

仔细看她的嘴巴、脸颊和眼睛,甚至胸部的起伏,动作细节非常到位,是不是足以以假乱真?
工具链接:https://app.heygen.com/home
Avatar IV 亮点可不少。
不止能处理正脸照,还支持侧脸、半身、全身等多角度图像输入,生成的数字人更立体、更生动,自带电影镜头感,不再是死盯镜头的 AI 面瘫脸。
更厉害的是,它不仅能说,还能唱。嘴型精准贴合音乐节奏,连眼神、头部、身体(比如腹部)都会随之起伏律动,细节拿捏到位。
核心升级来自一项新技术:基于扩散模型的音频驱动表情引擎。
简单理解,就是这套引擎能根据语音的节奏、语气、情绪,自动生成对应的表情与动作。它不是单纯对口型,而是能「听懂」语义和情绪,做出停顿、点头、语调起伏等细腻动作,像个真正会说话的人。
应用场景也因此拓宽了不少:动画视频制作、虚拟宠物拟人化、游戏角色配音、播客内容可视化……统统都能用上。
订阅用户可上传最长 30 秒的语音或文本,生成动态数字人视频,做个广告绰绰有余。
免费用户则有每月 3 次机会,生成最长 10 秒视频。
好了,看看怎么玩儿。
第一步,访问 HeyGen 官网,选择「照片转视频」最新模型—— Avatar IV。
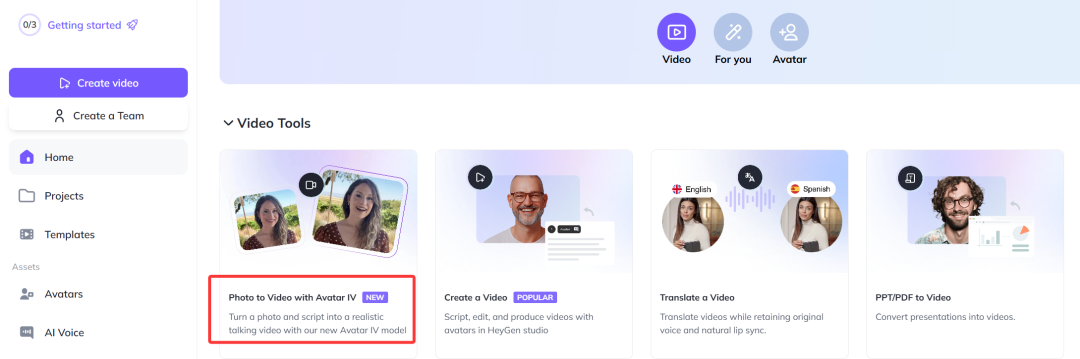
上传一张你想让它开口说话的照片,接着输入文字脚本+选择声音,或者直接上传一段音频。
