
今天是2025年6月5日,星期四,北京,晴
我们继续来看一些有趣的数据和新发现。
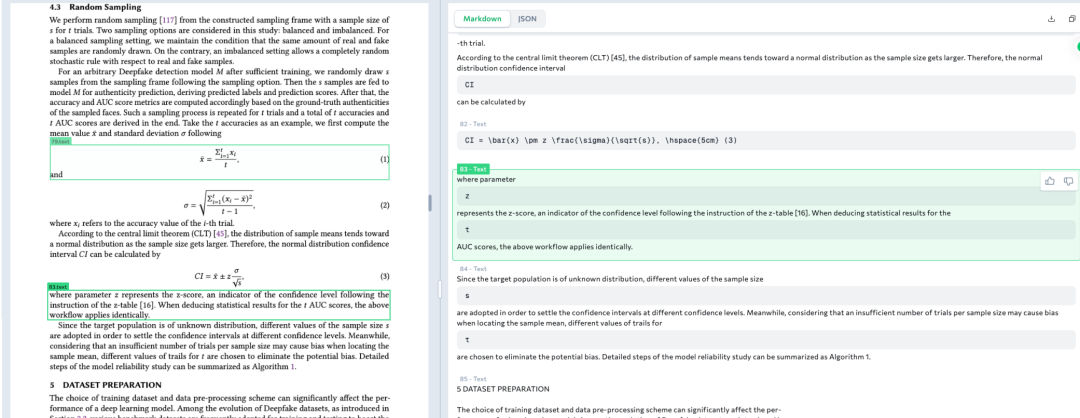
一个是将文本编码进MP4文件的有趣RAG尝试,思路很有趣,看看怎么做的。
另一个是Agentic-doc,用agent来做个文档处理。
都是很有趣的工作。
二、将文本编码进MP4文件的有趣RAG尝试
关于语义搜索进展,来一个很有趣的工作,Memvid,直接将文本数据编码成视频文件,通过将文本块压缩到单个MP4文件中,做语义搜索:https://github.com/olow304/memvid

索引的构建过程在:https://github.com/Olow304/memvid/blob/main/examples/build_memory.py,说明文件在:https://github.com/Olow304/memvid/blob/main/USAGE.md
核心点是,在实现快速语义搜索(1M块少于 2秒)目标时,不使用向量化数据库,而是基于MP4索引文件,所以整个数据流为:
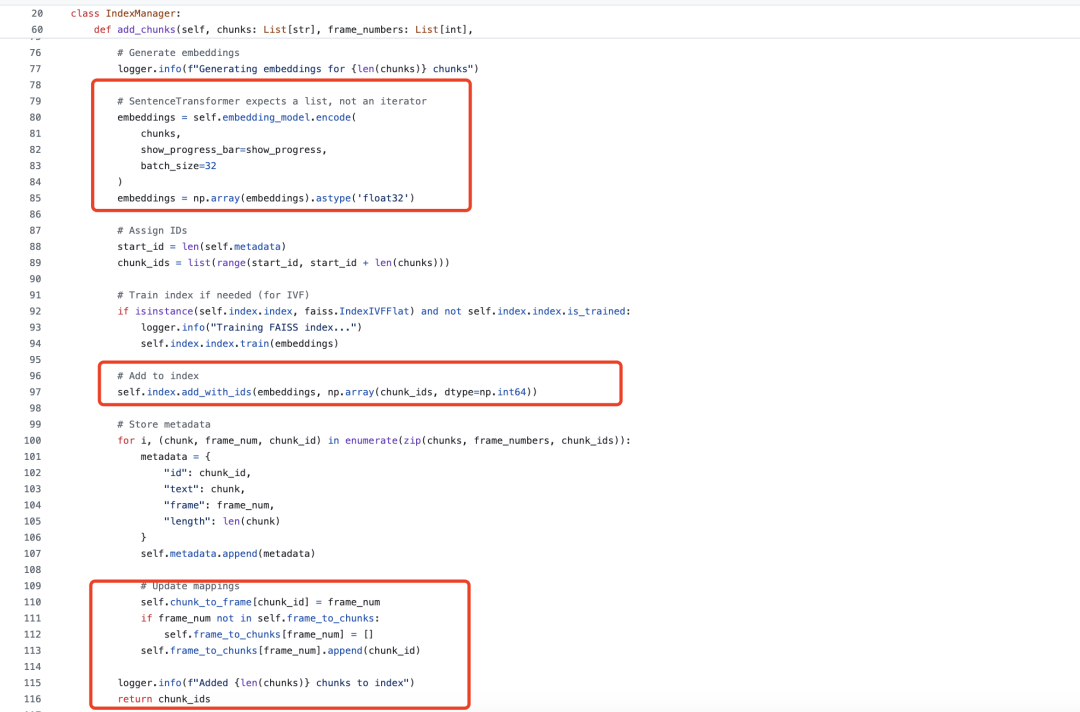
一个是构建索引,怎么把chunk编码成视频做存储

chunk转二维码并记录索引,做embedding后送Faiss。
1、mp4文件的构成
