

AI 医生比真人大夫还准?

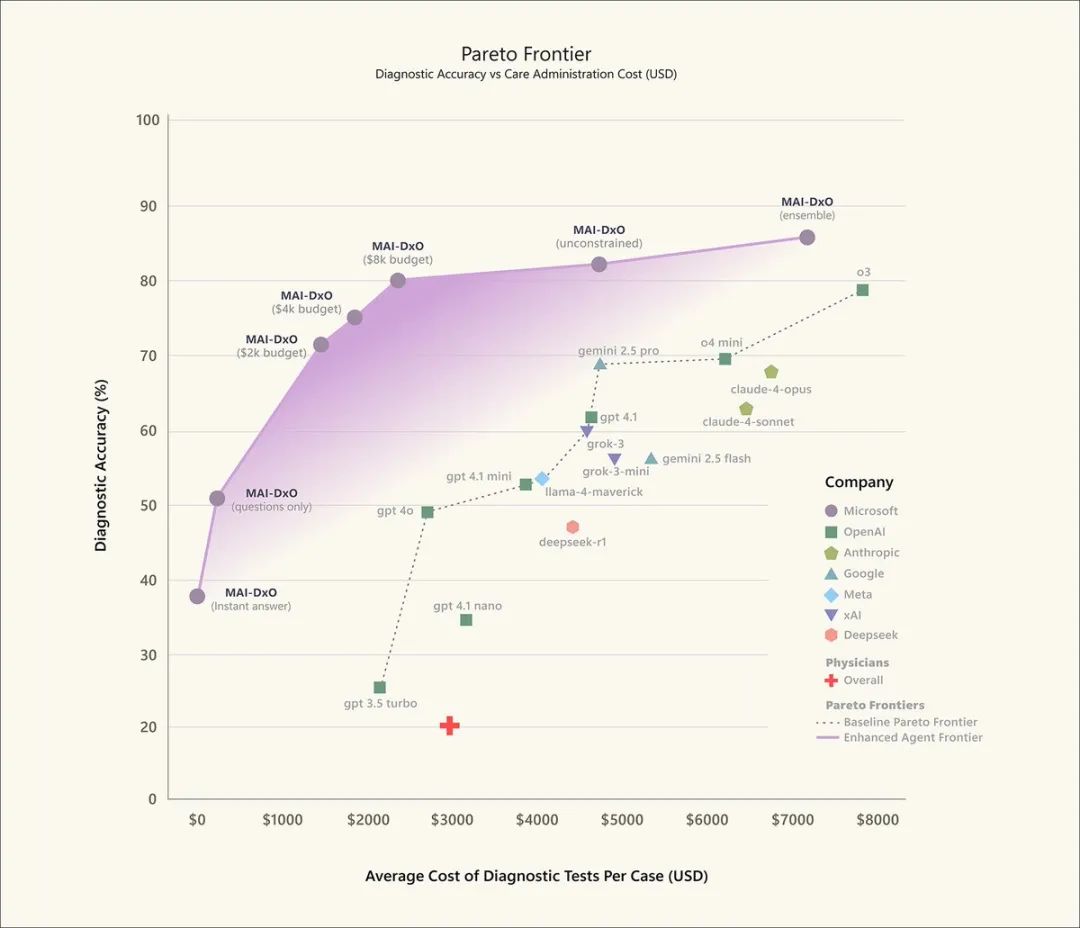
刚刚,微软CEO Satya Nadella 宣布:他们的AI诊断系统MAI-DxO在新英格兰医学杂志(NEJM)的304个病例测试中,诊断准确率达到85.5%,而同样病例下,经验丰富的医生准确率只有20%。
这不是在开玩笑。
不再是选择题游戏
以往测试AI医疗能力,都是让它做美国医师执照考试(USMLE)的选择题。
而AI 们早就能考出接近满分的成绩了。
但选择题能代表真实看病吗?
