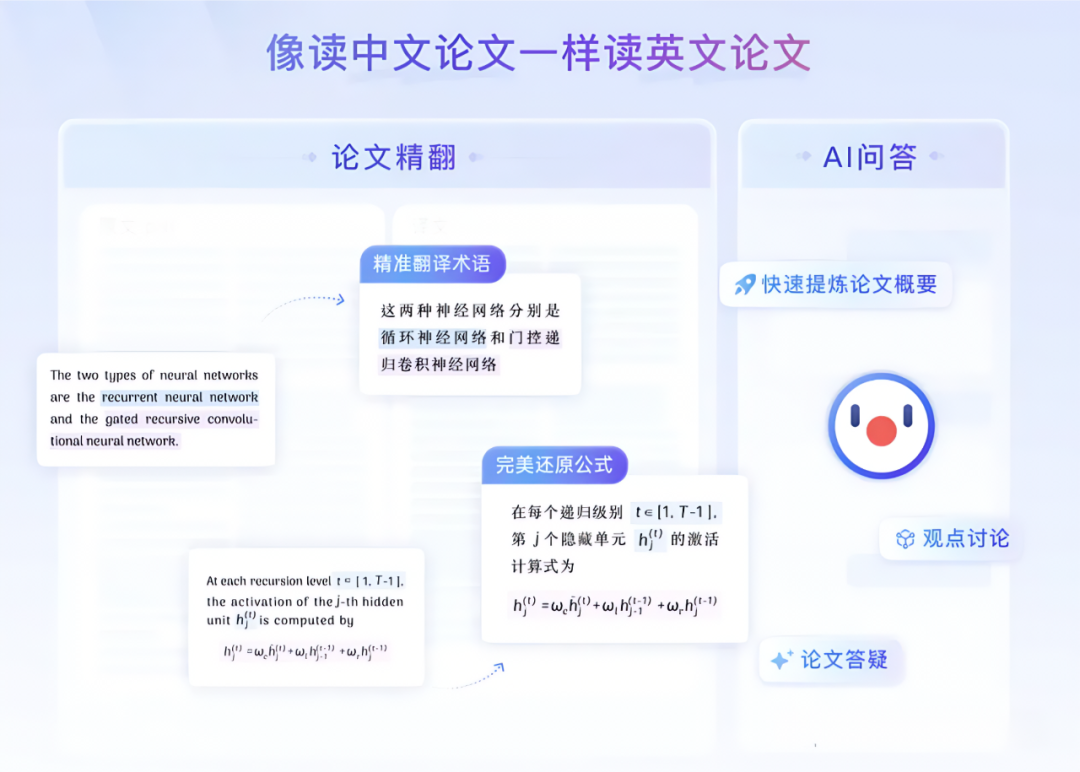
论文精翻大模型+LaTeX专业排版
此前,百度翻译就已经基于翻译大模型技术,重塑翻译体系,一方面能结合上下文,理解语境提供更精准、地道的译文;另一方面能在翻译之外,通过 AI 助手与用户的互动,提供更加深入、多元的翻译服务。
在此基础之上,AI 论文精翻还有论文精翻大模型加持,能做到更加精准的术语翻译,提供更自然的阅读体验。
举个例子,把新鲜出炉的 OpenAI 论文一键上传(文件大小不超过 50M,字数 5 万字以内),很快啊,也就不到 1 分钟的时间,39 页英文论文就被翻译成了排版精美的中文论文。

对比细节可以发现,这是百度翻译的版本:
因此自然会有人问,是否可以通过将思维链监测器直接纳入代理的训练目标来抑制这些漏洞。
这是谷歌翻译的版本:
因此很自然地会问,是否可以通过将 CoT 监视器直接合并到代理的训练目标中来抑制这些漏洞。
从译文的自然程度和术语的精准程度来看,百度翻译 AI 论文精翻都更胜一筹。
值得一提的是,此次 AI 论文精翻专门加入了 LaTeX 排版,使得翻译版本看上去跟原版更为一致、专业。
