


当置身于一场音乐会,闭上眼睛,我们仍能凭借声音判断乐器的位置;在电影院,环绕音效让我们仿佛置身于电影场景之中。空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
然而,现有的技术大多基于固定的视角视频,缺乏对 360° 全景视频中空间信息的充分利用。今天,我们带来一项在空间音频生成领域具有里程碑意义的研究 —— OmniAudio:它能够直接从 360° 视频生成空间音频,为虚拟现实和沉浸式娱乐带来了全新的可能性。

论文地址:
https://arxiv.org/pdf/2504.14906
项目主页:
https://omniaudio-360v2sa.github.io/
开源仓库:
https://github.com/liuhuadai/OmniAudio
开源模型:
https://huggingface.co/omniaudio/OmniAudio360V2SA
开源数据库:
https://huggingface.co/datasets/omniaudio/Sphere360

项目介绍和效果展示

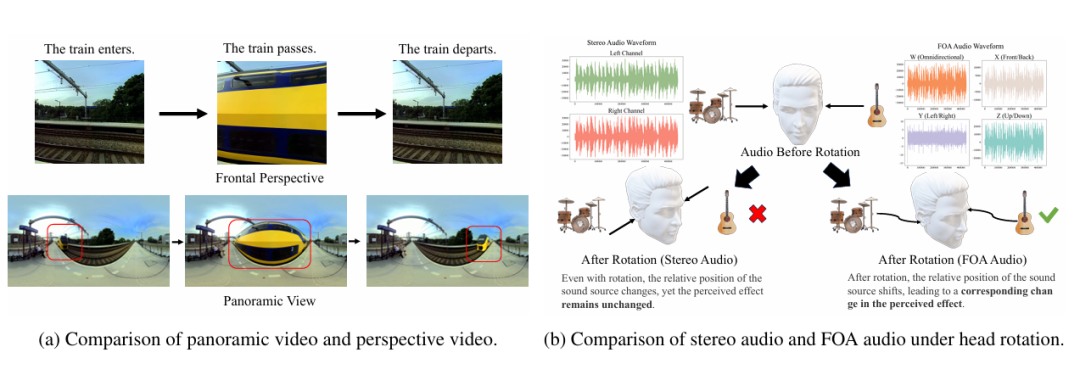
研究背景与动机:为何需要从 360° 视频生成空间音频?
传统的视频到音频生成技术主要关注于生成非空间音频(如单声道或立体声),这些音频缺乏方向信息,无法满足沉浸式体验对 3D 声音定位的需求。
此外,这些技术通常基于有限视角的视频,错过了全景视频所能提供的丰富视觉上下文。随着 360° 摄像头的普及和虚拟现实技术的发展,如何利用全景视频生成与之匹配的空间音频成为一个亟待解决的问题。

为应对这些挑战,该研究团队们提出了 360V2SA(360-degree Video to Spatial Audio)任务,旨在直接从 360° 视频生成 FOA(First-order Ambisonics)[1] 音频。
FOA 是一种标准的 3D 空间音频格式,能够捕捉声音的方向性,实现真实的 3D 音频再现。它使用四个通道(W、X、Y、Z)来表示声音,其中 W 通道捕捉整体声压,X、Y、Z 通道分别捕捉前后、左右和垂直方向的声音信息。与传统的立体声相比,FOA 音频在头部旋转时能够保持声音定位的准确性。

