

AI发展已抵达关键的“中场时刻”!上半场是“能力构建”时代,核心范式是模型驱动的“解题刷榜”,在预设基准上比拼分数,如同竞技体育,催生了Transformer、GPT-4等强大“运动员”。但现在,一个融合语言、规模、推理的“超级配方”让AI能力剧增,单纯“刷榜”已陷入内卷,边际价值递减。下半场规则巨变,进入“价值创造”时代,新范式是“出题定义价值”:焦点转向设计新的评估“赛道”,拷问AI在真实世界的效用,解决“实验室超神,现实乏力”的效用难题。未来属于能“出题”——即定义问题、设计评估、引导方向——并将智能转化为可靠产品的玩家。评估创新,正成为新的胜负手!
(本文核心观点源自AI研究者Shunyu Yao的洞察。Yao博士毕业于普林斯顿大学NLP组,曾在OpenAI、UC Berkeley等机构研究,现于Anthropic致力于强化学习与智能体研究,是ReAct、Tree of Thoughts等重要论文的作者,对语言智能体和AI前沿趋势有深刻见解。)
AI的中场哨声响起
我们正站在人工智能发展的历史性岔路口。过去几十年的AI征程,好比一场激动人心的球赛上半场。这场比赛的核心是“解题刷榜”:不断训练更强大的模型(如同培养更强的运动员),让它们在各种预设的标准化“赛场”(基准测试)上,一次次打破记录。从深蓝击败卡斯帕罗夫,到AlphaGo战胜李世石;从GPT-4等大语言模型(LLM)在SAT、律师考试中取得高分,到o-series模型在IMO、IOI竞赛中摘金夺银。这些辉煌成就,都是上半场“更高、更快、更强”理念的胜利,背后是搜索、深度强化学习(Deep RL)、规模化法则以及推理能力等核心训练方法的持续精进。
但现在,裁判吹响了中场哨。游戏规则,似乎正在发生根本性的改变。
转折点在哪里?一个关键信号是:曾经像难以捉摸的天才球员一样的强化学习(RL),在LLM的加持下,终于学会了“阅读比赛”、实现了“泛化”,使得能够执行复杂任务的通用智能体(Agent)成为可能。一个融合了大规模语言模型(提供世界知识与理解力)、庞大数据与算力(提供体能基础)以及“推理即行动”(提供战术思维)的“超级配方”悄然成型。这个配方,让AI Agent展现出在软件工程、创意写作、科学发现、复杂人机交互等广阔领域解决问题的惊人潜力。
LLM不再仅仅是强大的语言模型,它成为了构建通用Agent智能的基石与大脑。
这意味着什么?AI的下半场,聚光灯将从上半场的“如何让模型解题更快、分数更高?”转向下半场的“我们应该让AI解决哪些真正有价值的问题?如何设计新的‘比赛’来衡量这种价值?”。焦点从单纯的“解题能力”提升,转向了更根本的“出题能力”——即定义问题、设计评估场景、引导发展方向的能力。在这个新阶段,“评估”(Evaluation)的设计与创新,其战略重要性将历史性地超越“训练”(Training)本身。我们需要像一位既懂运动员(模型)潜力,又懂比赛规则(评估)和观众需求(价值)的总教练兼赛事设计师那样去思考。
上半场的回响:“解题刷榜”驱动的能力构建时代
