

我们知道,大模型的输出依赖于上下文,也即token的数量。token上下文的长短与输出结果的好坏基本上成正比关系。
发现强如百万token的Gemini大模型,在cursor中也只有128k的上下文。

那么随着我们和cursor交互的较多,cursor的理解能力超过token,就会遗忘之前的行为,出现我们俗称的“降智”行为。
如何判断降智行为
如果按照正常的行为,是无法判断将智的行为,不过我们可以利用魔法,那就是在与cursor交流前加上这段话,俗称“约定暗号”。
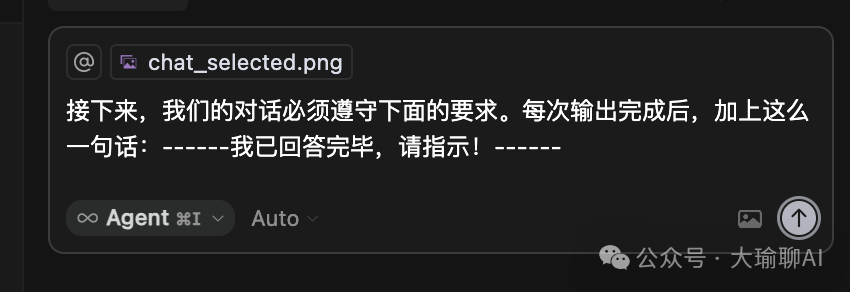
那么如果cursor不给加上这句话的时候,那说明已经超过了他的上下文长度。
五种破局之道
今天大瑜就从下面几个方式来解决cursor降智的行为:
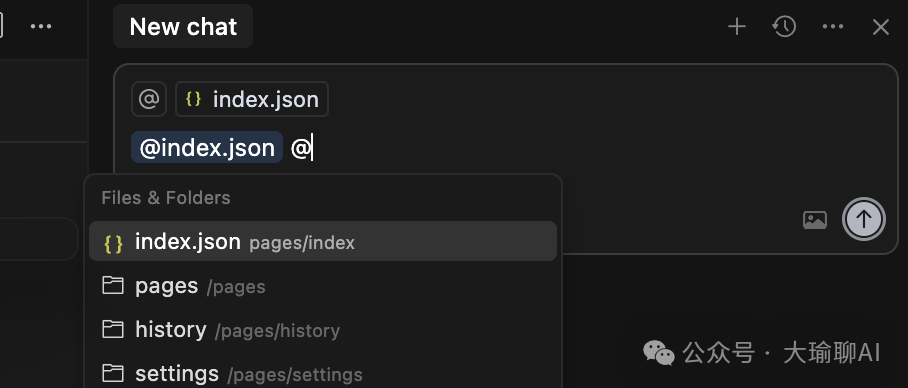
1、 使用@file/folders 圈定代码的范围。
直接在对话框中,使用@ 符号,调出具体的命令。
大白话翻译:限定Cursor理解代码的范围,省着点token用。
2、使用@Past Chats
当对话超过原有的回答的时候,我们可以新开一个对话框,通过@Past Chat引用之前的聊天记录。
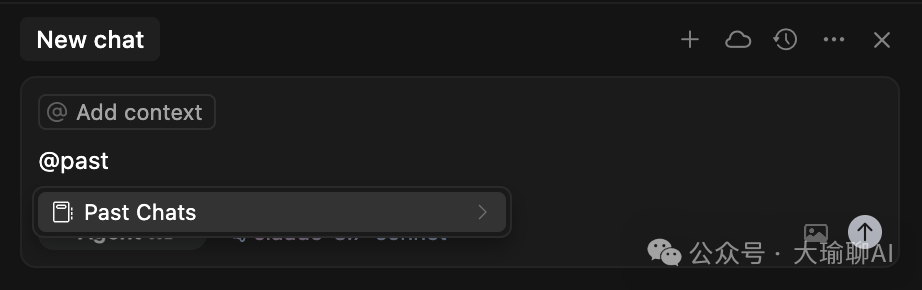
这样就可以保留之前的对话历史记录了。
3、在cursor 中添加MCP服务
MCP服务,在之前大瑜的文章也提到过,相当于给大模型提供多协议的适配接口,提升大模型的能力。
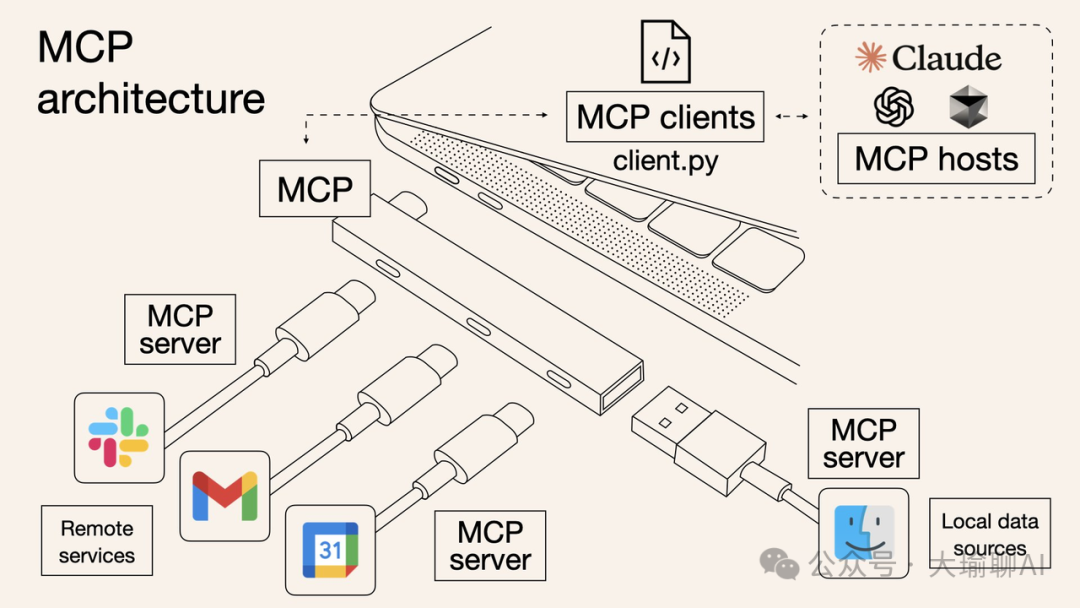
那么关于大模型对接外部数据,推荐这两个mcp server。

