

直接偏好优化(DPO)在大语言模型(LLMs)对齐研究上表现优异,许多方法尝试通过替换输入数据将其扩展至多模态场景。这种方法有什么局限性?我们通过可视化图文表征空间发现,现有多模态 DPO 模型即便经过严格的对齐训练,仍难以准确区分有无幻觉的描述,也难以识别图像与语义一致的文本。
为此,本文提出 CHiP 方法,融合视觉偏好与多粒度文本偏好,有效提升模型的幻觉识别与跨模态对齐能力,并在多个基准和多模态大语言模型上验证该框架的效果性。

论文标题:
CHiP: Cross-modal Hierarchical Direct Preference Optimization for Multimodal LLMs
论文地址:
https://openreview.net/pdf?id=7lpDn2MhM2
代码地址:
https://github.com/LVUGAI/CHiP

现有方法存在的问题与研究动机
现有研究表明,直接偏好优化(Direct Preference Optimization, DPO)在大语言模型(Large Language Models, LLMs)中能有效提升人类偏好对齐能力并取得显著性能突破(其框架如图 1(a)所示)。
许多现有研究试图将 DPO 直接迁移至多模态场景(框架如图 1(b)所示),然而简单的多模态偏好数据替换策略难以有效应对多模态场景的复杂挑战。
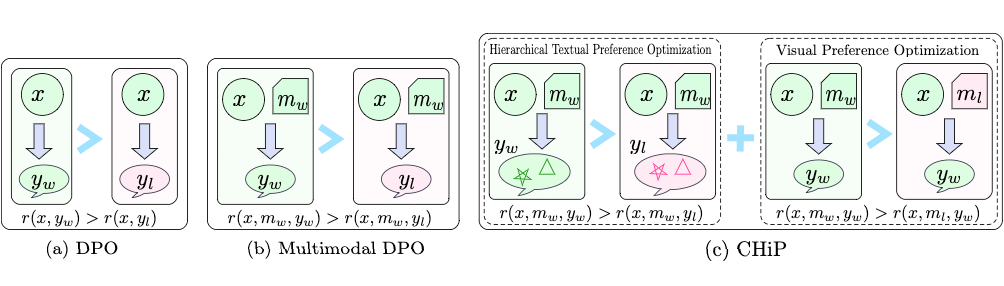
▲ 图1:DPO,多模态DPO,以及本文方法 CHiP 的框架图
理想情况下,对于对齐良好的多模态大语言模型(MLLMs),图像与其真实描述的表示应尽可能接近,而真实描述与幻觉描述的表示则应保持较大距离。
本文通过多模态表征空间的可视化分析发现,现有基于 DPO 的多模态对齐方法在图像-文本语义对齐及幻觉描述辨识方面存在显著局限。
如图 2 所示,对比 LLaVA-1.6(图 2(a))与 DPO 增强的 LLaVA(图 2(b))可以发现:尽管后者在图像-描述表征对齐度和幻觉/非幻觉描述区分度上有所改进,但其优化效果与期望效果差距甚远。
为了解决这些问题,本文提出跨模态分层偏好优化方法 CHiP(Cross-modal Hierarchical Direct Preference Optimization)。该方法通过构建视觉偏好与多粒度文本偏好(响应级、片段级、词元级)的双重优化框架,实现跨模态对齐能力的系统性提升,其方法论框架如图 1(c)所示。
实验设计方面,我们在 LLaVA-1.6 和 Muffin 两大主流框架上进行系统验证,实验覆盖四个流行幻觉基准测试集。
实证结果表明:在关键指标幻觉率方面,CHiP 相较传统 DPO 方法实现了突破性改进。在 Object HalBench 数据集上,CHiP 在减少幻觉方面显著优于 DPO,基于基础模型 Muffin 和 LLaVA,分别实现了 52.7% 和 55.5% 的相对提升。
可视化分析进一步证实(如图 2(c)所示),CHiP 在图像-描述语义对齐精度和幻觉描述鉴别能力方面显著优于基准方法(LLaVA+DPO)。

▲ 图2:表示空间的可视化分析
本文的主要贡献:
1. 我们通过图文表示分布分析发现,多模态 DPO 在语义对齐和幻觉识别方面存在不足。
2. 为此,我们提出 CHiP,结合分层多粒度的文本偏好和视觉偏好优化,以增强跨模态偏好建模。
3. CHiP 集成至多种 MLLM 后,在多个数据集上显著减少幻觉,并保持多模态大语言模型通用能力不下降。

