

在过去十多年里,人工智能的发展像是开了挂,不断上演“下一个时代已经到来”的戏码。
从AlphaGo横扫围棋世界,到ChatGPT改变我们工作和生活的方式,这背后到底发生了什么?为什么AI能越来越“聪明”?
这并不是靠某个天才程序员的灵感闪现,而是数据、算法、算力这三驾马车的持续进化,推动了整整一个时代的技术飞跃。

本篇文章将带你穿越人工智能过去15年的关键里程碑,不仅看到一次次划时代的技术突破,还能理解这些背后隐藏的“数据力量”和发展逻辑。
你将看到为什么GPU的出现是AI的起点,ImageNet怎么唤醒了AI的视觉能力,Transformer如何统治今天的大模型时代,更会了解到,未来的AI,不再靠模型大不大,而是看“数据够不够好”。
人工智能的演进,其实就是一个不断寻找最优组合的过程:更强的算力、更大的数据集、更高效的算法。这三者的协同,就像三根引擎柱,一旦哪一项取得了突破,整架AI飞船就能飞得更远、更快。
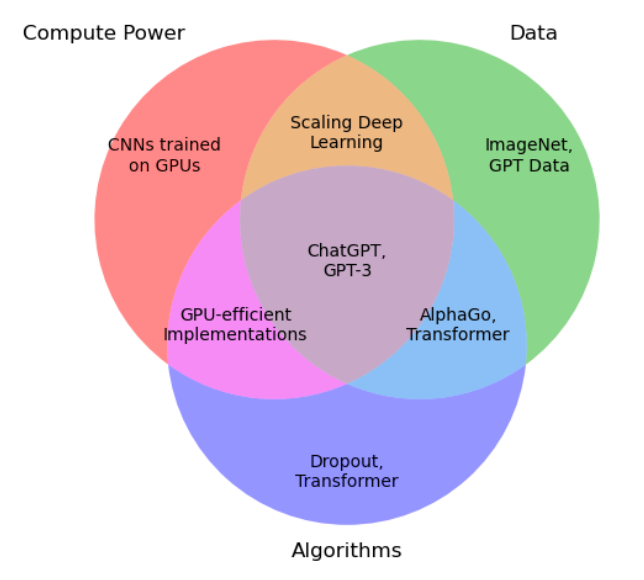
一开始,人们以为算力就是全部,GPU训练模型成了风口;后来发现,没有海量高质量数据,算力再强也白搭;再往后,大家意识到:真正的游戏规则在算法,如何让模型“聪明地”用好数据才是王道。
而今,新的挑战摆在我们面前:开放数据越来越少,隐私和监管越来越严,AI的下一次飞跃,会不会来自更安全、更合规的“数据范式重构”?比如联邦学习、隐私保护计算、合成数据生成,这些听起来高大上的技术,正在默默为AI铺设下一条跑道。
统计学习理论不仅提供了一个概念视角,它还为研究人员提供了一个优化AI开发的实际框架。它帮助他们选择有效的架构,定义性能限制,并相应地调整数据需求。
