

邮箱|huangxiaoyi@pingwest.com
在所有人都在猜测DeepSeek V4或者R2和Qwen3谁先到来时,Qwen3发布了。
4月29日凌晨,阿里巴巴开源了新一代通义千问Qwen3系列模型,涵盖8款不同尺寸。其中,旗舰模型Qwen3 235B采用混合专家(MoE)架构,总参数量235B(仅为DeepSeek-R1的1/3),激活参数仅需22B,预训练数据量达36万亿Tokens。

性能上,据官方介绍,Qwen3在多项测评中表现优异,超越DeepSeek-R1、OpenAI-o1等主流模型,成为当前性能领先的开源大语言模型。
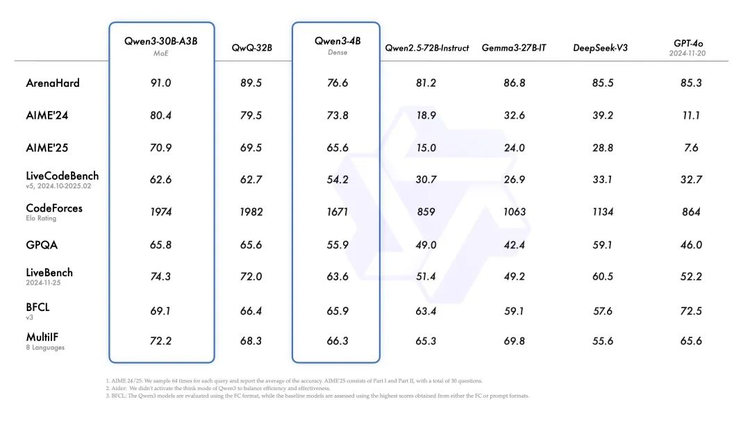
具体来看,Qwen3在推理、指令遵循、工具调用、多语言能力等方面均大幅增强:在奥数水平的AIME25测评中,Qwen3斩获81.5分,刷新开源纪录;在考察代码能力的LiveCodeBench评测中,Qwen3突破70分大关,表现甚至超过Grok3;在评估模型人类偏好对齐的ArenaHard测评中,Qwen3以95.6分超越OpenAI-o1及DeepSeek-R1。
看惯了模型榜单表现上的反复超越,但这次的Qwen3还有些不同,比起单纯的模型边界突破,Qwen3更想突出的是以小博大的能力。而且它在和DeepSeek轮流推动开源模型进步的过程中,再次给开源社区提供了与R1不同的配方。
没完全用R1的方法,但完成了对R1的超越
和R1类似的是,Qwen3也走的是“用模型训模型”的思路。
在预训练阶段,Qwen3的性能优化很重要的一个来源是大量高质的合成数据。
数量上看,Qwen3的数据集相比Qwen2.5有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。其中一部分来自于PDF文档提取信息,另一部分就是Qwen2.5系列模型合成的数据。
技术报告中明确提到,“我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。”
这也意味着,在预训练的过程中,Qwen3借助自身的生态优势,又构建了一个自我迭代提升的数据系统。
预训练奠定了Qwen3的基础能力,而在此基础上的后训练阶段则是Qwen3最为关键的技术创新,它通过多阶段训练方法实现了推理能力与直接回答能力的融合。

以上图为例,同一模型内实现了思考和非思考模式。在官方的应用界面来看,选择哪种模式的方法看起来还是让用户自己选择,不过在选择了深度思考模式后,用户多了一个设置思考预算的功能,让模型根据问题难度动态分配。
在后训练上,Qwen3用了和R1整体pipeline类似的的“回锅肉”式迭代:微调、RL、再微调,然后再更具体的RL。

它和DeepSeek一样用大模型蒸馏小模型,不过Qwen彻底是自己蒸馏自己了。
另一个特别值得注意的是,第二阶段RL,Qwen团队采用的是基于规则的奖励来增强模型的探索和钻研能力。
“第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。”官方博客写到。这与当前被认为是DeepSeek R1等模型成功关键的GRPO(基于结果奖励的优化)形成鲜明对比。Qwen3没有完全依赖GRPO这样基于结果的奖励机制。
紧接着,在第三阶段的微调中,Qwen3采用了一份长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,实现了将非思考模式整合到思考模型中,确保了推理和快速响应能力的无缝结合。
最后,在第四阶段,Qwen3在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习。
Qwen3没有完全用R1的方法,但完成了对R1的超越。
模型全尺寸,但参数正在“变小”
和Qwen此前的生态路线一样,Qwen3一口气发布了8款不同的模型版本,包含2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款密集模型,每款模型均斩获同尺寸开源模型SOTA(最佳性能)。
这次的全尺寸,果然没有让期待已久的社区失望,欢呼声一片。
MLX 是专为 Apple Silicon设计的高效机器学习框架。在模型发布前,MLX的团队就完成了对Qwen 3的支持工作。其中0.6B和4B可以应用于手机,8B、30B、30B MOE可用于电脑……
尺寸全是一方面。更重要的是Qwen在不断以更多、更小的尺寸,达到过去更大尺寸同样的性能效果。在很多场景下,模型都具备了在端侧运行的能力和水平。
据官方博客显示,Qwen3的30B参数MoE模型实现了10倍以上的模型性能杠杆提升,仅激活3B就能媲美上代Qwen2.5-32B模型性能;Qwen3的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如32B版本的Qwen3模型可跨级超越Qwen2.5-72B性能。

Qwen3显然是个能让开源界好好把玩和拆解一段时间的最热门模型,接下来它更全面的技术报告发布后,估计会揭秘更多“独家配方”,继续推动开源模型的进步和创新。


(文:硅星人Pro)