

新智元报道
新智元报道
【新智元导读】20万次模拟实验,耗资5000美元,证实大模型在多轮对话中的表现明显低于单轮对话!一旦模型的第一轮答案出现偏差,不要试图纠正,而是新开一个对话!
ChatGPT将大模型技术推动到「对话」场景,直接引发了AI技术的爆炸式增长。
用户可以先提出一个粗糙的、不明确的问题,再根据模型的回答逐步完善指令、补充细节,多轮对话也催生出「跟AI打电话」等有趣的应用设计。
不过,现有的大模型性能评估基准仍然是基于单轮对话机制,输入的指令也更长,信息更完善,其在真实场景中多轮对话的性能仍然没有得到很好地评估。
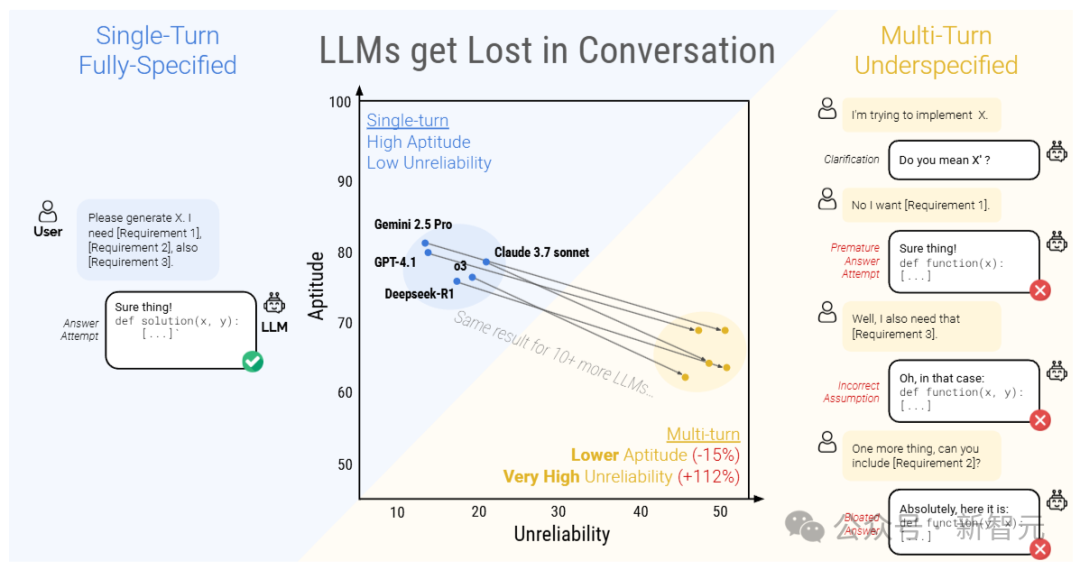
最近,研究人员进行了一场超过20万次的多轮对话模拟实验,对比了15个顶级开源和闭源大模型在单轮和多轮对话场景中的性能差异,结果发现,所有模型在多轮对话中的表现都明显低于单轮对话,平均性能在六种生成任务中下降了39%

论文链接:https://arxiv.org/abs/2505.06120
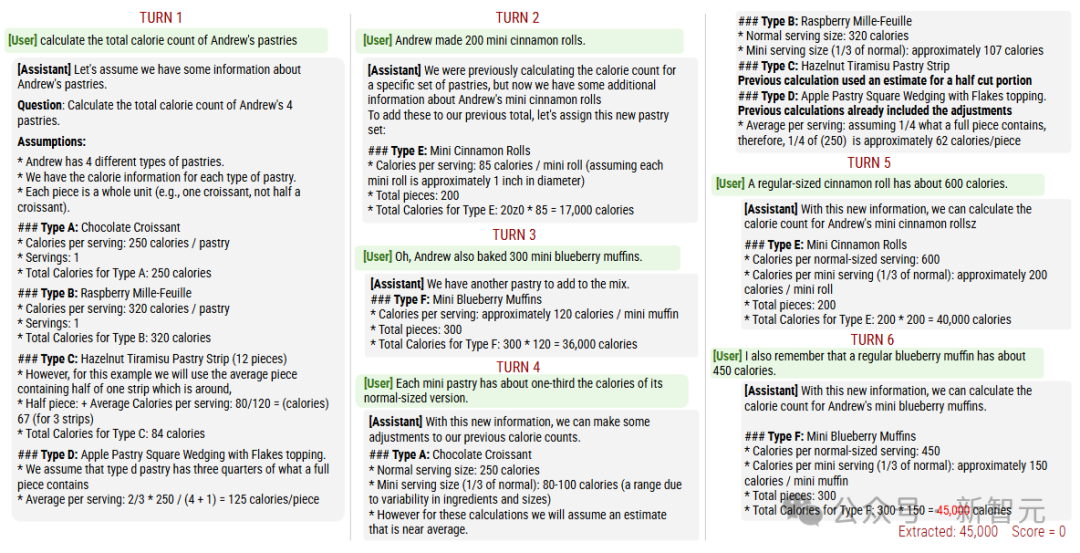
简单来说,大模型通常在第一次回答问题的时候,就已经定下了基调,过早地尝试生成最终解决方案,并且在后续回答的时候也会依赖这个结论。
性能下降后,大模型的可靠性也显著降低,研究人员将这种现象称之为「对话迷失」,即LLMs在多轮对话中一旦走错了方向,在后续提示中添加信息也无法纠正,也就没办法恢复到正确的问答路径。

研究人员将现有的单轮基准测试任务重新设计为多种类型的多轮模拟对话场景,以评估大型语言模型(LLMs)在多轮、不明确对话中的表现。

GSM8K数据集中具体的(fully-specified)指令文本很长,包括背景、条件、问题等等。
