
源起于一位LM 研究生@kalomaze的爆料
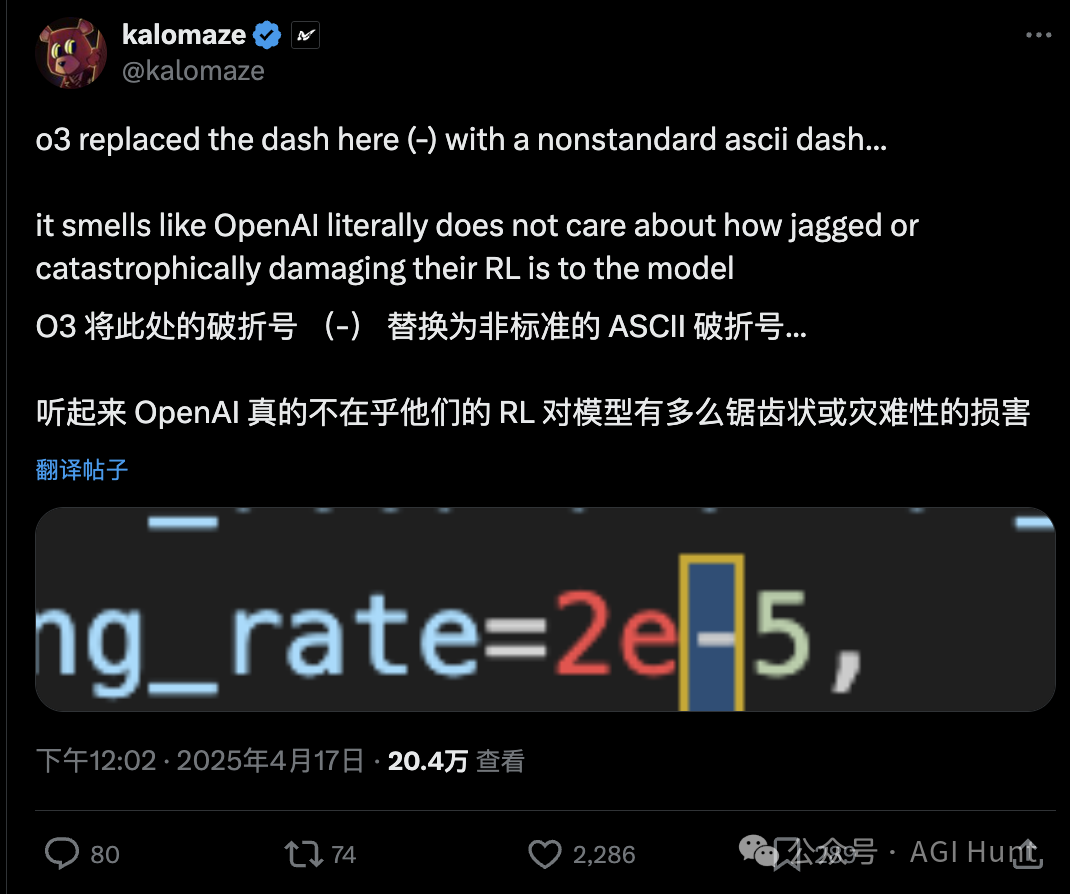
o3 玩起了奇葩Unicode符号

差点把他评估数学能力的代码搞崩了!

