



概况
双目立体匹配是计算机视觉中几十年来经久不衰的一个研究课题,其主要是从矫正的左右目图像中恢复稠密的匹配视差。进入深度学习时代后, 双目匹配的准确度和鲁棒性都得到了稳步的提高。
然而,现在模型仍然受到搜索准确的稠密匹配的一些固有难点的约束,如遮挡(在右图中匹配点没有直接展现),弱纹理/图像模糊/不良曝光(造成匹配难以准确定位),以及高分辨(往往伴随着大视差,需要很大搜索范围)。
最近,深度估计领域的的一个相关任务 – 单目相对深度估计获得非常大的提升。例如,Marigold [1] 和 Depth Anything V1 [2] 和 V2 [3] 在不同场景中实现了卓越的零样本泛化能力。其中 Depth Anything V2 [4] 是能够恢复非常好的场景结构细节,且相比与基于 Stable Diffusion 的 Marigold [5] 具有显著更快的速度。
因此,为了能够利用单目深度基础模型提供的强大的单目先验用于双目匹配,本文设计了将 Depth Anything V2 [6] 循环双目匹配框架 RAFT-Stereo [7],从构造出了新的双目匹配模型 DEFOM-Stereo。
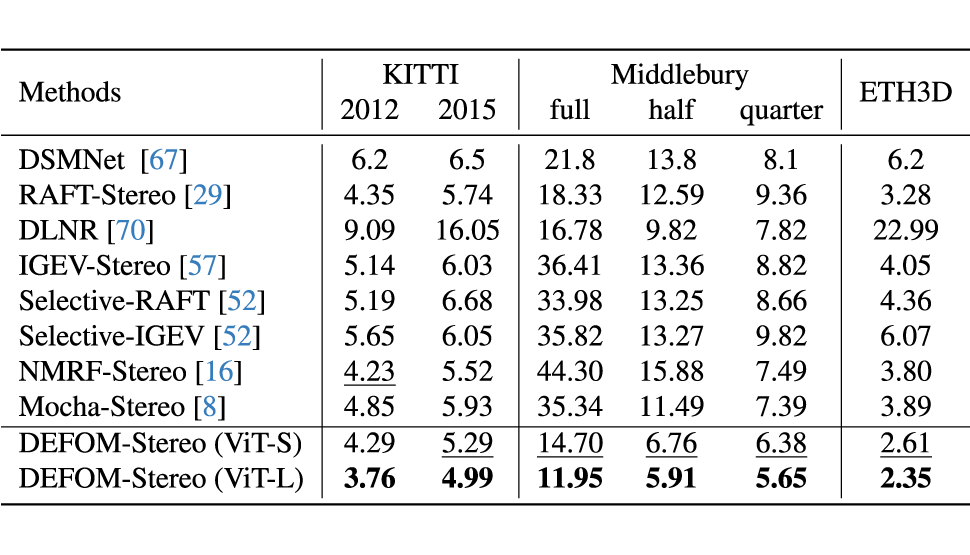
在仿真域到真实域的 Zero-Shot 综合评估上,DEFOM-Stereo 相比于其他双目模型具有显著的优势。此外,在双目领域的权威在线 Benchmarks 上,包括 KITTI,Middlebury 和 ETH3D 上,DEFOM-Stereo 均由众多指标排名第一。并且,在鲁棒视觉挑战(RVC)的联合评估设定下,我们的模型也能同时在各个子测试集上由于之前所有 RVC 模型。

论文标题:
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
论文地址:
http://arxiv.org/abs/2501.09466
项目主页:
https://insta360-research-team.github.io/DEFOM-Stereo/
代码开源:
https://github.com/Insta360-Research-Team/DEFOM-Stereo

方法框架
2.1 联合编码器
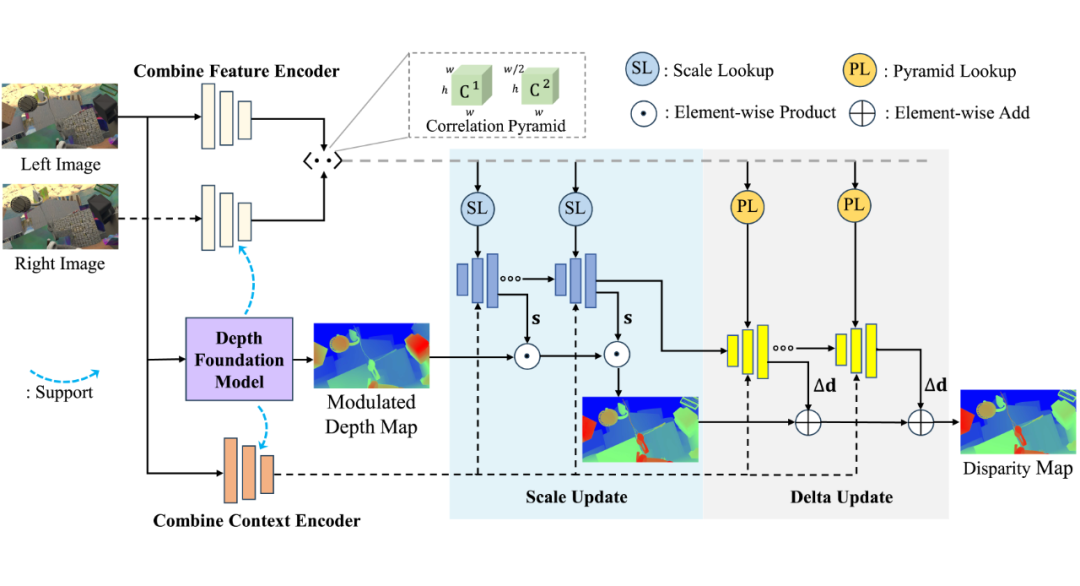
我们利用 Depth Anything V2 中的强大预训练 ViT 和随机初始化的 CNN 一起组成联合编码器,这样使得双目匹配网络中的特征提取更加有效。由于在循环双目匹配框架中,存在两个图像编码器:
1)匹配特征编码器,同时应用在左右图从而来计算像素点之间的相关性;
2)上下文提取器,只应用在左图来控制循环的视差迭代恢复过程。我们同时构建了组合特征提取器和组合上下文特征提取器。
2.2 单目视差初始化
为了利用 Depth Anything V2 估计的深度(实际上是仿射不变的视差)中的已经恢复的场景结构信息,我们将其估计的“深度”进行一定的幅度调整后,用于循环迭代视差的初始化。
虽然相对深度估计被设计成能够恢复仿射不变视差,即与真实视差只相差一个未知的线性变换。但我们在实测发现,即使是最先进的 Depth Anything V2,估计的”深度”图和真实的视差之间不能只用一个线性变换拟合,其估计的“深度”图的各个区域间存在一定的尺度不一致性,如下图所示。
此外,我们将 Depth Anything V2 估计的“深度”图经过仿射对齐到 GT 视差后,再进行视差误差计算,同样也产生非常大的误差。这些,都给后续的循环迭代视差恢复造成了一定的困难。