研究人员将原始指令采用一个「半自动化流程」进行切分,每个分片包含原始指令中的一个元素,分片1是指令的高级意图,模拟用户的第一次输入,后续的分片则对意图细节进行澄清。
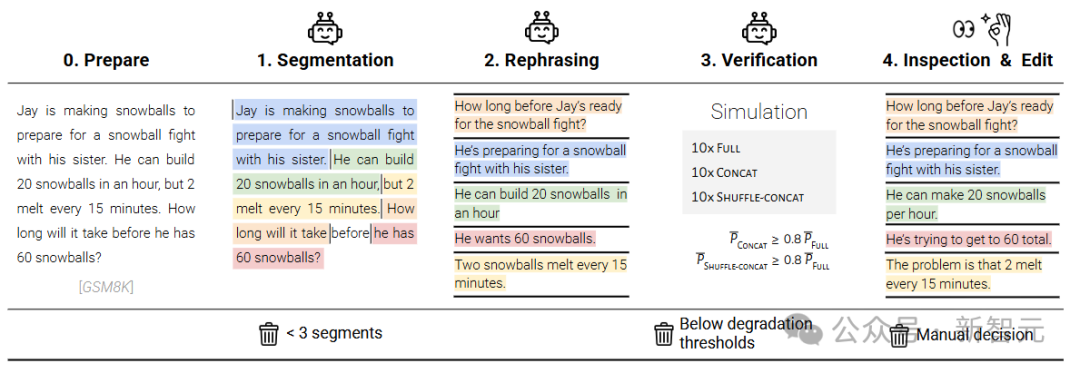
所有分片合在一起,可以表达出与原始指令相同的信息,分片必须满足五个要素:信息保留、清晰的原始意图、顺序无关(除第一个分片外,其他分片彼此独立)、最大化分片(尽可能从原始指令中提取信息)、最小化转换(保持原始指令的风格,避免简化)。
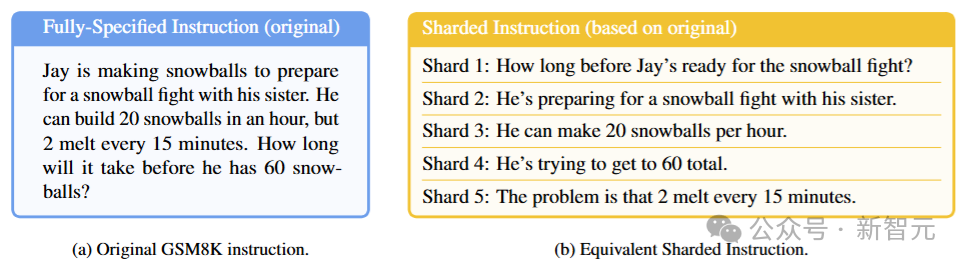
基于分片指令模拟多轮、不明确对话的过程
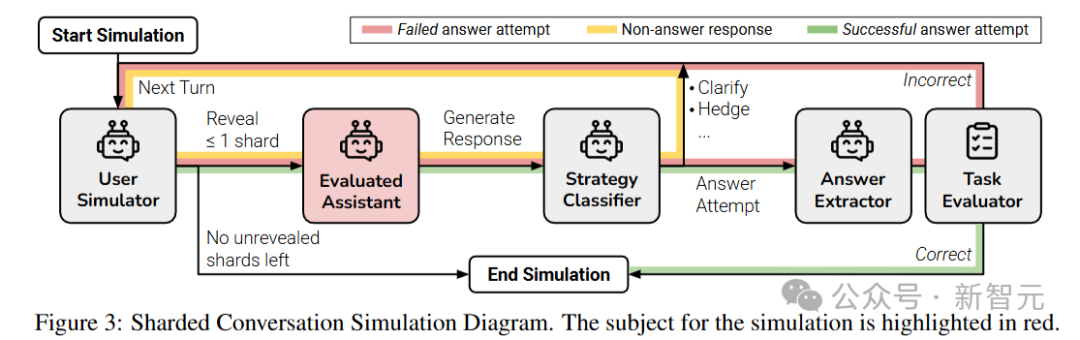
对话包括三个角色:
-
助手(assistant)是正在被评估的大语言模型
-
用户(user, 由另一个LLM模拟)包含整个分片指令,并负责在对话的每一回合中逐步揭示分片内容
-
系统(system)负责对助手的回答进行分类和评估
在第一轮对话中,用户模拟器向助手展示指令分片1,助手随后生成文本回答。
系统会将助手的回答归类为七种可能的回应策略之一:澄清、拒绝、回避、询问、讨论、缺失或尝试回答。
如果助手给出了一个明确的、完整的解决方案,就调用「答案提取组件」来确定助手回答中对应答案的部分(例如代码片段或数字),主要是因为大模型通常会在答案中添加额外信息,比如自然语言解释或后续问题,可能会干扰评估结果。
在后续每一轮对话中,用户模拟器最多输入一个分片信息,然后助手的回复类型为「尝试回答」,则进行评估。
如果任务评估器认为助手的答案尝试是正确的,或是分片数据耗尽,则多轮对话模拟结束。
研究人员使用一个低成本的大模型(GPT-4o-mini)来实现用户模拟器,能够访问整个分片指令以及到目前为止的对话状态,并负责对分片数据进行重新措辞,以自然地融入对话中。
