

对 LLM(大模型)进行微调可以定制其行为、增强并注入知识,并优化其在特定领域或任务上的表现。例如:
-
GPT-4作为基础模型,然而,OpenAI 对其进行了微调,使其能够更好地理解指令和提示,最终打造出了如今大家使用的 ChatGPT-4。
-
DeepSeek-R1-Distill-Llama-8B是 Llama-3.1-8B 的微调版本。DeepSeek 利用 DeepSeek-R1 生成的数据对 Llama-3.1-8B 进行了微调。这一过程被称为蒸馏(distillation),即将数据注入 Llama 模型,使其学习推理能力。
使用 Unsloth,我们可以在 Colab、Kaggle 或本地(仅需 3GB 显存)免费进行微调。通过在专业数据集上微调预训练模型(如 Llama-3.1-8B),你可以:
-
更新知识:引入新的领域知识。
-
定制行为:调整模型的语气、个性或回复风格。
-
优化任务:提高特定任务的准确性和相关性。
微调的典型应用场景
✅ 训练 LLM 预测某个新闻标题对公司是正面还是负面影响。
✅ 利用历史客户交互数据,提供更准确且个性化的回复。
✅ 在法律文本上微调 LLM,用于合同分析、判例研究和合规性审查。
你可以将微调后的模型理解为一个专门针对某些任务优化的特定 Agent,能够更高效地完成特定任务。微调可以复现 RAG 的所有能力,但 RAG 不能完全替代微调。
选择合适的模型和微调方法
如果你是初学者,建议从 Llama 3.1(8B)这样的小型指令模型(Instruct Model)入手,并在此基础上进行实验。此外,你需要在 QLoRA 和 LoRA 训练方法之间做出选择:
-
LoRA:微调 小型可训练矩阵(16-bit),无需更新所有模型权重。
-
QLoRA:结合 LoRA + 4-bit 量化,能够以最小的资源处理超大规模模型。
你可以在 Hugging Face 上选择自己喜欢的模型,并匹配相应的模型名称,例如:unsloth/llama-3.1-8b-bnb-4bit。
此外,还有 3 个可调节的关键参数:
✅ max_seq_length = 2048 —— 控制上下文长度。虽然 Llama-3 支持 8192,但推荐使用 2048 进行测试。Unsloth 支持 4× 更长的上下文微调。
✅ dtype = None —— 默认为 None,对于较新的 GPU,建议使用 torch.float16 或 torch.bfloat16。
✅ load_in_4bit = True —— 启用 4-bit 量化,可在 16GB GPU 上减少 4 倍显存占用,在大显存 GPU(如 H100) 上关闭此选项可略微提升 1%~2% 的准确率。
推荐使用 QLoRA,它是目前最易用且高效的微调方法之一。Unsloth 的动态 4-bit 量化使 QLoRA 相比 LoRA 造成的精度损失已基本恢复。
除了微调,你还可以使用 Unsloth 进行:
🚀 推理(GRPO)
👀 视觉任务
🏆 奖励建模(DPO、ORPO、KTO)
📚 持续预训练
📝 文本补全
以及其他训练方法!
