作者|沐风
来源|AI先锋官
今年以来,从深度推理模型DeepSeek R1到混合推理模型Claude3.7、到AI Agent产品Manus、到谷歌最强模型Gemini 2.5 Pro,再到GPT-4o的生图功能等等,可以说是王炸不断。
就在昨天,AI初创公司Runway也放出了大招,发布了其最新研发的AI视频生成模型Gen-4,让AI视频更靠近电影级。
相较于Gen-3,它在生成高动态性视频方面表现更出色,不仅能呈现真实流畅的动作效果,还能保持主题、物体和风格的一致性,同时具备卓越的提示遵循能力及场景理解能力。
Runway在其官方的博客中称,Gen-4在高保真度和、一致性和指令遵循度均达到了同类顶尖水平。
简单来说,用户只需提供角色的参考图像,Gen-4就能够在不同的视频场景中保持角色、地点和物体的高度一致性,维持“连贯的世界环境”,整个过程无需进行模型微调或额外的专门训练。
并且,它还能够从场景内的不同视角和位置重新生成元素。
例如,给它一张参考图片,Gen-4就能让图片中的角色在各种场景、角度中始终保持形象一致。
如果你想要获取场景的任意视角,只需提供拍摄对象的参考图像并描述镜头的构图即可,Gen-4即可完成剩下的工作。
值得一提的是,Runway称,“ Gen-4 代表了视觉生成模型在模拟真实世界物理能力方面的一个重要的里程碑。”
其展示演示的视频中,Gen-4对于水、火、空气流动以及在一些物理条件中人物和物体的表现,都理解得极其细致入微,几乎看不出失真的地方。
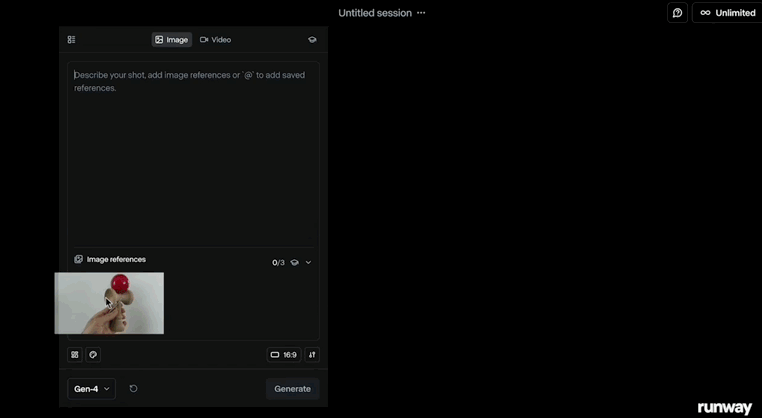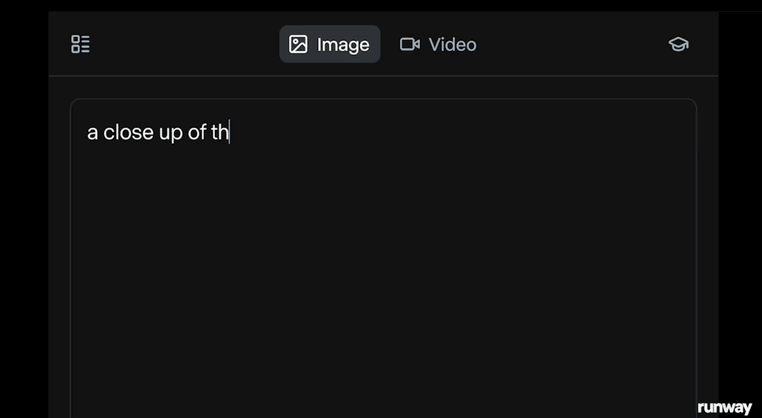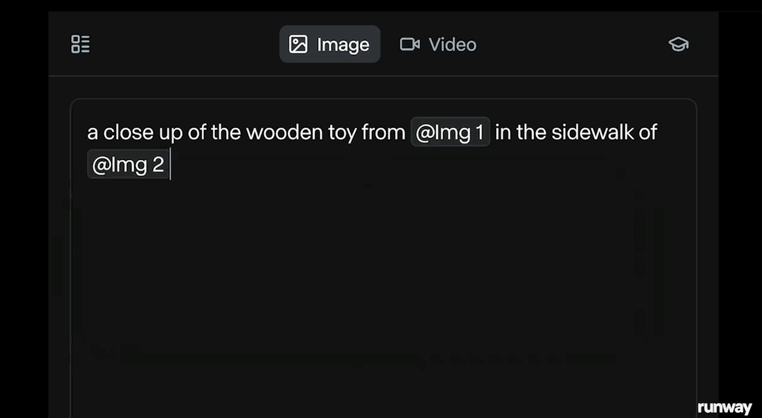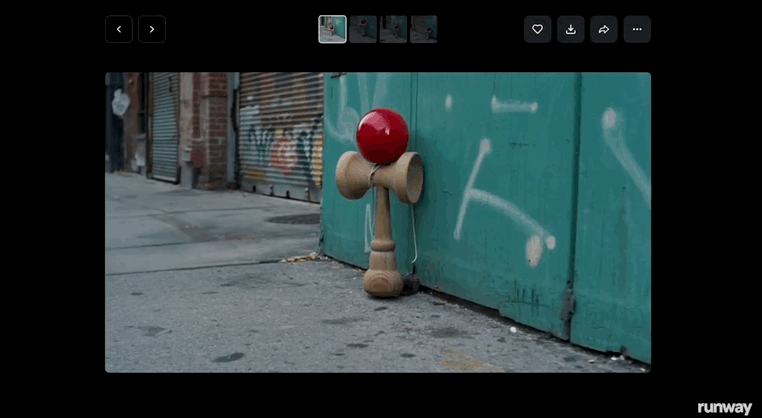
在Runway发布的宣传片中,其还演示了用两张照片生成影像级视频的整个过程。
拍摄一张手中的玩具的照片,然后上传了一张街景图片,通过简单的指令就将玩具融入到了街景当中。
接着挑选其中一张照片,就能生成人们从玩具旁边走过的视频。
除此之外,你还可以将这个玩具放在任何地方,如雪地、山脉、沙漠等。
为了展现Gen-4的实力,Runway还专门放出了一系列完全使用Gen-4制作的视频短片,每个时长都超过了100秒。
《The Lonely Little Flame》
在第一个《The Lonely Little Flame》短片中,为制作臭鼬寻找东西的片段时,Runway团队为臭鼬设定了两个关键标记点,精确控制其移动路径。
然后其中一名成员在几个小时内生成了几百个单独的视频片段,将它们编辑成一个连贯的片段。
Runway联合创始人兼CEO Cristóbal Valenzuela Barrera在接受采访时表示,整个过程花了几天时间。
传统的视觉特效制作往往需要耗费大量时间进行建模、渲染和后期调整,但Gen-4引入了生成式视觉特效(GVFX)技术,大幅缩短了这一过程。
可以快速、可控且灵活的生成视频,可以与实时动作、动画和VFX内容无缝结合。
目前,Gen-4已向所有付费用户和企业客户开放,另外,用于角色、位置和物体一致性的场景参考功能也即将推出。
最后,小编也用其中的一个视频帧发送给可灵1.6进行参考,让它生成视频,结果……
不仅人物脸部完全崩坏,最后还有个头从车顶探了出来,唯独汽车这段视频在一致性上还做的不错,只不过最后这辆无人驾驶的轿车像变形金刚似的来了波首尾调换![]() 。
。
(文:AI先锋官)





 。
。