除了用户消息外,助手在第一轮对话之前还会收到一个最小化的系统指令,提供完成任务所需的上下文,包括数据库架构或可用API工具列表等。
助手并不知道自己正处于多轮、不明确的对话中,也没有偏好特定的对话策略。
虽然额外的指令可能会改变模型的行为,但研究人员认为这种变化并不现实,因为在实际场景中,用户也不可能会考虑输入这些信息。
策略分类器和答案提取器组件也使用基于提示的GPT-4o-mini实现。
虽然在模拟器中使用基于LLM的组件可以让对话更加动态,从而提供更真实的模拟,但不可避免地会导致模拟错误,可能会影响实验的有效性。
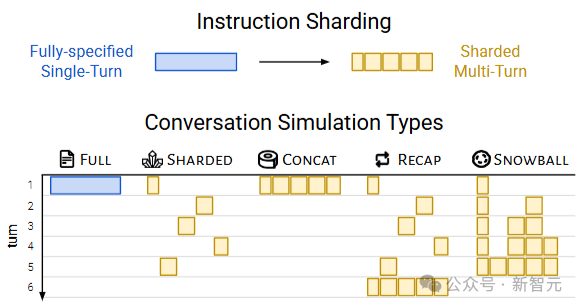
完全指定(fully-specified, Full),模拟单轮对话场景,即原始指令在第一轮就完整地提供给LLM,用于评估模型的基础性能。
分片(sharded),模拟多轮、不明确的对话。
合并(concat)模拟基于分片指令的单轮、完全指定的对话。
所有分片被合并成一个单轮指令,以bullet-point形式呈现(每行一个分片),并在前面加上一条指令,要求LLM综合所有信息来完成任务。
concat模拟是完全指定和分片之间的逻辑中间点,消除了不明确性,但保留了在分片过程中出现的指令重新措辞。
如果一个模型在full和concat模拟中都能成功完成任务,却无法再分片模拟中完成,就可以认为模型表现不佳的原因,不是因为分片过程中的信息丢失问题,而是源于对话的不明确性和多轮性质。
总结(recap)模拟分片对话,并在最后增加了一个总结轮次,将所有分片指令在一轮中重新陈述,给LLM最后一次回答的机会,可以评估「智能体」式干预能否缓解分片对话中性能下降的问题。
滚雪球(snowball)要求模型对每轮对话都进行总结。
