
0x0. 前言
上周六的时候发现 @DiegoD94 在 vLLM 中尝试对DeepSeek V3/R1 应用一个fuse shared experts到普通256个expert中的工作 (https://github.com/vllm-project/vllm/pull/15502)。还有一个技术文档:https://docs.google.com/document/d/1iXgzR6Mt6s0DpT7w2Pz93ExlUJ-nnSnU_o9Sqd8TE34/edit?tab=t.0#heading=h.w2t5rj3ovrvv ,读了一下感觉比较有意义并且看起来对整体的吞吐和TTFT/ITL都有比较好的收益。所以利用周末时间在SGLang中实现了一下这个工作,由于我们之前在SGLang的sgl moe_align_kernel 中已经支持了num_experts>256的情况,所以本次实现起来比较方便,不需要修改sgl-kernel里面的cuda代码。在SGLang中的细节如下:https://github.com/sgl-project/sglang/pull/4918 。下面来讲一下这个fuse shared expert的技巧,另外再次致谢 @DiegoD94
0x1. 效果
下面展示一下在SGLang中的端到端效果:
GSM8K Acc Test
➜ sglang git:(support_r1_shared_expers_fusion) ✗ python3 benchmark/gsm8k/bench_sglang.py --num-questions 2000 --parallel 2000 --num-shots 8
100%|████████████████████████████████████████████████████████████████████████| 1319/1319 [01:08<00:00, 19.14it/s]
Accuracy: 0.952
Invalid: 0.000
Latency: 69.547 s
Output throughput: 1998.856 token/s
Benchmark in H200
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
注意,吞吐越高越好,TTFT/ITL越低越好。
从测试数据中可以看到,随着qps增大到4,吞吐提升了4%,TTFT和ITL都降低了15%-20%左右。表格对应的详细数据和服务启动命令以及bench_serving脚本的使用方式均贴在 https://github.com/sgl-project/sglang/pull/4918 中,感兴趣可以在这里找到相关信息。
0x2. 原理
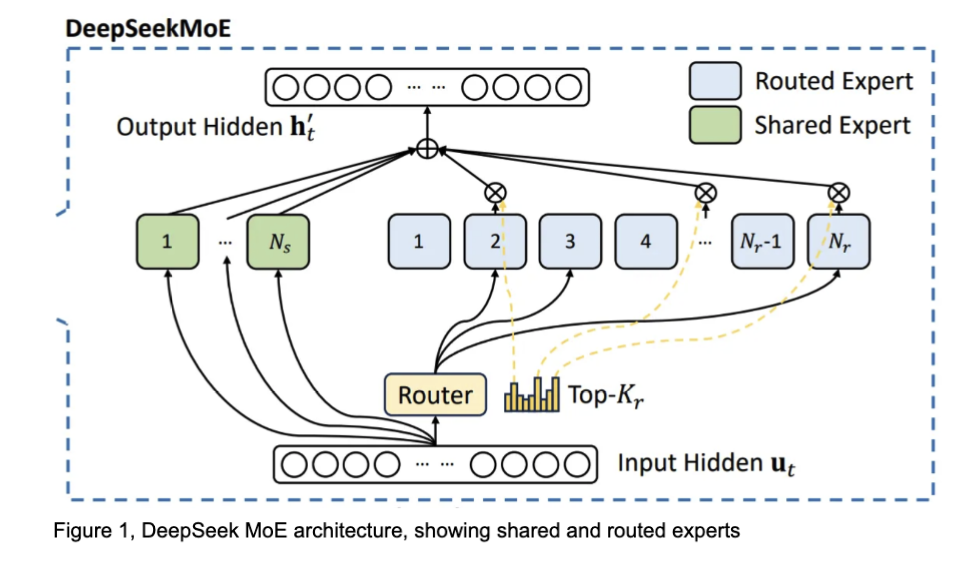
如图1所示,DeepSeek的MoE结构会将所有输入的token都送入共享专家(shared experts),同时也会将每个token路由到由路由器选择的top-k个专家(routed experts)中,最后基于权重将所有专家的输出进行聚合。具体来说,DeepSeek R1使用了256个路由专家和1个共享专家,对于每个token,它会选择top 8个路由专家。在VLLM和SGLang的实现中,token的隐藏状态首先通过共享专家,然后再通过FusedMoE kernel中的路由专家。最后将这两个输出相加作为最终输出。
一个简单的优化方法是:我们可以将共享专家的计算合并到FusedMoE kernel中,因为共享专家和路由专家具有完全相同的架构和形状。这样,对于每个token,我们不再是从256个专家中选择top 8个,再单独选择1个共享专家,而是直接从257个专家(256个路由专家+1个共享专家)中选择top 9个,并且始终将第9个专家设置为共享专家。通过进一步调整这9个选定专家的聚合权重,我们可以得到与优化前的MoE层完全相同的输出结果。
这里的意思是,在原始的Deepseek V3/R1 MoE forward代码中:
def forward_normal(self, hidden_states: torch.Tensor) -> torch.Tensor:
if self.n_shared_experts isnotNone:
shared_output = self.shared_experts(hidden_states)
# router_logits: (num_tokens, n_experts)
router_logits = self.gate(hidden_states)
final_hidden_states = (
self.experts(hidden_states=hidden_states, router_logits=router_logits)
* self.routed_scaling_factor
)
if shared_output isnotNone:
final_hidden_states = final_hidden_states + shared_output
if self.tp_size > 1:
final_hidden_states = tensor_model_parallel_all_reduce(final_hidden_states)
return final_hidden_states