2.3 尺度更新
为了应对上述单目深度的尺度不一致现象,我们在原始的循环残差迭代更新前面插入了提出的一种尺度更新模块,这个模块以估计一个稠密的尺度因子图的,并以乘积形式更新迭代的视差图。
为了使稠密的尺度因子图恢复得更加准确,我们还设计了一种从相关体金字塔中进行尺度查找的方法。尺度查找主要是预设一系列尺度因子,乘以当前估计视差图获得一些列尺度视差图,再去相关体金字塔采样获取尺度相关特征。

实验结果
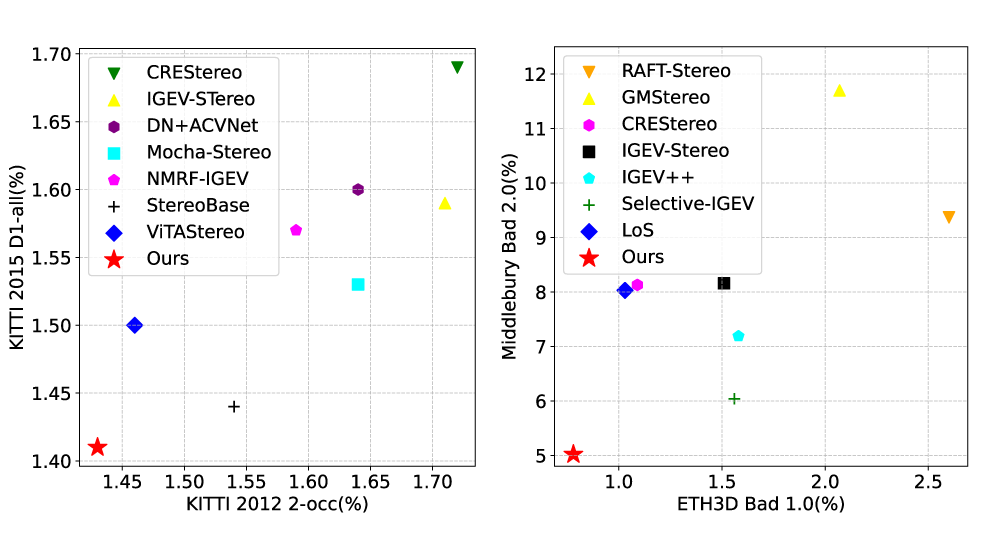
3.1 零样本泛化对比

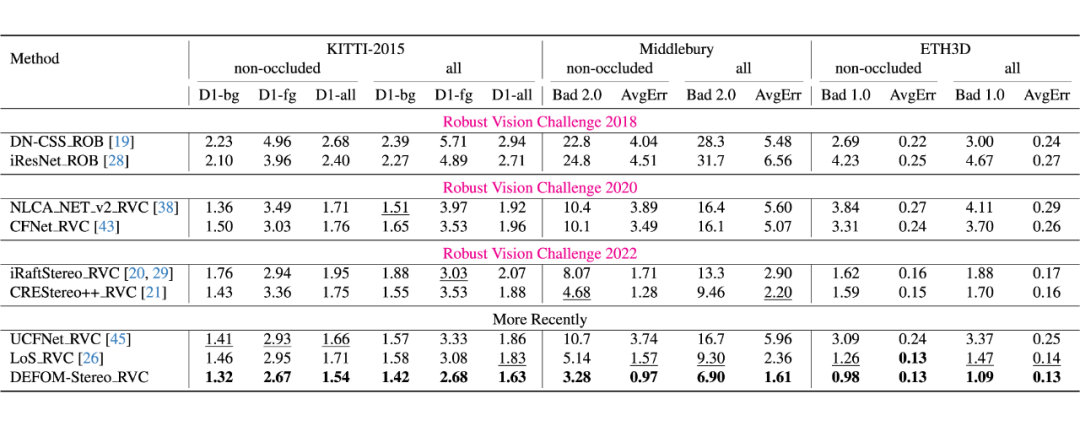
3.2 在线 Benchmarks
我们模型同时在 Middlebury,ETH3D,KITTI 2012/2015 上同时具有领先表现,同时在 RVC 联合评估也完胜其他 RVC 模型。





(文:PaperWeekly)