

今天是2025年7月5日,星期六,北京,晴
我们来看开源相关进展,看两个问题。
一个是大模型用于文本纠错开源工具,有一些模型跟数据,可以做个记录。
另外,在语音方面,也有一些语音转写或者对话的大模型,也做个技术汇总,看看有哪些模型,哪些数据,哪些tokenizer。
一、大模型用于文本纠错开源工具
先看NLP进展,中文拼写和语法纠错大模型,https://github.com/TW-NLP/ChineseErrorCorrector,支持中文拼写和语法错误纠正,并开源拼写和语法错误的增强工具。
在具体功能上,支持缺字漏字、错别字错误、缺少标点、错用标点、主语不明、谓语残缺、宾语残缺、其他成分残缺、虚词多余、其他成分多余、主语多余、语序不当、动宾搭配不当、其他搭配不当共 14种错误。

在开放模型上,大模型训练代码,给出了多个模型,有4B、7B和1.5j几个版本,如https://huggingface.co/twnlp/ChineseErrorCorrector3-4B,具体如下:
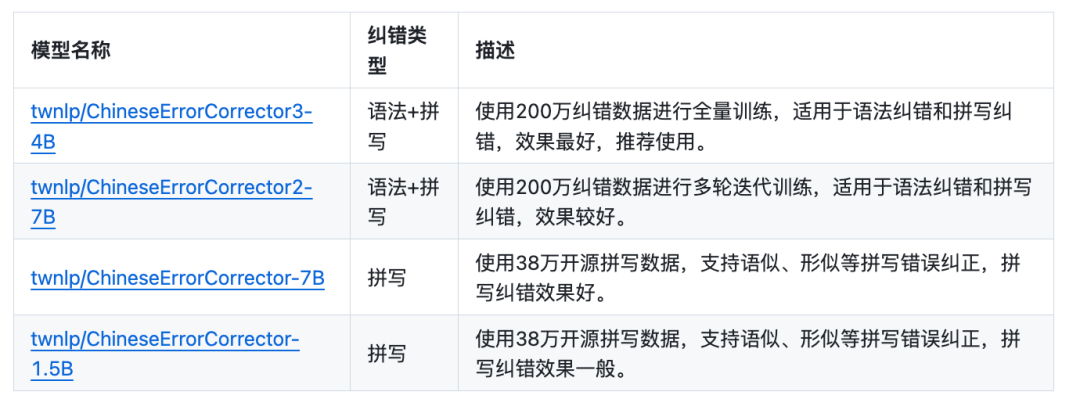
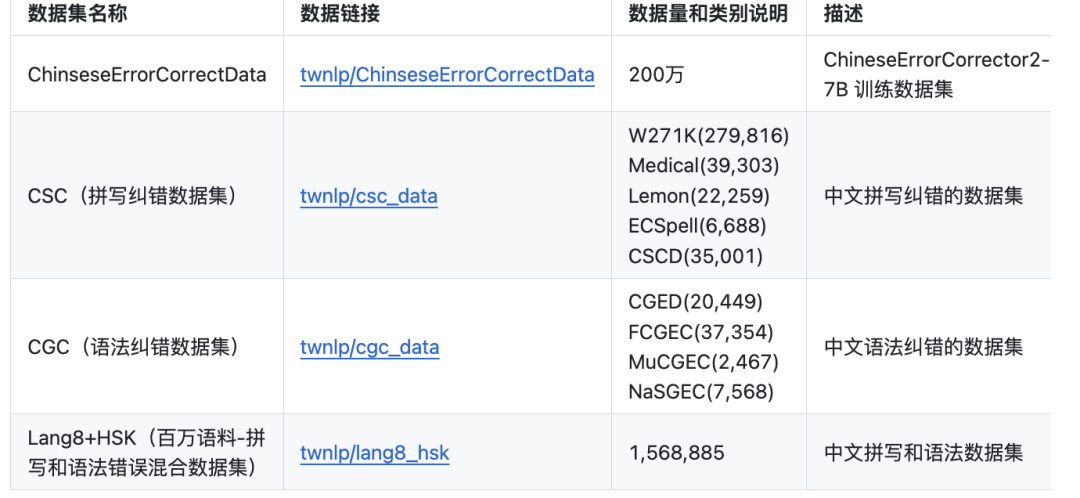
