跳至内容

AI圈的PK竞赛又开始变得热闹起来,继DeepSeek推出最强开源非推理模型V3-0324之后,大洋彼岸的谷歌、OpenAI连夜上新,纷纷拿出了各自的最新杀手锏。
DeepSeek的新版V3模型借鉴了R1模型训练过程中的强化学习技术,大幅提高了在推理类任务上性能表现,在数学、代码类相关评测集上对OpenAI最新模型GPT-4.5形成赶超之势,多项评测表现也优于Anthropic旗舰模型Claude 3.7 Sonnet,再次代表开源AI打出一套王炸牌。
目前,AI独角兽Anthropic尚未有任何动态回应,但代表美国AI技术前沿的谷歌和OpenAI迅速做出了反应。
周二夜间,谷歌推出Gemini 2.5 Pro Experimental,CEO桑德尔·皮查伊发帖表示这是谷歌迄今为止最智能的AI模型;另一边OpenAI的CEO萨姆·奥特曼则亲临直播间发布ChatGPT原生图像生成功能,展示了精确AI生图效果,大大提升了AI生图的实用性。
可以说,这波较量直接把今年的AI竞赛水平拉上新台阶。
Gemini 2.5模型属于当下主流的思维链模型,能够在做出反应之前通过自己的想法进行推理,从而提高性能和准确性,谷歌这次发布的是2.5 Pro实验版。
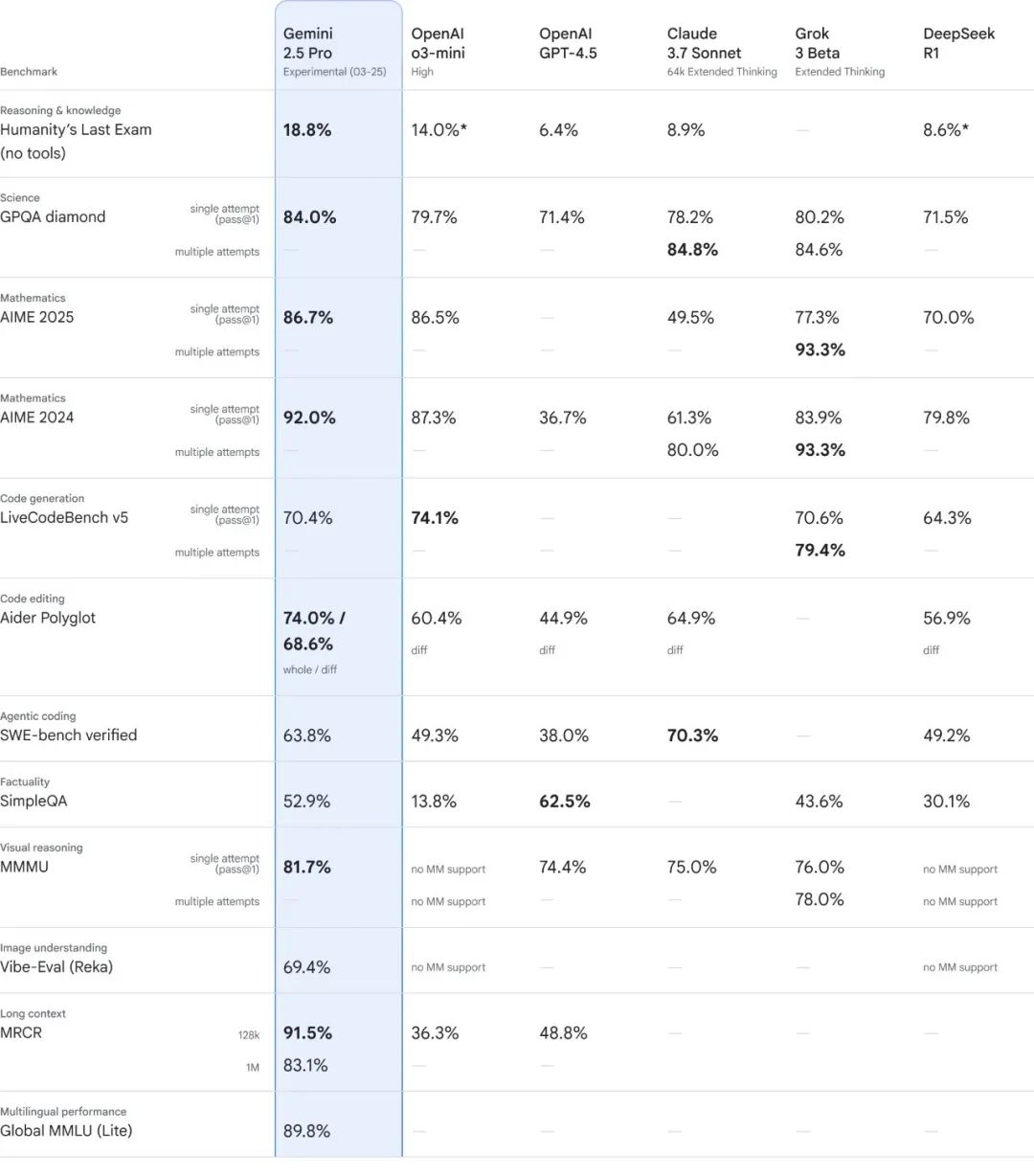
官方给出的数据来看,它在各种基准测试中都处于领先水平,并在LMArena上以显著优势排名第一,表明该模型具有出色的性能和高品质的风格,2.5 Pro还表现出强大的推理和编码能力,在常见的编码、数学和科学基准测试中。
目前,Gemini 2.5 Pro已在Google AI Studio和Gemini应用中面向Gemini Advanced用户推出(每月20美元订阅费用),谷歌方面表示将在未来几周内推出定价,使人们能够使用具有更高速率限制的2.5 Pro进行大规模生产使用。
而且,延续Gemini原生多模态和长上下文窗口特性,可以理解庞大的数据集并处理来自不同信息源的复杂问题,包括文本、音频、图像、视频甚至整个代码存储库。
财大气粗的谷歌为2.5 Pro设定带有100万个标记上下文窗口,这意味着该模型一次大约可以处理75万个单词,比整部《指环王》书籍的字数还要多,谷歌还表示Gemini 2.5 Pro很快将支持两倍的输入长度(达到200万个token)。
增强推理和高级编码是这次Gemini 2.5 Pro发布的亮点。在一系列需要高级推理能力的基准测试中,不使用会增加成本的测试时间技术情况下,Gemini 2.5 Pro在数学和科学基准测试(如GPQA和AIME 2025)中处于领先地位,在“人类的最后考试”中,它获得了18.8%分值,实现行业目前最佳成绩。
同时,Gemini 2.5 Pro更擅长创建视觉Web应用程序和代理代码应用程序,以及代码转换和编辑,在衡量软件开发能力的SWE-Bench Verified测试基准上,Gemini 2.5 Pro使用自定义代理设置得分为63.8%,优于OpenAI的o3-mini和DeepSeek的R1,但低于Anthropic的Claude 3.7 Sonnet,后者的得分为70.3%。
Gemini 2.5 Pro生成的代码复制过来直接运行毫无压力,为当下“一句话编程”等AI应用再添一把火。