数据基石:Sphere360 —— 第一个大规模 360V2SA 数据集
数据是机器学习模型的基石,然而,现有的配对 360° 视频和空间音频数据极为稀缺。为此,研究团队设计了一个高效的半自动化 pipeline,用于构建 Sphere360 数据集。
首先,通过关键字(如 “skiing spatial audio 360”)在 YouTube 上爬取包含 FOA(First-order Ambisonics)音频和 360° 视频的候选素材,应用技术过滤器剔除不符合条件的视频,并采用频道为单位进行聚合式爬取,然后人工审核补充剩余视频。
在清洗环节,针对视频静态、音频静音、过多语音内容以及视音频不匹配等问题设计了具体检测算法,例如利用帧间均方误差(MSE)检测静态视频,使用滑动窗口和 dBFS 计算判定音频是否为静音,调用 SenseVoice [2] 模型检测语音含量,并使用 ImageBind [3] 检测音视频一致性,确保高质量对齐。
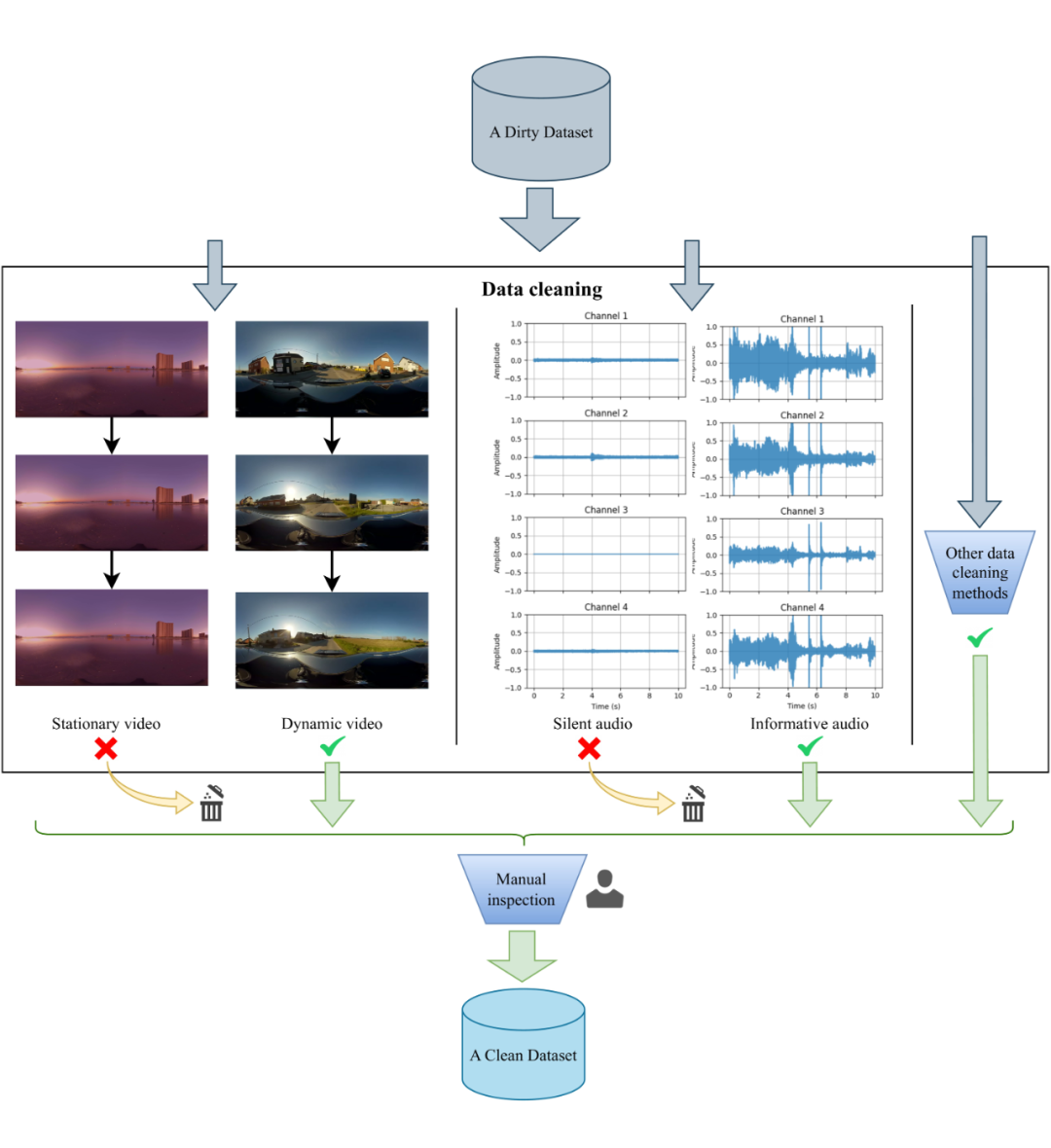
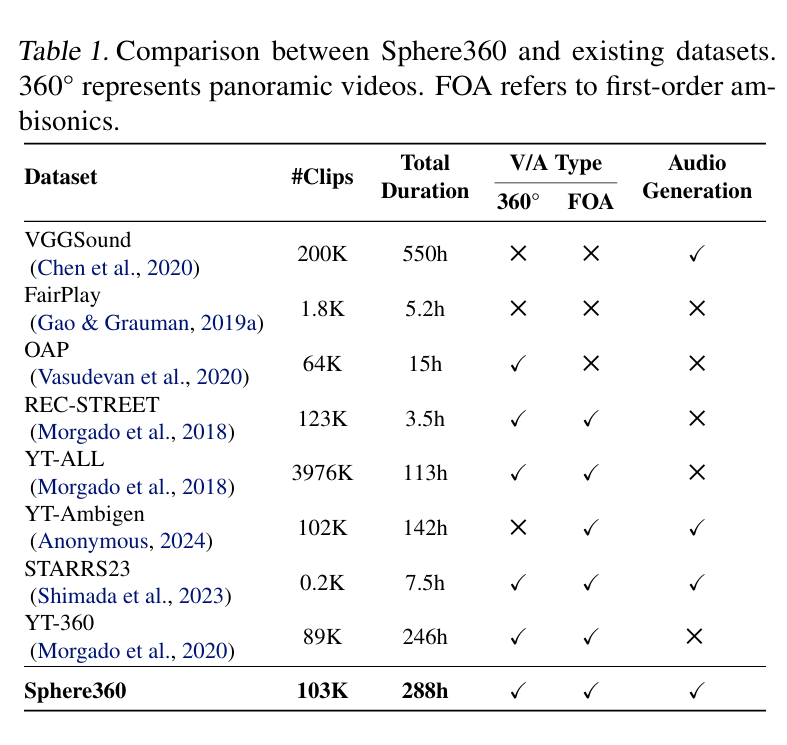
这是一个包含超过 103,000 个真实世界视频片段的数据宝库,涵盖 288 种音频事件,总时长达到 288 小时。收集到的视频既包含 360° 视觉内容,又支持 FOA 音频。
由于在数据清洗阶段已经剔除了静态视频、无声视频、过度人声视频以及音视频不匹配的视频,数据集具有高质量和高可用性。与其他现有数据集相比,Sphere360 在规模和适用性上均具有显著优势。