这一视角阐明了过去突破的重要性,并确定了可能推动下一波进步的参数。通过将历史里程碑置于理论结构中,SLT使研究人员能够通过连贯的分析框架来解释进步。在下一节中,我们将从这个视角探讨这些突破。
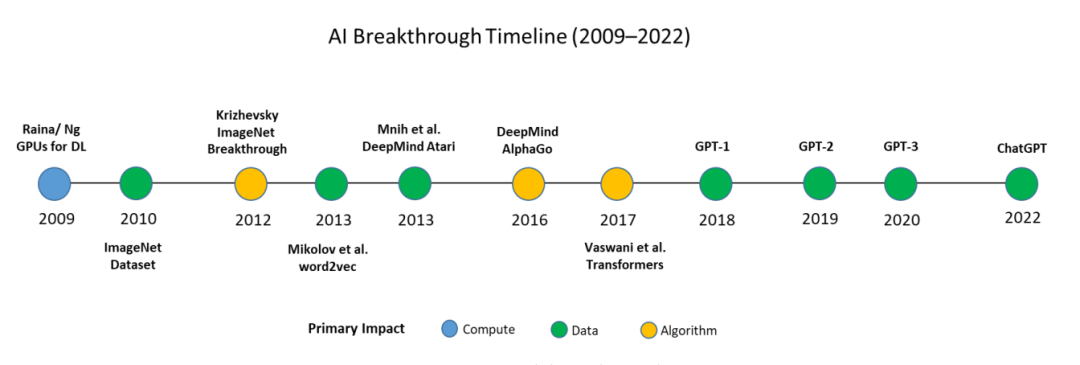
人工智能(AI)历史中的一些发展不仅仅是技术成就,它们代表了范式转变。这些突破要么实现了以前无法实现的学习规模,要么引入了取代现有方法的新方法。
2009年,Andrew Ng及其团队引入了使用GPU进行神经网络训练。在此之前,大多数模型依赖于基于CPU的训练,这在大规模模型上带来了显著的时间和资源限制。他们的工作表明,在合理的时间范围内训练超过1亿参数的网络是可行的。这一进展标志着由扩展计算资源推动的AI的重大飞跃。
斯坦福大学在2010年发布了ImageNet数据集,当时它是该领域最大且最全面的标记图像数据集之一。包含数百万张标注图像的ImageNet使得视觉识别的比较基准测试成为可能,并积极促进了算法的进步。这一发展强调了数据规模在推动AI进步中的重要性。
同年,AlexNet在ImageNet竞赛中的成功重新定义了深度学习在大规模上的成就。通过在GPU上训练模型并引入Dropout 作为一种正则化技术,研究人员展示了一种在不增加数据量的情况下提高泛化能力的实用方法。
Dropout通过在训练过程中随机停用单元,鼓励模型依赖分布式表示,从而降低其对特定路径的依赖并降低样本复杂性。这一发展不仅在不增加数据量的情况下提高了性能,还展示了架构简单性和数据效率如何相互加强。
2013年,Thomas Mikolov及其同事引入了Word2Vec,这是自然语言处理的一个突破。该模型以其能够数学化地表示语义关系而闻名,例如以下公式:
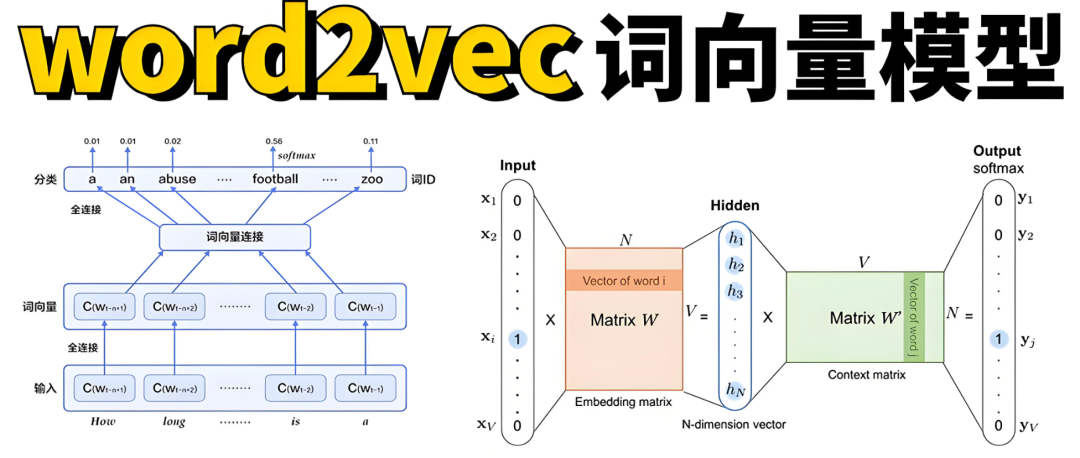
King - Man + Woman = Queen从统计学习理论的角度来看,Word2Vec是一个样本复杂性低的模型,通过数据量的扩展实现了高准确性。
尽管Word2Vec看起来像是一个标准的算法创新案例,但它的实际贡献在于将一个故意“弱”的模型与大量数据相结合。本质上:
弱模型 × 大量数据 = 高性能
这一事件强化了AI中的一个反复出现的模式:对大规模且高质量数据的访问往往比单独的复杂算法带来更大的收益。
DeepMind在Atari项目中结合Q学习和卷积神经网络,证明了强化学习(RL)可以促进有效无限数据的生成。

该模型从游戏玩法的视觉输入中学习,模拟了在物理世界中难以复制的体验。这项工作为合成数据生成开辟了新方向,并开启了从无限虚拟环境中学习的想法。
AlphaGo不仅在游戏策略上引入了新范式,还在数据生成、学习能力和决策架构方面引入了新范式 。以前的系统从人类专家玩的有限数量的游戏中学习。

相比之下,AlphaGo重新定义了这一轨迹。在对专家游戏进行预训练后,该系统开始通过自我对弈策略与自己玩数百万局游戏,从而生成了一个几乎无限的训练语料库。这种人工数据的丰富性使得学习深度达到了仅靠真实世界数据无法提供的水平。
AlphaGo仍然是一个罕见的例子,其中“更多数据”和“更好算法”协同促成了变革性的结果。
Transformer架构在“Attention is All You Need”中被引入,它用一个简化的但功能强大的替代方案取代了复杂的RNN和CNN模型。
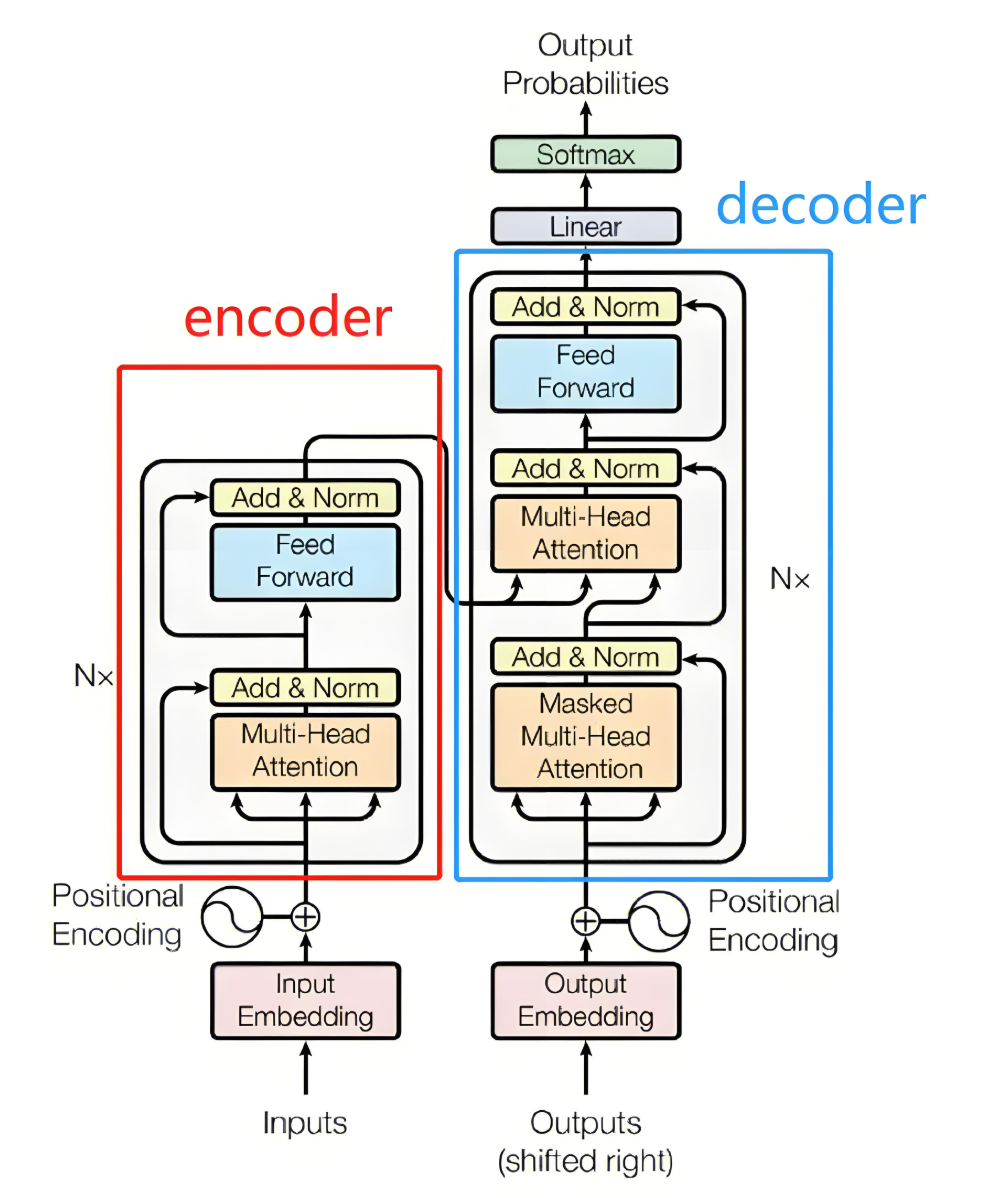
该架构完全依赖于注意力机制来捕捉长距离依赖性,消除了递归。这种方法显著降低了样本复杂性,并能够高效地在大规模数据集上进行训练。