回顾AI的上半场,其核心范式是“方法/模型驱动,基准验证”。如同竞技体育的发展,重心在于发明新的训练方法(算法/架构)和提升运动员(模型)的基础能力,并通过在标准场地(基准)上的表现来衡量进步。
Transformer、AlexNet、GPT-3等里程碑,都是提供了更强“训练方法”或“运动员天赋”的基础性突破。它们之所以获得巨大成功和引用,是因为它们在ImageNet、WMT’14等公认的“赛场”上显著提高了“比赛成绩”。但正如体育史上人们更关注博尔特而非他跑过的跑道,学界和业界真正追捧的是这些方法和模型本身,而非它们跑赢的基准。ImageNet的引用远不及AlexNet,WMT’14的引用远不及Transformer,这清晰地揭示了上半场的重心:提升解题能力是目标,刷榜是手段,方法/模型创新是核心驱动力。
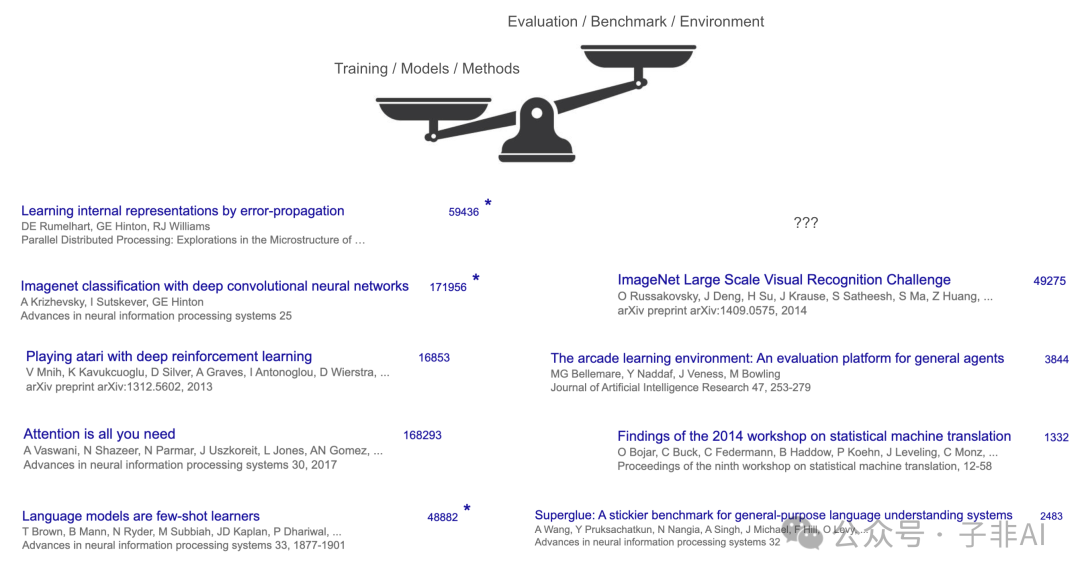
图1: 上半场的重心:方法/模型论文(如AlexNet, Transformer)的引用量远超其使用的基准(如ImageNet, WMT’14),体现了以提升“解题能力”为核心的范式。
这个范式在上半场卓有成效,因为它符合当时AI能力尚弱的现实。基础能力的提升(更强的感知、理解、生成)自然能带来一定的应用价值。但随着“超级配方”的出现,这个范式正逼近其天花板,甚至陷入“内卷”。
转折点:“超级配方”如何颠覆“解题刷榜”游戏
这个“超级配方”的诞生,不仅是技术的融合,更是对强化学习(RL)核心要素——算法(Algorithm)、环境(Environment)和先验知识(Priors)——认知优先级的深刻颠覆。正是这种认知的转变,让“解题刷榜”的旧范式难以为继。
1. RL三大支柱的认知变迁与优先级反转:
-
•曾以为“算法”是关键:早期RL研究者如同寻找终极训练秘籍的教练,专注于优化学习算法本身(如Q-learning, PPO等),希望能找到一套万能策略让智能体学得更快更好(Sutton & Barto的教科书是这个时代的缩影)。 
图2: 经典RL教科书侧重算法,但这只是故事的一部分。 -
•后发现“环境”很重要:深度RL时代,人们发现训练场地(环境)的真实性和复杂性极大影响训练效果(如OpenAI Gym、Universe的探索)。但如同只在标准场地上训练的运动员,智能体仍难以适应真实多变的赛场,泛化能力差(如Dota、魔方成果难迁移)。 -
•终领悟“先验”定成败:直到大规模语言模型(LLM)的崛起,才揭示了被长期忽视的“秘密武器”——先验知识(Priors)。LLM通过预训练学习了海量的语言和世界知识,如同给智能体注入了“天赋”和“球商”。WebGPT、ChatGPT的成功证明,强大的先验知识是通往通用智能的关键基础。 -
•点睛之笔:“推理”激活先验:光有天赋还不够,还需要“战术意识”。“推理即行动”(Reasoning as Action, 如ReAct)机制,允许Agent利用LLM的推理能力进行“思考”、规划和反思,有效地将先验知识应用于具体的行动决策中。这解决了“有知识却不会用”的难题,是实现复杂任务泛化的关键。(早期基于GPT-2的文本游戏智能体CALM,因缺乏有效推理,即使有LLM先验也学习缓慢、难以泛化,反衬出推理的重要性。) 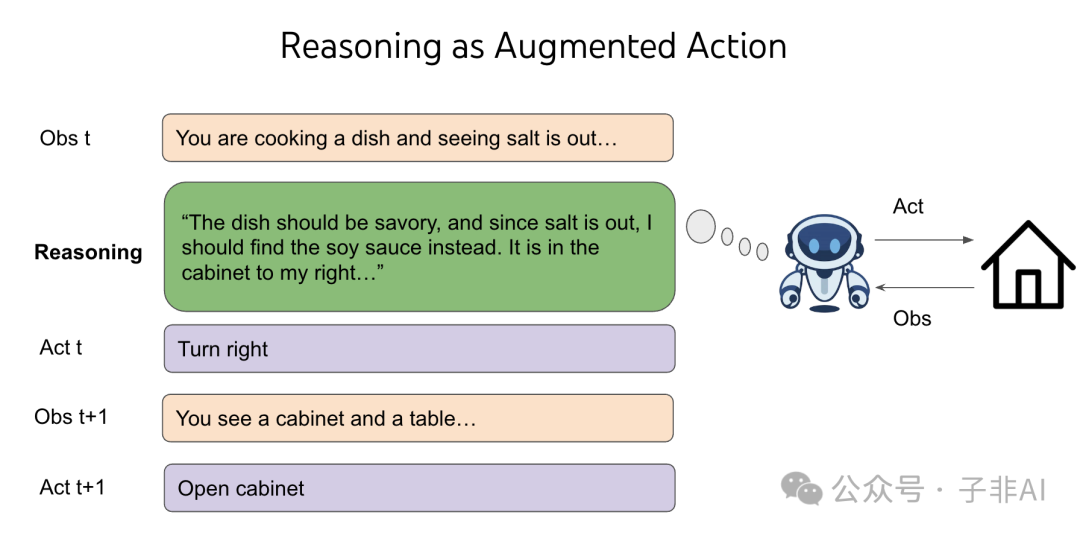