之前的方案,需要额外有一个存储文档chunk的数据库,比如es,mongodb或者mysql,所以,为了解决这个问题,就用mp4来存储一个个chunk,那么怎么存储,就是编码为一个个二维码,然后记录出这个二维码位于整个视频中所在的帧索引,也就是timestamp,所以就会形成以下这个结构:
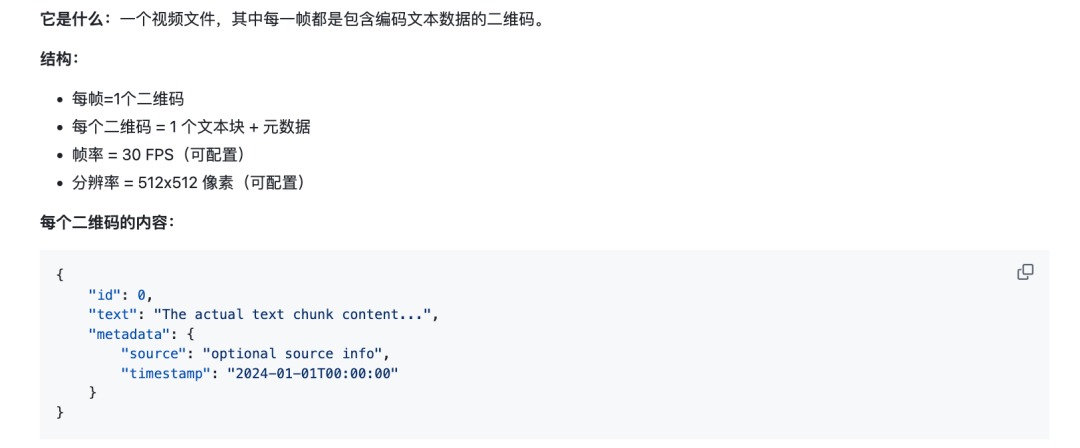
那么,问题来了,怎么把chunk变成一个二维码?那就是使用FFmpeg用于视频编码,使用libzbar0用于二维码解码。
2、索引文件
索引文件包括:memory_index.json+ memory_index.faiss
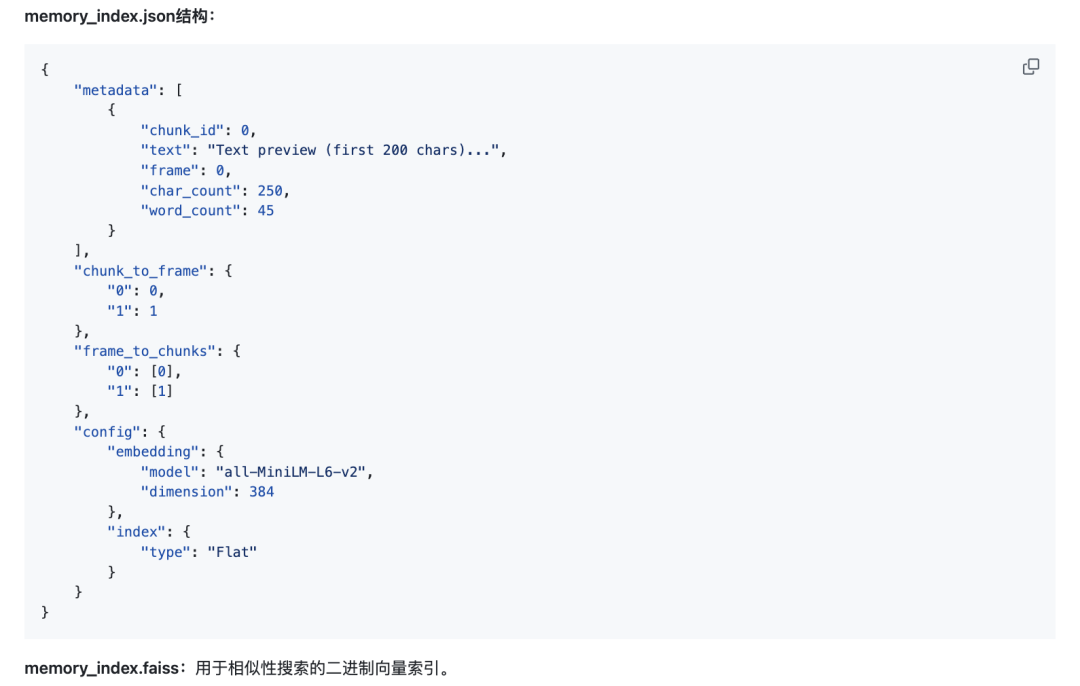
在向量化方面,其实跟之前并没有区别,还是使用sentence_transformers进行chunk嵌入,然后存入faiss中。
这么一来,除了faiss之外,就没有额外的数据库了,给出了一个大致的量化结果:

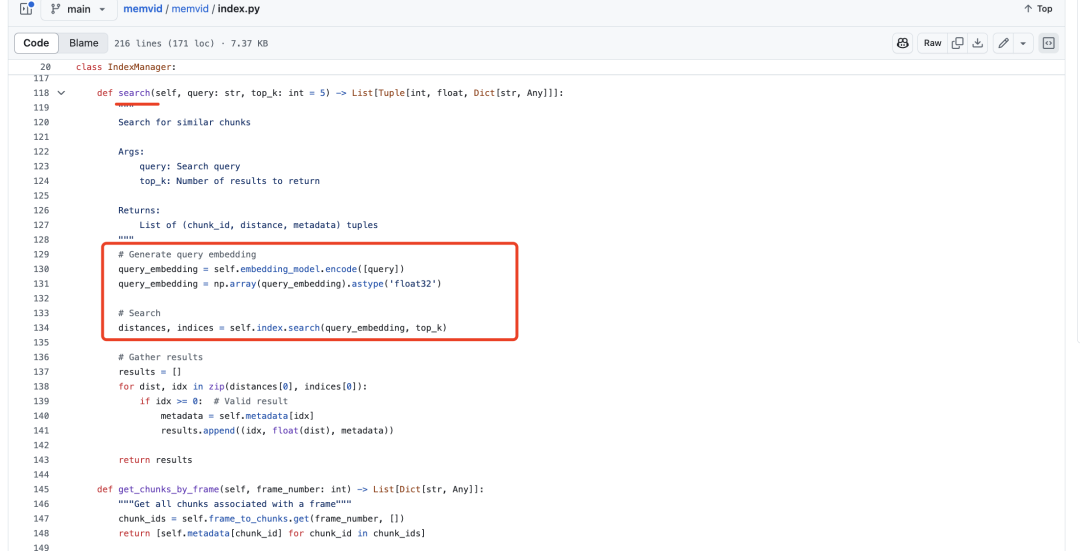
一个是索引的使用,也就是执行检索

query做embedding后送faiss做检索,然后获取frame number去获取对应的chunk,送大模型做生成。
