
 关注我,记得标星⭐️不迷路哦~
关注我,记得标星⭐️不迷路哦~
✨ 1: qwen3
Qwen3是阿里云发布的最新通义千问大模型,提供多种尺寸和专家模型,具备优秀推理、对话和工具使用能力。
Qwen3 是由阿里云 Qwen 团队开发的大型语言模型系列。它是 Qwen 系列的最新成员,代表了该团队迄今为止最先进、最智能的系统,吸取了构建 QwQ 和 Qwen2.5 的经验。Qwen3 系列模型已开源,提供权重供公众使用。
模型种类和规模
Qwen3 系列包含多种不同规模的模型,包括稠密模型(Dense)和混合专家模型(Mixture-of-Expert, MoE)。开源的模型权重包括两个 MoE 模型和六个 Dense 模型。
- MoE 模型
: -
Qwen3-235B-A22B:总参数量超过 2350 亿,激活参数量约为 220 亿。这是旗舰模型。 -
Qwen3-30B-A3B:总参数量约为 300 亿,激活参数量约为 30 亿。这是一个小型 MoE 模型。 - Dense 模型
: -
Qwen3-32B -
Qwen3-14B -
Qwen3-8B -
Qwen3-4B -
Qwen3-1.7B -
Qwen3-0.6B
所有这些模型都支持 Apache 2.0 开源许可,允许免费下载和商用。
主要亮点和特性
Qwen3 包含多个核心亮点:
- 多种思考模式
:支持思考模式和非思考模式之间的无缝切换。思考模式下模型会逐步推理,深思熟虑后给出最终答案,适合复杂问题。非思考模式提供快速、近乎即时的响应,适合对速度要求高的简单问题。这种灵活性允许用户根据任务控制模型的“思考”程度,优化成本效益和推理质量。可以通过 enable_thinking=False参数或使用/think和/nothink指令来控制模式。 - 显著增强的推理能力
:在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ (思考模式) 和 Qwen2.5 instruct 模型 (非思考模式)。 - Agent 能力增强
:优化了 Agent 和代码能力,同时加强了对 MCP 协议的支持。这使得模型能够精确集成外部工具,并在复杂的基于 Agent 的任务中实现领先性能。Qwen-Agent 框架封装了工具调用模板和解析器,降低了代码复杂性。 - 卓越的人类偏好对齐
:擅长创意写作、角色扮演、多轮对话和指令遵循,提供更自然、引人入胜的对话体验。 - 广泛的多语言支持
:支持 100+ 种语言和方言,资料中具体提到支持 119 种语言和方言。这包括印欧语系、汉藏语系、亚非语系、南岛语系、德拉威语、突厥语系、壮侗语系、乌拉尔语系以及日语、韩语等其他语言。
预训练和后训练
Qwen3 的预训练数据集相比 Qwen2.5 显著扩展。
- 数据规模
:Qwen2.5 在 18 万亿 token 上预训练,而 Qwen3 使用的数据量几乎是其两倍,达到约 36 万亿 token。 - 数据来源
:数据不仅来源于网络,还从 PDF 文档中提取。团队使用 Qwen2.5-VL 提取文本,并用 Qwen2.5 改进提取质量。 - 合成数据
:为了增加数学和代码数据,利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个专家模型合成数据,形式包括教科书、问答对和代码片段等。 - 预训练阶段
:预训练过程分为三个阶段。 - S1 (基础语言技能)
:在超过 30 万亿 token 上预训练,上下文长度为 4K token,构建基本的语言技能和通用知识。 - S2 (知识密集型优化)
:增加知识密集型数据(如 STEM、编程、推理任务)的比例,在额外 5 万亿 token 上继续预训练。 - S3 (长上下文扩展)
:使用高质量长上下文数据将上下文长度扩展到 32K token。 - 后训练
:为了开发具备思考推理和快速响应能力的混合模型,实施了四阶段的后训练流程。 - 长思维链冷启动
:使用长思维链数据微调模型,增强基本推理能力,涵盖数学、代码、逻辑推理、STEM 等领域。 - 长思维链强化学习
:进行大规模强化学习,利用基于规则的奖励增强探索和钻研能力。 - 思维模式融合