方法:跨模态分层直接偏好优化(CHiP)
我们提出的 CHiP 方法包含两个核心模块:
1. 分层文本偏好优化(Hierarchical Textual Preference Optimization):在响应级、片段级和 token 级对文本进行偏好优化;
2. 视觉偏好优化(Visual Preference Optimization):引入图像偏好对,引导模型生成过程中多关注图片的内容。
2.1 分层文本偏好优化
基于图像的回复通常冗长复杂,而回复级偏好优化依赖于对回复质量的粗略排序,无法清晰识别哪些片段或标记包含幻觉。这使得将期望行为的权重分配变得十分困难,从而导致 reward hacking,以及对大量标记数据的需求。
因此,我们提出分层文本偏好优化模块,以更细粒度地分配奖励。对于多模态大模型(MLLMs),每个训练样本包含输入图像 、提示词 、被选回复 和被拒回复 。多模态 DPO 依赖图像和文本共同选择更偏好的回复。
以下是三个层级的优化设计:
2.1.1 响应级偏好优化
目标为最大化 ,损失函数定义为:
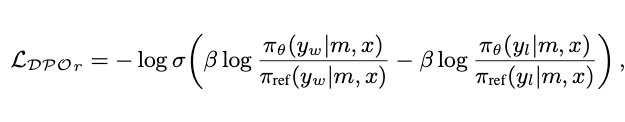
其中:
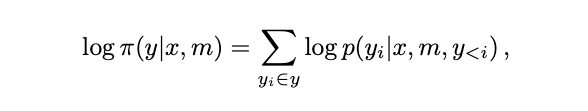
2.1.2 段落级偏好优化
我们对比选中与拒绝响应中出现差异的片段(尤其是实体名词)并给予更高奖励。段落级行为分数如下:
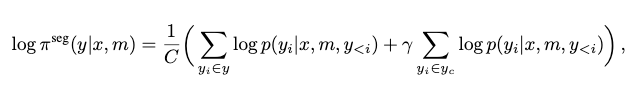
其中 表示发生变化的 token 子集,归一化因子为 。代入上式可得 。
2.1.3 Token 级偏好优化
由于图像输出是自回归生成序列,Token 级对齐有助于更精细控制模型生成行为,也有助于保持多样性。其损失函数定义如下:
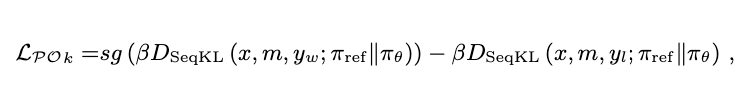
其中:
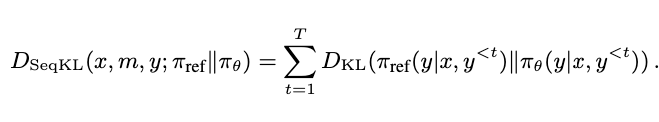
2.1.4 HDPO 总体目标
分层文本偏好优化最终目标为:
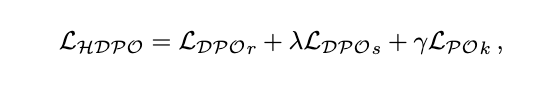
其中 和 控制段落级与 token 级的权重。
2.2 视觉偏好优化
为缓解 MLLMs 对语言模型的过度依赖,我们引入视觉偏好优化模块。该模块通过构造图像对 ,引导模型根据视觉信息判断偏好。
目标是最大化 ,损失函数为:
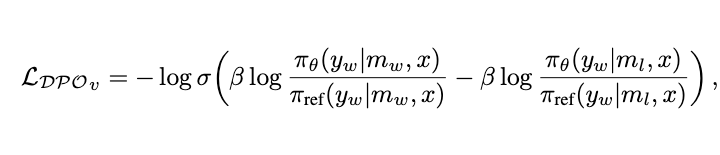
其中, 可通过旋转、裁剪、加噪声等方式扰动 而获得。
2.3 总体目标函数:CHiP
最终的跨模态分层优化目标为:
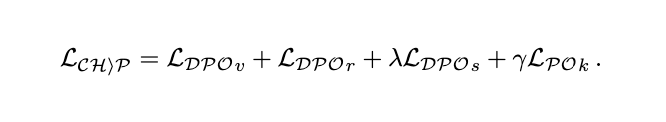
其中, 与 被赋予权重 1(完全考虑), 和 小于 1(部分考虑)。

