

机器之心编辑部
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。这一趋势在国内也得到印证。
刚刚,上海 AI Lab 宣布创造性构建了 “加速训练营”(InternBootcamp),通过对评价建模,与大模型进行交互并提供反馈,从而使大模型持续进化,获得解决复杂推理任务的能力。
通过上述方法以及一系列通专融合底层技术架构创新,书生・思客(InternThinker)实现在奥赛级数学、科学对象理解与推理、算法编程、棋类游戏、智力谜题等多个专业任务同步学习演进,并在多任务混合强化学习过程中出现智能 “涌现时刻”。
随着 InternThinker 专业推理能力升级,它成为我国首个既具备围棋专业水平,又能展示透明思维链的大模型。在实验室科研人员的布局和着子中,蕴含数千年智慧的围棋成为了科学探索的 “试应手”。
围棋作为一项具有四千多年历史的智力竞技项目,因其独特的复杂性和对人类智能的深刻体现,可作为衡量人工智能专业能力最具代表性的任务之一。2016 年 AlphaGO 一战成名,随后,AI 在棋力、效率、通用性等方面均有显著提升,但其具体推理过程仍为 “黑盒”,即便能输出胜率评估和落子概率,亦无法用人类语言解释 “为什么某一步更好”。典型表现为:AI 有时会下出违背人类直觉的 “天外飞仙” 棋步,事后被证明有效,但当时难以解释。
本次升级后的 InternThinker,在围棋任务上不仅具备较强的专业水平,在大模型中率先实现打破思维 “黑盒”,运用自然语言就对弈过程进行讲解。目前 InternThinker 已开启公测,所有用户均可以随时随地与之对弈(公测链接:https://chat.intern-ai.org.cn/)。