:在包含长思维链数据和常用指令微调数据的组合数据上微调,将非思考模式整合到思考模型中。 - 通用强化学习
:在 20 多个通用领域任务(如指令遵循、格式遵循、Agent 能力)应用强化学习,进一步增强通用能力并纠正不良行为。
性能和测评结果
Qwen3 的性能显著提升。
-
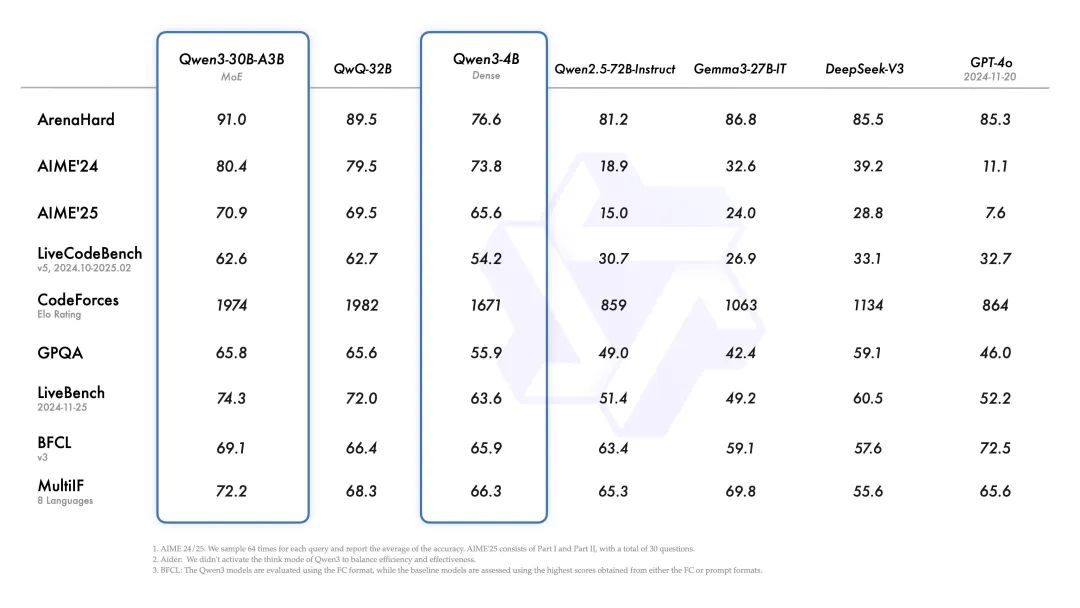
与 Qwen2.5 相比:由于模型架构改进、训练数据增加和更有效训练方法,Qwen3 Dense 基础模型整体性能与参数更多的 Qwen2.5 基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。
-
MoE 模型效率:Qwen3 MoE 基础模型在仅使用 10% 激活参数的情况下,达到了与 Qwen2.5 Dense 基础模型相似的性能。小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,但表现更胜一筹。
-
小型模型表现:即使是 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。最小的 Qwen3-0.6B 模型速度很快,足以完成许多日常推理任务,可以在普通手机上流畅运行。
-
与顶级模型对比:旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力甚至超越的结果。
-
在 ArenaHard、AIME 24/25、LiveCodeBench、CodeForces、Aider 等测试平台中,全部超过了 DeepSeek 开源的 R1 以及 OpenAI 的 o1 等著名模型。 -
在奥数水平的 AIME25 测评中,斩获 81.5 分,刷新开源纪录。 -
在考察代码能力的 LiveCodeBench 评测中,突破 70 分大关,表现甚至超过 Grok3。 -
在评估模型人类偏好对齐的 ArenaHard 测评中,以 95.6 分超越了 OpenAI-o1 及 DeepSeek-R1。 -
在评估 Agent 能力的 BFCL 评测中,创下 70.8 的新高,超越 Gemini2.5-Pro、OpenAI-o1 等顶尖模型。 -
编程:Qwen3-30B-A3B 以优异的成绩通过了旋转七边形测试:
-
部署成本:性能大幅提升的同时,Qwen3 的部署成本大幅下降。旗舰模型 Qwen3-235B-A22B 仅需 4 张 H20 即可部署满血版(约 50w 左右),而满血版 R1 需要 16 张 H20(约 200w 左右),部署成本大约是 R1 的 25%~35%。显存占用仅为性能相近模型的三分之一。Qwen3-30B-A3B 消费级别显卡即可部署。
获取和使用
Qwen3 模型可通过多种渠道获取和使用:
- 开源平台
:模型权重已在 Hugging Face、ModelScope 和 Kaggle 等平台开放使用。GitHub 页面提供了更多信息。 - 在线体验
:用户可以在 Qwen Chat 网页版 (chat.qwen.ai) 和通义 APP 中试用 Qwen3。 - 云服务提供商
:Qwen3 也可通过 阿里云百炼调用 API 服务,以及通过 Fireworks AI、Hyperbolic 等云服务提供商使用。 - 本地部署/推理框架
:对于部署,推荐使用 SGLang 和 vLLM 等框架 (需要相应版本,例如 SGLang >= 0.4.6.post1)。对于本地使用,推荐 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。在 Apple Silicon 设备上,MLX-LM >= 0.24.0 也支持 Qwen3。使用 Transformers 库需要版本 >= 4.51.0。GitHub 仓库提供了推理的指导,包括 batch inference, streaming 等。
阿里表示,Qwen3 代表了该公司在通往**通用人工智能(AGI)和超级人工智能(ASI)**旅程中的一个重要里程碑。未来的计划包括从多个维度提升模型,如优化模型架构和训练方法,扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,并利用环境反馈推进强化学习以进行长周期推理。
