

编辑:Panda、+0
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。
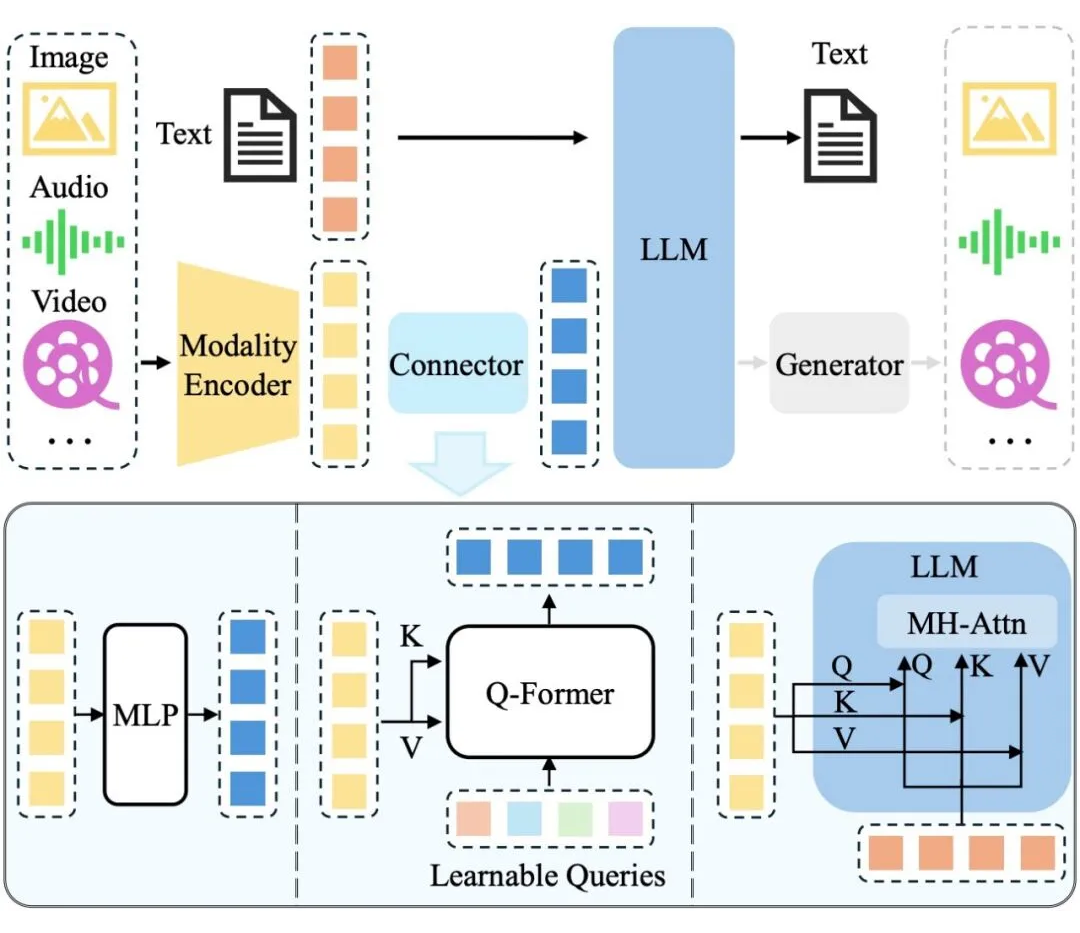
常见的 MLLM 结构。
这种模式要求模型首先将视觉信息「翻译」或「映射」为文本描述或内部的文本化 token,然后再利用大型语言模型的文本推理能力进行处理。
这个转换过程不可避免地可能导致视觉信息中固有的丰富细节、空间关系和动态特征的丢失或削弱,形成了所谓的「模态鸿沟 (modality gap) 」。这种鸿沟不仅限制了模型对视觉世界的精细感知,也影响了其在复杂视觉场景中进行有效规划的能力。
例如,模型虽然能够识别图像中的物体并描述它们之间一些相对简单的空间关系,但在追求极致的定位精度,或需要深入理解和预测物体间高度复杂、动态或隐含的交互逻辑(而非仅仅识别表面现象)时,其表现仍可能因视觉信息在文本化过程中的细节损失而受到限制。
来自剑桥、伦敦大学学院、谷歌的研究团队认为:语言不一定始终是进行推理最自然或最有效的模态,尤其是在涉及空间与几何信息的任务场景中。
基于此动因,研究团队提出了一种全新的推理与规划范式 —— 视觉规划(Visual Planning)。该范式完全基于视觉表示进行规划,完全独立于文本模态。

-
论文标题:Visual Planning: Let’s Think Only with Images
-
论文地址:https://arxiv.org/pdf/2505.11409
-
代码仓库:https://github.com/yix8/VisualPlanning
在这一框架下,规划通过一系列图像按步编码视觉域内的推理过程,类似于人类通过草图或想象视觉图景来计划未来行为的方式。
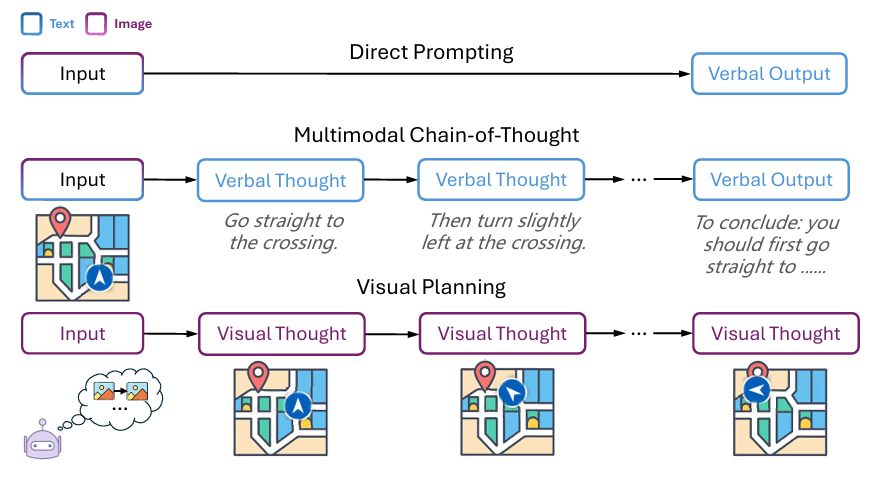
推理范式的对比。传统方法(上方与中间两行)倾向于生成冗长且不准确的文本规划,而视觉规划范式(下方一行)则直接预测下一步的视觉状态,形成完全基于图像的状态轨迹,过程无需语言中介。
为支持该方法,研究团队提出了一个创新性的强化学习框架 —— 基于强化学习的视觉规划(Visual Planning via Reinforcement Learning, VPRL)。该框架以 GRPO(群体相对策略优化)为核心优化方法,用于在训练后提升大规模视觉模型的规划能力。