研究人员广泛认可Transformer不仅因为其架构简单,还因为其在大规模上实现高数据效率的能力,使其成为现代AI的基础创新之一。
2018-2020年,GPT系列:通过规模和数据驱动的突破实现泛化。OpenAI的生成性预训练Transformer(GPT)系列是深度学习中最引人注目的成就之一。

这些模型的核心成功之处在于它们能够将Transformer架构扩展到处理巨大的数据量。
GPT模型采用了两阶段训练策略:首先,在无标签文本上进行大规模自监督预训练,以开发通用的语言表示;然后,在特定任务的数据集上使用较小的监督语料库进行微调。
GPT-1引入了这一范式,提出了一个简单的主张:“标记数据稀缺,但无标签文本丰富。我们首先进行大规模自监督预训练,然后在小数据集上进行特定任务的微调。”这种策略使模型能够有效地利用大规模数据源,并在广泛的任务中实现强大的性能。GPT1没有引入新的架构,而是展示了如何通过数据规模提升现有的架构。
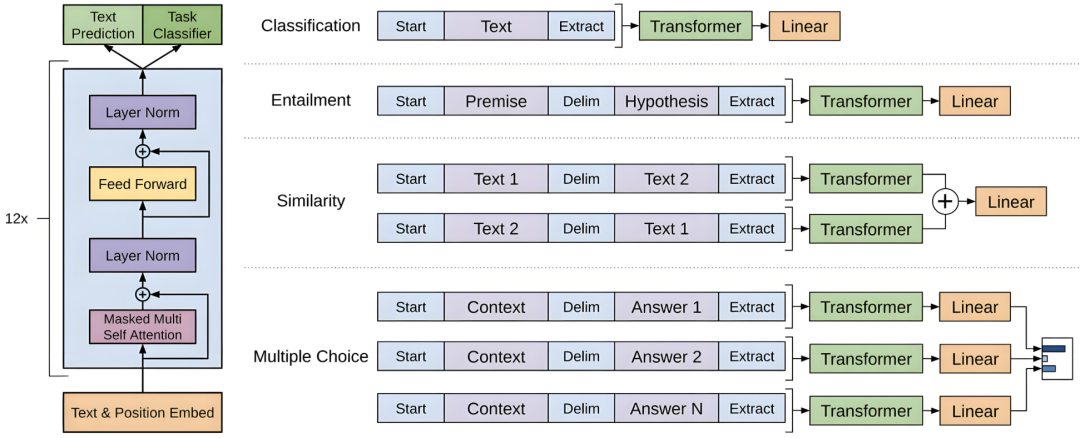
GPT-2遵循了相同的原则。它在WebText上进行了训练,这是一个从数百万网页中提取的大型数据集。这并不是一个架构上的飞跃,而是展示了增加数据量可以直接提升模型性能。更多的数据转化为更好的泛化能力和更高的准确性。
GPT-3进一步强调了规模的重要性。尽管作者没有明确将这一成就描述为“数据突破”,但模型的大小和参数数量隐含地揭示了它与数据的关系。GPT-3之所以超越早期模型,并非仅仅因为参数数量的增加,而是因为它能够有意义地利用更多且更多样化的数据。这一进展表明,扩大模型规模还需要相应地增加训练数据量,以解锁额外的学习能力。