地址:https://github.com/QwenLM/qwen3
基准测试: https://qwenlm.github.io/blog/qwen3/
模型: https://huggingface.co/organizations/Qwen/activity/models
使用 : https://chat.qwen.ai/
✨ 2: FantasyTalking
FantasyTalking 通过连贯的运动合成,逼真地生成说话人像,并已开源代码和模型权重。

FantasyTalking是一个逼真的说话头像生成模型,它通过连贯的动作合成来生成生动的头像视频。
核心功能:
-
**逼真的说话头像生成:**能够根据输入的图像和音频,生成自然且逼真的说话头像视频。 -
**连贯的动作合成:**能够合成连贯的面部表情和头部动作,使生成的视频更加生动。 - 音频驱动:
通过音频输入,模型可以控制人物的嘴型和情感表达,使头像与语音同步。
地址:https://github.com/Fantasy-AMAP/fantasy-talking
✨ 3: CleverBee
CleverBee是基于AI的在线数据整合助手,利用LLM和网页浏览技术辅助用户进行研究,提升效率。

CleverBee 是一个基于 Python 的 AI 驱动的在线数据信息整合助手。
它使用大型语言模型(LLM)例如 Claude 和 Gemini,结合 Playwright 进行网页浏览,并使用 Chainlit 构建交互式用户界面。CleverBee 的主要功能是:
- 自动进行网页研究:
根据用户指定的研究主题,自动浏览网页,提取网页内容(HTML),并进行清理和格式化。 - 信息整合:
基于提取的内容,使用不同的 LLM 对信息进行总结和综合,最终生成研究报告。 - 可配置性强:
支持多种 LLM 提供商,例如 Gemini 和 Claude,并且可以通过配置文件灵活调整各项参数。 - 成本控制:
集成了 Token 追踪功能,可以监控 LLM 的使用情况,并预估成本。 - 缓存机制:
使用 SQLite 缓存 LLM 的结果,提高性能并降低成本。
地址:https://github.com/SureScaleAI/cleverbee
✨ 4: Deep Recall
Deep Recall是一个开源LLM的记忆框架,提供企业级存储、检索和整合用户交互记录,以实现个性化响应。

Deep Recall 是一个为开源 LLM 设计的超个性化智能体记忆框架,旨在提供企业级的用户交互数据存储、检索和集成能力。
核心功能:
- 记忆增强:
通过存储和检索用户历史交互,使 LLM 具备上下文感知能力,能提供更个性化的响应。 - 可扩展架构:
采用三层架构(Memory Service, Inference Service, Orchestrator),支持云端和本地部署,并具备自动伸缩能力。 - 高性能:
采用 GPU 优化推理,集成向量数据库(如FAISS, Milvus, Qdrant, Chroma),确保高效的记忆检索。 - 模块化设计:
易于替换存储后端或 LLM 模型。 - 数据安全:
提供API管理用户数据,支持查看、更新或删除。
地址:https://github.com/jkanalakis/deep-recall
✨ 5: MCP Server for Deep Research
MCP Server for Deep Research是一个深度研究工具,能够生成结构化的、引用充分的综合研究报告。
MCP Server for Deep Research 是一个旨在帮助用户进行深入研究的工具,它本质上是一个个人研究助理。 它通过结构化的流程将研究问题转化为全面且带有引用的报告。 该工具集成了问题阐述、子问题生成、网络搜索、内容分析和报告生成等功能,旨在提供一个完整的端到端研究工作流程。用户可以通过 Claude Desktop 进行配置和使用。
地址:https://github.com/reading-plus-ai/mcp-server-deep-research
(文:每日AI新工具)