用户在与 InternThinker 对弈的过程中,大模型化身为循循善诱的 “教练”,它能全面地分析当前局面形势,对不同的落子点进行判断和对比,并给出明确的结果,让用户了解每一步棋背后的推理过程和决策依据,从而帮助用户更好地理解和学习围棋。
李世石在与 AlphaGO 交战的第四盘 78 手下在 L11,被称为 “神之一手”,直接扭转局势赢下一局。在研究人员对这一名局的复现中,InternThinker 评价这步棋 “相当刁钻…… 这步棋完美解决 L11 的威胁,重新确立中央控制权,为后续进攻埋下伏笔。” 随后它给出了落子在 L10 的应对策略。
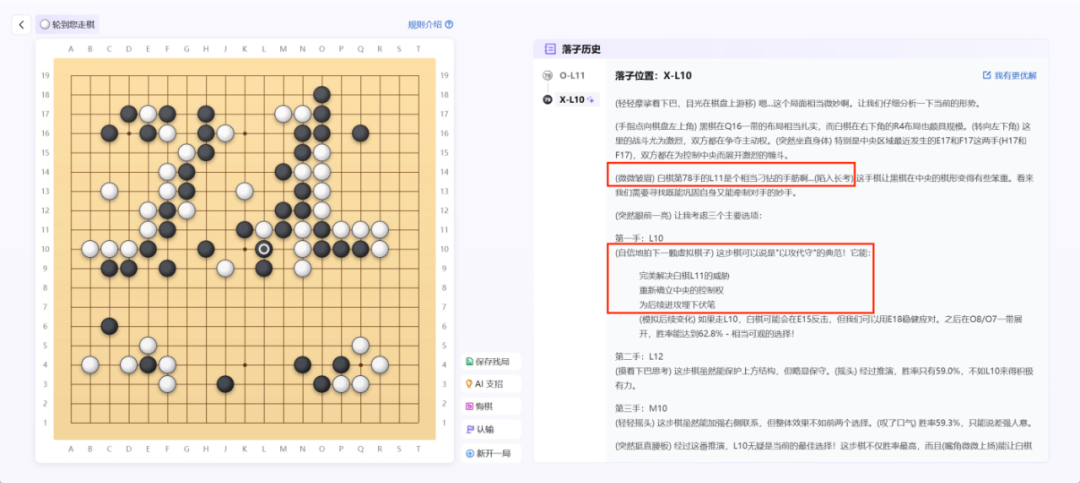
InternThinker 应对李世石 “神之一手”
InternThinker 还具备多样化的 “语言” 风格,极具 “活人感”。比如,当用户下了一步好棋,它会加油鼓励:“这步棋相当有力,可以说是‘以攻代守’的好手”;也会冒出毒舌锐评:“可以说是‘不是棋’的选择”。
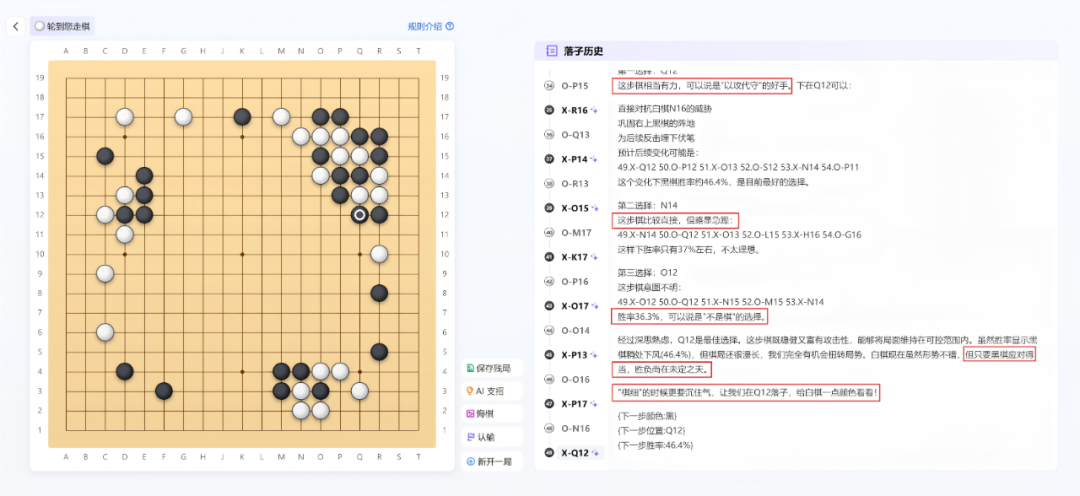
InternThinker 多样化的语言风格
在棋力方面,InternThinker 未来仍有提升空间。新生代世界围棋冠军王星昊九段在与其对弈后评价道:“能解说思考过程的 AI 还是第一次见,感觉它分析得非常好;从布局看棋力可能在职业 3-5 段之间。”
InternBootcamp:“体验” 即学习,探索大模型推理能力提升新范式
InternThinker 强大的推理能力及在围棋任务上的突破,得益于其创新的训练环境。针对复杂的逻辑推理任务,如何准确地获得过程和结果反馈尤为关键,为此,研究人员搭建了大规模、标准化、可扩展的可交互验证环境 InternBootcamp—— 这相当于为模型创造了一个 “加速训练营”,使其可以高效习得专业技能,快速 “成长”。