好(祸)事(不)成(单)双(行)
这位Princeton的PhD学生Kaixuan Huang
测试o3-mini在MATH-Perturb上表现时
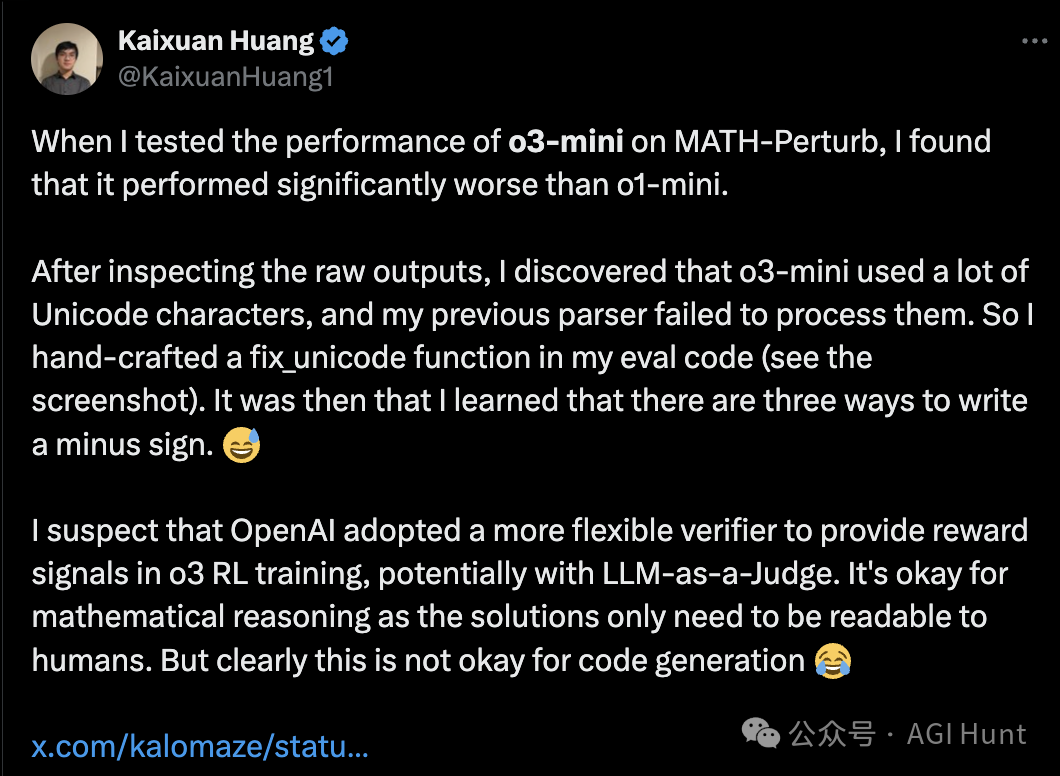
发现它远不如o1-mini那么靠谱
总是各种幺蛾子

一开始他还以为是模型真的变菜了
不过仔细检查了下代码,这才恍然大悟:
坏了,o3迷上了Unicode!
整段代码里那个2e−5的连字符
和标准ASCII的连字符根本不是同一个
仔细一看,真是醉了
o3模型居然用了另外两种连字符:
一种是en dash(–,U+2013)
一种是minus sign(−,U+2212)
都不是编程用的标准hyphen(-,U+002D)
可这都啥年代了,还有这种操作?!
这不就得加行代码修复嘛
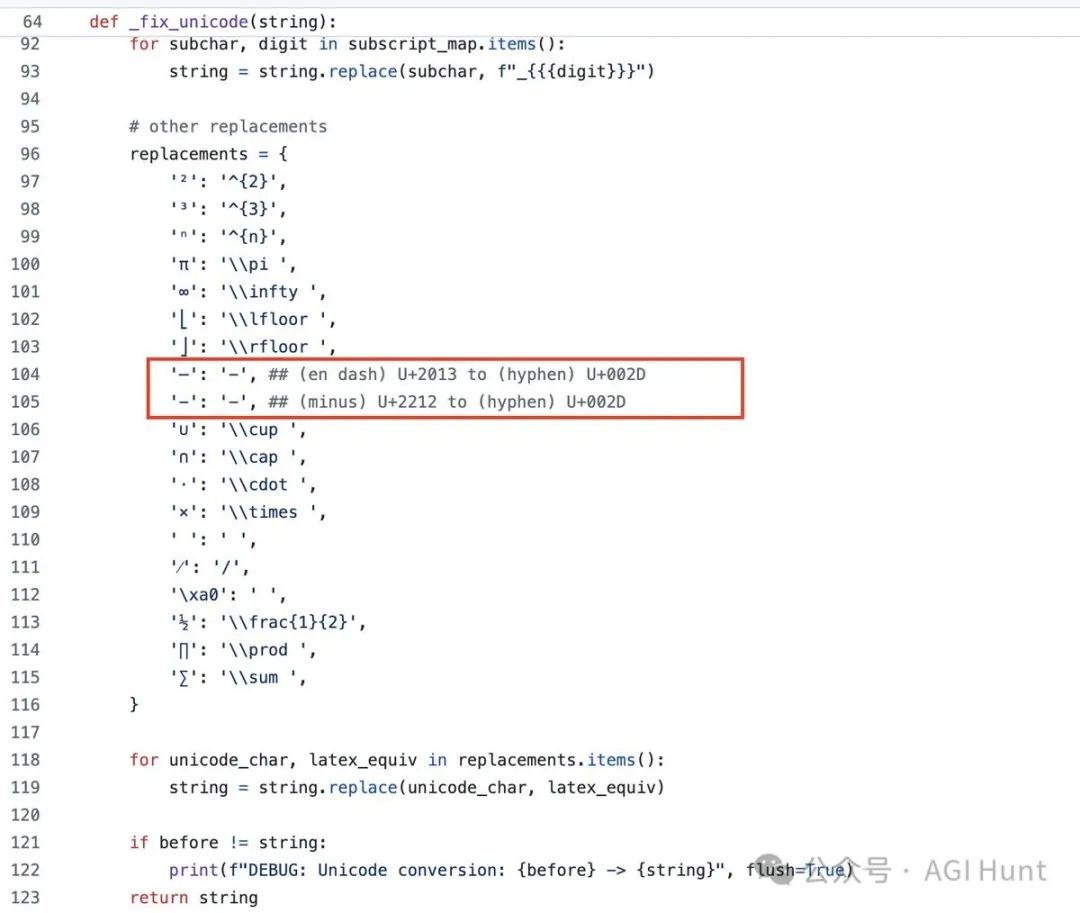
于是他不得不写了个 _fix_unicode函数
原地做了个符号修正才解了燃眉之急
Kaixuan Huang(@KaixuanHuang1) 指出这和训练方式有关:
当我测试o3-mini在MATH-Perturb上的性能时,发现它表现明显比o1-mini差。仔细检查原始输出后,我发现o3-mini使用了大量Unicode字符,我之前的解析器无法处理它们。于是我在评估代码中手工制作了一个fix_unicode函数(见截图)。这时我才了解到写减号有三种方式。😅
问题似乎越查越多
Kaixuan Huang 分析称:
难不成是OpenAI训练o3模型时
