
Datawhale分享
作者:Douwe Kiela,编译:思考机器
每隔几个月,人工智能领域就会经历类似的模式。一个具有更大上下文窗口的新模型问世,社交媒体上便会充斥着“RAG 已死”的宣言。Meta 最近的突破再次引发了这场讨论——Llama 4 Scout 惊人的 1000 万(理论上)token 上下文窗口代表着一次真正的飞跃。
RAG 的初衷
无法访问私有(企业内部)数据: 模型通常基于公共数据进行训练,但往往需要那些不断变化和扩展的专有信息。过时的参数知识: 即使模型频繁更新,其训练数据截止日期与当前时间之间总会存在差距。幻觉和归因问题: 模型经常编造听起来合理但错误的信息。RAG 通过将回答基于真实来源,并提供引文让用户核实信息,解决了这个问题。
为什么我们仍然需要 RAG(并且永远需要)
2023 年 5 月:Anthropic 的 Claude,上下文窗口达 10 万 token 2024 年 2 月:Google 的 Gemini 1.5,上下文窗口达 100 万 token 2025 年 3 月:模型上下文协议(Model Context Protocol)让你能直接与你的数据对话 (注:原文日期可能是笔误)
可扩展性与成本 :处理数百万 token 速度缓慢,且在计算和财务上都代价高昂。即使计算成本在下降,延迟对于应用程序来说也可能是一个大问题。性能下降 :LLM 仍然受困于“中间丢失”(lost in the middle)的问题。这意味着它们无法有效利用长文本中间部分的信息。通过剔除不相关文档并避免“大海捞针”的情况,您将获得更好的结果。数据隐私 :将所有 数据提供给基础模型可能引发严重的数据隐私问题。尤其是在医疗保健或金融服务等受到严格监管的行业,您需要对数据强制执行基于角色的访问控制。
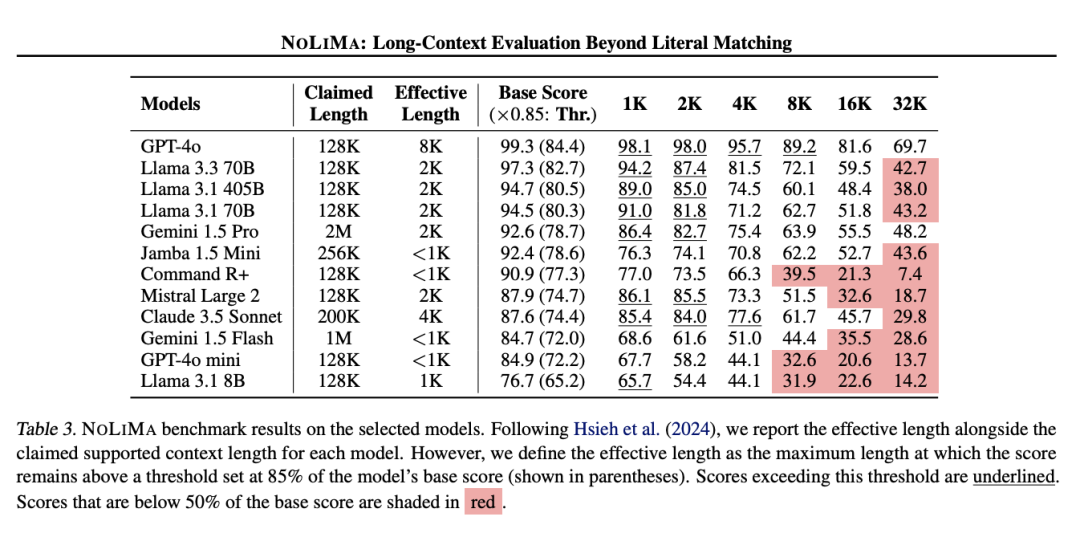
可扩展性 – 您的企业知识库是以 TB 或 PB 来衡量的,而不是 token。即使有 1000 万 token 的上下文窗口,您仍然只能看到可用信息的极小一部分。这就是为什么检索技术的创新一直快速发展,混合搜索、查询转换、自我反思、主动检索以及对结构化数据的支持等方面的进步,都在帮助您在知识库中找到正确的信息。准确性 – 有效的上下文窗口与产品发布时宣传的大相径庭。研究一致表明,模型在远未达到其官方极限时性能就会下降。在实际测试中,同样的模式也会出现,模型难以准确引用深埋在其上下文中的信息。这种“上下文悬崖”意味着仅仅将更多内容塞入窗口并不会带来更好的结果。
延迟 – 将所有内容加载到模型上下文中会导致响应时间显著变慢。对于面向用户的应用程序,这会造成糟糕的用户体验,人们会在得到答案前就放弃交互。基于检索的方法可以通过仅添加最相关的信息来提供更快的响应。效率 – 你会在需要回答一个简单问题时去读完整本教科书吗?当然不会!RAG 提供了相当于直接翻到相关页面的能力。处理更多 token 不仅更慢,而且极其低效,并且比使用 RAG 精准定位所需信息要昂贵得多。
警惕错误的二分法

RAG 提供了访问模型知识库之外信息的途径微调 改善了信息处理和应用的方式更长的上下文 允许检索更多信息供模型推理MCP 简化了 Agent 与 RAG 系统(及其他工具)的集成

结论
如果你的系统无法利用你的专有数据,持续提供过时信息,或者缺乏你所需的专业知识,那么让我们谈谈。我们构建了一个将智能检索与前沿 LLM 相结合的系统,来解决这些长期存在的难题。因为重要的不是哪种技术在某场人为的竞赛中获胜,而是构建能够真正解决实际问题的方案。”
(文:Datawhale)