普通的experts的计算结果需要乘以 self.routed_scaling_factor ,为了把shared expert融合到普通的expert中一起计算,我们需要在grouped_topk模块中把top9也就是shared experts对应的topk_weights提前除一下这个self.routed_scaling_factor 参数,这样就可以保证数值等价,请看下面的关于grouped_topk中的修改。
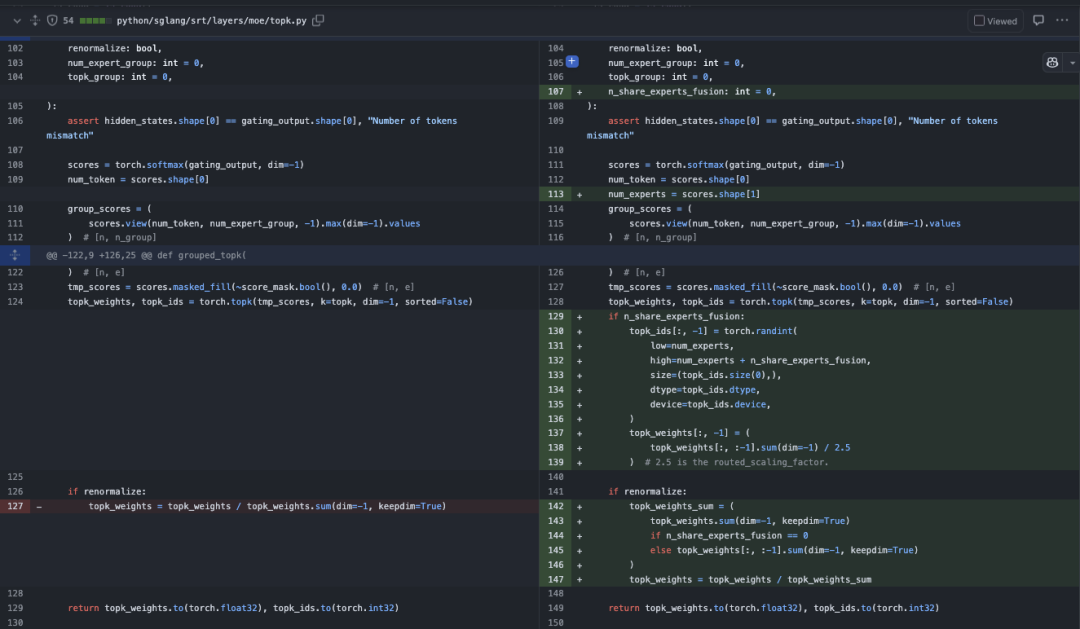
0x3. 实现细节
除了上面提到的为了保持数值等价做的Topk weights的系数修改之外,我们还可以观察到我们始终将所有token的第9个专家分配给共享专家,并且这里的共享专家可能还不止一个。对应这行代码:
topk_ids[:, -1] = torch.randint(
low=num_experts,
high=num_experts + n_share_experts_fusion,
size=(topk_ids.size(0),),
dtype=topk_ids.dtype,
device=topk_ids.device,
)
之所以设定多个共享专家,原因可能是可以对token做一个类似负载均衡的策略,防止一个共享专家分配到所有的token导致Expert间的token数差距过大导致计算效率低的问题。
我tuning并Benchmark了一下不使用任何额外复制的shared experts的情况,发现这种情况的性能确实比使用tp_size个shared experts复制的情况要糟糕,TTFT甚至会延长。具体可以看这里的benchmark数据:https://github.com/sgl-project/sglang/pull/4918
要支持复制多个shared experts要修改一下DeepseekV2ForCausalLM类的load_weights函数:
if self.n_share_experts_fusion != 0:
weights_list = list(weights)
weights_dict = dict(weights_list)
suffix_list = [
"down_proj.weight",
"down_proj.weight_scale_inv",
"gate_proj.weight",
"gate_proj.weight_scale_inv",
"up_proj.weight",
"up_proj.weight_scale_inv",
]
names_to_remove = []
for moe_layer in tqdm(
range(
self.config.first_k_dense_replace,
self.config.num_hidden_layers,
self.config.moe_layer_freq,
),
desc=f"Cloning {self.n_share_experts_fusion} "
"replicas of the shared expert into MoE",
):
for num_repeat in range(self.n_share_experts_fusion):
for suffix in suffix_list:
weights_list.append(
(
f"model.layers.{moe_layer}."
f"mlp.experts."
f"{self.config.n_routed_experts + num_repeat}"
f".{suffix}",
weights_dict[
f"model.layers.{moe_layer}.mlp.shared_experts.{suffix}"
].clone(),
)
)
names_to_remove += [
f"model.layers.{moe_layer}.mlp.shared_experts.{suffix}"
for suffix in suffix_list
]
weights = [w for w in weights_list if w[0] notin names_to_remove]
这里还把原始权重中每一层多余的那个shared expert的权重给移除了。
其它还有需要的注意的细节是由于expert个数有变化,所以还需要使用tuning fused moe脚本来针对tuning一下。此外,相比于原始的非fuse实现版本,每个tp rank上的显存会增加,对于FP8 dtype来说,一个rank上新增一个shared expert。一个shared expert 按照FP8 dtype折算为42MB内存(总参数量 = hidden_size moe_intermediate_size * 3 = 7168 * 2048 * 3),然后(51-3)*42MB=2016MB/1024=1.96GB。也就是说这个优化将在TP Rank上多使用1-2GB的内存才可以获得最佳性能收益。
另外,这个优化在fused moe gate的加持下会更有用一些,期待后续进展。
———————————————-分割线———————————————–
打扰了,补充一下,如果读者还有购买我家种的米易枇杷的需求可以点这个链接:攀枝花米易枇杷
(文:GiantPandaCV)