显然不能。
真实的诊断过程是这样的:病人说「我咳嗽发烧」,医生要决定问什么问题、做什么检查、怎么一步步缩小范围,最后得出诊断。
这就是微软团队做的事:
他们把NEJM每周发布的最复杂、最具挑战性的病例,转化成了互动式诊断挑战。

这个叫SDBench的基准测试,让AI像真医生一样工作:
-
从初始症状开始 -
逐步询问病史 -
决定做哪些检查 -
根据结果调整思路 -
最终给出诊断
值得注意的是,每个检查都需要「花钱」,就像真实世界一样。
这样既能看准确率,也能看成本控制。
虚拟医生团队的力量
MAI-DxO的秘密武器是什么呢?
它不是一个AI,而是一群AI。
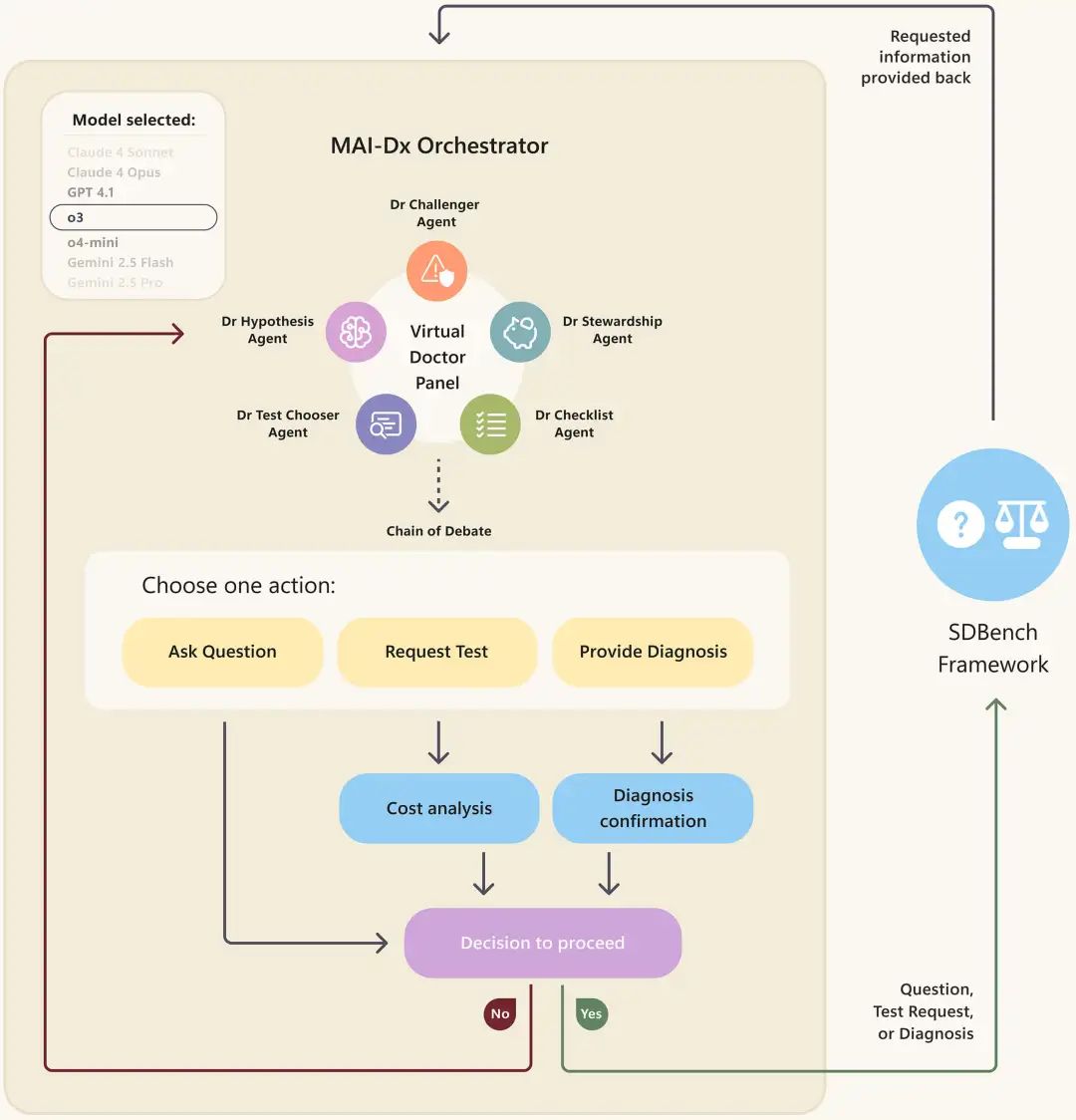
这个系统模拟了一个虚拟医生团队,每个「医生」有不同的诊断思路。
他们会:
-
提出不同的假设 -
建议不同的检查 -
互相验证推理 -
最后达成共识
就像真实世界的会诊。
最神奇的是,这个方法让所有测试的基础模型性能都得到提升——不管是GPT、Claude、Gemini还是Llama。
准确又省钱
测试结果让人震惊:
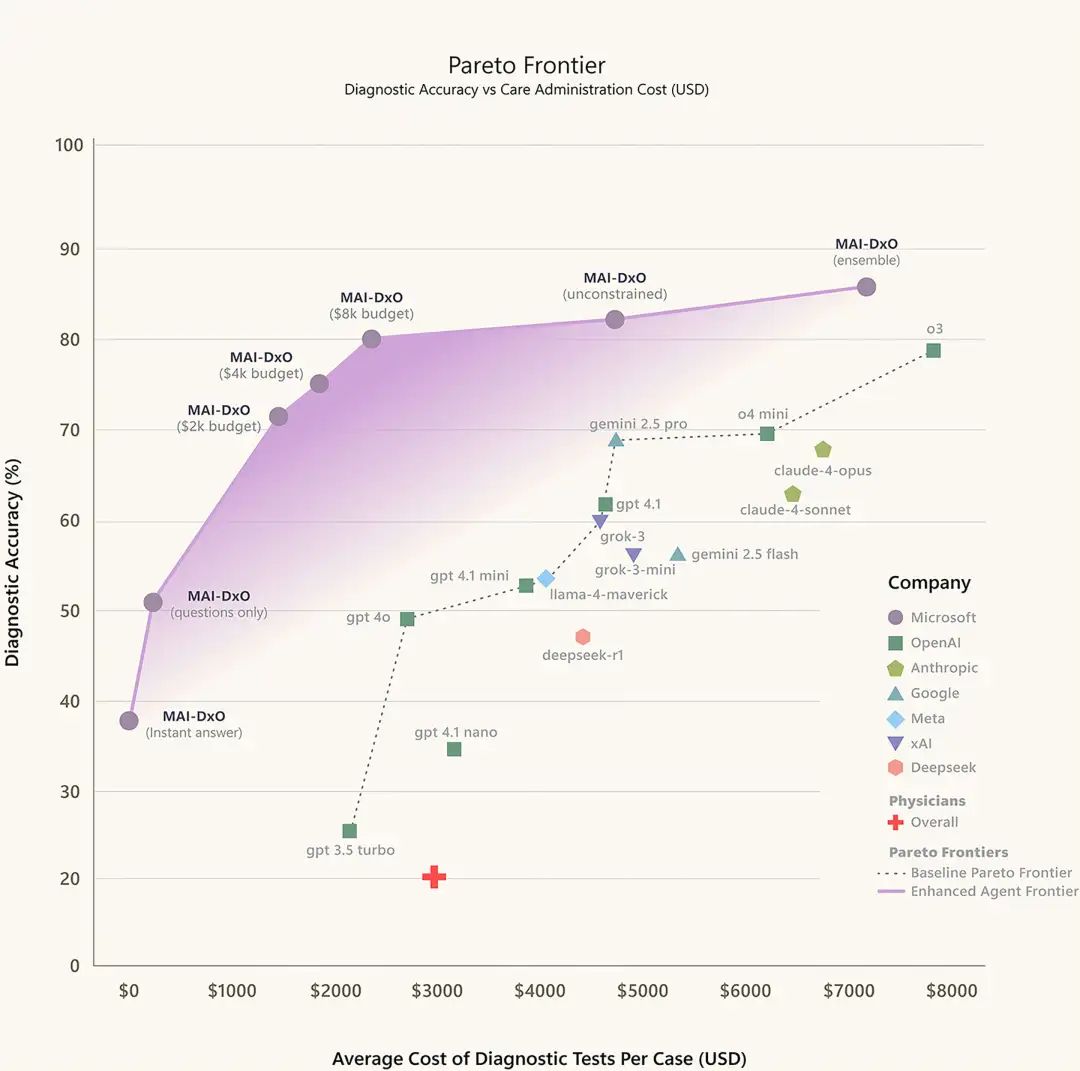
MAI-DxO不仅诊断准确率最高,检查成本还比医生更低。
既准又省,这在医疗领域可谓是意味重大。
