
今天是2025年6月7日,星期六,北京,晴
今天来看知识图谱的问题,关于知识图谱本体。
我们介绍两个工作,一个是RAG用于Mysql数据生成知识图谱本体,另一个是基于非结构化知识库进行本体生成。
一、RAG用于Mysql数据生成知识图谱本体
关系数据库在数据管理中很重要,但由于其结构化框架,难以进行语义查询和集成。将关系数据库转换为知识图谱(KG)可以促进数据共享和集成,并增强学习和推理能力,但是,现有工作主要集中在从关系数据库中提取本体,但大多依赖于数据库模式(如表和列名),缺乏外部知识,导致生成的本体质量不高。
近期的工作《Retrieval-Augmented Generation of Ontologies from Relational Databases》(https://arxiv.org/pdf/2506.01232),介绍了一种名为RIGOR(Retrieval-augmented Iterative Generation of RDB Ontologies)的方法,用于将关系数据库转换为丰富的OWL本体。
实现流程如下:
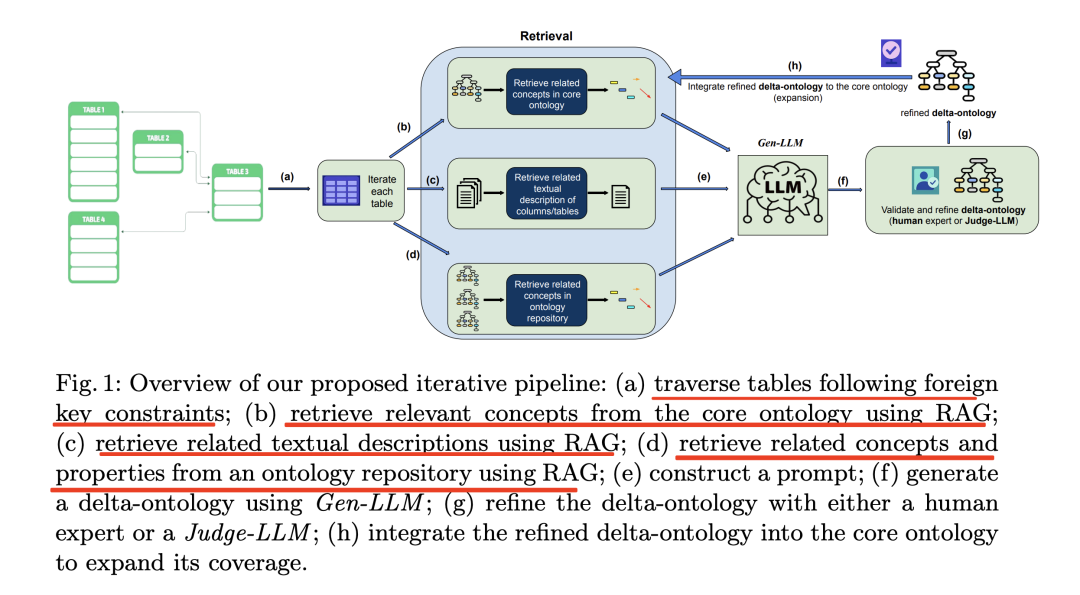
(a)按照外键约束遍历表;(b)使用RAG从核心本体中检索相关概念;(c)使用RAG检索相关文本描述;(d)使用RAG从本体库中检索相关概念和属性;(e)构建提示;(f)使用Gen-LLM生成增量本体;(g)通过人类专家或Judge-LLM对增量本体进行细化;(h)将细化后的增量本体整合到核心本体中,以扩展其覆盖范围。