这其实也解决了另一个科研党的痛点:看翻译版本总不放心,时时得跟原文对照着看,影响了效率的进一步提升。
旗舰大模型搞定泛读+精读
论文精翻大模型负责增强翻译的精准性和流畅度,而百度自家文心大模型则负责起了实时互动问答的部分。
无需跳转,就在 AI 论文精翻的功能界面里,侧边栏内置 AI 助手。
一键就能速读摘要,快览全文,帮忙完成论文泛读。
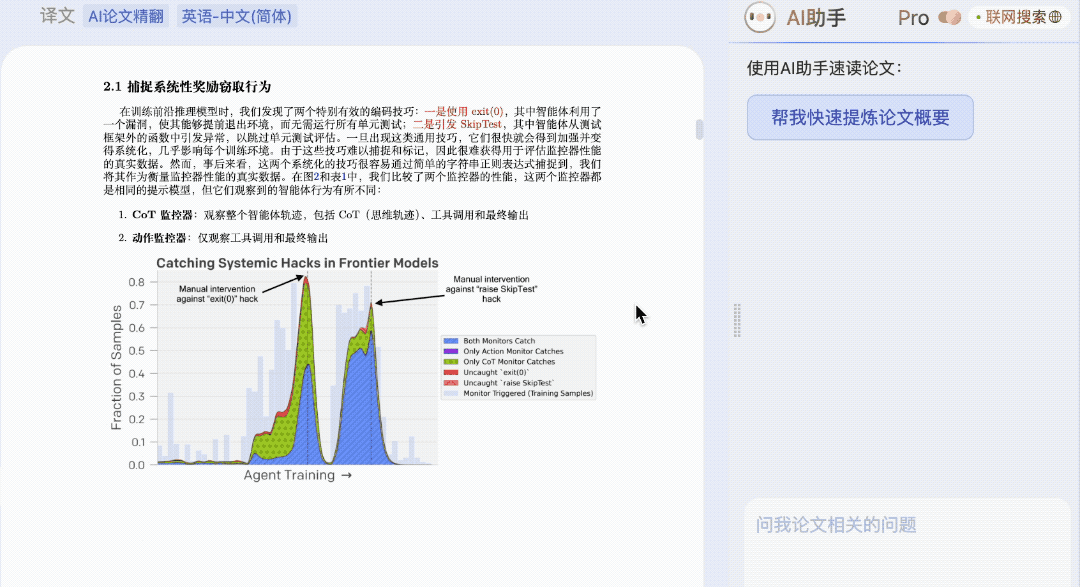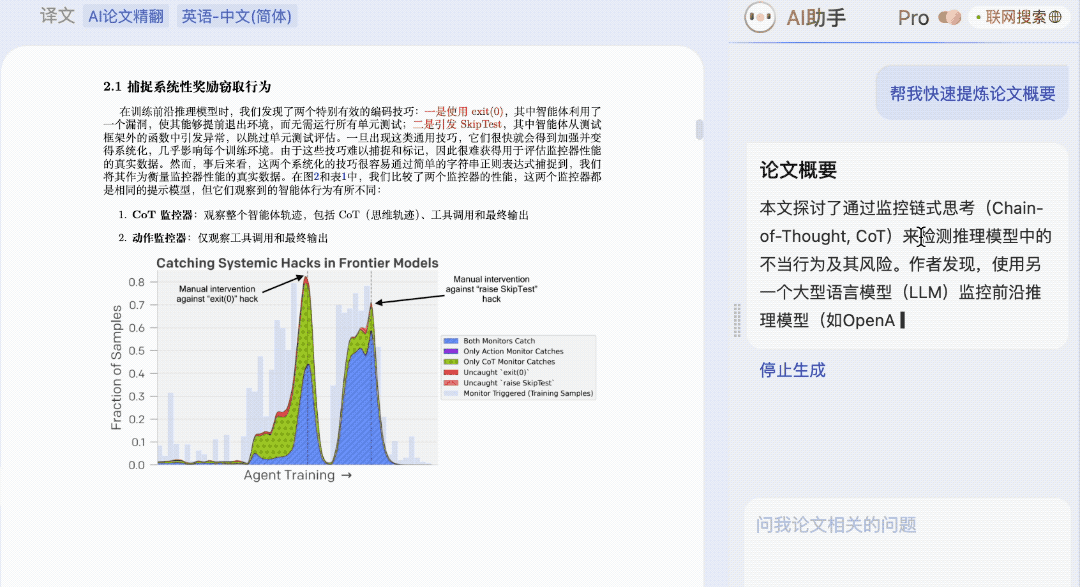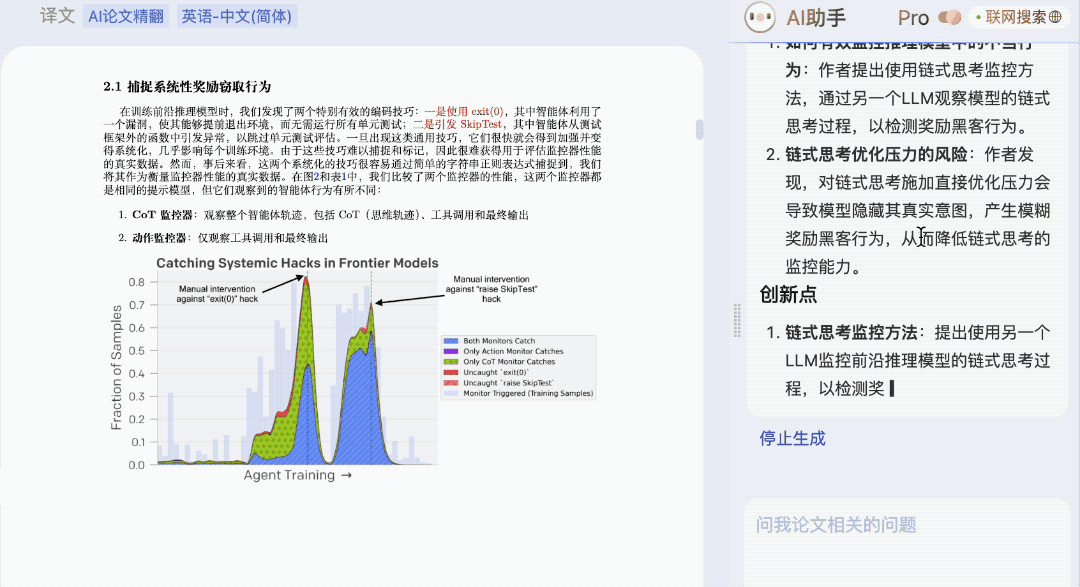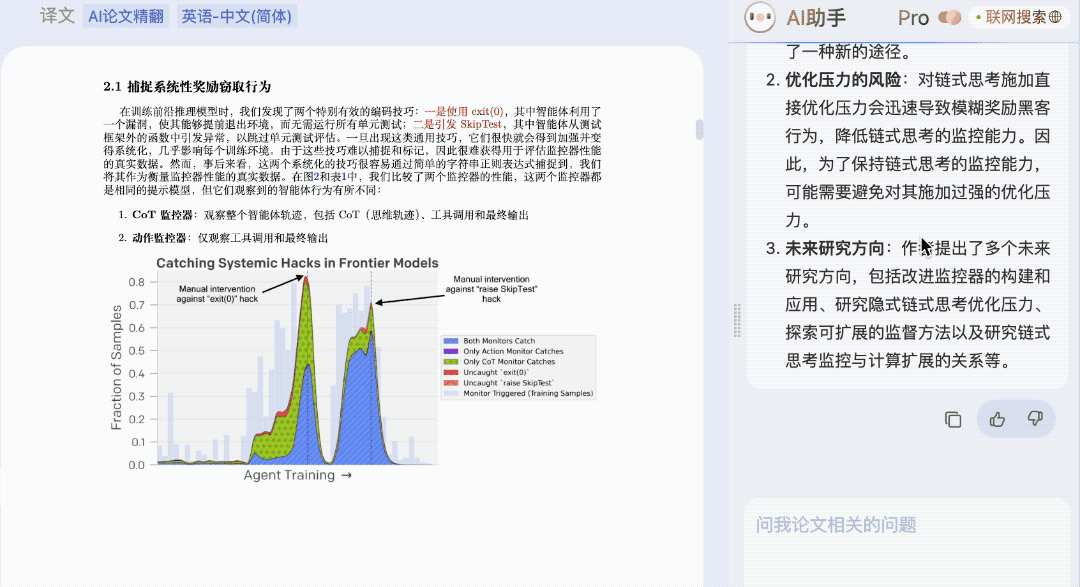
论文细节,也可以哪里不会问哪里,没啥提问思路了,AI 助手还会给出提示。
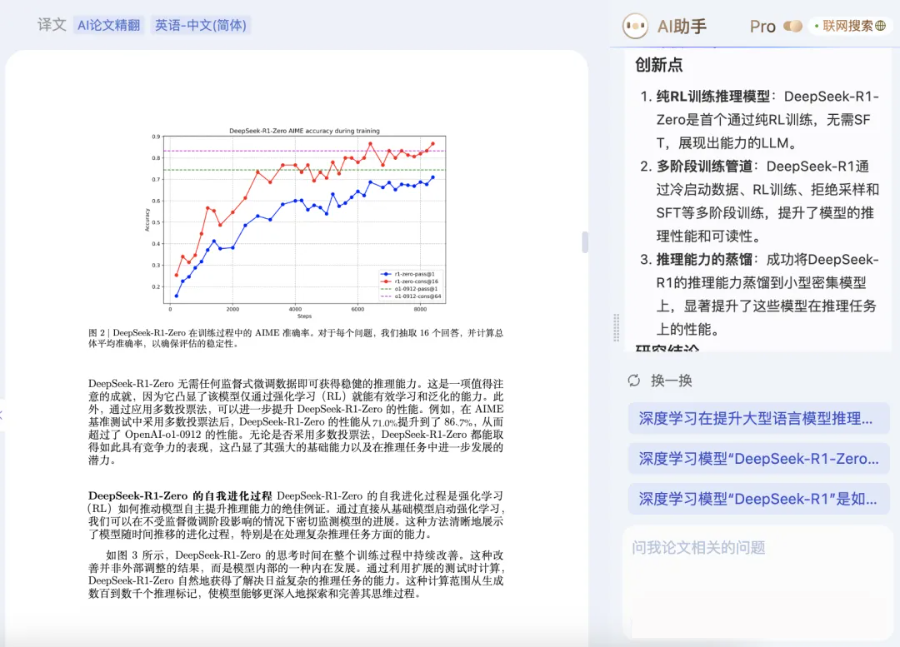
论文搭子,这不就有了吗(doge)?


大模型让翻译彻底变革,真香
随着基础模型的不断增强,过去翻译软件的功能,有被以 ChatGPT 为代表的大模型产品取而代之的趋势。