在多个典型的视觉导航任务中,包括 FROZENLAKE、MAZE 和 MINIBEHAVIOR,该方法实现了显著的性能提升。实验结果表明,相较于在纯文本空间内进行推理的其他所有规划变体,研究团队提出的纯视觉规划范式在效果上具备更强优势。
以下是动态示例:
冰湖(FrozenLake): 这是一个具有随机性的网格世界(gridworld)环境,智能体需从指定起点出发,安全到达目标位置,期间必须避免掉入「冰洞」。

迷宫 Maze: 智能体获得一个初始图像,该图展示了迷宫的布局。其任务是在迷宫中从起点(绿色标记)出发,最终到达终点(红色旗帜所在位置)。
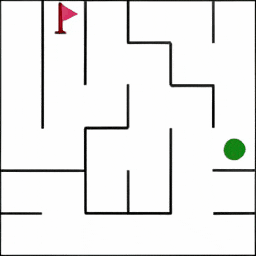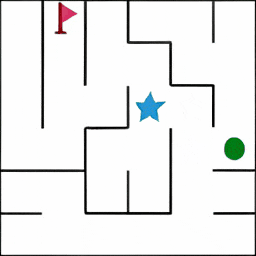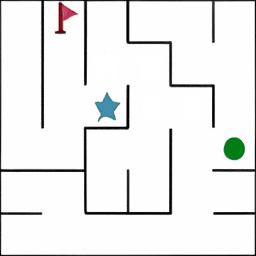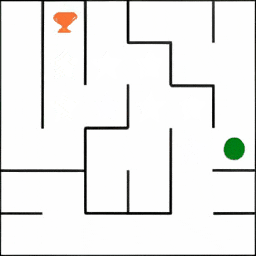
微行为(MiniBehaviour): 智能体首先需要从起点移动至打印机所在的位置并「拾取」它,之后应将打印机运送至桌子处并「放下」。

这项研究不仅证明视觉规划是一种可行的替代方案,更揭示了它在需要直觉式图像推理任务中的巨大潜力,为图像感知与推理领域开辟了崭新方向。
强化学习驱动的视觉规划
视觉规划范式
以往的大多数视觉推理基准任务,通常通过将视觉信息映射到文本领域来求解,例如转换为物体名称、属性或关系等标注标签,在此基础上进行几步语言推理。
然而,一旦视觉内容被转换为文本表示,该任务便退化为纯语言推理问题,此时语言模型即可完成推理,而无需在过程中再引入视觉模态的信息。
研究团队提出的视觉规划范式本质上与上述方法不同。它在纯视觉模态下进行规划。研究团队形式化地定义视觉规划为:在给定初始图像 v₀ 的前提下,生成中间图像序列 T = (ˆv₁, …, ˆvₙ),其中每个 ˆvᵢ 表示一个视觉状态,共同构成一个视觉规划轨迹。具体而言,记 π_θ 为一个参数化的生成视觉模型。该视觉规划轨迹以自回归方式生成,每一个中间视觉状态 ˆvᵢ 都在给定初始状态和此前生成状态的条件下进行采样:
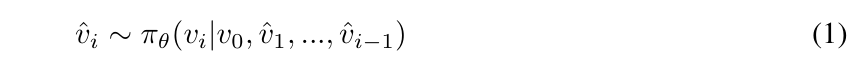
大规模视觉模型中的强化学习
强化学习(RL)在优化自回归模型方面表现出显著优势,其通过序列级奖励信号进行训练,突破了传统 token 级监督信号的限制。在自回归图像生成任务中,图像被表示为视觉 token 的序列。
