

深夜,科技圈投下一颗“核弹”,阿里 Qwen3 横空出世,直接封神全球开源模型王座!成本暴降,性能狂飙,碾压一众顶尖对手,开源仅 3 小时,GitHub 狂揽 17k 星,热度席卷全球!

一、Qwen3:出道即巅峰,吊打全球顶尖模型!
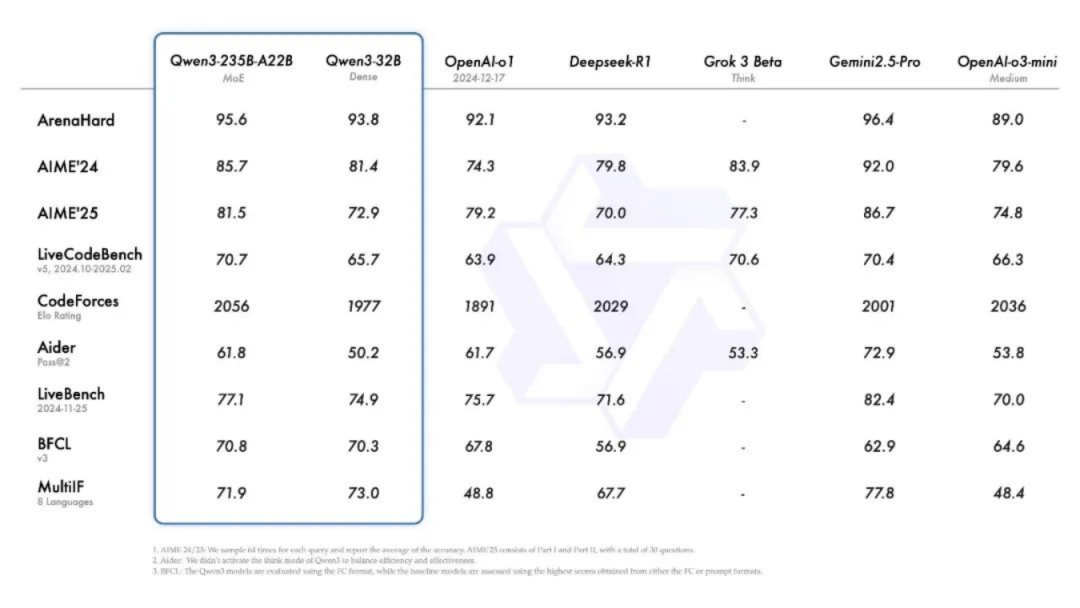
这次阿里的Qwen3 开源,简直是一场“降维打击”!参数量只有竞品 DeepSeek-R1 的 1/3,性能却直接爆表!在数学、代码、推理等各项测试里,Qwen3 都把对手按在地上摩擦。
比如在奥数 AIME25 测评里,Qwen3 拿下 81.5 高分,直接刷新开源模型纪录;
在代码评测 LiveCodeBench 上,更是突破 70 分大关,超越了 Grok3!
让很多网友直呼:“这哪是模型,简直是作弊外挂!”
而且Qwen3 的部署成本低到感人,仅需 4 张 H20 显卡就能满血运行,显存占用只有同性能模型的 1/3!这意味着啥?
小团队、个人开发者都能轻松上手,再也不用被高昂的算力成本劝退了!
二、混合推理模式:快慢随心,想咋答就咋答!
Qwen3 最牛的,还得数它的“混合推理模式”。
简单来说,就是它既能“秒回”简单问题,又能“深度思考”复杂难题。就像你聊天时,朋友问“晚上吃啥”,它能瞬间秒回“不如吃火锅”;
但要是遇到“如何解决世界性能源危机”这种世纪难题,它也能一步步拆解分析,给出专业答案。
这种模式太实用了!日常聊天、客服咨询用“非思考模式”快速回复,节省时间;学术研究、编程开发用“思考模式”深度推理,确保精准。网友评价:“一个模型,两种灵魂,Qwen3 简直是开了挂的智能体!”
三、多语言支持:全球通吃,119 种语言一键搞定!
Qwen3 的多语言能力也让我惊掉下巴!它支持 119 种语言和方言,从英语、法语、中文这种通用语言,到缅甸语、孟加拉语、越南语这种小语种,全都手到擒来。这意味着啥?无论你是国内开发者,还是国外技术宅,都能直接用母语调用 Qwen3。
想象一下,非洲的程序员用斯瓦希里语写代码,印度的工程师用泰米尔语做学术研究,中东的创业者用阿拉伯语开发商业应用…… 全球开发者的生产力都被 Qwen3 拉满了!网友调侃:“Qwen3 开源后,联合国开会都不需要翻译了!”