其中,用于本体生成的提示模板如下:
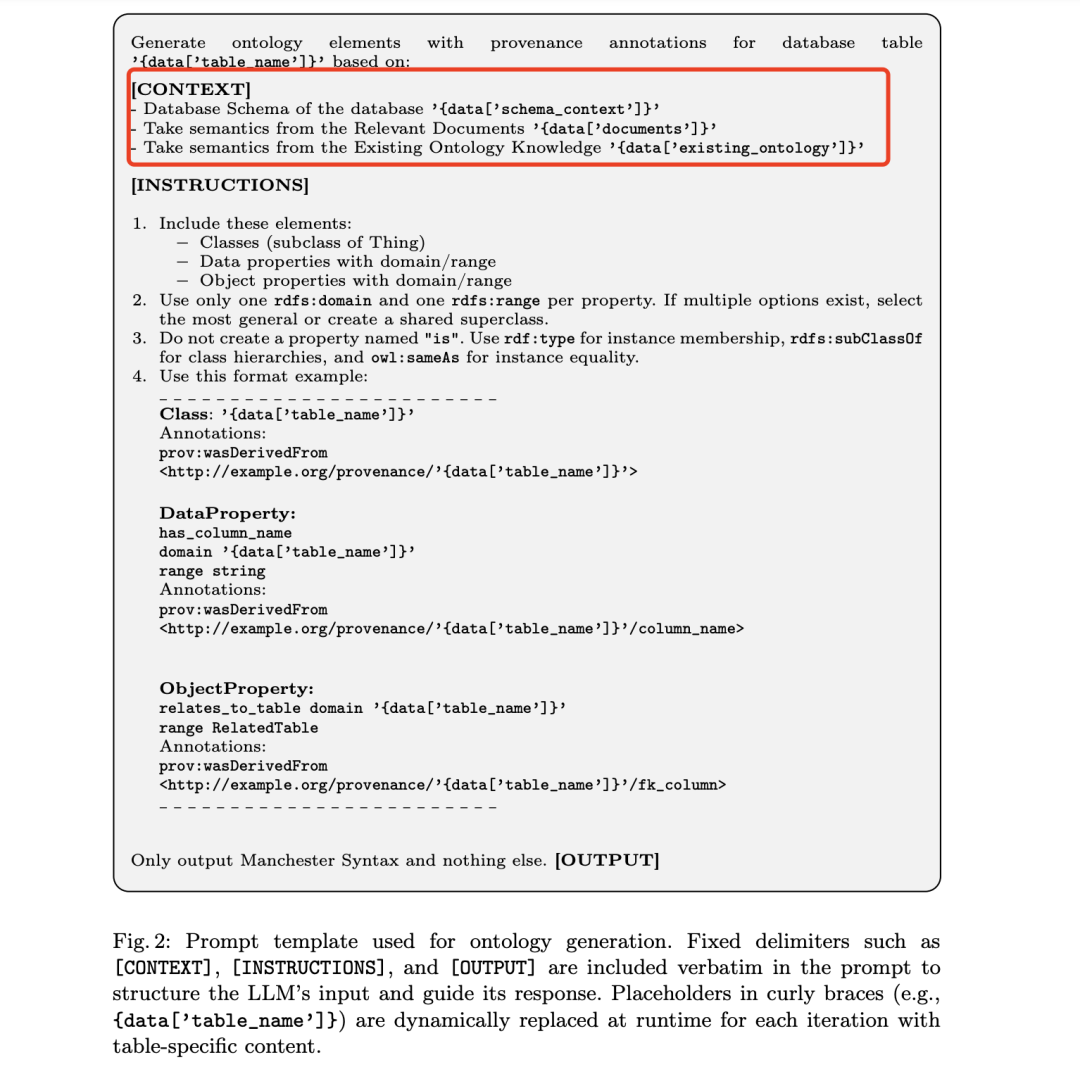
固定的分隔符(如[CONTEXT]、[INSTRUCTIONS]和[OUTPUT])被逐字包含在提示中,以结构化LLM的输入并引导其响应。花括号中的占位符(例如,{data[‘table_name’]})在每次迭代时都会动态替换为特定于表的内容。
看一个转换结果:
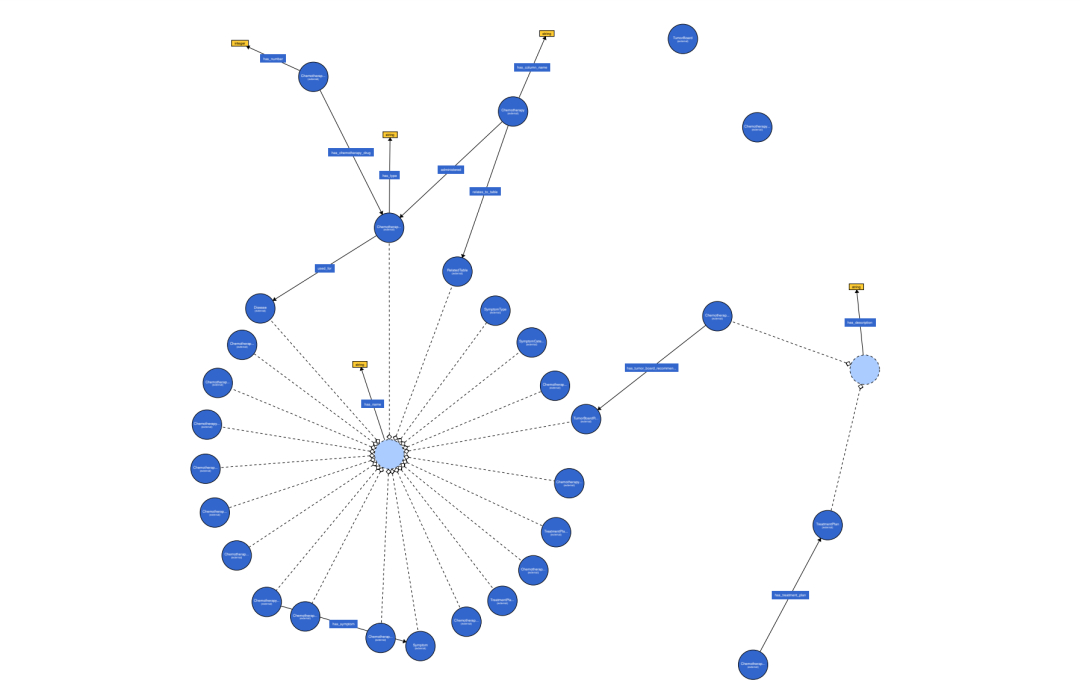
这个工作的意义在于,加快将mysql数据库为知识图谱的转换速度。
二、基于非结构化知识库进行本体生成
本体对于构建知识库以增强由大模型生成问答有价值,尤其是对知识库的约束上,有组织总比没有好。
但是,传统的本体创建依赖于领域专家的手工努力,这一过程耗时耗力、易出错,所以自动化生成是常用的一个方案。
所以,可以看一个工作《OntoRAG: Enhancing Question-Answering through Automated Ontology Derivation from Unstructured Knowledge Bases》(https://arxiv.org/pdf/2506.00664),提到一种在从非结构化知识库中提取本体的方法,重点关注电气继电器文档,也是对上面文章的补充。
那么,是怎么做的呢?
