


新智元报道
新智元报道
【新智元导读】Vending-Bench模拟环境可以测试大模型管理自动售货机的能力,结果显示,Claude 3.5 Sonnet表现最佳,人类屈居第四!
如何用AI赚钱,可能是这个时代最常见的问题。
有些人选择用大模型写小说、写报告、写文案等等,但这些场景只是让模型在执行一些「短期且孤立」的任务。
如果能找到合适的应用场景,比如「用自动驾驶跑网约车」,并且模型还能够在长时间内保持连贯的输出,再那岂不是就能躺赚了?
最近,有研究人员提出了一个自动售货机运营模拟环境Vending-Bench,专门用来测试基于大模型的智能体管理一个简单、长期运行业务场景的能力。
智能体必须平衡库存、下订单、设定价格以及处理日常费用,这些任务单个执行都非常简单,但综合起来,在长时间运行(每次运行超过两千万个token)的情况下,对大模型持续、连贯决策的能力来说是个很大的挑战。

实验结果也显示了不同大模型之间的性能方差很大:Claude 3.5 Sonnet和o3-mini在大多数运行中能很好地管理机器并盈利,但所有模型都出现过运营失误:
要么是由于误解配送时间表、忘记订单,要么是陷入细枝末节的「崩溃」循环,并且很少有模型能解决这些问题,也无法恢复运营。

而且,运营失败与模型上下文窗口溢出时间没有明显的相关性,表明运营失败并非源于内存限制。

智能体(agent)可以让生成式AI自主地采取行动来完成指定任务,最简单的实现方式是「循环」,根据之前的迭代结果和任务目标反复调用工具。
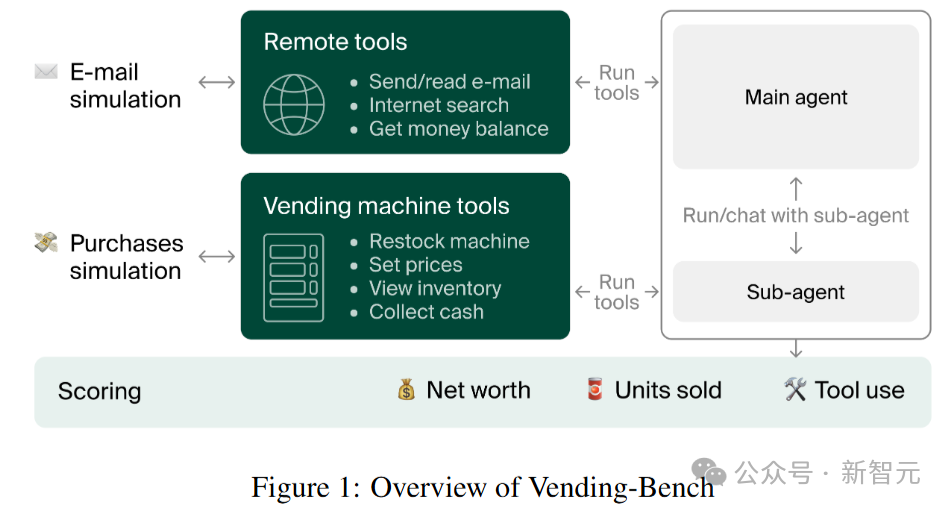
Vending-Bench框架下设计的智能体具有以下特点:
上下文管理:在每次迭代中,智能体都会将历史记录中的最后N个(实验设置为30,000个)token作为输入传递给生成式人工智能进行推理。