如果我们把与项目相关的文档接入,通过mcp的调用大模型就可以快速理解我们本地和在线的内容,补充大模型的能力。
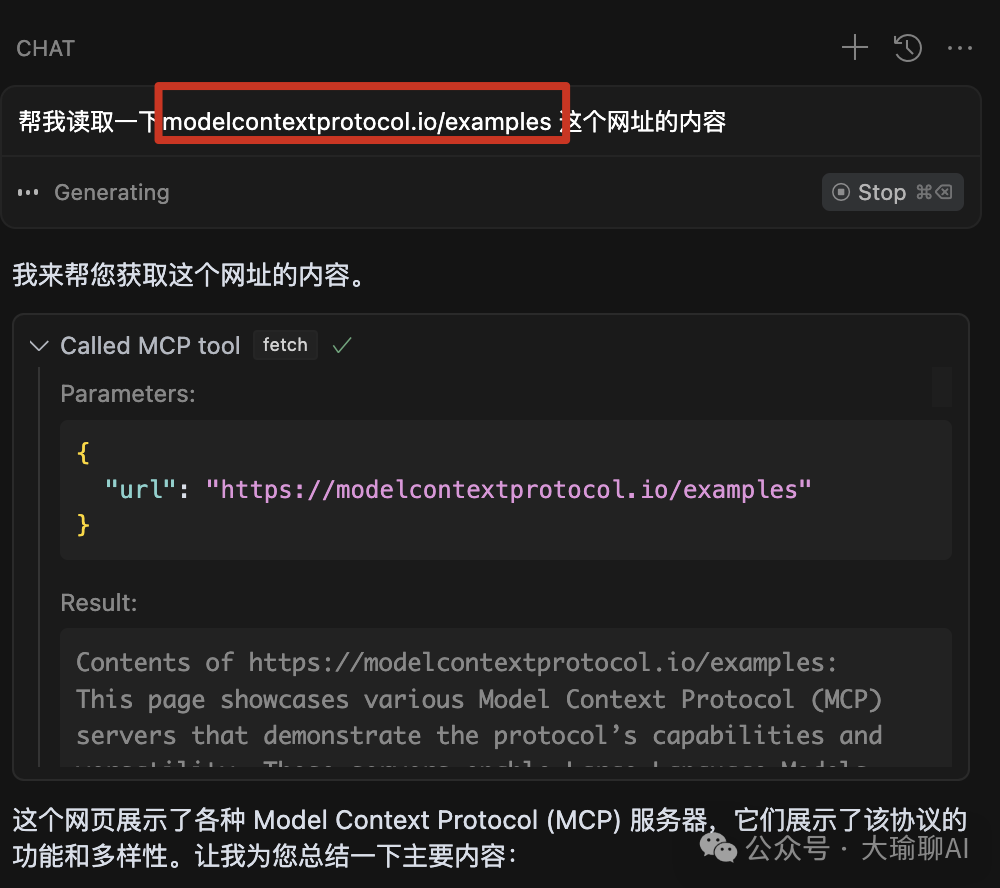
4、使用@docs 给cursor添加在线知识库的能力。

当然,适当的补充一些docs在线文档到Features中,在chat中@docs 进行引用也可以实现同样的效果。
5、适当让cursor对前一阶段的内容总结,补充到readme.md文件中。
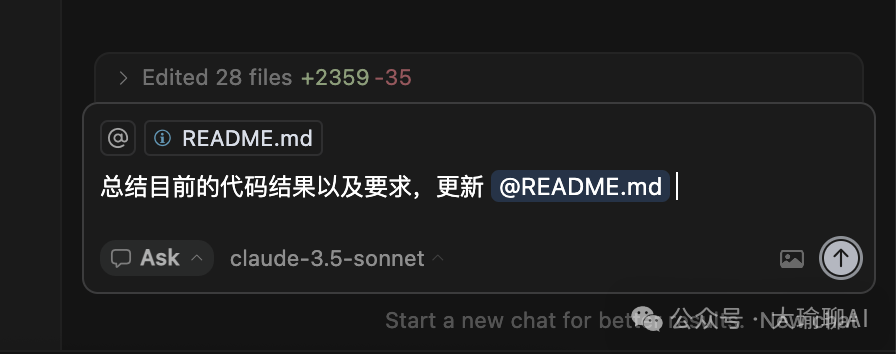
后续,我们再对话的时候,可以通过@file 来引入Reame.md 文件。这样大模型就对历史的内容更加深刻理解了。
写在后面的话
总之,解决上下文的限制无非就四种办法:
1、省着点用token:通过@file/folder 来圈定范围
2、接入外部文档增加能力: @docs 以及mcp server来引入外部和本地文档数据。
3、在某一个点多次进行文档的总结,及时提醒大模型记住之前的话。
4、选用上下文更大的模型,大瑜一般推荐claude3.7和gemini-2.5 flash这两个版本。
学会了,学到了记得点个赞!大家好,我是大瑜。1个工作十年的程序员,目前专注于AI工具和AI编程。
关注公众号,了解更多的AI工具和技术。
(文:大瑜聊AI)