用了更灵活的验证器提供奖励信号?
可能是LLM-as-a-Judge给的反馈太宽松
这种宽松对数学推理其实没大问题
毕竟只要人类能看懂答案就行
但对代码生成来说就是灾难啊!
Jonathan Chang(@cccntu) 也同意这个观点:
似乎合理的流程是:输出 -> LLM解析答案 -> 奖励 这样模型获得奖励更快,不必学习严格的格式约束
网友们发现,这种诡异现象可不止这一个
有人把代码发给 @kalomaze 吐槽:
「o3竟然把标准连字符替换成了非标准ASCII符号…
看起来OpenAI根本不在乎他们的强化学习有多粗暴」
kalomaze(@kalomaze) 更是气不打一处来:
o3输出的注释格式超级奇怪,还带着各种古怪的ASCII符号,这模型到底在搞什么鬼啊
我一看评论区,发现大家纷纷中招
有人在SQL里收到了满是emoji的注释
有人遇到了故意使用奇怪双引号的情况
还有人得到的Python代码直接在字符串里塞进了孟加拉文和希伯来文🤦♂️
OIiver(@OIiver) 调侃道:
it’𝚜 gеnіuѕ leνel, ɑrе уοu? іf nοt ѕіt bɑc𝗸 ɑnd wɑtch іn ɑwе, mɑybе уοu’ll leɑrn ɑ thіng οr twο
看不懂上面那句是啥意思?
把乱码当个性,是吧?👆
jose antonio(@jose antonio) 则更神:
😊2e👏 — 5🚀
这到底啥情况?
我寻思,都5202年了
难道OpenAI是在故意为模型加水印?
还是说o3真就激进得不管不顾了?