在训练数据上,使用200万纠错数据进行全量训练,适用于语法纠错和拼写纠错,也开源了数据集,数据集如下:
二、语音大模型的技术总结
语音大模型进展,Awesome-SpeechLM-Survey,涵盖了50多种语音语言模型,提供丰富的模型资源,《Recent Advances in Speech Language Models: A Survey》: https://github.com/dreamtheater123/Awesome-SpeechLM-Survey
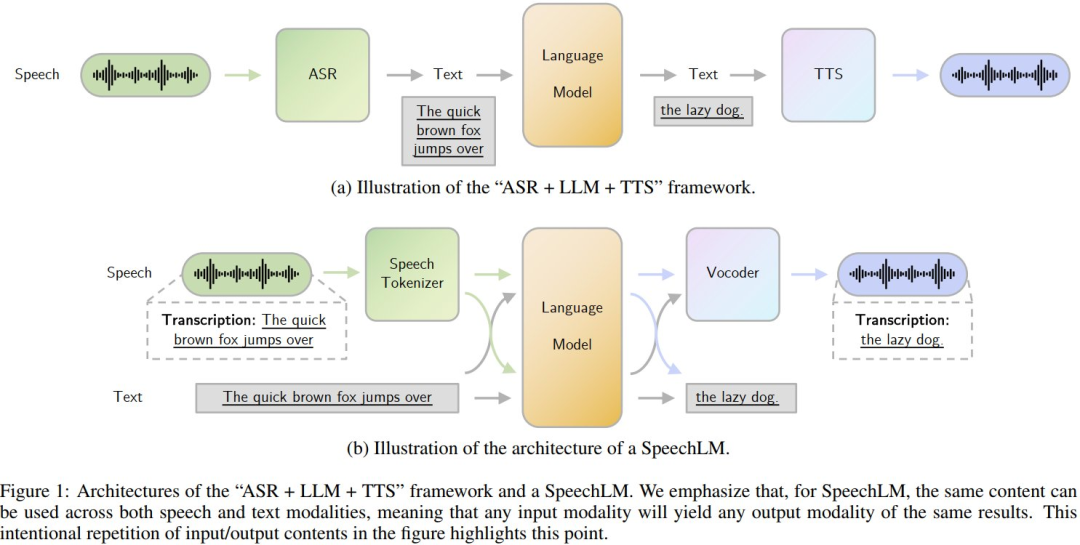
其中重点的,可以看:
1、目前有哪些训练数据集:
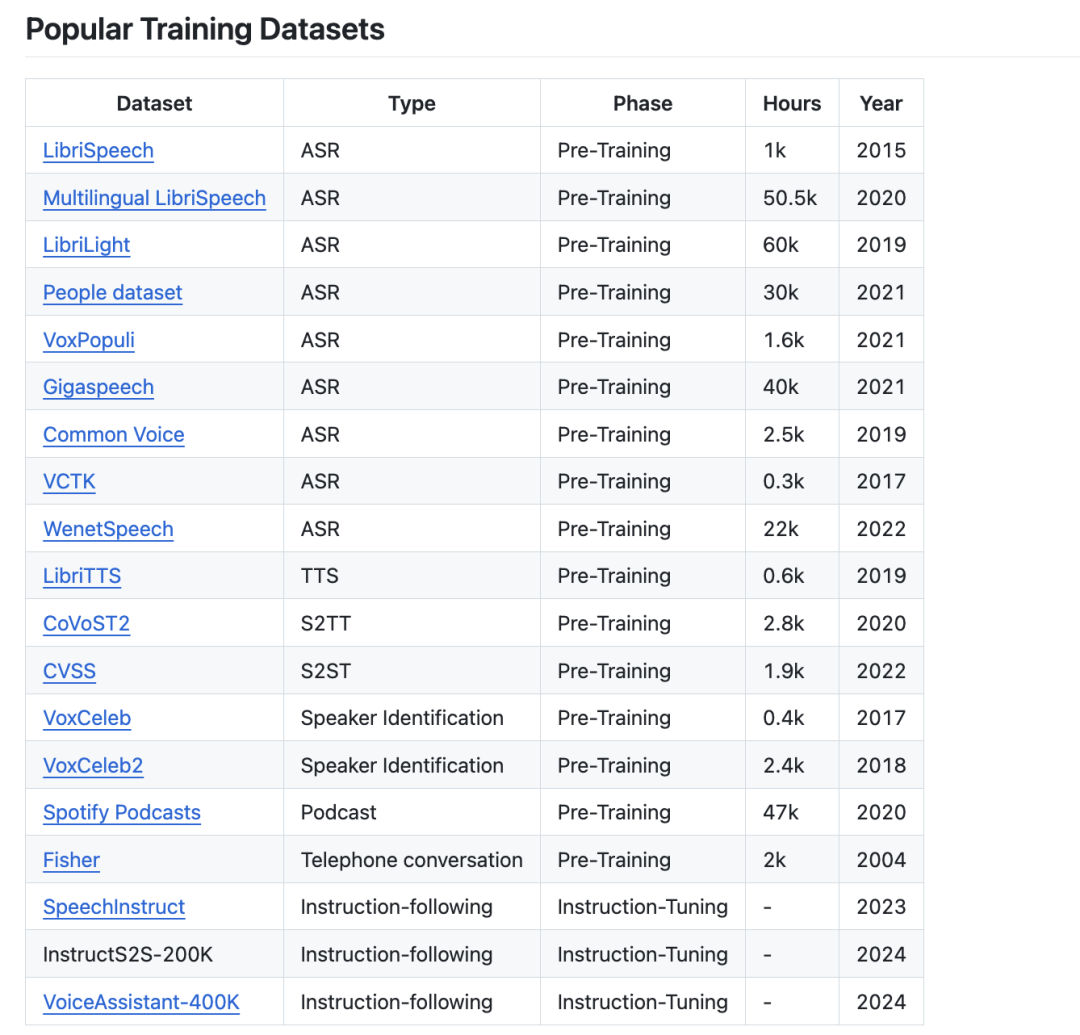
2、目前对于语音的tokenizer:
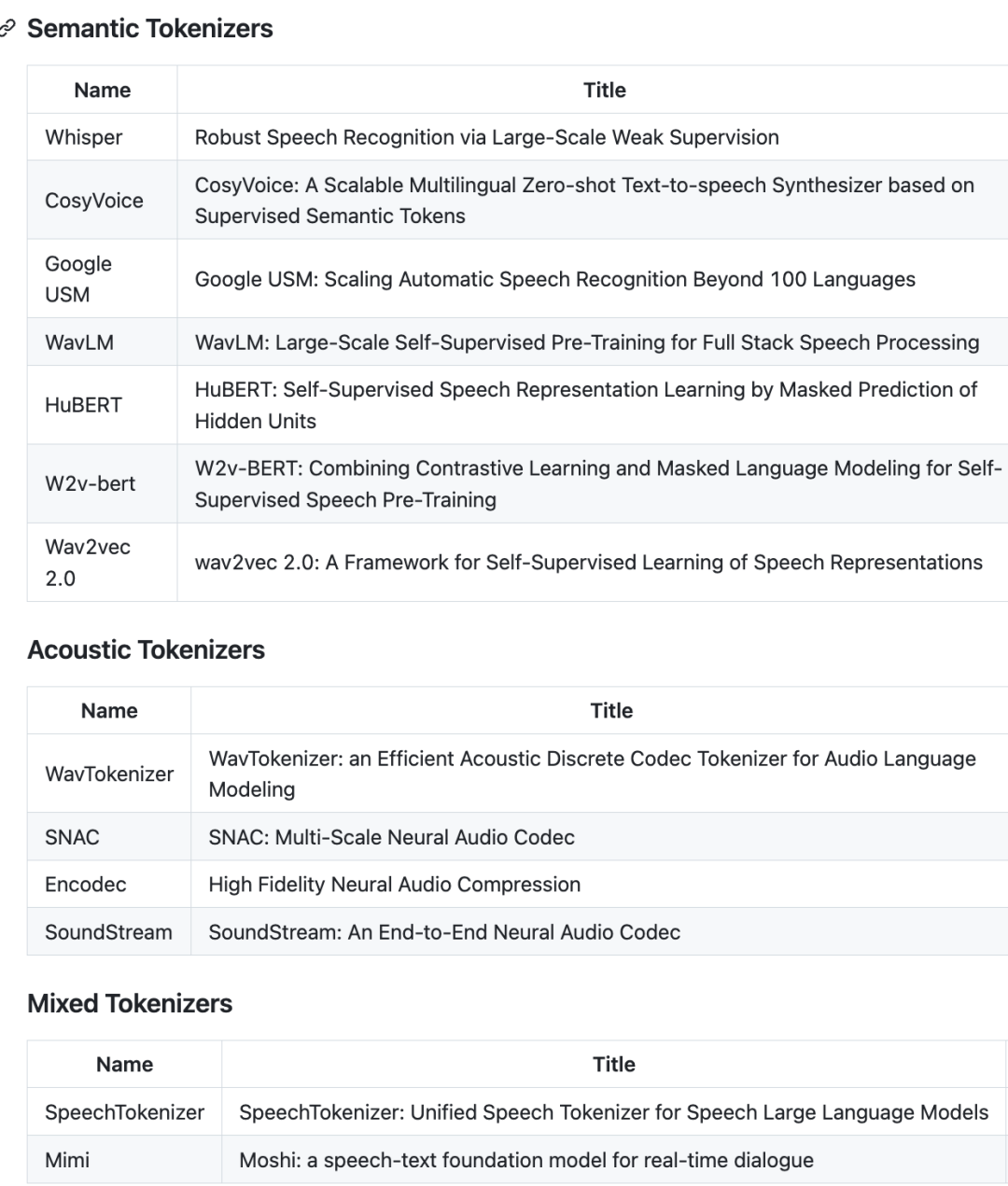
3、目前主流的语音大模型:
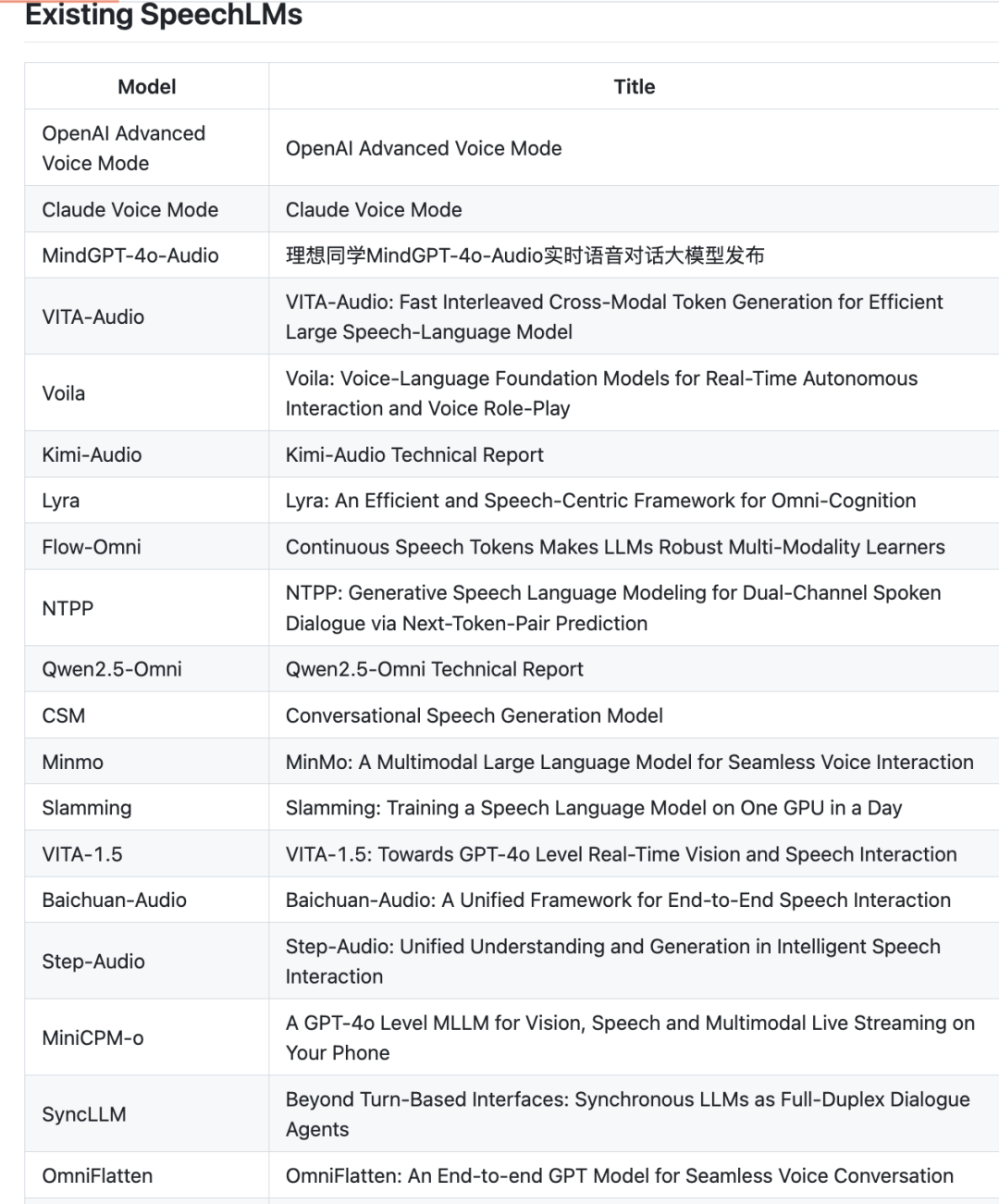
参文献
1、https://github.com/TW-NLP/ChineseErrorCorrector
2、https://github.com/dreamtheater123/Awesome-SpeechLM-Survey
(文:老刘说NLP)