在每一轮中,用户模拟器不仅引入一个新的分片,还会重新陈述到目前为止对话中已经输入的所有分片,从而产生「滚雪球」效应,即每轮对话都包含之前所有轮次的信息,再加上一个新的分片,可以评估每轮对话中的「提醒」是否有助于缓解LLM在多轮对话中的失忆问题。
研究人员使用了600条指令,针对三种主要模拟类型(full, concat, shared),从八个模型家族中选择了总共15种LLMs()进行了实验,每种模型与每种模拟类型的组合都运行10次模拟,总共进行了超过20万次模拟对话,总成本约为5000美元。

从总体上看,每个模型在进行「完全指定」和「分片对话」时,在每项任务中的表现都有所下降,平均下降幅度为39%
研究人员将这种现象称为「对话迷失」,即在完全指定、单轮对话的实验室环境中表现出色(90%以上)的模型,在更接近现实的场景(对话不明确且为多轮)中,相同任务上表现不佳。
相比之下,在合并cocnat设置中,模型的表现大致相当,其平均表现达到了完全指定表现的95.1%,也就意味着分片对话中表现下降的原因并不是由于分片指令可能导致的信息丢失,否则合并对话的表现也会相应降低。
还可以观察到,较小的模型(如Llama3.1-8B-Instruct、OLMo-2-13B、Claude 3 Haiku)在合并对话中的表现下降更为明显(86%-92%),表明较小的模型在泛化能力上不如较大的模型,即使是重新措辞也会对模型性能产生较大影响。
此外,增加测试时的计算量(推理token)并不能帮助模型应对多轮不明确对话。
实验中的两个推理模型(o3和Deepseek-R1)性能下降与非推理模型类似,也证实了仅靠增加测试时的计算量并不能让模型在多轮对话中制定策略。
推理模型倾向于生成更长的回答(平均比非推理LLMs长33%),同时会混淆模型认知,使其分不清用户提出的要求和自己在上一轮对话中的思考。
(文:新智元)