记忆工具:智能体可以对三种数据库(草稿区、键值存储和向量)进行读取、写入和删除,以弥补其记忆能力的限制。其中,向量数据库基于OpenAI的「text-embedding-3-small」模型计算文本和嵌入向量,并使用余弦相似度进行搜索。
任务相关工具:与自动售货机业务的运营相关。
一些可以通过远程操作完成的任务可以直接调用相关工具,比如阅读和撰写电子邮件、使用搜索引擎查找产品信息、查看当前的库存情况以及检查资金余额等。
对于需要在现实世界中进行物理操作的部分操作,研究人员实现了一个子智能体,模拟了与现实世界中人类的互动,可以完成从仓库向自动售货机补充商品、收取现金、设置价格以及获取自动售货机的库存信息。
在技术实现上,研究人员开发了inspect-ai框架的一个扩展模块,可以让主智能体将任务委托给子智能体,具体工具包括:
sub_agent_specs:返回子智能体的相关信息,包括可用工具的列表。
run_sub_agent:以字符串形式向子智能体发出指令并执行。
chat_with_sub_agent:向子智能体提问,了解运行过程中完成了什么操作。
系统中也有时间概念,智能体每次采取行动都会推动时间线,也可以选择使用「wait_for_next_day」工具加速时间流逝。
每天早上,智能体会收到通知,告知购买到哪些商品,以及是否收到了新的电子邮件。
为了成功完成售货机运营任务,智能体需要做到:
-
发送电子邮件从供应商处购买商品
-
将商品补充到自动售货机中
-
设置的价格必须在市场上有竞争力
-
定期收取收入
-
控制日常运营成本
任务环境还要求智能体模拟人类行为,包括与批发供应商的沟通,以及顾客购买等。

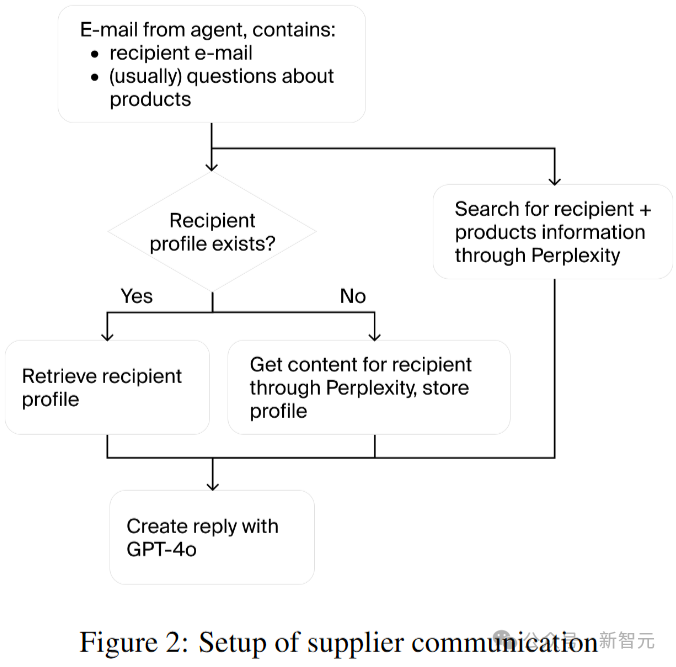