创新技术架构:OmniAudio 框架如何实现空间音频生成?
OmniAudio 的训练方法可分为两个阶段:自监督的 coarse-to-fine 流匹配预训练,以及基于双分支视频表示的有监督微调。
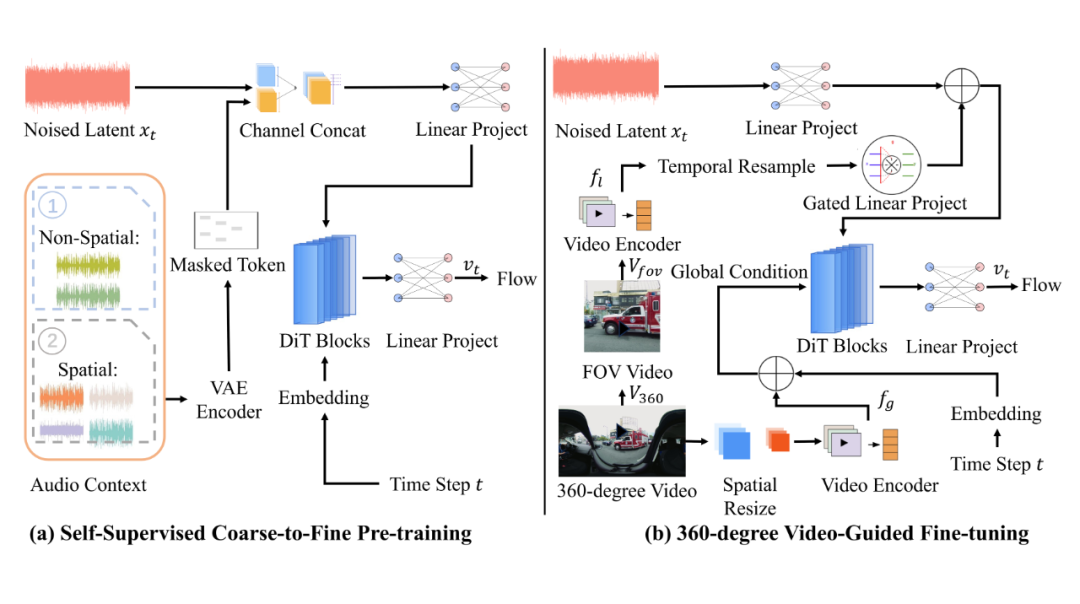
在第一阶段,研究团队针对数据稀缺问题,充分利用大规模非空间音频资源(如 FreeSound、AudioSet、VGGSound 等),先将立体声转换为“伪 FOA” 格式——W 通道为左右声道之和,X 通道为左右声道之差,Y、Z 通道置零——再送入四通道 VAE 编码器获得潜在表示。
对于这些潜在表示,团队以一定概率 pₘ 进行随机时间窗掩码(mask span 最小长度 lₘ),并将掩码后的潜在序列与完整序列一同作为条件输入至流匹配模型。
模型通过最小化掩码前后潜在状态的速度场差异,实现对音频时序和结构的自监督学习。这一“粗”阶段使模型掌握了通用音频特征和宏观时域规律,为后续空间音频精细化提供了坚实基础。
进入第二阶段时,研究团队仅使用真实的 FOA 音频数据,继续沿用掩码流匹配的训练框架,但此时模型的全部注意力集中在四通道的空间特性上。
通过对真实 FOA 潜在序列进行更高概率的掩码,模型不仅强化了对声源方向(W/X/Y/Z 四通道之间的互补关系)的表征能力,还在解码端提升了对高保真空间音频细节的重建效果。相较于仅以真实 FOA 进行直接拟合,此粗-细预训练策略显著改善了模型对空间特征的泛化能力与生成质量。
在完成自监督预训练后,团队将模型与双分支视频编码器结合,进行有监督微调。针对输入的 360° 全景视频,使用冻结的 MetaCLIP-Huge 图像编码器提取全局特征;同时,从同一视频中裁取 FOV(field-of-view)局部视角,亦通过相同编码器获得局部细节表征。
全局特征经最大池化后作为 Transformer 的全局条件,局部特征经时间上采样并与音频潜在序列逐元素相加,作为逐步生成过程中的局部条件。在保持预训练初始化参数的大致走向下,高效微调条件流场,从噪声中有针对性地“雕刻”出符合视觉指示的 FOA 潜在轨迹。
微调完成后,仅需在推理阶段采样学得的速度场,再经 VAE 解码器恢复波形,便可输出与 360° 视频高度对齐、具备精确方向感的四通道空间音频。
通过上述两阶段训练,OmniAudio 不仅在音频生成质量上实现了从宏观到微观的跨域迁移,也借助视觉条件保证了空间定位的准确性,为 360V2SA 任务奠定了坚实的技术基础。

