

“AI音频时代”研究小组独家专稿,转载请务必先联系。

上篇:当下最具有代表性的 10 个中文文生音 TTS模型(上),(本文部分内容来自于ChatGTP、豆包、DeepSeek等):
OpenVoice
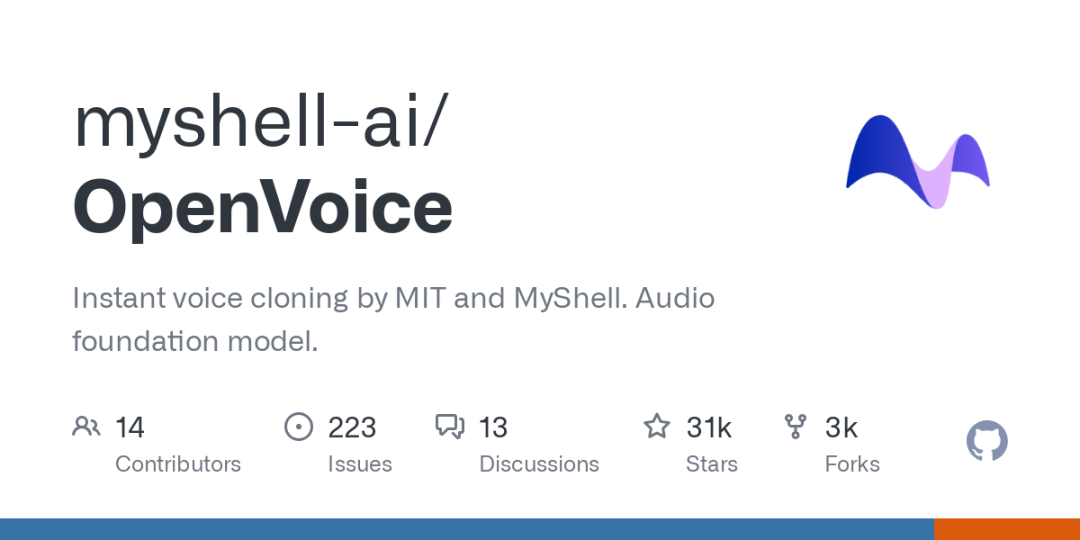
OpenVoice 是麻省理工学院(MIT)和 MyShell 联合开发的开源即时语音克隆项目,一种多功能的即时语音克隆方法,只需要来自参考说话人的简短音频剪辑即可复制他们的语音并生成多种语言的语音。OpenVoice 还可以对语音风格进行精细控制,包括情感、口音、节奏、停顿和语调。
优势:
-
精确的音色克隆:能够准确克隆参考语音的音色,在音调、音质、情感等方面高度还原原声,可在不同语言和口音之间生成高度一致的语音内容。比如,在制作多语言有声读物时,能将原作者的声音特点精准克隆到不同语言版本中。
-
灵活的语音风格控制:允许用户对语音风格进行细粒度控制,包括情感、口音、语速、停顿和语调等。用户可以根据具体需求,将语音设置为欢快、悲伤、严肃等不同情感风格,或者调整为不同地区的口音。
-
零样本跨语言语音克隆:无论生成语音的语言,还是参考语音的语言,都不需要在庞大的多语种训练数据集中出现。即使训练数据集中没有包含某些语言,也能实现这些语言之间的语音克隆,为跨语言交流和语音应用的全球化提供了便利。
局限:
语音自然度仍有待提升:尽管能够克隆出与目标说话人相似的声音,但在语音的自然度和流畅度方面,与人类自然语音相比仍有差距。在语调、韵律、停顿等细节处理上,有时会显得生硬和机械,影响听众的听觉体验,特别是在长文本的语音合成中,这种不自然感可能会更加明显。
情感表达不够精准:对于语音中情感的细腻表达能力有限。在需要传达复杂情感,如微妙的悲伤、喜悦或愤怒等情绪时,生成的语音可能无法准确捕捉和呈现这些情感的细微差别,导致语音缺乏情感共鸣,难以让听众产生强烈的情感连接。
版权与伦理问题:作为语音克隆技术,GPT-SoVITS 面临着严重的版权和伦理挑战。未经授权克隆他人声音,可能侵犯个人的声音版权和隐私权。同时,恶意使用该技术,如伪造名人声音进行诈骗、传播虚假信息等,会对社会秩序和个人权益造成极大危害,引发一系列法律和道德争议。
EmotiVoice
EmotiVoice(易魔声)是网易有道开源并维护的一款功能强大且现代的开源文本转语音(TTS)引擎,原生支持包括中文在内的多种语言,提供灵活的语音风格控制和零样本跨语言语音克隆功能,方便在不同语言和风格之间切换。
优势:
-
双语言支持:支持中英文两种语言的文本转语音,在处理包含多种语言的文本时,能够准确地将其转换为相应语言的语音,满足不同语言场景的需求。
-
音色丰富:拥有超过 2000 种不同的音色,包括男声、女声、童声等多种类型,用户可以根据需要选择合适的音色进行语音合成。
-
情感合成:特色功能之一是情感合成,允许用户通过简单的提示词实现情感的切换,如快乐、兴奋、悲伤、愤怒等,使合成的语音更具表现力和感染力。