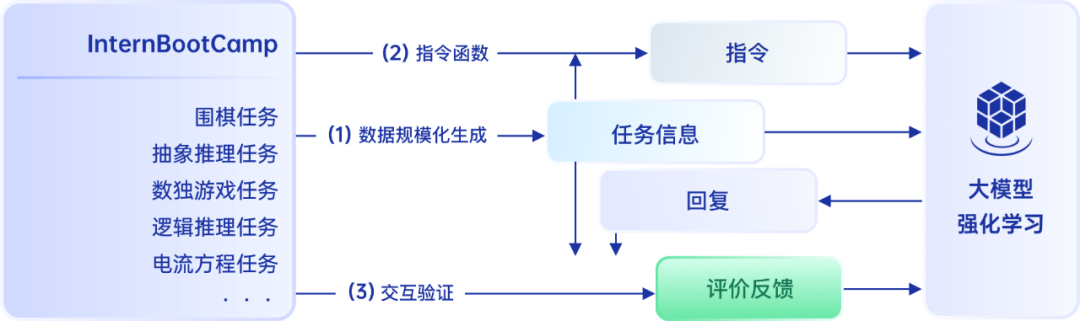
InternBootCamp 与大模型交互流程
基于代码智能体自动化构造,InternBootCamp 包含超 1000 个验证环境,覆盖广泛的复杂逻辑推理任务,能有效帮助大模型领域研究者基于强化学习开展探索。InternBootcamp 可以批量化、规范化生成难度可控的推理任务,如奥赛级数学、科学对象理解与推理、算法编程、棋类游戏、智力谜题等,并与大模型进行交互和提供反馈。通过不同专业知识大规模构造和混合训练,使大模型跳出基于数据标注获取问题和答案的繁琐模式,同时避免传统奖励模型的欺骗,从而实现大模型推理能力提升的新范式。
除围棋外,在其他任务中 InternThinker 也有不俗表现。通过对多种任务的混合强化学习,InternThinker 在包括数十个任务的测试集上的平均能力超过 o3-mini、DeepSeek-R1 以及 Claude-3.7-Sonnet 等国内外主流推理模型。
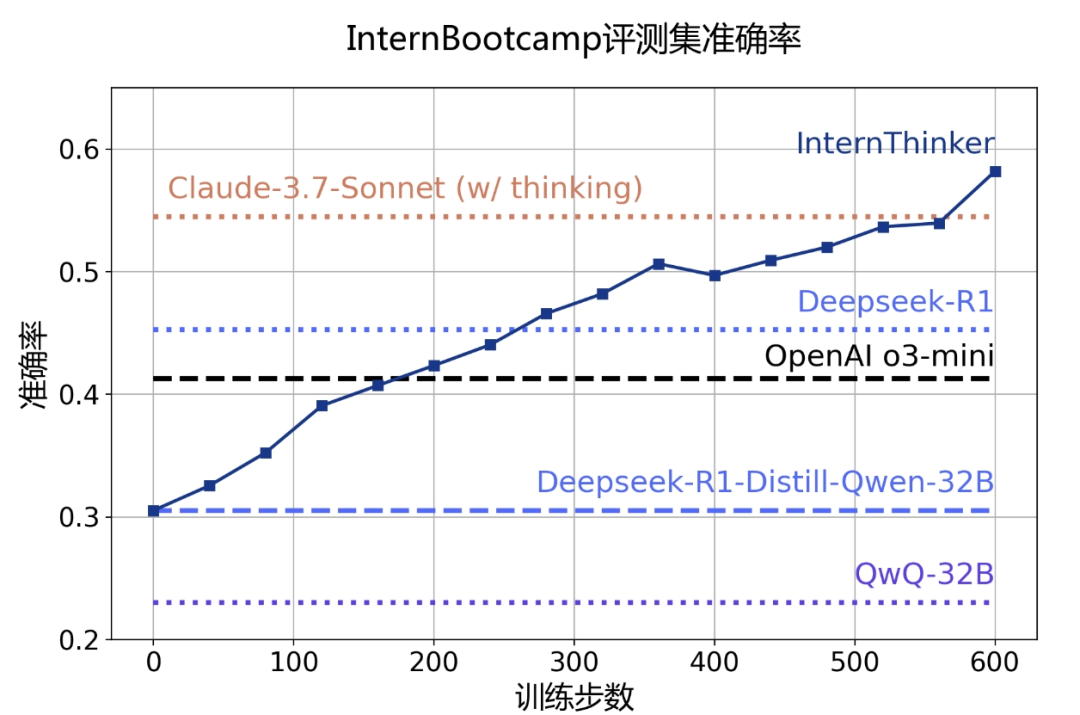
InternThinker 在包括数十个任务的测试集上的平均能力超过 o3-mini、DeepSeek-R1 以及 Claude-3.7-Sonnet 等国内外主流推理模型。
甚至在一些任务中性能表现远超当前其他推理大模型。
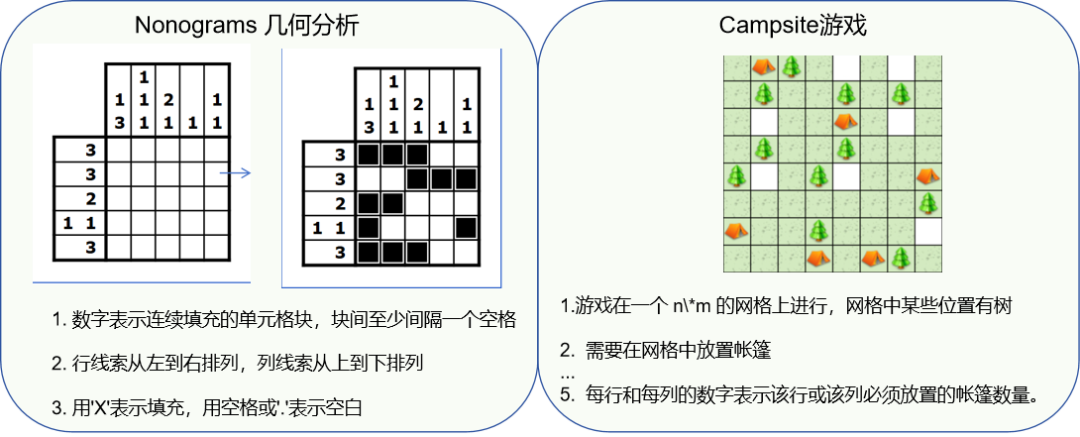

InternBootcamp 已开源,欢迎接入任务,开展更多有价值的探索:https://github.com/InternLM/InternBootcamp