此时,一个关键的平衡出现了。在不增加数据量的情况下扩大模型容量会带来过拟合的风险。成功取决于同时扩展模型和数据。GPT系列证明了架构与数据量之间的和谐是必不可少的,而不是可选的,对于大规模有效学习至关重要。
GPT的整体成功并非仅仅源于架构上的新颖性,而是将数据规模与模型容量对齐。这种对齐使模型能够在广泛的任务中实现零样本和少样本学习。该系列提供了明确的证据,表明“更多数据能够实现更好的泛化”,并展示了如何将这一原则转化为现实世界AI应用中的先进性能。
2022年,基于GPT-3.5构建的ChatGPT标志着技术基础设施和用户体验的一个关键时刻。OpenAI整合了人类反馈的强化学习(RLHF),使模型能够生成更自然、更具情境意识的回应。
通过通过一个公开的对话界面部署ChatGPT,OpenAI扩大了AI的社会影响力,并推动了其文化整合。这一模型体现了计算能力、数据和算法设计的平衡合成,使其成为一个多维度的突破。
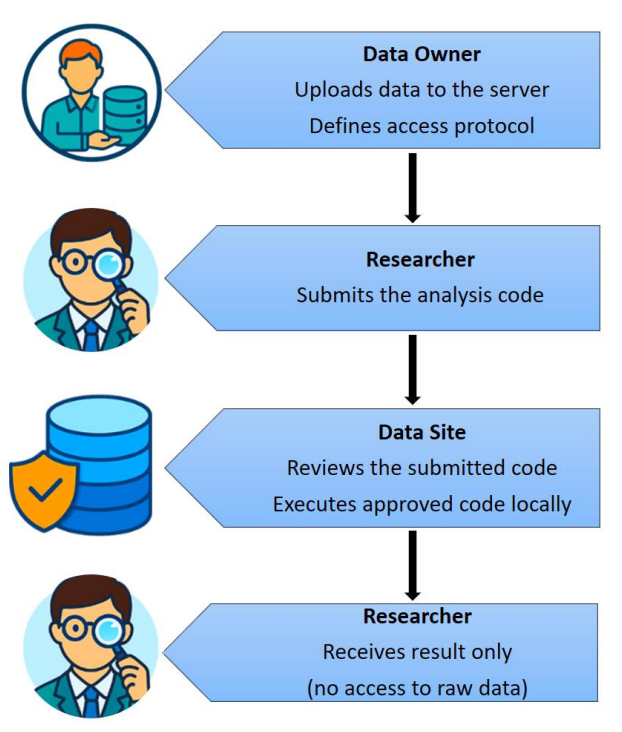
总体来看,这些突破反映了一个一致的模式,即算法设计、数据可用性和计算能力是协同进化的。
更仔细地观察AI的主要突破会发现,大多数创新都源于计算能力、算法设计和数据可用性之间的相互作用。然而,历史分析表明,高质量数据的访问一直占据主导地位。
“工程化的智能可能会带来短期收益,但长期的进步来自于应用于越来越强大的计算能力和越来越丰富数据集的可扩展学习算法。”
因此,本研究支持这样的预测:下一次重大的AI突破很可能会源于对更大、更高质量和更具包容性的数据资源的改进访问。
当我们审视过去十五年中AI的主要突破时,我们会发现其中大部分是由两个核心驱动因素支撑的:数据的扩展和计算能力的进步。