-
使用便捷性
-
用户友好界面:提供了简洁直观的网页界面,用户可以轻松上手,无需复杂的设置即可进行语音合成。
-
批量语音生成 API:除网页界面外,还配备了批量语音生成的 API,方便开发者将其集成到自己的项目中,实现自动化的语音合成功能。
-
应用前景较广:在语音助手、在线教育、有声读物、广告配音等多个领域具有广泛的应用前景,能够提供高质量的语音合成服务,满足用户的多样化需求。
局限:
-
声音预览缺失:EmotiVoice 不支持声音预览,用户在选择语音包时无法提前试听,只能凭运气或经验选择,这可能会浪费用户的时间和精力,影响使用体验。
-
音色标注不准确:部分音色的性别标注可能存在错误,用户需要自己试听来判断,这也给用户选择合适的音色带来了不便。
-
对运行环境要求较高:EmotiVoice 的本地部署包较大,需要足够的存储空间进行下载和解压。并且,为了达到最佳使用体验,建议使用拥有 NVIDIA GPU 的 PC 进行本地部署,因为 GPU 性能将影响语音合成的效率,这对于一些没有高性能 GPU 的用户来说,可能无法充分发挥该软件的功能。
-
文本处理存在局限:当文本含有中英文混搭、阿拉伯数字或标点符号过多时可能会报错,对复杂文本格式的处理能力有待提高。
-
情感识别准确性有待提升:尽管 EmotiVoice 具有情感合成功能,但人工智能在理解和识别情感表达方面仍然存在一定的局限性,可能无法完全准确地把握和合成一些复杂、隐晦的情感。
PaddleSpeech
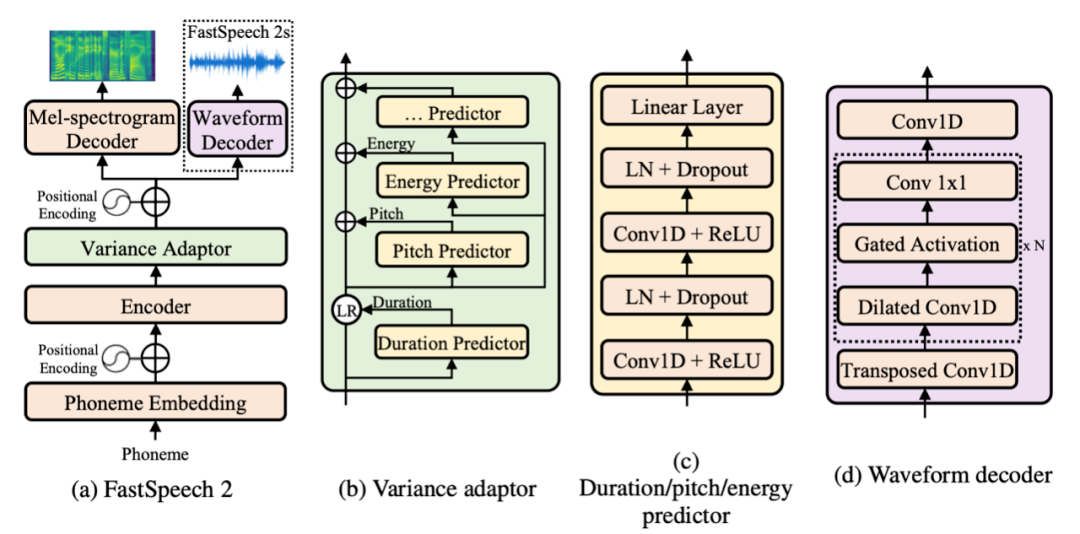
PaddleSpeech 是百度AI开发的一个基于飞桨深度学习框架开发的开源语音处理工具集,提供了基于 FastSpeech2 声学模型和 HiFiGAN 声码器的中文流式语音合成系统。
优势:
-
易用性强:提供命令行界面、服务器 API 和流式处理等多种使用方式,还有详细的文档和示例代码,方便开发者快速上手,降低了语音处理技术的使用门槛。
-
功能丰富多样:集成了语音识别、语音合成、语音分类、声纹识别、语音翻译、标点恢复以及语音前端处理等多项先进语音技术,能满足不同行业和领域的多样化需求。
-
性能出色:采用业界先进的语音模型和算法,经过大量数据训练和优化,在准确性和效率上表现优异,能够快速、准确地处理语音任务,为用户提供高质量的语音服务体验。
-
高度可定制:开放了模型训练和微调的能力,开发者可以根据自身特定的应用场景和数据特点,对模型进行个性化定制,使 PaddleSpeech 更好地适应不同的业务需求,实现定制化的语音处理解决方案。
-
中文优化显著:针对中文语音处理进行了专门优化,在文本正则化、多音字处理等方面表现出色,能够有效提升中文语音处理的准确性和自然度,特别适合中文语音相关的应用开发。
-