美国医疗支出接近GDP的20%,其中25%被认为是浪费的——对患者治疗没有实质帮助。
如果AI能减少不必要的检查,这将是巨大的进步。
质疑声四起
当然,这么惊人的结果立刻引发了激烈讨论。

Chunhua Liao(@chunhualiao)直接发问:
医生只有20%的准确率?这是什么意思?
意思是我不止白花了许多钱,还白挨了很多针?
Haydar Jawad(@Haydar_A_Jawad)更是写了一大段质疑:
论文从未讨论如果用虚假症状测试会怎样。比如编造一个不存在的检查指标,或者虚构一种疾病,MAI-DxO会不会还能「自信地」给出诊断和检查建议?这会暴露它只是个高级关联引擎,而非真正理解医学。
EconodemetricsResearch(@EconodemetricsR)则关注评判标准:
准确率是怎么定义的?谁来设定诊断准确的基准?
他们用Grok分析后发现,这个研究的一个局限是:只有与NEJM最终诊断完全一致才算「正确」。
但实际医疗中,可能有多个合理的诊断假设。
医生会失业吗?
微软团队自己也在FAQ中回答了这个问题:
不会。
他们认为AI是医生的补充,而非替代。
医生的工作远不止诊断——还需要处理模糊情况、建立信任、安抚病人和家属。
但Ricky(@itsrickyszn)的评论可能代表了很多人的想法:
医生们最好学学编程。
更现实的观点来自Anshul Badhwar医生(@HeartblockedAB):
很期待试用这些模型。但真正的挑战是如何向真实病人提问。医学最难的部分之一,是在特定病人的背景下,恰当地权衡每个症状。
下一步在哪?
微软强调,这还只是研究阶段,距离临床应用还有很长的路:
-
需要在真实临床环境中验证 -
需要监管框架 -
需要确保安全性和可靠性
他们正在与医疗机构合作,进行严格的测试和验证。
但方向已经很清晰了。
当AI能够结合广度和深度的专业知识,展现出超越任何单个医生的临床推理能力时,医疗的未来正在被重新定义。

不过另一个问题是:
当我们创造出比人类自身更会看病的AI时,我们是否真准备好接受它的诊断?
或者说,当AI告诉你「你有病」时,你是相信那个85.5%的准确率,还是相信那个20%准确率但有温度的人类医生?
也许真正的答案是:不是选择题,而是人机协作的新医疗时代。
AI 负责精准,而人类则负责温暖。
诊断交给算法,关怀留给医生。

The Path to Medical Superintelligence: https://microsoft.ai/new/the-path-to-medical-superintelligence/
(文:AGI Hunt)