图3:推理即行动:Agent通过生成思考步骤(Thought)来利用LLM的先验和推理能力,指导其后续行动(Action),实现更复杂的任务。
2. 优先级反转的讽刺与现实:当这三大要素——强大的先验(来自LLM)、允许推理的交互机制、以及规模化基础——结合,能够执行复杂任务的Agent智能便呼之欲出(如o-series, R1)。这时,一个具有讽刺意味的结论浮现:曾经被认为是核心的RL算法,其相对重要性似乎下降了。我们可能花了数十年才意识到,要素的重要性排序或许应该是:先验知识 >> (包含推理的)环境交互 >> 算法。
3. 从LLM到Agent:一体两面,重心转移:这个“超级配方”的成熟,意味着LLM的价值不再仅仅是作为一个独立的语言模型存在,而是作为构建更通用、更有行动能力的Agent智能的核心引擎。Agent是LLM能力向现实世界延伸、产生交互和行动的载体。因此,仅仅在传统NLP基准上评估LLM本身的“解题”能力已显不足,真正的考验在于评估由它驱动的Agent在解决实际问题中的表现。
这个配方的成熟,使得在旧基准上“刷榜”变得相对容易,其挑战性和创新驱动力自然下降。AI研究的重心,不可避免地开始转向如何更好地应用、评估和引导这种新兴的Agent智能。
下半场的号角:“出题定义价值”的新赛道
既然“超级配方”让基础能力足够强大,甚至让“解题刷榜”陷入内卷,下半场的核心任务就是转换范式,开辟新赛道:从“解题”转向“出题”,从追求分数转向“定义价值”。这意味着:
1. 直面“效用难题”(Utility Problem):这是新赛道必须解决的核心问题。AI在“标准考试”(基准)中屡创佳绩,但在“社会实践”(真实世界应用)中却常常表现平平,未能带来预期的生产力革命。这种“高分低能”现象,正是旧范式过度关注“解题刷榜”而忽视真实价值的后果。
2. 以“出题”思维重塑“评估”(Evaluation):解决“效用难题”的关键,在于用“出题”的思维去彻底改造“评估”。这里的“出题”,不是让AI出考试题,而是指我们(人类研究者、产品经理、社会)要主动设计出能够衡量AI真实价值的新型“考场”和“考试科目”。这需要打破思维惯性(Inertia),不再满足于在旧题型上增加难度(如从MMLU到更难的AGI Safety Bench,或从简单编程到更难的SWE-bench),而是要创造全新的评估“设定”(Setups)。
现有评估设定(旧赛道规则)的两大典型弊端:
-
•弊端一:“无菌环境” vs. “真实交互”。多数评估如同在无干扰的实验室进行,自动、非交互式。但现实世界充满互动和不确定性。我们需要能够评估Agent在与人、与环境的动态交互中表现的新评估(如Chatbot Arena的人类偏好反馈,或tau-bench的复杂用户模拟)。 