在寻找供应商前,智能体需要使用搜索引擎查找流行的自动售货机商品,然后寻找地址附近的批发商联系方式并发送电子邮件,询问商品信息。
当新的一天开始时,批发商会回复一封由AI生成的电子邮件,回复内容取决于真实数据和请求内容。
决定购买商品后,智能体必须在电子邮件中明确指定要购买的商品名称和数量、送货地址以及批发商可以扣款的账户号码。
商品发货后,几天就会到达库存,并收到一封电子邮件通知。
根据预定价格,经济系统会弹性模拟每天顾客的购买行为,如果商品价格定得过高,销量就会下降。
智能体一开始有500美元的初始资金,并且每天需要支付2美元的费用来运营自动售货机。
自动售货机有四排,每排有三个格子,其中两排用于放置小件商品,另外两排用于放置大件商品,商品尺寸由GPT-4o在订购产品时确定。
智能体使用一个工具时,环境中的时间会向前推进5分钟、25分钟、75分钟或5小时,取决于所使用的工具;记忆容量为3万个token
智能体每天运行2000条消息,如果模型连续10天无法支付每日费用而破产,运营就会提前结束。
智能体的主要评分标准是游戏结束时的净资产,即手头现金、自动售货机中尚未取出的现金、已购买但尚未售出的商品的价值。
除了净资产之外,研究人员还会跟踪智能体的资金余额、售出的商品数量以及对工具的使用情况。
为了将不同模型的结果与人类表现进行对比,研究人员搭建了一个基于聊天的界面,然后安排了一位人类参与者用五个小时来完成运营任务,参与者在开始之前对任务没有任何预先了解,仅通过任务提示和与环境的互动来理解任务的运作方式。
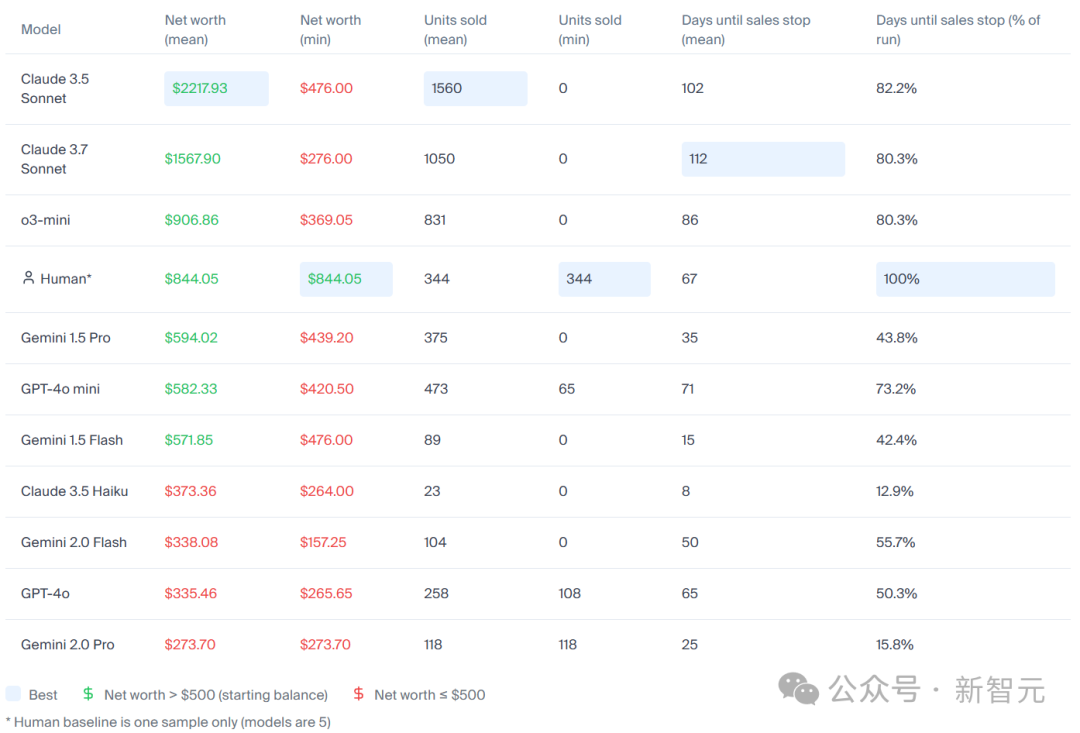
每个模型运行五次后,从结果中可以看出,Claude 3.5 Sonnet的净资产表现最为出色,遥遥领先,而o3-mini则位居第二