多任务混合强化学习:迎来 “涌现时刻”
值得一提的是,研究人员观察到,在基于 InternBootcamp 的多任务混合训练过程中,出现了强化学习的 “涌现时刻”:在单一任务中,无法成功推理得到奖励的模型,通过多个任务混合的强化学习,能够在训练过程中成功得到奖励,实现领域外专业任务的有效强化学习训练。
除了单独训练 Tapa、Unicoder25 任务外,研究人员额外选择了几十种任务进行混合训练。如下图所示:单一训练 Tapa 等任务并不能成功获得任务的正向反馈;而混合训练各类 InternBootcamp 任务达一定步数后,InternThinker 融合学习了这些推理任务的思考方式,建立起了不同任务间的关联,从而成功获取了 Tapa 这类任务的正向反馈,实现对该任务的有效学习。
这意味着,随着 InternBootcamp 任务的数量增加、质量提升和难度加大,大模型有望迎来能力的 “升华”,高效解决更多、更难、更具实用性的推理任务,在助力大模型推理能力泛化的同时,加速推动科学发现。
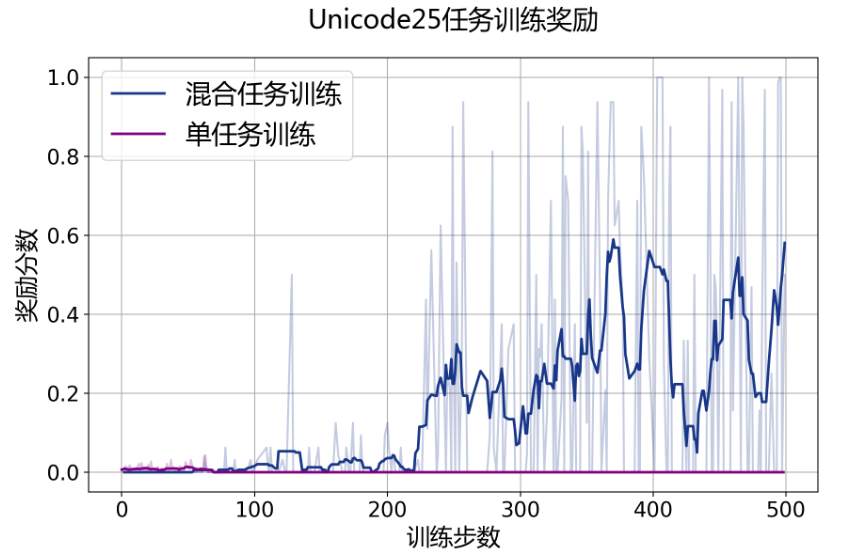
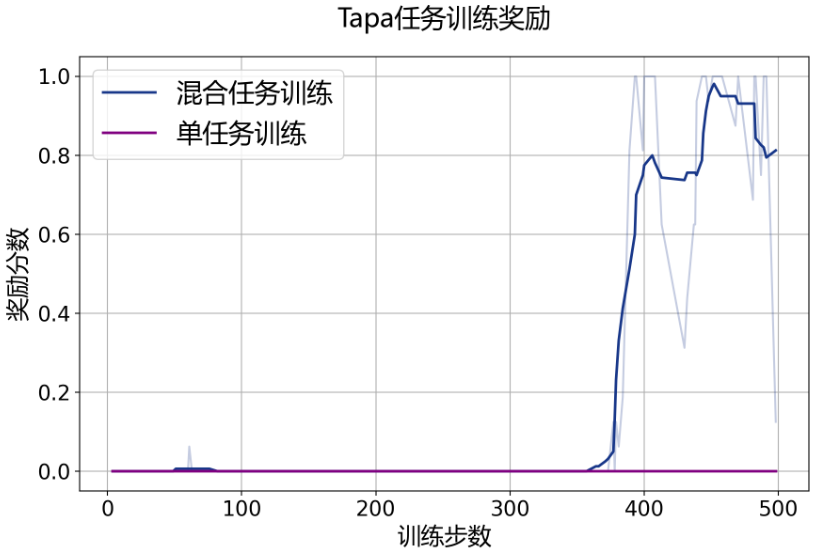
Unicode25 任务和 Tapa 任务 “涌现时刻”,其中浅色表示峰值、深色表示均值
通专融合底层技术突破
上述进展得益于近期上海 AI Lab 在通专融合路线的底层技术和架构方面的一系列创新突破。
从大模型发展历程来看,主要分化为专业性和通用泛化性两大路线。上海 AI Lab 率先提出通专融合技术路线(https://arxiv.org/abs/2407.08642),着力解决大模型高度专业化与通用泛化性相互制约的发展困境。这一路径的关键在于同步提升深度推理与专业泛化能力,使模型不仅在广泛的复杂任务上表现出色,还能在特定领域中达到专业水平。