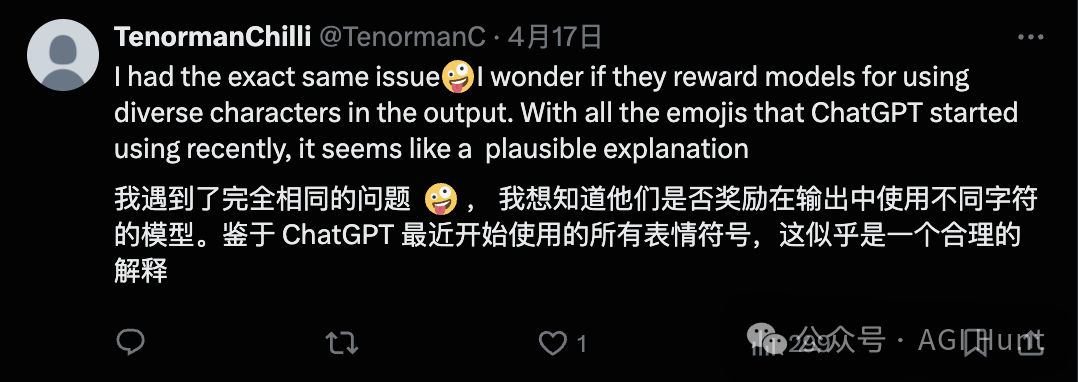
TenormanChilli(@TenormanChilli) 猜测道:
我遇到了完全相同的问题🤪我猜他们是否奖励模型在输出中使用多样化的字符。考虑到ChatGPT最近开始使用的所有表情符号,这似乎是一个合理的解释
25midi(@25midi) 给出了心理分析:
感觉o3就像一个极度紧张的模型,尝试一切方法来给人留下深刻印象
虽然在搞笑表面下
这种问题的影响其实挺严重的
Uri Gil (@Uri Gil) 吐槽:
我也遇到过!它给了我一个带有这种愚蠢破折号的pip安装命令,我把它复制粘贴到终端,却不明白为什么会报错。太蠢了
Aadish Verma (@Aadish Verma) 也遇到了类似情况:
命令仍然需要连字符。当提示错误时,o4-mini能够解决问题
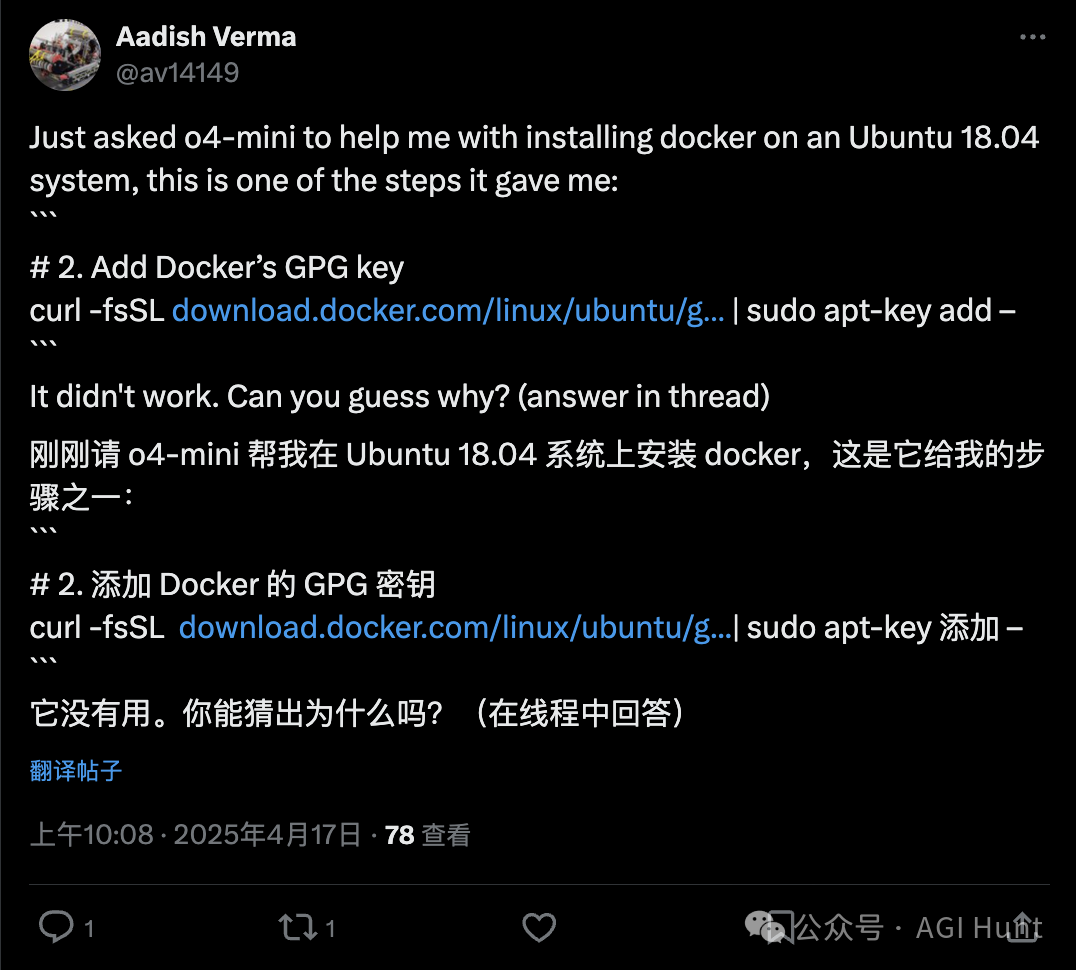
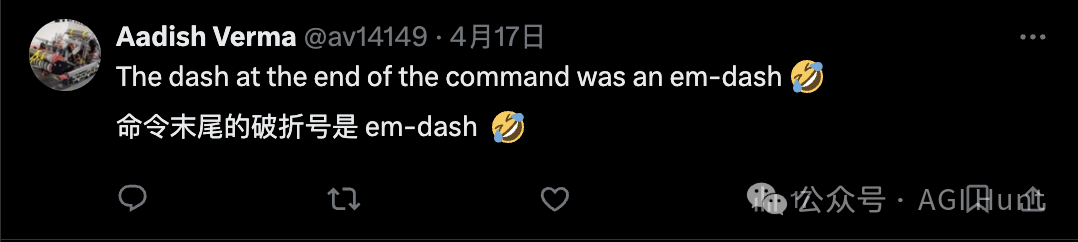
看来,虽然理论上AI已经高大上
但现实中,他们还在为符号对齐焦头烂额
皓 ジェイク(@皓 ジェイク) 甚至呼吁:
我们需要彻底重新制定符号标准,删除所有不必要或可能造成混淆的符号。