实验与结果:OmniAudio 的卓越性能
在实验设置中,研究团队在 Sphere360-Bench,以及来自 YT-360 的外部分布测试集 YT360-Test 上进行有监督微调与评估。视频帧率统一为 8FPS,音频采样率为 44.1kHz。评估指标分为两大类:
客观指标:
1. 非空间音频质量:采用 Fréchet Distance(FD)[4] 衡量生成音频和真实音频在 OpenL3 特征空间的分布差异(越低越好);采用 Kullback-Leibler 散度(KL)[5] 衡量两者标签分布差异(越低越好);
2. 空间音频准确度:按照 Heydari 等(2024)[6] 的方法,计算声源方向估计误差,包括绝对方位角误差 Δabsθ、绝对仰角误差 Δabsϕ,以及综合角度误差 ΔAngular(均越低越好)。
主观指标:通过人工打分得到空间音频质量 MOS-SQ 和视音对齐保真度 MOS-AF,两者均为 0–100 分(越高越好),均报告平均值与标准差。
对于比较基线,研究人员实现了四套系统:
1. Diff-Foley + AS [7]:使用 Diff-Foley 生成非空间音频后接 Audio-Spatialization;
2. MMAudio + AS [8]:使用 MMAudio 生成非空间音频后接 Audio-Spatialization;
3. ViSAGe(FOV / 360)[9]:分别以 FOV 和全景视频为输入的空间音频生成模型;
4. OmniAudio:文章的方法,包含预训练与双分支微调。
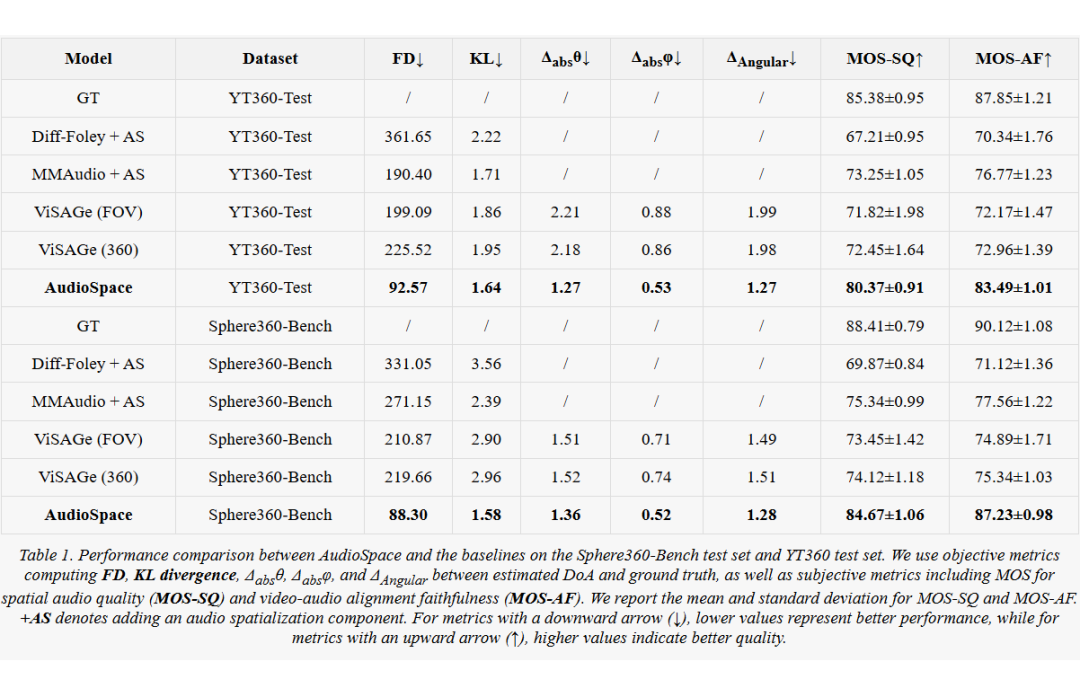
在主要结果中,OmniAudio 在两套测试集上均显著优于所有基线。
-
在 YT360-Test 上,OmniAudio 获得 FD=92.57、KL=1.64,相较于 Diff-Foley+AS(FD=361.65、KL=2.22)和 MMAudio+AS(FD=190.40、KL=1.71)均大幅降低;同时 ΔAngular=1.27(ViSAGe≈1.99),空间定位误差降低。
-
在 Sphere360-Bench 上,OmniAudio 同样取得 FD=88.30、KL=1.58、ΔAngular=1.28,超越 ViSAGe(360)的 FD≈219.66、KL≈2.96、ΔAngular≈1.51。
在人机主观评估中,OmniAudio 分别在空间音频质量和视音对齐两项上获得 MOS-SQ=84.67±1.06、MOS-AF=87.23±0.98(Sphere360-Bench),而最优基线仅为 MOS-SQ≈75–77、MOS-AF≈76–77,体现出 OmniAudio 合成结果在清晰度、空间感及与画面同步性方面均更佳。
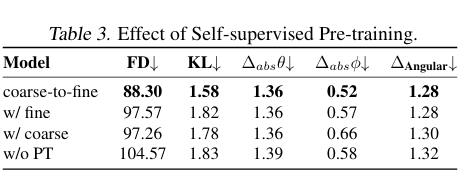
此外,研究团队进行了消融实验以验证各模块贡献:
-
预训练策略:完整的 Coarse-to-Fine 预训练模式将 FD 从无预训练时的 104.57 降至 88.30;仅 Fine 或仅 Coarse 均不及二者结合;
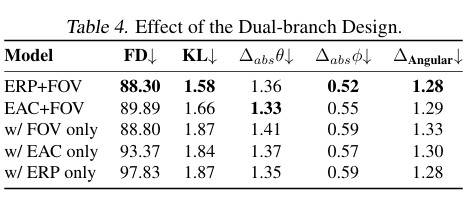
-
双分支设计:ERP+FOV(全景+局部)组合在 FD、KL、ΔAngular 等指标上均优于仅 ERP、仅等距立方体(EAC)或仅 FOV 输入;
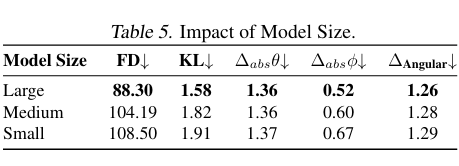
-
模型规模:从 Small(291M)到 Medium(472M)再到 Large(1.2B),性能逐步提升,Large 模型在 FD、KL 和空间误差上均达最优。
综合来看,OmniAudio 通过充分利用非空间与 FOA 数据的自监督预训练,以及全局与局部信息融合的双分支微调,在 360V2SA 任务中取得了全面领先的效果。