人工智能的演变影响的不仅仅是系统架构。它还影响开发者构建、部署和治理AI系统的方式。未来的突破将不仅仅需要强大的算法或大型数据集,它们还必须源自安全、可扩展且政治上可持续的基础设施。
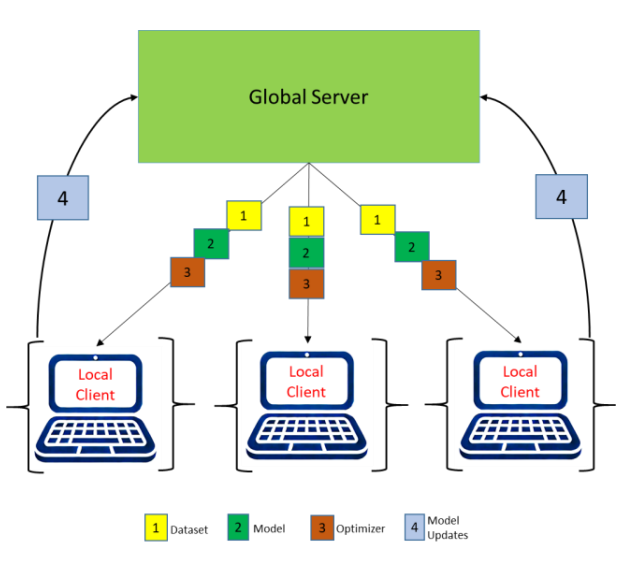
未来的人工智能研究可能会集中在三个关键领域:
-
改进联邦学习算法:研究人员将致力于提高在异构设备、非独立同分布数据和有限计算环境中运行的系统的效率和稳定性。
-
推进PET框架:工作将集中在开发更轻量、更快、更易于部署的差分隐私、同态加密和SMPC等技术变体。这包括算法优化和软硬件集成。
-
提高合成数据生成的真实性:研究人员将探索特定领域的生成模型,这些模型可以在不构成重新识别风险的情况下模仿真实数据。生成对抗网络(GANs)、变分自编码器(VAEs)和物理信息模拟器等技术将引领这一演变。
下一代人工智能基础设施必须优先考虑数据安全,维护伦理原则,在技术分布式环境中运作,遵守法律框架,并保持社会透明度。实现这一愿景将需要学术界、工业界和监管机构之间的深度协调,以确保突破在技术上有影响力且在社会上可持续。
本文从多维视角审视了过去十五年人工智能的演变,系统评估了三个核心驱动力:计算能力、数据量和算法创新。每个突破从历史角度来看,不仅仅是一个技术进步,也是一个结构性的范式转变,重新定义了人工智能研究的轨迹。
总之,人工智能的未来并不完全依赖于更大的计算能力或更大的模型。它取决于更好组织、安全、伦理和可访问的数据生态系统。
建立这些生态系统将需要跨学科合作,将工程学、法律、伦理学、社会科学和公共政策作为不可或缺的组成部分。
推动下一波人工智能突破的最关键因素将不再是“我们拥有多少数据”,而是“我们如何在伦理、安全和正确的上下文中使用数据”。
(文:AI技术研习社)