四、智能体能力:工具调用大师,效率直接翻倍!
Qwen3 还是个“工具调用大师”,能轻松和外部工具集成。比如你可以直接用 Qwen3 操作数据库、调用 API、运行代码解释器,甚至控制智能硬件。更绝的是,阿里还推出了 Qwen-Agent 框架,把复杂的工具调用封装成简单指令,小白也能轻松上手。
有开发者分享案例:“我用 Qwen3 搭建了一个自动下单系统,它能自动识别商品信息、计算价格、调用支付接口,全程只需要几行代码!效率直接翻倍,这哪里是工具,分明是个人工智能助理!”
五、开源秒下:3 小时狂揽 17k 星,全球开发者疯抢!
Qwen3 开源仅 3 小时,GitHub 上就狂揽 17k 星!这热度简直比春节抢红包还疯狂。全球开发者都迫不及待地下载体验,甚至有苹果工程师 Awni Hannun 站台,宣布 Qwen3 已适配 MLX 框架,可以无缝运行在 iPhone 和 Mac 设备上。
而且这次阿里开源的力度非常大,直接把8 款不同尺寸的模型全部放出,从手机端适配的 4B 模型,到企业级的 32B 模型,各种场景都能覆盖。很多网友直言:“这哪里是开源,简直是全球开发者的狂欢节!”
六、上手超简单:5 分钟搭建专属 Qwen3 应用!
为了让小白也能快速上手Qwen3,阿里还发布了一键部署教程。无论是用 Hugging Face 的 transformers 库,还是通过阿里云百炼调用 API,5 分钟就能搭建起一个专属的 Qwen3 应用。
(一)部署推理示例(使用 transformers)
Transformers 作为 Hugging Face 提供的通用模型库,适用于各种模型的推理任务,支持丰富的模型种类和灵活的推理配置。
1. 安装必要的库
pip install transformers modelscope2. 加载模型并生成文本
from modelscope import AutoModelForCausalLM, AutoTokenizer# 指定模型名称model_name = "Qwen/Qwen3-30B-A3B"# 加载分词器和模型tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto")# 准备模型输入prompt = "Give me a short introduction to large language model."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # 默认启用思考模式)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 执行文本生成generated_ids = model.generate(**model_inputs,max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()# 解析思考内容和最终回答try:# 查找 </think> 标签的索引index = len(output_ids) - output_ids[::-1].index(151668)except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index],skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:],skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)print("content:", content)
3. 禁用思考模式
只需将`enable_thinking` 参数设置为 `False` 即可:
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # 禁用思考模式)
(二)部署推理示例(使用 SGLang)
SGLang 是专为高效推理设计的框架,适合在资源受限的环境中快速部署模型,提供高性能的推理服务。
1. 安装 SGLang
pip install sglang2. 启动服务器
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3(三)部署推理示例(使用 vLLM)
vLLM 专注于大规模语言模型的高效推理,能有效管理多线程和多进程任务,适合处理高并发的推理请求。
1. 安装 vLLM
pip install vllm2. 启动服务器
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1(四)部署推理示例(使用 ollama)
Ollama 提供了轻量级的本地部署方案,适合在本地环境中快速启动和运行模型,方便用户测试和验证模型功能。
1. 安装 ollama
curl -fsSL https://ollama.com/install.sh | sh2. 运行模型
ollama run qwen3:8b七、总结&展望
这次Qwen3 的发布,不仅仅是一个模型的开源,更是全球人工智能发展的重要里程碑。通过混合推理模式、多语言支持和工具调用能力的结合,Qwen3 为通用人工智能 AGI 的实现铺平了道路。
阿里在官方博客中提到:“Qwen3 是我们迈向 AGI 的关键一步。未来我们将继续扩大数据规模、优化模型架构,让 Qwen3 能够处理更复杂的任务,支持更多模态,甚至实现自主学习。” 网友纷纷留言:“AGI 的时代,真的要来了!”
八、项目资料
在线体验:https://chat.qwen.ai/
GitHub:https://github.com/QwenLM/Qwen3
魔搭社区:https://modelscope.cn/collections/Qwen3
只需要打开网页,输入问题,就能感受Qwen3 的科幻级能力。无论是用来学习、工作,还是单纯过把 “和 AI 聊天” 的瘾,Qwen3 牛都不会让你失望!
(文:小兵的AI视界)