受 RL 在语言推理任务中成功应用的启发,研究团队引入了一个基于 RL 的训练框架,用于支持大模型下的视觉规划,并采用了 GRPO 方法。该方法利用视觉状态之间的转换信息来计算奖励,同时验证生成策略是否满足环境约束条件。
为训练一种能生成有效动作、并在 RL 阶段保持探索多样性的策略模型,研究团队提出了一种创新性的两阶段强化学习框架:
Stage 1:策略初始化。在该阶段,研究团队采用监督学习,通过在环境中的随机游走(random walk)生成的轨迹来初始化视觉生成模型 π_θ。目标是生成有效的视觉状态序列,并在「模拟」环境中保持充足的探索性。在训练过程中,每条轨迹由一个视觉状态序列 (v₀, …, vₙ) 构成。对每条轨迹而言,研究团队提取 n−1 对图像样本 (v≤ᵢ, vᵢ₊₁),其中 v≤ᵢ 表示前缀序列 (v₀, …, vᵢ)。随后,在给定输入前缀的情况下,模型会接触到来自 K 条有效轨迹的下一状态候选集 {vᵢ₊₁^(j)}_{j=1}^K。这些候选状态共享相同的前缀,为防止模型过拟合某一特定转换,同时鼓励生成过程的随机性,研究团队在每个训练步骤中随机采样一个候选状态 vᵢ₊₁^(ℓ) 作为监督目标,通过最小化视觉微调损失函数(VPFT)来优化模型:
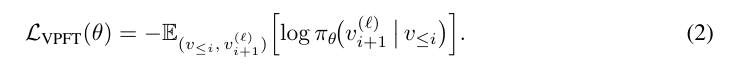

所提 VPRL 框架概览。图中展示了该框架在视觉导航任务中的应用,利用自回归式大规模视觉模型进行图像生成。其中使用了 GRPO 对视觉策略模型进行训练,并引入进度奖励函数以鼓励推进性的动作并惩罚非法行为,从而实现与目标一致的视觉规划。
总体而言,该阶段主要作为接下来的强化学习阶段的热启动过程,旨在提升生成图像的连贯性和整体规划质量。
Stage 2:面向视觉规划的强化学习。在第一阶段初始化后,模型拥有较强的探索能力,这对强化学习至关重要,可确保模型覆盖多种状态转移路径,避免陷入次优策略。在第二阶段中,模型通过模拟未来状态(即潜在动作的后果),依据生成结果获得奖励反馈,从而逐步引导学习出有效的视觉规划策略。
具体而言,给定当前输入前缀 v≤ᵢ,旧版本模型 π_θ^old 会采样出 G 个候选中间状态 {ˆvᵢ₊₁^(1), …, ˆvᵢ₊₁^(G)}。每个候选状态代表了时间步 i 上智能体采取某一行动 a^(k) 后,模拟产生的下一视觉状态。研究团队使用基于规则的解析函数将状态对 (vᵢ, ˆvᵢ₊₁^(k)) 映射为离散动作,以便进行结构化解释。
随后,研究团队设计了一个复合奖励函数 r (vᵢ, ˆvᵢ₊₁^(k)) 来对每个候选状态进行打分,该奖励衡量候选状态是否代表了对目标状态的有效推进(即是否有用)。