数据集
对于 LLM,数据集是可以用来训练模型的数据集合。为了能够用于训练,文本数据需要以可以 tokenize 的格式呈现。
通常,你需要创建一个包含两列的数据集 —— 问题和答案。数据的质量和数量将直接影响微调后的效果,因此确保这一部分正确至关重要。
你可以使用 ChatGPT 或本地 LLM 来合成生成数据并将数据集结构化(转换为问答对)。
微调可以永久性地融入已有文档库,并不断扩展其知识库,但仅仅将数据堆积起来并不会获得最佳效果。为了获得最佳结果,建议精心策划一个结构良好的数据集,理想情况下是问答对。这种方式有助于提高模型的学习、理解和回答准确性。
但并非总是如此。例如,如果你仅仅将所有代码数据直接用于微调,即使没有结构化的格式,模型的性能也可能会有显著提升。所以,这实际上取决于你的应用场景。
理解模型参数
模型有数百万种超参数组合,选择合适的参数值对于获得良好的结果至关重要。你可以编辑下面的参数(数值),但其实可以忽略它们,因为我们已经选择了相当合理的参数值。
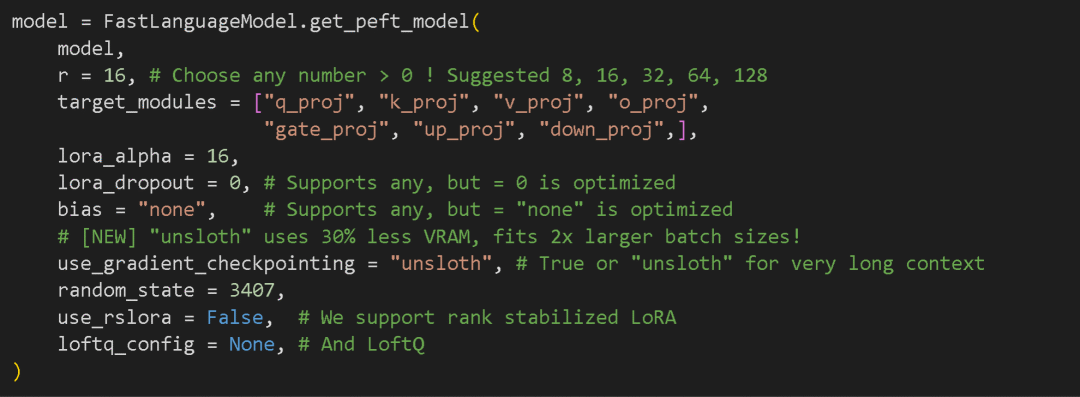
目标是调整这些参数,以提高准确性,同时避免过拟合。
过拟合是指语言模型记住了某个数据集的内容,却无法回答新的问题。我们希望最终的模型能够回答未见过的问题,而不是简单地进行记忆。以下是关键参数:
学习率(Learning Rate)
定义了模型在每个训练步骤中权重调整的幅度。
-
较高的学习率:训练速度更快,但有过拟合的风险。
-
较低的学习率:训练更稳定,但可能需要更多的训练轮次(epochs)。
-
典型范围:1e-4(0.0001)到 5e-5(0.00005)。
训练轮次(Epochs)
模型看到完整训练数据集的次数。
推荐:1-3轮(超过 3 轮通常不是最优的,除非你希望模型减少幻觉回答,但也会减少创造力)。
-
更多的训练轮次:有助于更好的学习,但也更容易过拟合。
-
较少的训练轮次:可能导致模型欠拟合。
避免过拟合和欠拟合
过拟合(过于专业化)模型记住了训练数据,无法推广到未见过的输入。解决方案:
-
降低学习率。 -
减少训练轮次。 -
将数据集与通用数据集结合,例如 ShareGPT。 -
增加 dropout 比例,引入正则化。
欠拟合(过于通用)虽然这种情况比较少见,但有时模型可能无法从训练数据中学习,给出的回答与基础模型类似。解决方案:
-
增加学习率。 -
训练更多轮次。 -
使用更符合领域的相关数据集。
微调没有单一的“最佳”方法,只有最佳实践。实验是找到适合你需求的方法的关键。
训练与评估
一切设置好后,就可以开始训练了!如果遇到问题,记住你可以随时调整超参数、数据集等内容。
在训练过程中,你会看到一些数字的日志!这些是训练损失(training loss),你的任务是调整参数,使其尽可能接近 0.5。如果你的微调没有达到 1、0.8 或 0.5,可能需要调整一些参数。如果损失降到 0,这通常也不是一个好兆头!