上海 AI Lab 进一步提出通过相互依赖的基础模型层、 融合协同层和探索进化层 “三层” 技术路径, 可打造 “通用泛化性”“高度专业性”“任务可持续性” 三者兼得的通用人工智能。
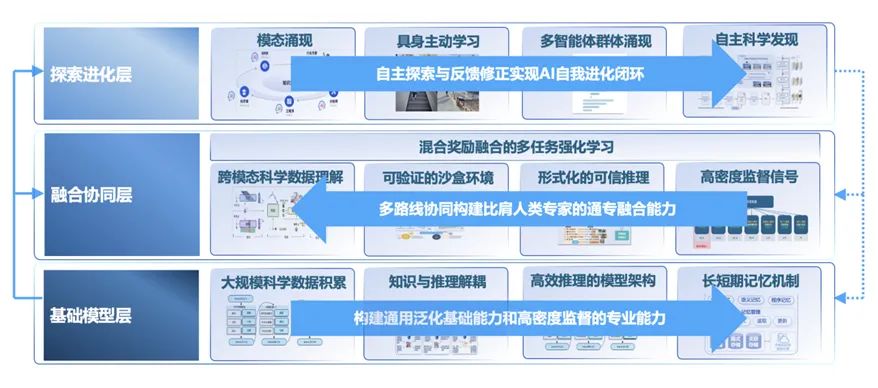
通专融合 AGI 实现路径
第一层为基础模型层,旨在构建通用泛化基础能力和高密度监督的专业能力。上海 AI Lab 团队近期提出全新的 “记忆体 + 解码器” 大模型架构 Memory Decoder,并实现两个组成部分通过不同的预训练任务分别进行训练。区别于将所有信息全都编码进 decoder 的现有 Transformer 经典大模型架构,该架构实现了通专融合中 “知识与推理可分离与自组合” 的新一代大模型。其中,记忆体承担 “专” 的功能,负责对不同领域知识的可靠记忆;解码器承担 “通” 的功能,负责通用的语言组织和逻辑;记忆体可经过一次训练后应用于不同基模型。
第二层为融合协同层,通过多路线协同构建比肩人类专家的通专融合能力。团队近期的突破包括:
-
设计强化学习算法 PRIME(https://arxiv.org/abs/2502.01456),结合高密度监督信号,有效强化了智能体专精能力的提升效率,为通用群体智能发展铺平了道路。可实现更快速的收敛,同时获取比现有方法高出 7% 的性能提升。在 AIME、MATH 等竞赛难度数学题上,仅用少量开源数据,便可使得 7B 模型的数学能力显著超越 OpenAI 的 GPT-4o。
-
推出以多任务强化学习为核心的后训练技术框架 MoR,聚焦实现多任务的强化学习。针对不同类型任务(例如数学解答和证明、科学问答、推理解谜、主观对话等)进行了算法探索和初步集成验证,实现了多任务强化学习的混合训练。