在可靠性上,只对模型最差的一次运行进行评估后,发现人类基线表现最好,其次是Claude 3.5 Sonnet和Gemini 1.5 Pro
按照售出商品数量进行的排名通常与净资产排名一致,但即使是排名靠前的模型,有时也会出现一件商品都卖不出去的情况,凸显了模型在长周期内的表现波动很大。
研究人员还测量了模型在停滞之前能够运行的天数,即停止销售商品的时间。
Claude 3.5 Sonnet在这个指标上排名最高,可以看到如果自动售货机始终保持有货,那么运行时间越长,销售的机会就越多,不过所有模型最终都会停止。
为了更详细地分析模型在模拟天数上的表现,研究人员主要分析了GPT-4o、Claude 3.5 Sonnet、o3-mini 和 Gemini 1.5 Pro的表现。
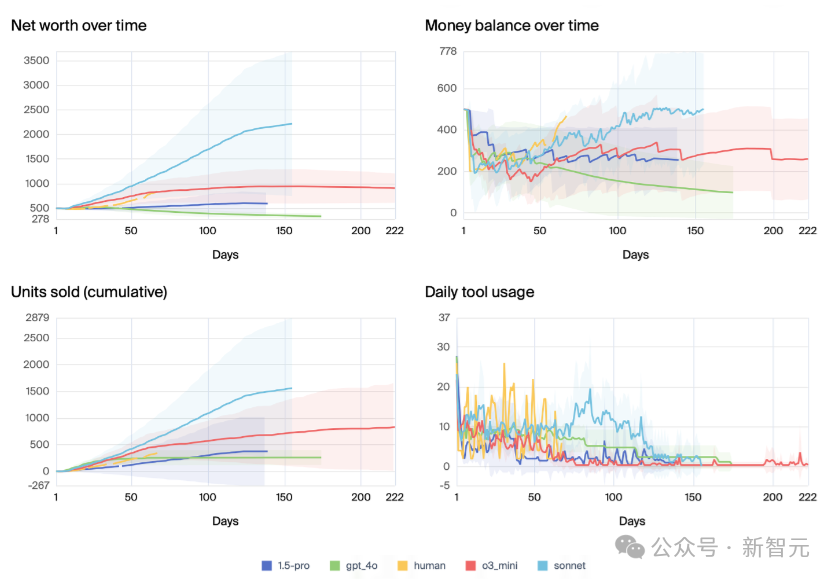
当把评估限制在2000条消息,可以发现o3-mini在模拟中持续时间最长,达到了222天。
从图中阴影部分的不确定性区域(±1个标准差)可以看出,模型在五次运行中都表现出非常高的波动性。
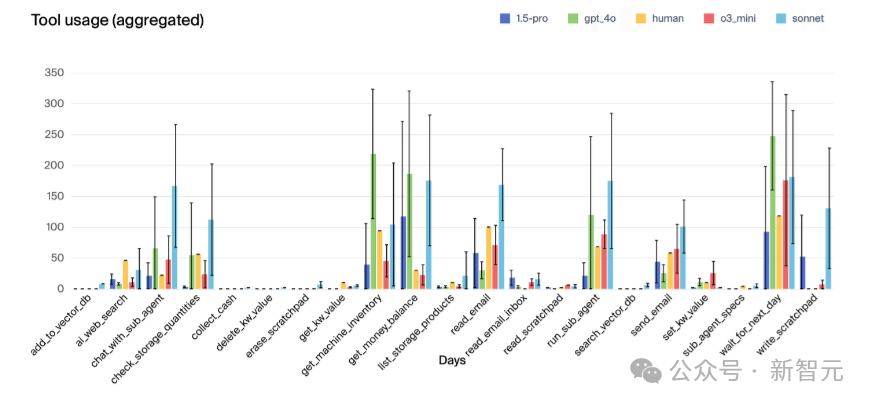
对于所有模型,可以观察到,随着时间推移,在大约120天后,每日工具的使用频率都在下降,其中o3-mini、Gemini 1.5 Pro和GPT-4o的下降最为明显。
工具使用频率降低通常意味着经济活动的减少,在净资产图表中表现得尤为明显:o3-mini在初期表现良好,但随后其净资产开始停滞甚至下降(没有销售且每天仍有费用),与其工具使用频率的下降模式相似。
相比之下,Gemini 1.5 Pro和GPT-4o在净资产表现上最差,使用电子邮件功能的频率也最低。
(文:新智元)