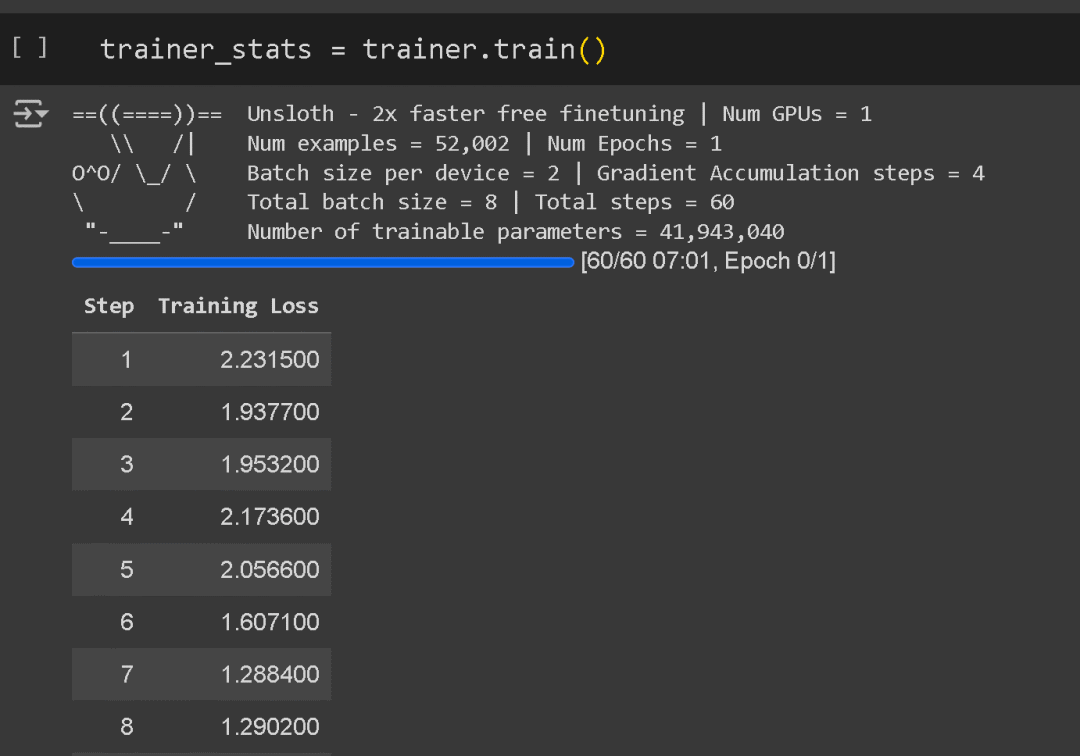
我们通常建议保持默认设置,除非你需要更长的训练时间或更大的批量大小。
-
per_device_train_batch_size = 2 :增加此值可以更好地利用GPU,但要注意可能会因为填充而导致训练速度变慢。相反,可以增加 gradient_accumulation_steps 以获得更平滑的训练过程。
-
gradient_accumulation_steps = 4 :模拟更大的批量大小,而不增加内存使用。
-
max_steps = 60 :加速训练。对于完整的训练,可以用 num_train_epochs = 1 来替代(建议 1-3 轮,以避免过拟合)。
-
learning_rate = 2e-4 :选择较低的学习率可以实现较慢但更精确的微调。可以尝试像 1e-4、5e-5 或 2e-5 这样的值。
评估
为了进行评估,你可以通过与模型聊天的方式进行手动评估,看看它是否符合你的需求。你也可以启用 Unsloth 的评估功能,但要记住,根据数据集的大小,这可能会比较耗时。为了加快评估速度,你可以:
-
减少评估数据集的大小,或 -
设置 evaluation_steps = 100。
对于测试,你也可以取 20% 的训练数据用于测试。如果你已经使用了所有的训练数据,那么就需要手动进行评估。你也可以使用像 EleutherAI 的 lm-evaluation-harness 这样的自动评估工具。需要注意的是,自动化工具可能无法完全符合你的评估标准。
https://docs.unsloth.ai/get-started/fine-tuning-guide

(文:PyTorch研习社)