-
构建基于结果奖励的强化学习新范式 OREAL(https://arxiv.org/abs/2502.06781),着力解决大模型当前面临的 “稀疏奖励困境、局部正确陷阱和规模依赖魔咒” 三大困局。该算法超越了目前广泛使用的 GRPO 等方法,定义了一个更广泛的算法设计空间,能将 PRIME、DAPO 等方法的优点融合入算法框架中,无需蒸馏超大参数规模模型,便实现了轻中量级(7B/32B)模型推理能力的再提升。
-
第三层为探索进化层,通过自主探索与反馈修正实现 AI 自我进化闭环。团队近期的突破包括:
-
测试时强化学习(TTRL)框架(https://arxiv.org/abs/2504.16084),有效探索人工智能自主进化的可能路径。TTRL 能在没有准确标签的情况下进行奖励估计,驱动模型朝着正确的方向学习,有力支持了在减少人工标注依赖方面的潜力,进一步推动强化学习向大规模、无监督方向的持续扩展。
-
构建分子逆合成新方法 Retro-R1,基于大模型 + 智能体 + 长推理 + 强化学习的范式,在多步逆合成问题上展现出了更精准的合成路径规划能力。Retro-R1 在不使用任何 SFT 数据仅使用 1 万条强化学习数据通过 200 步训练的情况下就实现了大模型在逆合成推理能力的升级,并在不同领域数据中展现出了出色的泛化能力。
据悉,未来上海 AI Lab 将系统推进通专融合技术路线的发展与探索,将通专融合的新能力、新进展持续通过 InternBootcamp 对外开放,加速以新一代通专融合基座模型的方式解决具体科学发现中的关键问题,同时牵引打造垂直领域示范应用案例,为科学发现与产业创新提供关键驱动力。
©
(文:机器之心)