我们上传的是周星驰的剧照,配上哪吒的 Rap 打油诗音频:
「天雷滚滚我好怕怕,劈得我浑身掉渣渣。突破天劫我笑哈哈,逆天改命我吹喇叭。」
注意:免费用户最多生成 10 秒视频,别贪心,脚本或音频太长不会被系统支持。
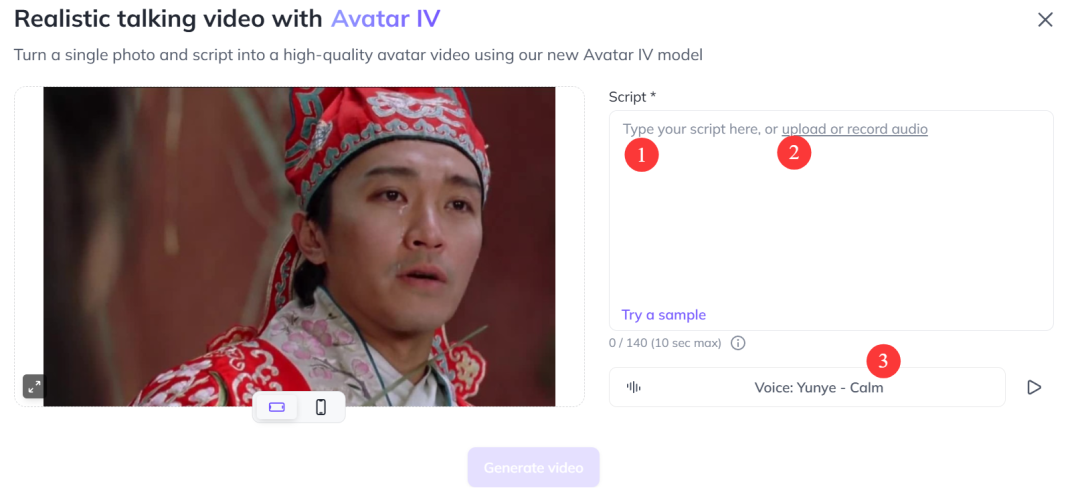
不过也有些小遗憾——相比英文,系统的中文声音资源还不算丰富。
你可以根据方言口音、声音性别、年龄、情绪(比如愤怒、兴奋、平静)、使用场景等维度筛选。
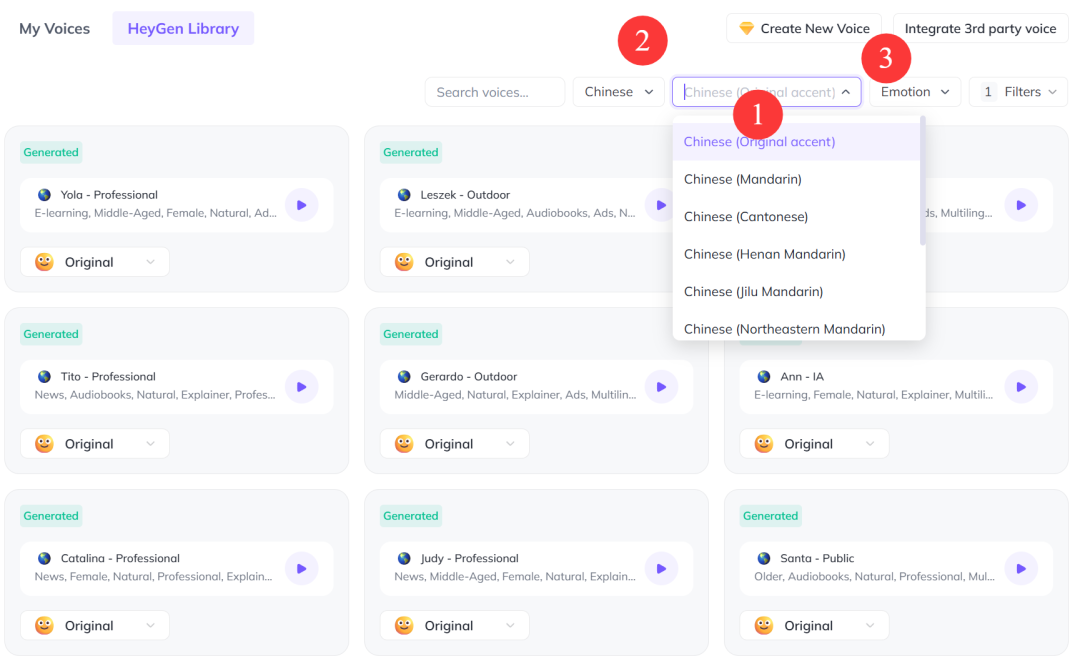
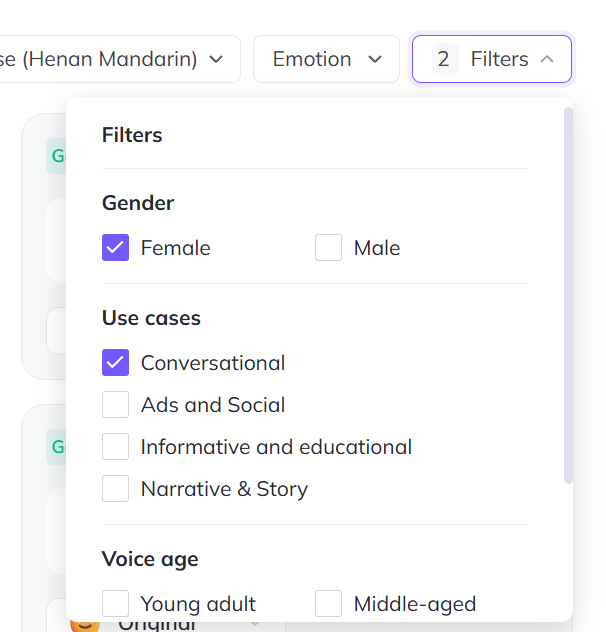
左右滑动查看更多
嘴型精准匹配,眼神、头部、身体微动跟随语音节奏,连喉结都跟着上下浮动,真实感拉满。
接下来我们试了个更大胆的操作:
上传编辑部同事家边牧的照片,让它来一段全球爆火的《APT.》。
照片中边牧正好伸着舌头,导致数字人效果略显出戏,但其他部分表现依然在线,尤其是腹部细节,做得很到位。
苏格兰国立美术馆用 X 光扫描梵高画作《农妇头像》,意外发现画布背后竟藏着一幅自画像,层层胶水和硬纸板封印多年。
于是我们尝试:让勃鲁盖尔笔下的名画《老妇人的肖像》播报这则新闻——一下子,吸睛指数拉满。
(文:AI好好用)