Bhaktavaschal Samal(@BhaktaVee) 得出了深刻结论:
调试过程揭示了一个关键教训
通过RLHF优化的人机交互LLM可能与机器需求相背离
解决方案不仅是更好的模型,还需要更好的评估流程和任务感知奖励设计
代码生成尤其需要混合方法,同时奖励可读性和可执行性
看来o3的问题,归根结底还是为了讨好人类
过度地迎合人类习惯,反而把代码搞炸了
o3变成了一个过度讨好人类的模型
结果代码变得不伦不类,即不能执行
也无法被代码编译器正确识别
甚至连一些硬核程序员都开始叛变了
Maxin 🇬🇭(@Maxin 🇬🇭) 直接劝解:
老兄直接用Gemini吧,解放自己
我寻思这一波,表面上看是技术问题
本质上却反映出AI进化的困境:
你到底是为了取悦人类还是写出能用的代码?
想两头都要,怕是很难讨好啊!

尤其是OpenAI这次似乎激进强化学习策略
急着让模型更强,结果反而撞墙
这是在强化炼蠢吗?
过度优化的典型案例啊!
强化没错,但过度强化就是邪道
希望未来这种情况能得到改善
不然程序员们用AI写代码
改来改去最后发现是奇怪破折号背锅
怕得天天骂娘了……
不过我倒是有一招
把o3 的输出交给能力不强但够听话的gpt4o 处理一下!
(文:AGI Hunt)