实验与分析
3.1 主要实验结果
我们在 LLaVA-1.6 与 Muffin 框架上引入了 CHiP,并在四个主流幻觉基准上进行评测,即 Object HalBench,MMHal-Bench,HallusionBench,AMBER。
结果表明:
1. CHiP 显著减少了基础模型 Muffin 和 LLaVA 的幻觉率。
2. CHiP 在四个基准测试中均优于 DPO。
3. 在 ObjHal 和 AMBER 数据集上,结合 CHiP 的 LLaVA 和 Muffin 的幻觉率低于 GPT-4。
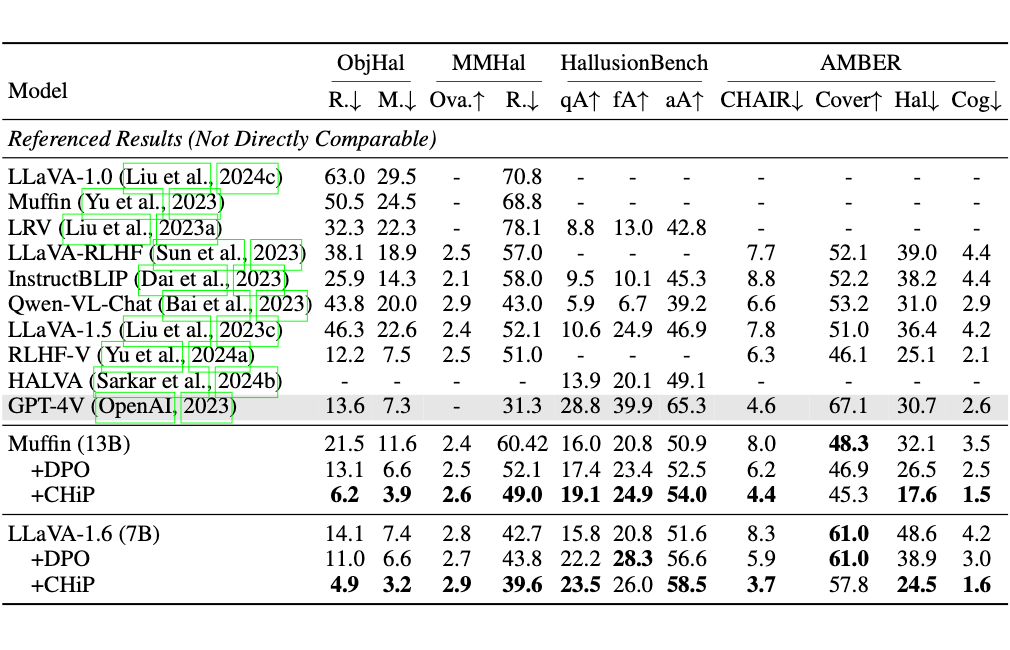
▲ 表1:CHiP 基于 LLaVA-1.6 和 Muffin 在多模态幻觉的四个基准上的评估结果
3.2 通用能力评估
偏好优化可能削弱模型的通用能力。为验证 CHiP 是否会影响模型泛化能力,我们对比评估了 LLaVA 与 LLaVA+CHiP,结果如图 5。 在多个通用评估集上的表现。

▲ 表2:通用能力评估。观察结果:在 6 个数据集中,LLaVA+CHiP 在其中 5 个上优于 LLaVA,表现出 CHiP 在提升幻觉对齐的同时,不影响通用能力,反而在 MMMU、LLaVA-Wild、MMB-CN 等任务上略有提升。
3.3 人工评估
由于 MMHal-Bench (MMHal) 部分样本缺少准确标注,GPT-4 难以识别幻觉,我们引入专家人工标注对比 CHiP 与 DPO(基于 LLaVA)的性能。
观察结果:在可判别的 36.5% 样本中,CHiP 在 31.6% 上优于 DPO。
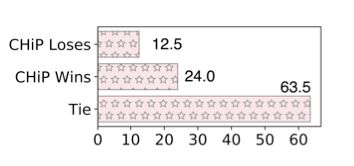
▲ 图3:MMHal-Bench 数据的人工标注结果
3.4 分层文本优化强度分析
CHiP 在文本上进行响应级、段落级和 token 级偏好优化。
在权重设置方面,我们固定响应级权重为 1,token 级权重 ,重点研究段落级权重 。
如图 6 所示,当 (Muffin)或 (LLaVA)时,AMBER 数据集上 CHAIR 与幻觉率指标表现最佳。
因此我们在所有实验中使用此设置。