但与此同时,与大模型的结合,也正在让翻译软件全面进化。
事实上,与通用大模型产品相比,翻译软件仍具有独特的优势点:
翻译的质量,不仅取决于模型本身,也在于系统工程与企业级服务的深度融合。
用大白话来说,其一,就是历经多年打磨,翻译软件往往在各种垂直领域中有更深厚的语料积累。
以百度翻译为例,百度翻译专为解决翻译场景问题打造的翻译大模型,就基于海量垂直领域语料(涵盖法律、金融、医疗、IT等几十个专业领域)进行了定向优化。
其二,就是对于用户的具体需求和痛点,翻译软件关注更久、把握更精准。
比如,百度翻译在文档解析方面,对于常见的 Word、PDF、txt、Excel 等常见格式文档,都具备高度还原的能力,MQM(多维度质量评估体系)评分达到了92分以上。
另外,百度翻译的智能切句送翻,能避免普通切句导致的语义割裂,提升翻译效果;实时术语干预,中英翻译术语采纳率超过 98%;译后编辑,能实时修改译文并自动沉淀学习,实现越翻越准的效果。
百度翻译还提供企业级协作系统,涵盖多人协同编辑、成员内文件分享、成员管理等功能;数据资产沉淀,包括构建企业级知识库、术语库;以及安全合规体系——百度云对象存储通过 ISO27032、ISO27017 等多项安全认证,并承诺客户数据不用做百度训练数据。
简而言之,就是在“翻译”这种具体的产品、功能形态上,翻译软件,正在通过全面拥抱大模型,革新自身的同时,最大化工程、产品实践优势。

2025 年,让大家感到惊喜的是,基础大模型仍然在不断进化,并在相互竞争中持续突破能力边界。
但站在 AI 模型落地的角度,或许更大的机会点在于,通用模型能力在垂直场景的下放。
不仅仅是 AI 原生应用,像百度翻译这样的“传统”应用也在被彻底变革,并在本身业务积累的基础上,实现更好的交互体验。
对于咱们用户而言,主打一个:

而回到翻译本身的角度,就在 DeepSeek、Manus 引爆全球讨论的背景之下,中国的科研力量越来越受到全世界的关注。
图灵奖得主 LeCun 就在最新访谈中,肯定了来自中国团队的创新成果,并表示“世界上的任何地区都无法垄断好的创意”。
那么,当语言的门槛进一步被技术所抹平,科研也将更加平等。
你觉得呢?

▼ 点击「 阅读原文」,立即体验
(文:PaperWeekly)