流式处理能力:支持语音识别和语音合成的流式处理,这使得它在实时交互场景中表现出色,如实时语音聊天、直播语音转文字等,能够满足对实时性要求较高的应用场景需求。
-
跨平台兼容:能在 Linux、Windows 和 MacOS 等多种操作系统上运行,兼容多种设备和开发环境,如 Python、Jupyter Notebook 等,方便开发者进行实验和调试。
-
社区支持活跃:拥有强大的开发团队和活跃的社区,持续更新维护,问题响应及时,开发者可以通过参与贡献来帮助推动项目的发展。
局限:
-
框架容错率较低:在面对一些异常输入或不常见的语音数据时,可能容易出现错误或报错,对输入数据的规范性要求相对较高。
-
维护人员有限:开源项目的维护人员数量可能相对有限,这可能导致在处理一些复杂问题或新需求时,响应速度和解决问题的效率受到一定影响。
-
不支持 Torch 下二次开发:由于是基于飞桨深度学习框架开发,不能在 Torch 框架下进行二次开发,限制了一些习惯使用 Torch 框架的开发者的选择。
-
语音合成自然度和情感表达有待提升:虽然语音合成功能可将文本转化为自然流畅的语音,但在自然度和情感表达方面,与一些专业的商业语音合成系统相比,可能还存在一定的差距,语音可能会显得相对机械,在表达复杂情感时不够细腻和准确。
-
多语种支持存在挑战:尽管支持多种语言,但在多语种的全面性和语种间切换的无缝衔接上,可能还有提升空间,难以实现像一些专门的多语种语音处理系统那样的流畅切换和高质量合成。
剪映 TTS
剪映CapCut TTS 是字节跳动AI Lab 语音与音频团队开发的语音合成技术,
优势:
-
语音合成质量高:字节跳动 AI Lab 语音与音频团队通过研发音素级别细粒度韵律建模的 AM 架构等技术,使 CapCut TTS 能够生成发音准确、清晰,可懂度高的语音。并且能实现同一声音演绎多国语言,提供超过 17 种语言、13 种方言、100 + 不同风格媲美真人的音色,满足不同用户的需求。
-
操作便捷:用户只需输入文本,选择语音角色,即可一键合成 TTS 语音,还能试听和调整,直到满意为止,操作简单,容易上手。
-
支持多格式导出:生成的语音文件支持 MP3、WAV 等多种常见音频格式,方便用户直接把生成的文件用于剪辑、配音、短视频创作等,无需担心格式不兼容的问题。
-
与剪辑软件集成度高:与剪辑软件剪映(CapCut)的视频剪辑功能紧密结合。用户在剪辑视频时,能方便地将文本转换为语音并直接应用到视频中,无需在不同软件之间切换,节省了时间和精力,工作流程更加顺畅。而其他 TTS 产品可能需要额外的步骤来导入到剪辑软件中,操作相对繁琐。
局限:
-
功能相对单一:主要专注于文本转语音功能,在语音交互、语音特效等其他相关功能方面可能相对缺乏,不能满足一些用户对于复杂语音处理的需求。
-
存在语言限制:虽然支持多种语言,但作为剪辑软件的一个功能,对某些小众语言或特定领域的专业术语支持不够完善,在语音合成的准确性和自然度上有待提高。
-