▲ 表4:段落级权重()的取值搜索
3.5 训练范式的影响
图文语义不对齐是 MLLM 幻觉的重要成因。然而,大多数方法在训练时冻结视觉编码器,仅训练连接层与语言模型部分。
这引出了一个关键问题:在偏好优化过程中联合训练视觉编码器是否有助于降低幻觉?我们在 LLaVA+CHiP 与 LLaVA+DPO 下对视觉编码器是否训练进行对比,结果如表 5 所示。
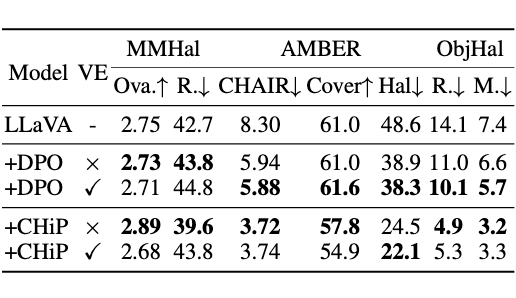
▲ 表5:训练范式的影响。结果观察:DPO 在训练视觉编码器时幻觉率更低;CHiP 在视觉编码器参与训练时反而效果略差。可能原因在于:多重优化目标(文本+图像)在联合训练时会稀释模型对图文对齐的关注度,导致效果下降。
3.6 拒绝图像构建策略分析
偏好样本的质量依赖于拒绝图像的构造方式及其与选中图像的差异。文本探索了五种,如下所示
1. 扩散(Diffusion):按照图像生成中的前向扩散过程,对 chosen 图像逐步加入高斯噪声(T=500 步);
2. 黑屏(Blackness):将 chosen 图像所有像素 RGB 设置为 0;
3. 裁剪(Crop):对 chosen 图像进行随机裁剪;
4. 旋转(Rotation):将图像随机旋转 10 至 80 度;
5. 随机替换(Randomness):从训练集中随机选取其他图像作为拒绝图像。构造示例如图 7 所示。

▲ 图4:拒绝图像(rejected image)构建策略示例
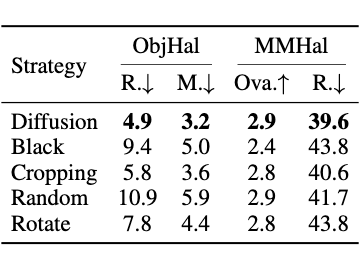
▲ 表6:不同策略下的 CHiP 表现。结果观察:(1) 扩散与裁剪策略效果最佳,能保留较多视觉语义信息;(2)黑色与随机替换最差,几乎完全丢失了图像特征;(3)旋转策略表现一般,虽然保留图像信息但引入了强视觉偏差。
噪声步数 T 的影响: 本文进一步探索了扩散步骤数 T 对 CHiP 性能的影响,结果如图 5 所示。
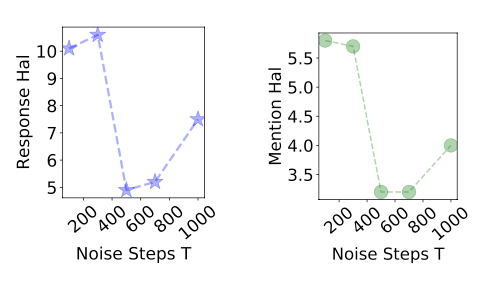
▲ 图5:不同加噪步数下的 CHiP 表现。结果观察:(1)当 T = 500 时,CHiP 效果最佳;(2)T 太小 → 选拒图太相似 → 偏好标签含糊;(3)T 太大 → 信息丢失严重 → 模型区分太容易,弱化了视觉偏好学习。

总结
CHiP(跨模态层次化直接偏好优化方法)在缓解多模态大语言模型中的幻觉问题上表现出显著成效。
实验结果表明,CHiP 在四个主流数据集上均有效降低了幻觉率。表征可视化进一步验证了其优势:相比标准多模态 DPO,CHiP 更好地缩小了图像与非幻觉描述间的语义差距,并增强了对幻觉内容的辨别能力。
(文:PaperWeekly)