这种思路很有趣,属于数据库中的一个新奇思路,但是其中会遇到二维码生成失败等问题,并且并不灵活,比如我们通常在rag索引的过程中,会添加很多元素,并且还有Graphrag等方案,这种就很难支持了,所以,从灵活性和效果优化上来说,并没有太大的实用意义。
二、Agentic-doc,用agent来做个文档处理
上次有人问用agent来做文档解析,真有了,gentic-doc:高效提取复杂文档结构化数据的Python库,从表格、图片、图表等复杂文档中提取结构化数据并返回精确位置的层级JSON。 支持超长文档,单次调用可处理1000+页PDF;自动重试与分页,智能处理并发、超时和速率限制;提供可视化工具,可生成标注提取区域的图像,方便调试与验证。
这个倒不奇怪,因为接入agent范式之后,串起来各类api,理论上来说,就能解决一批单模型无法做的事情。
地址在:https://github.com/landing-ai/agentic-doc,不过要收费:https://landing.ai/agentic-document-extraction,视频介绍:https://landing.ai/videos/agentic-document-extraction
说下测试结论,社区成员有做过测试,性能跟minerU在线版差不多。
参考文献
1、https://github.com/olow304/memvid
2、https://github.com/landing-ai/agentic-doc
(文:老刘说NLP)