因为它会运用其推理能力可以从简单的提示词中分析如何去实现目标,进而生成可执行的代码。
例如提出要求:为我制作一个引人入胜的无尽跑酷游戏。屏幕上显示关键操作说明,使用p5.js创建场景,无需HTML,我喜欢像素风格的恐龙和有趣的背景,那么一个游戏开发的时间仅需67秒。
这跟国内百度近期发布的无代码对话式应用开发平台秒哒类似,AI让想法变成实际应用的能力越来越强,开启“自然语言编程时代”,可能会催生出无数衍生应用。
与谷歌的大模型进击相比,OpenAI并没有提前释放关于GPT-5的信息,而是推出了一个新功能——4o图像生成,如果以前的AI生图细节不太受控,那么基于此功能开始可以实现精确、准确、逼真的输出,进而解锁实际有用且有价值的AI图像。
1、这是一项令人难以置信的技术/产品。我记得看到过这个模型产生的第一批图像,当时很难相信它们真的是由人工智能制作的。
2、这代表着AI在创作自由方面达到了一个新高度。人们将会创造出一些非常了不起的作品,也会创造出一些可能会冒犯他人的东西。我们想要达到的目标是,除非你有意为之,否则这个工具不会生成冒犯性的内容,而在你有意的情况下,它也会在合理范围内生成。
这跟谷歌的一句话生成代码开发游戏一样,在ChatGPT创建和自定义图像就像使用GPT-4o聊天一样简单,一句话进行PS平面设计,只需描述你所需要的内容,包括任何具体细节,例如纵横比、使用十六进制代码的精确颜色或透明背景等等。
4o图像生成擅长准确渲染文本、精确遵循提示以及利用4o固有的知识库和聊天上下文,包括转换上传的图像或将其用作视觉灵感。
优势在于:1、照片级的真实感与写实风格适应;2、自然对话中的多轮编辑;3、图像内精确的文本渲染;4、准确处理10-20个图中不同的对象;5、利用现实世界的知识创造有意义的视觉效果。
还有一些对于漫画家非常友好的功能,把手绘草稿想法直接变成上好色的动画版面成品:
或者把写实照片渲染制作成吉卜力工作室版本,效果很细腻,如果能再跟AI生成动画结合,可能会带来小小的颠覆:
OpenAI表示,由于此模型可以创建更详细的图片,因此图像渲染时间更长,一张图通常需要一分钟以上,另外,该生图模型目前也并不完美,例如裁剪不恰当、存在一定幻觉、多语言文本渲染、编辑精度等还有待提高,后续会通过改进来解决这些限制。
生成式AI是当下人工智能领域发展最为迅速且极具潜力的一个细分市场,而且可能会在技术进一步突破后迎来一轮暴涨。
据Bloomberg Intelligence的一项研究预测,随着以谷歌、OpenAI等为代表的消费级生成AI程序的渗透,到2032年全球生成式AI市场规模有望增长至1.3万亿美元,复合年增长率可能达到42%。
短期内,增长仍由训练基础设施推动,而从中长期来看,增长动力将逐渐转向大型语言模型(LLM)的推理设备、数字广告以及专业软件和服务。生成式AI的影响也将从占IT硬件、软件服务、广告支出和游戏市场支出总额的不到1%扩大到至少10%。
在越来越先进的大模型加持下,生成式AI的水平正在变得越来越高也越发精细化,无论是生成代码还是生成图像,输出质量越来越贴合实际需求和场景,这正在成为行业竞争新趋势,可能会催化出很多新市场和新赛道。

(文:头部科技)