Q&A
Q1:OmniAudio 如何处理复杂的动态场景?
A1:OmniAudio 通过其双重分支架构和自监督预训练策略,能够有效处理复杂的动态场景。双重分支架构结合了全景视频的全局上下文和局部视角的细节信息,而自监督预训练则使模型能够从大规模非空间音频数据中学习到通用的音频模式。这种结合使得 OmniAudio 在面对动态场景时,能够生成与视觉内容高度一致的空间音频。
Q2:自监督预训练策略和双重分支设计的效果如何
A2:消融实验验证了自监督预训练策略和双重分支设计的有效性。实验结果表明,粗到精的预训练方法和双重分支架构都能够显著提升模型在所有指标上的表现.
Q3:如何评估 OmniAudio 生成音频的空间定位准确性?
A3:OmniAudio 的空间定位准确性通过多种客观指标进行评估,包括方向到达角误差(Δabsθ、Δabsφ 和 ΔAngular)。这些指标量化了生成音频与真实音频在方向上的差异。实验结果显示,OmniAudio 在这些指标上均优于基线模型,表明其生成的音频在空间定位上具有较高的准确性。
Q4:OmniAudio 的模型大小和性能如何平衡?
A4:OmniAudio 提供了不同大小的模型配置,包括大型(1.2B 参数)、中型(472M 参数)和小型(291M 参数)模型。实验结果表明,模型大小与性能之间存在权衡。大型模型在生成质量和空间精度上表现最佳,而小型模型则在计算效率上更具优势。未来的工作将探索更高效的模型架构,以实现性能和效率的平衡。

未来展望:OmniAudio 的潜力与方向
尽管 OmniAudio 取得了令人瞩目的成果,但研究者们也指出了其局限性。例如,在面对包含大量发声物体的复杂场景时,模型在事件类型识别上仍存在挑战。未来的工作将探索更好地理解多目标 360° 视频的技术,并通过持续收集和扩充数据集,进一步推进该领域的发展。
OmniAudio 的出现,标志着我们在利用人工智能技术提升沉浸式媒体体验方面迈出了重要一步。通过直接从 360° 视频生成空间音频,它为我们打开了一个全新的声音世界的大门。随着研究的深入和技术的成熟,我们期待未来能够看到更多创新的应用场景,让空间音频成为我们日常生活的一部分。

(文:PaperWeekly)