不同于传统强化学习中依赖学习一个价值函数评估器(critic),GRPO 通过候选组内的相对比较来计算优势值,从而提供易于解释、计算更加高效的训练信号。此时每个候选的相对优势 A^(k) 的计算方式为:
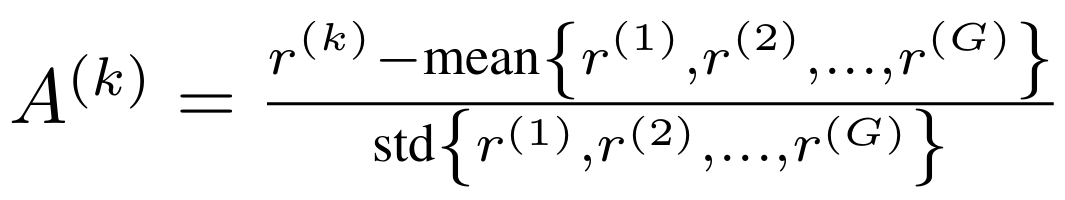
为引导模型产生更优的候选响应,并强化高优势行为的倾向,研究团队根据以下目标函数更新策略:
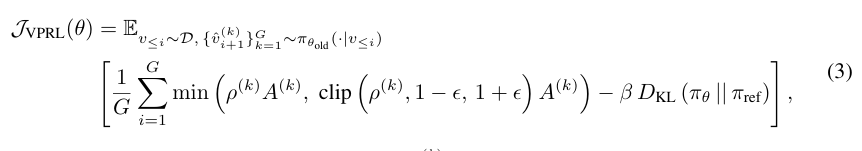
其中,D 指代前缀分布,ρ^(k) = π_θ(ˆvᵢ₊₁^(k) | v≤ᵢ) / π_θ^old (ˆvᵢ₊₁^(k) | v≤ᵢ) 表示重要性采样比值。
奖励设计。与离散操作或文本 token 不同,视觉输出往往是高维稀疏信息,难以被直接分解为可解释的单元。在研究团队的视觉规划框架下,核心挑战在于如何判断一个生成的视觉状态能否准确表达对应的规划动作。因此,奖励设计聚焦于在考虑环境约束下,对朝向目标状态的推进进行评估。
为解释由状态 vᵢ 到候选状态 ˆvᵢ₊ₜ^(k) 所隐含的动作计划,研究团队定义一个状态 – 动作解析函数 P: V × V → A ∪ E,其中 A 表示有效动作集合,E 表示非法状态转移集合(例如违反物理约束的动作)。
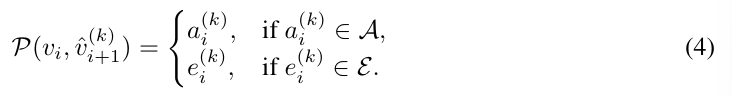
该过程可借助独立的图像分割组件或基于规则的脚本完成,从像素层级数据中解析出可解释的动作单元。
一旦动作被识别,研究团队引入「进度图」(progress map)D (v) ∈ ℕ,表示从某一可视状态 v 到达目标状态所需的剩余步骤数或努力度。通过比较当前状态与生成状态在进度图上的相对变化,研究团队将动作集合 A ∪ E 划分为三类:
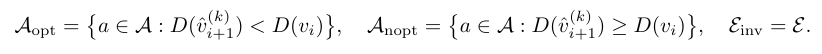
据此,研究团队提出进度奖励函数 r (vᵢ, ˆvᵢ₊₁^(k)):

r =αₒₚₜ, 若为推进有效动作(optimal)r =αₙₒₚₜ, 若为无推进的动作(non-optimal) r =αᵢₙᵥ, 若为非法动作(invalid)
在实验中,研究团队设置 αₒₚₜ = 1,αₙₒₚₜ = 0,αᵢₙᵥ = −5,从而鼓励推进行为,惩罚不可行的状态转移。
系统变体
除提出的 VPRL 主干框架外,为全面评估监督方式(语言 vs. 图像)与优化方法(监督微调 vs. 强化学习)对性能的影响,研究团队提出了若干系统变体作为对比基线:
视觉微调规划(VPFT)。研究团队提出「视觉微调规划」(Visual Planning via Fine-Tuning, VPFT)作为本框架的简化版本,其训练结构与第 2.2 节中的阶段一一致,但使用最优规划轨迹代替随机轨迹。对于每个环境,研究团队采样一条最小步骤的最优轨迹 (v₀^opt, v₁^opt, …, vₙ^opt),该轨迹从初始状态 v₀^opt = v₀ 通向目标状态。在每一步,模型根据当前前缀 v≤ᵢ^opt 学习预测下一个状态 vᵢ₊₁^opt。训练目标与公式(2)相同,以最优轨迹作为监督信号。
基于语言的监督微调(SFT)。在该对比方法中,规划任务被构建于语言模态中。与生成图像形式的中间状态不同,模型需生成动作序列的文本描述。形式上,给定输入视觉状态 v 及任务描述文本提示 p,模型被训练以输出一个动作序列 t = (t₁, …, t_L),其中每个 token tᵢ ∈ V_text 表示一个动作。模型输入为提示词 token 与视觉 token 的拼接,目标为对应的文字动作序列。研究团队采用此前在自回归模型中常用的监督微调方法,通过最小化交叉熵损失来学习动作预测:
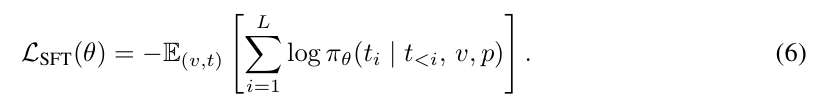
视觉规划的实验表现如何?
该团队基于一些代表性任务检验了视觉规划这一新范式的实际表现。
具体来说,为了对比视觉规划与基于语言的规划,该团队实验了三种视觉导航环境:FROZENLAKE、MAZE 和 MINIBEHAVIOR。所有这些环境都可以在两种模态下求解,这样一来便能更加轻松地对比两种策略。
模型方面,该团队选择的是完全在视觉数据上训练的模型 —— 这些模型在预训练过程中未接触过任何文本数据。
具体来说,他们选择了大型视觉模型 LVM-3B 作为骨干网络,并使用了 VPFT 和 VPRL 方法。与此同时,相对比的文本模型包括不同设置的 Qwen 2.5-VL-Instruct 以及 Gemini 2.0 Flash (gemini-2.0-flash-002) 和先进思维模型 Gemini 2.5 Pro (gemini-2.5-pro-preview-03-25)。
评估指标则采用了精确匹配 (EM) 和进度率 (PR) 两种。
那么,视觉规划的表现如何呢?
视觉规划胜过文本规划
如下表 1 所示,视觉规划器(VPFT 和 VPRL)在所有任务上均取得了最高分,优于所有使用语言推理的基线模型。
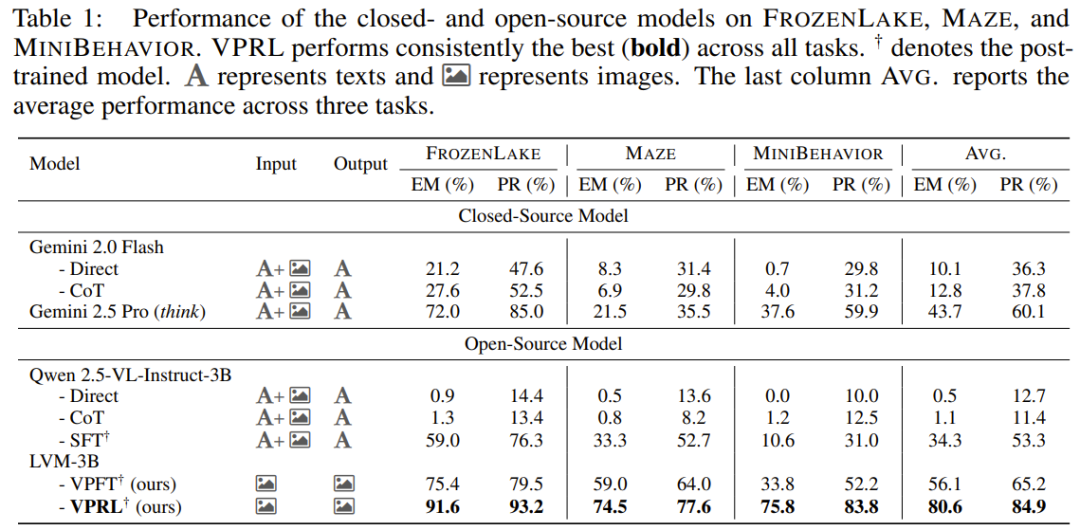