主要流程如下,包括六个阶段:网络抓取、PDF解析、混合分块、信息提取、知识图谱构建和本体创建。
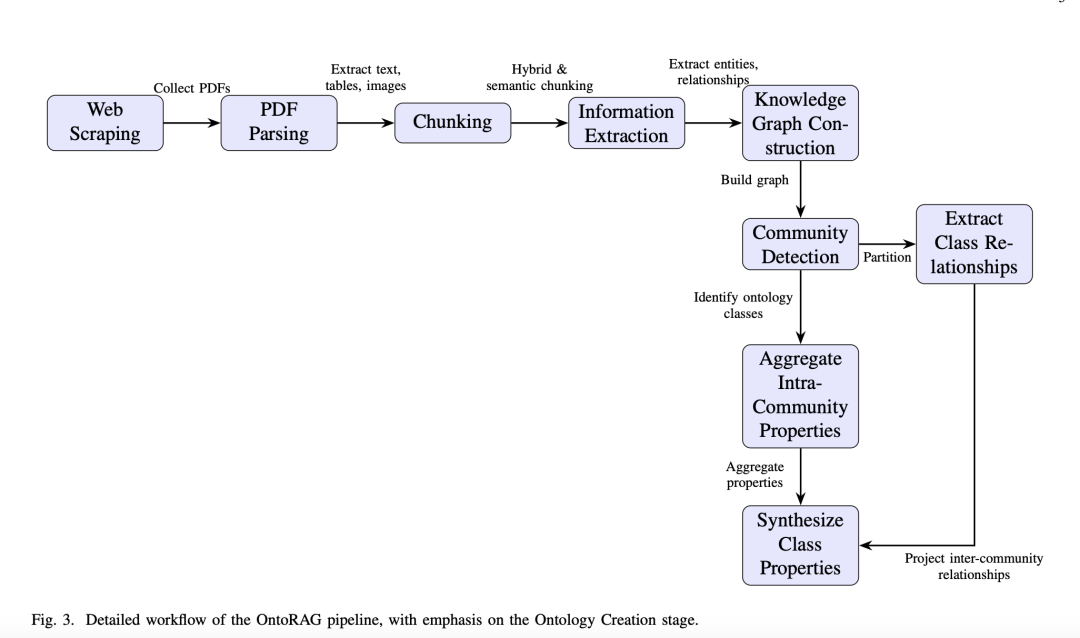
其中:
PDF解析阶段,采用Unstructured库,结合OCR、对象检测和数字解析技术,准确识别文档布局和元素位置。为了提高表格提取的准确性,使用PyMuPDF对表格区域进行隔离和处理。
混合分块阶段,结合了基于元素的和基于语义的分块方法,确保生成的块在上下文上连贯且适合LLM处理;
信息提取阶段,使用Gemini 2.5 Flash进行文本清理、消歧、命名实体识别、原子事实提取等步骤,将文本转换为结构化的原子事实和关系;
知识图谱构建阶段,通过聚类关键元素形成本体类,并将关系投影到这些类上,形成知识图谱;
本体创建阶段,应用Leiden社区检测算法对知识图谱进行分区,提取类属性并合成类属性,最终形成层次化的本体结构。
那么,怎么验证其有效性,也可看看:
使用了一个包含约100万token的ABB继电器产品PDF文档数据集进行评测,结论是:OntoRAG通过将LLMs与基于图的方法结合,在全面性和多样性方面优于向量RAG和GraphRAG,可以实现88%和65%的胜率。
参考文献
1、https://arxiv.org/pdf/2506.01232
2、https://arxiv.org/pdf/2506.00664
(文:老刘说NLP)