

今天是2025年4月3日,星期四,北京,天气晴。
先看一个关于大模型评测的事儿,有个大模型测试《Large Language Models Pass the Turing Test》(https://osf.io/jk7bw,https://arxiv.org/pdf/2503.23674,https://turingtest.live),评估了四个系统(ELIZA、GPT-4o、LLaMa-3.1-405B和GPT-4.5),参与者需要在五分钟内与一个人类和一个AI系统进行对话,也就是每组参与者完成8轮对话,每轮对话中,一名评审员与一名人类和一名AI同时交流,并判断哪个是真正的人类。
设计了两种提示类型,无提示(NO-PERSONA)和有提示(PERSONA)。无提示提示仅包含基本的参与指导和信息,而有提示提示则包含了更详细的角色扮演指令,例如采用一个内向且熟悉网络文化的年轻人的角色。
结果呢很有趣,73%参与者将其误认为人类,远高于真人对照组的50%识别率,有趣的是,其发现,“人设提示”是关键因素,无人设时GPT-4.5胜率骤降至36-38%,添加人设后模型能展现内向性格、使用俚语和适当犯错,进而推出识别AI最有效方法是测试异常反应和探索知识盲区,而非闲聊日常或询问情绪体验,因为参与者也主要依赖语言风格和交互动态来判断AI的真实性。所以,测试是门艺术。
我们继续回到技术问题,这次是RAG和语音识别。
一个是RAG用于视频文章生成的方案WIKIVIDEO,其实现思路的核心也是对整个task-flow的设计,论文,就是如此。
另一个是面向语音识别的开源方案,尤其是针对支持东亚、南亚、东南亚和中东等东方语言,支持中国方言,如执行语音识别、语音活动检测(VAD)、分段和语言识别(LID)等功能,这些其实都是做数字人等应用的基础。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、RAG用于视频文章生成的方案WIKIVIDEO
RAG进展,用来做视频文章生成。从多个视频自动生成维基百科风格文章,也就是给定一个关于真实世界事件的请求、一个查询问题以及一组相关的视频,系统需要从视频内容中生成一篇文章,所有声明都必须基于视频的视觉、音频和/或OCR内容。
因此,可以看看这个工作,《WIKIVIDEO: Article Generation from Multiple Videos》,https://arxiv.org/pdf/2504.00939,提出了一种方案,通过迭代交互的方式,结合视频语言模型(VideoLLM)和基于文本的推理模型,从多个视频中提取信息并生成文章,代码在https://github.com/alexmartin1722/wikivideo,现在项目代码没开源,但可以看到数据集,在https://huggingface.co/datasets/hltcoe/wikivideo。