依赖软件环境:需要在软件或相关支持的平台中使用,不能独立运行,对于一些希望在不同设备或离线状态下使用语音合成功能的用户来说,不太方便。
TTS Maker
TTS Maker 是一款免费在线的文本转语音工具,提供语音合成服务,支持包括英语、法语、德语、西班牙语、阿拉伯语、中文、日语、韩语、越南语等多种语言,支持中文多种方言,如东北话、粤语、闽南话等,以及各种声音风格。
优势:
-
免费商用:用户可免费使用该工具生成音频,且拥有合成音频文件的 100% 版权,无论是个人创作还是企业商业用途,都无需担心版权问题。
-
语言和风格丰富:支持 50 多种语言,涵盖中文、英语、日语、韩语、法语、德语等主流语言,以及多种方言和特色语言。每种语言配备超过 300 种语音风格,包括男声、女声、不同年龄段的声音,还有播音腔、方言、情感化语音等,能满足不同用户的多样化需求。
-
操作简便高效:操作流程简单,只需输入文本、选择语言和语音风格、输入验证码点击 “开始转换” 三步即可。其强大的 AI 神经网络模型确保了高效的转换速度,即使是较长的文本也能在短时间内完成转换。
-
个性化定制程度高:提供丰富的高级设置功能,包括语速、音量、音高调节,以及段落停顿时间和背景音乐添加等,让用户能够根据具体需求定制音频,满足不同场景的使用要求。
-
音频格式支持多:生成的音频可以保存为 MP3、OGG、AAC、OPUS、WAV 等多种格式,方便用户根据不同的使用场景选择合适的文件格式。
局限
-
筛选配音师不便:配音师特色筛选比较麻烦,需要下拉逐一浏览,不够便捷高效,用户可能需要花费较多时间才能找到符合自己需求的语音风格。
-
转换字数受限:每次只能转换 1 万字,而且每周只能转换 3 万字,对于有大量文本转换需求的用户来说,无法满足其全部需求。
-
语音合成质量有差距:语音合成质量可能不如一些高端付费工具,在自然度和情感表达的细腻程度上,与专业的商业语音合成系统相比存在一定差距,可能会有机械感。
-
依赖网络:作为在线配音工具,需要联网才能操作,在没有网络或网络信号不好的情况下无法使用,这对使用场景有一定限制。
结语:
正如上篇开头所说,TTS在2024年迎来了火山爆发似的发展,需要一个较全面的总结,感谢大家的阅读与转发,预计2025年TTS将继续向着更高质量发展,很快语音生成的真实度将达到真正的“以假乱真”。另外需要补充的是,中文文生音TTS上下两篇文章主要基于自24年初至年底我们的跟踪,25年初又有更多的TTS推出,由于时间精力等原因暂未收录。
Resreach
“AI音频时代”研究小组由扎根电影声音行业的资深人士以及对音频发展有兴趣的年轻音频人组成,核心目标是跟踪并实践当下AI音频技术的发展,未来在内容创作,音频技术方面积极应用,由电影声音网,DiffuSound 弥声工作室提供场地、技术及设备支持。欢迎合作。
由电影声音网,DiffuSound 弥声工作室提供场地、技术及设备支持
(文:AI音频时代)