图5:交互式评估探索:Tau-Bench等框架尝试通过模拟用户交互,更真实地评估Agent在动态、多轮任务中的表现,挑战“无菌环境”评估。 -
•弊端二:“单点快照” vs. “连续学习与记忆”。评估通常假设任务独立同分布(i.i.d.),每次都是“新游戏”。但现实中学习和工作是连续的,需要积累经验、形成记忆。我们需要能评估Agent长期记忆、持续学习和适应能力的新框架,勇敢挑战i.i.d.假设(相关长期记忆研究如此项和彼项正需要这样的新评估来驱动)。
为何现在必须“出题”?因为在上半场,提升基础“解题”能力就能带来价值。但现在,“超级配方”在旧“考场”上已过于强大,继续“卷”旧题型无法引导AI发展出解决现实复杂问题的能力。只有通过“出题”——设计出更贴近真实价值的新评估“赛道”——才能迫使AI(及其背后的研发力量)去发展真正需要的新能力,超越当前“秘方”的舒适区。
下半场的新游戏规则(“出题定义价值”范式):
-
1.设计新赛道:从真实需求出发,开发反映实际效用的、新颖的评估设定或任务。(出题) -
2.选手上场:利用现有“秘方”(或对其进行改进)让Agent在这些新赛道上接受考验。 (应题) -
3.裁判打分并反馈:新评估的结果直接暴露Agent的短板,指导下一代LLM和Agent方法的研发方向。(以评促建) -
4.迭代升级:持续优化赛道(评估)和选手(模型/方法),在这个循环中不断逼近真实价值。
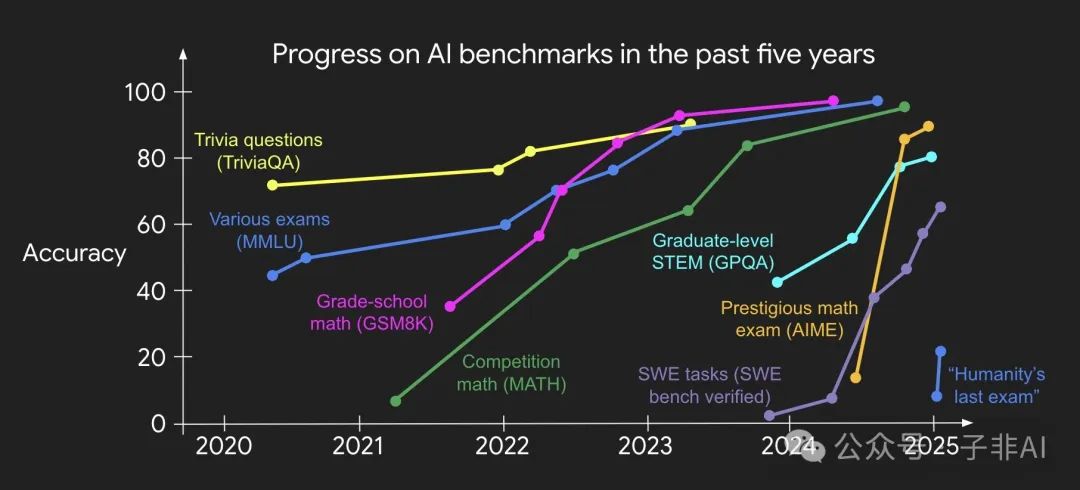
图4: AI进展加速,基准饱和加快。这并非终点,而是“中场休息”的信号:是时候从“解题刷榜”转向“出题定义价值”的新赛道了。
欢迎来到激动人心的AI下半场!
AI下半场的征程,无疑将更加崎岖,因为它要求我们从熟悉的“解题”舒适区走出,进入充满未知的“出题”无人区。但也正因如此,它才更加激动人心,因为它直接指向创造真实、可靠、普惠的AI价值。
上半场的英雄是那些在“解题刷榜”中登峰造极的模型架构师和算法工程师。而下半场的领军者,将是那些具备“出题”智慧——能够洞察真实需求、定义有价值的问题、并设计出科学评估体系的“产品思想家”、“评估科学家”和“价值定义者”。他们将通过构建真正有用、值得信赖的AI Agent,开启一个AI深度赋能各行各业的新纪元。
强大的“超级配方”既是基础,也是“过滤器”。它会加速淘汰那些在旧范式下修修补补的增量创新。只有那些敢于拥抱新范式,以“出题定义价值”为导向,从评估创新出发,直面并解决真实世界难题的研究和应用,才能引领潮流,成为真正改变游戏规则的力量。
这不仅是一场技术的换挡,更是一场思维的革命。准备好迎接这场以价值定义和评估创新为核心的全新征程了吗?
欢迎来到AI的下半场!一个从“卷”模型到“出”价值的新时代!
推荐阅读
-
•The Second Half (Original Blog Post by Shunyu Yao):https://ysymyth.github.io/The-Second-Half/
(文:子非AI)