核心还是看两点。
一个是WIKIVIDEO数据集的构建过程。
WIKIVIDEO数据集基于MultiVENT 1.0和MultiVENT 2.0视频,并与MegaWika2数据集中的维基百科文章链接,包括五个步骤:

初始事件和文章选择,选择具有英语视频和相关联的英文维基百科文章的事件->文章声明分解,将维基百科文章中的每个句子分解为一组上下文化、原子子声明。->声明纠正,专家标注人员手动纠正分解的子声明,确保其原子性和对原文的忠实性。->声明归一化,将纠正后的子声明归一化,并在相关视频中标注每个子声明的支持情况(视觉、音频或OCR)。->文章重写,根据归一化的子声明及其对应的视频,重写维基百科文章,确保文章仅包含视频支持的信息。
最终数据集包含52个事件和近400个相关视频,每个事件都有专家撰写的参考文章。
一个是CAG方法的核心组件以及实现方式
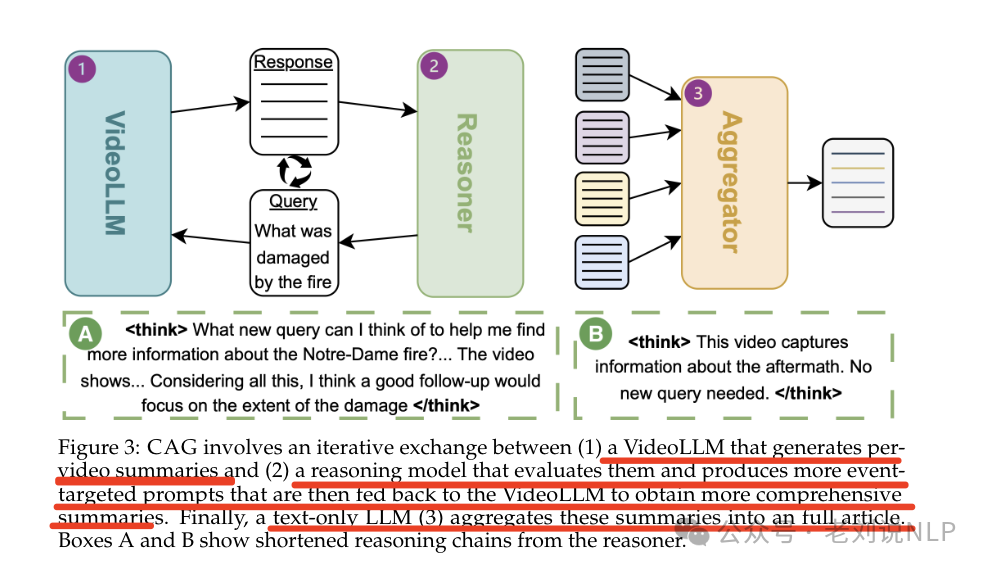
具体实现上,涉及三个核心组件VideoLLM、基于文本的推理模型以及纯文本LL。首先,VideoLLM生成每个视频的通用摘要,提供低级别的场景描述和突出的屏幕文本。其次,推理模型根据查询和初始摘要提供相关性反馈。

如果推理模型认为初始摘要不足,它会生成新的提示请求VideoLLM生成更高级别的信息。这个过程是迭代的,直到推理模型对摘要满意为止。最后,使用VideoLLM生成的通用摘要和推理模型提供的重新提示摘要来生成最终文章。
在实验中,使用多种VideoLLMs,如LLaVA-Video-72B、VAST、InternVideo2.5-8B和QwenVL2.5-72B。推理模型使用DeepSeek-R1蒸馏的Qwen-32B,纯文本LLM使用Qwen2.5。
二、面向东方语言的语音大模型开源方案
关于小语种识别,尤其是东方语言的识别,如越南语、缅甸语等,其实是一个刚需。
例如,最近的工作《Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages》,https://arxiv.org/abs/2503.20212,开源了一个支持东方40个语种的语音识别模型,着实是不错的,具体语种在:https://github.com/DataoceanAI/Dolphin/blob/main/languages.md。