在相同的通过微调的监督训练方法下,VPFT 在精确匹配 (EM) 指标上平均比基于语言的 SFT 高出 22% 以上,而 VPRL 的优势还更大。在进度率 (PR) 方面也观察到了类似的趋势。
这些结果表明,视觉规划范式在以视觉为中心的任务中优势明显,因为语言驱动的方法可能与任务结构不太契合。纯推理模型(无论是大型闭源系统还是小型开源 MLLM)。如果不针对特定任务进行调优,在完成这些规划任务时都会遇到困难。即使是先进的思维模型 Gemini 2.5 Pro,在更复杂的 MAZE 和 MINIBEHAVIOR 任务中,EM 和 PR 也几乎低于 50%,这表明当前前沿的语言模型还难以应对这些挑战,尽管这些任务对人类来说是直观的。
强化学习能带来增益
两阶段强化学习方法 VPRL 带来了最高的整体性能,超越了其它变体。在第二阶段之后,该模型在更简单的 FROZENLAKE 任务上实现了近乎完美的规划(91.6% EM,93.2% PR),并在 MAZE 和 MINIBEHAVIOR 任务上保持了强劲的性能。在所有任务上的性能都比 VPFT 高 20% 以上。
正如预期,该团队的强化学习训练的第一阶段(强制输出格式,但不教授规划行为)获得了近乎随机的性能(例如,在 FROZENLAKE 数据集上实现了 11% 的 EM)。在使用新提出的奖励方案进行第二阶段的全面优化后,规划器达到了最佳性能。这一提升凸显了强化学习相对于 SFT 的一个关键优势:VPRL 允许模型自由探索各种动作并从其结果中学习,而 VPFT 则依赖于模仿,并且倾向于拟合训练分布。通过奖励驱动式更新来鼓励利用(exploitation),VPRL 学会了捕捉潜在的规则和模式,从而实现了更强大的规划性能。
下图展示了一个可视化的对比示例。

随着复杂度提升能保持稳健性
该团队发现,在研究不同方法在不同任务难度(更大的网格通常更难)下的表现时,强化学习依然能保持优势。
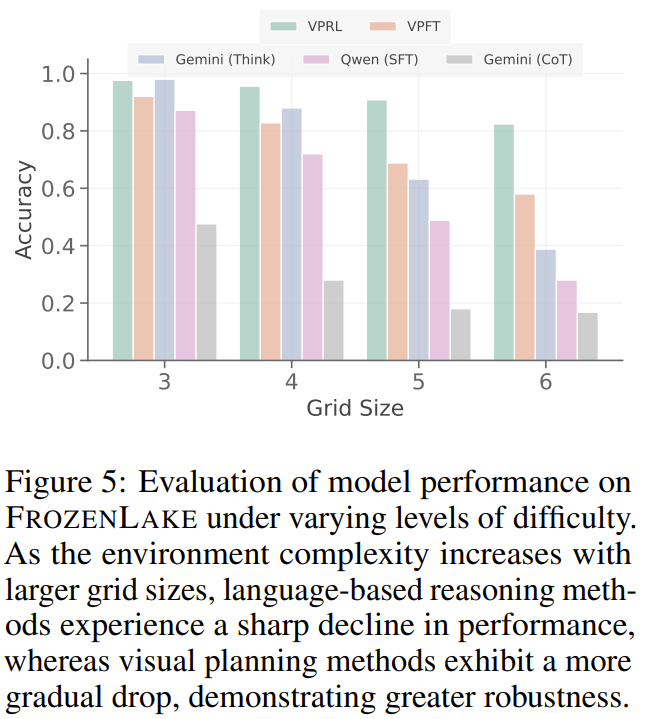
如图 5 所示,当在 FROZENLAKE 环境中,随着网格尺寸从 3×3 增加到 6×6,Gemini 2.5 Pro 的 EM 分数从 98.0% 骤降至了 38.8%。相比之下,新提出的视觉规划器不仅在所有网格尺寸下都保持了更高的准确度,而且性能曲线也更加平坦。同样,VPRL 也表现得比 VPFT 更稳定,在 3×3 网格上 EM 分数保持在 97.6%,在 6×6 网格上也仍能达到 82.4%,这表明 VPRL 的稳健性相当好。

©
(文:机器之心)