在模型功能方面,支持东亚、南亚、东南亚和中东的40种东方语言,同时还支持22种中国方言,中文语种支持22方言(含普通话),可以执行语音识别、语音活动检测(VAD)、分段和语言识别(LID)。
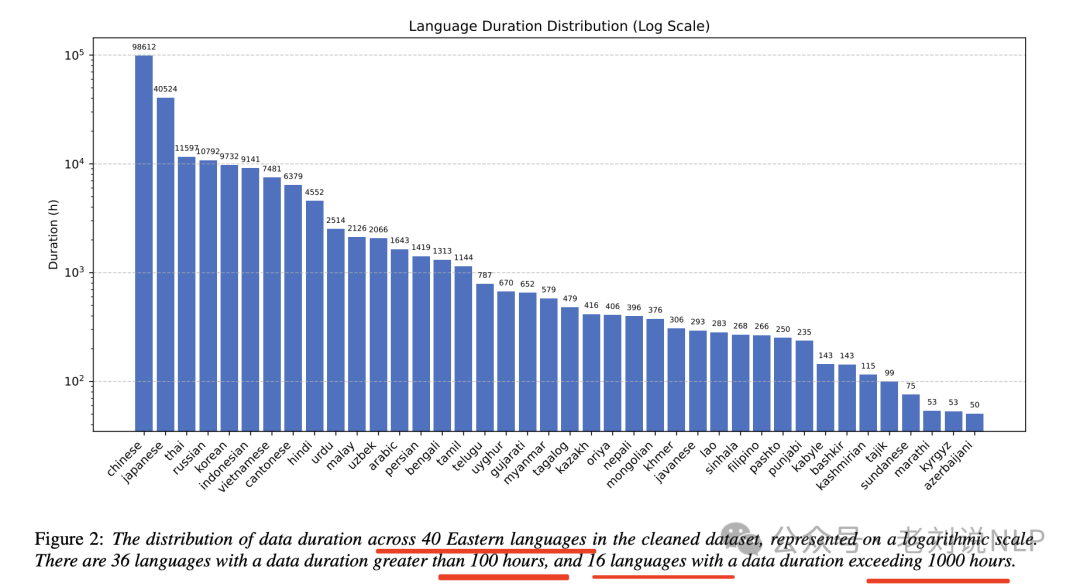
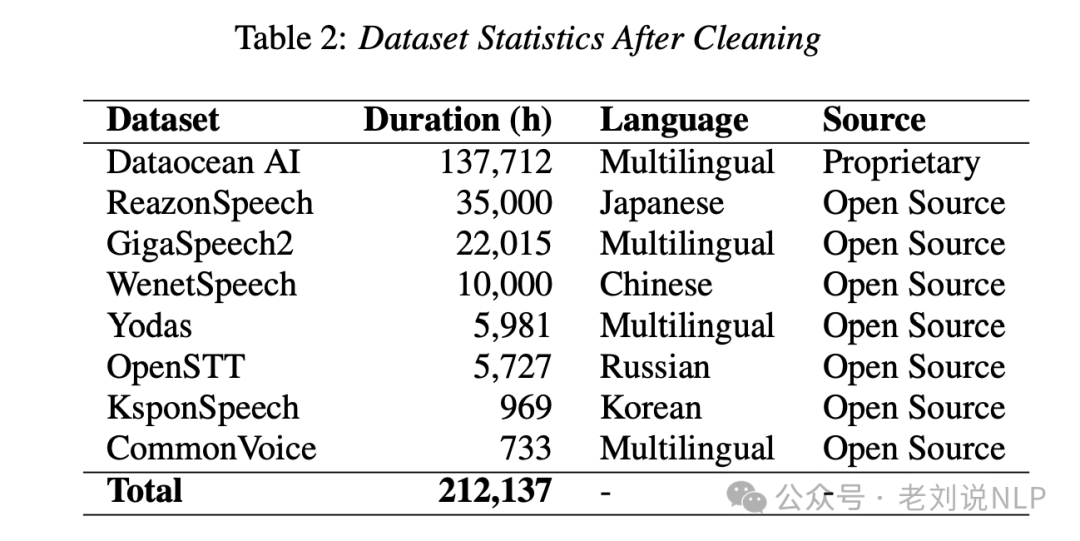
在训练数据方面,总时长21.2万小时,其中海天瑞声高质量专有数据13.8万小时,开源数据7.4万小时;同尺寸比whisper更好。
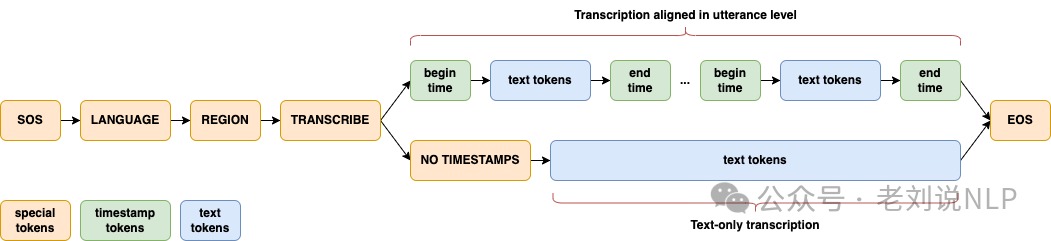
在模型设计方面,Dolphin在很大程度上沿用了Whisper和OWSM的设计方法,采用了联合CTC-Attention架构,编码器基于E-Branchformer,解码器基于标准Transformer。也针对ASR进行了多项关键修改,因为不支持翻译任务,并且不再使用先前的文本及其相关标记,但有一个重大改进是引入了两级语言标记系统,以便更好地处理语言和地区多样性,尤其是在DataoceanAI数据集中。第一个标记指定语言(例如,<zh>,<ja>),而第二个标记表示地区(例如,<CN>,<JP>)
在使用方面,Dolphin需要FFmpeg将音频文件转换为WAV格式。
import dolphin
waveform = dolphin.load_audio("audio.wav")
model = dolphin.load_model("small", "/data/models/dolphin", "cuda")
result = model(waveform)
# Specify language and region
result = model(waveform, lang_sym="zh", region_sym="CN")
print(result.text)
在下载地址方面,可以看Github:https://github.com/DataoceanAI/Dolphin,Huggingface:https://huggingface.co/DataoceanAI ,Modelscope:https://www.modelscope.cn/organization/DataoceanAI
参考文献
1、https://arxiv.org/pdf/2504.00939
2、https://arxiv.org/abs/2503.20212
(文:老刘说NLP)