
小红书正式加入开源大模型行列!

dots.llm1 模型生成的自我介绍图
小红书hi lab 团队刚刚公布了他们的第一个开源大模型dots.llm1!
朋友看到后,兴奋得直接从床上跳下来做量化去了……(这种兴奋,懂的都懂
这个142B参数的MoE模型,仅需14B激活参数就能与Qwen2.5-72B打平。
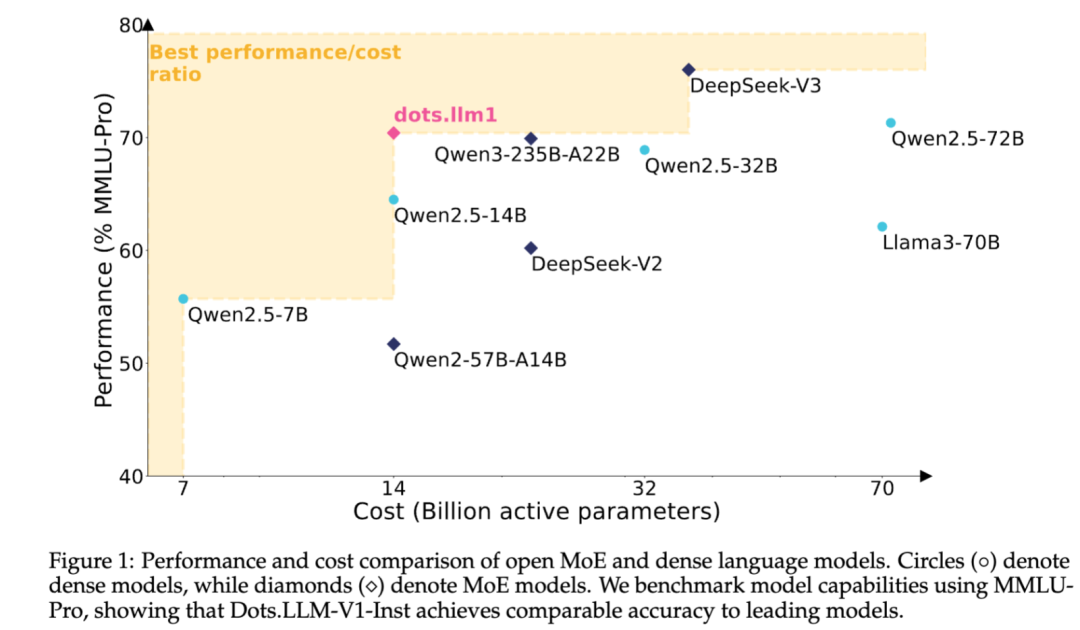
更令人惊喜的是,小红书这次开源力度可以说是前所未有——
不仅开源了最终模型,还公开了每1T token的中间训练checkpoint,总共14个模型权重全部放出!
小,却精悍
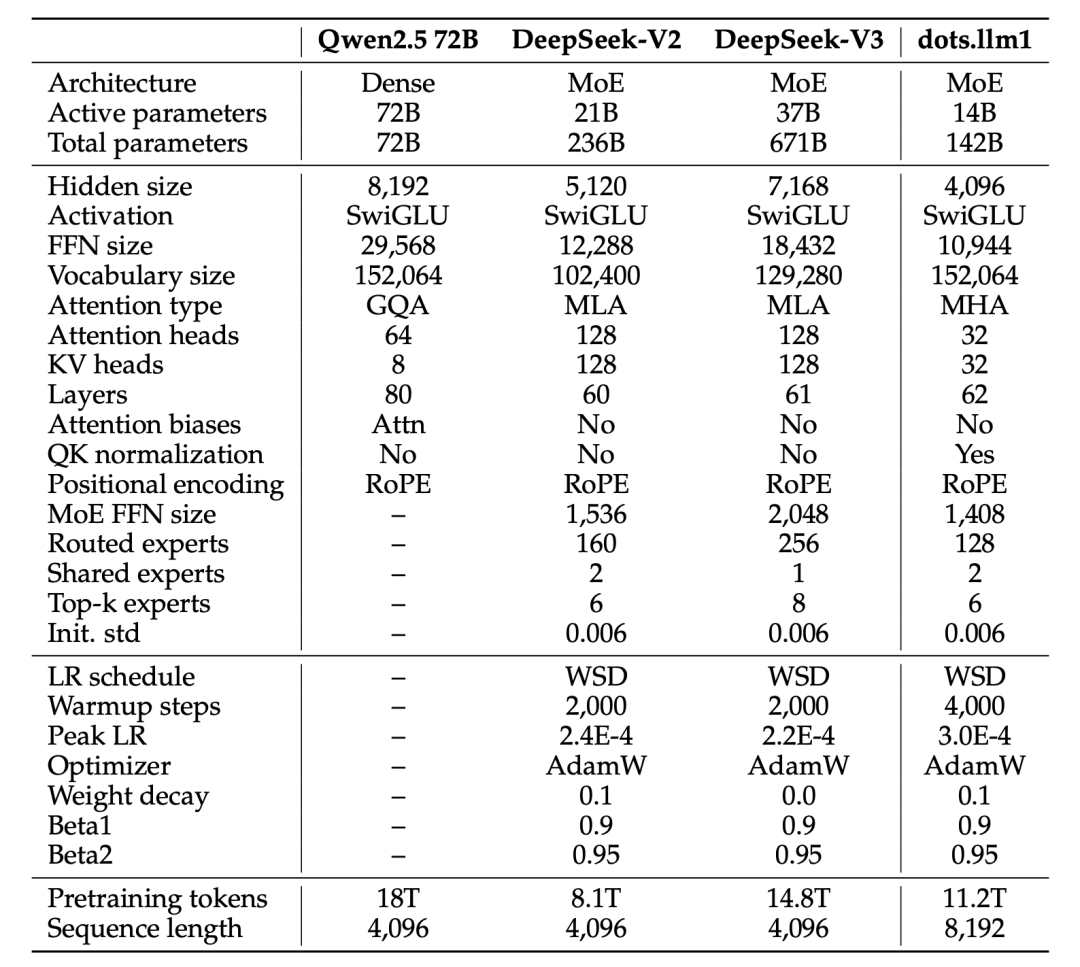
先看看dots.llm1的基本配置(见HG):
-
模型架构:142B总参数,14B激活参数的MoE结构
-
专家配置:128个路由专家中选6个,外加2个共享专家
-
层数深度:62层
-
训练数据:11.2T高质量token,无合成数据
-
上下文长度:32,768 tokens
-
支持语言:中英双语
以小博大
在综合评测中,dots.llm1 展现出了极高的效率:
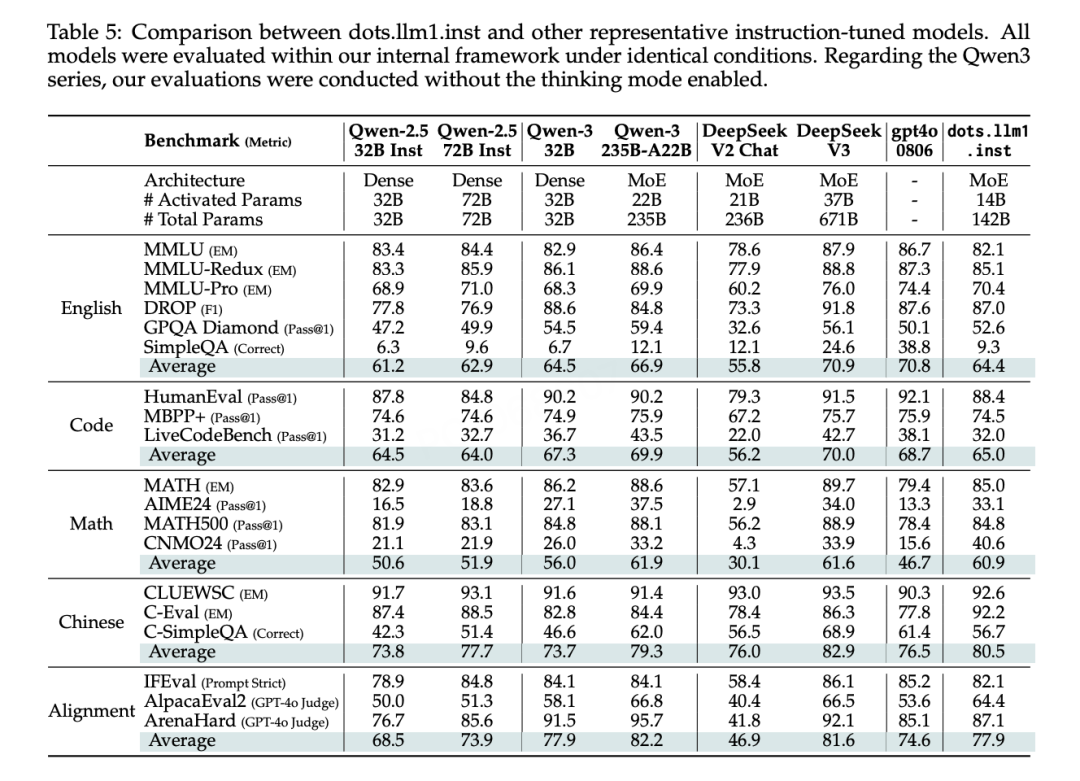
中文任务表现卓越
在CLUEWSC语义理解上得分92.6,达到业界领先水平;C-Eval综合知识评测得分92.2,超越了包括DeepSeek-V3(86.3)在内的所有对比模型;中文任务平均得分80.5,显著领先。
数学推理能力突出
在高难度的AIME24竞赛题上得分33.1,展现了处理复杂数学问题的能力;MATH500得分84.8,超越Qwen2.5系列,接近最先进水平;CNMO24(中国数学奥赛)得分40.6,数学综合得分60.9。
英文和代码能力均衡
在MMLU、DROP、GPQA等英文基准测试上与Qwen系列相当,平均得分64.4;代码能力虽不是最强项,但65.0的平均分也达到了Qwen2.5的水平。
对齐能力优秀
在IFEval、AlpacaEval2、ArenaHard等指令遵循和人类偏好对齐测试上,平均得分77.9,表明模型能准确理解和执行复杂指令。
这种性能表现,对于仅14B激活参数的模型来说,不得不说,确实让人印象深刻——在多个维度上超越或打平72B参数的Qwen2.5-Instruct,证明了dots.llm1架构设计的有效性。
效率为王
dots.llm1 在训练效率上下足了功夫。
在Interleaved 1F1B流水并行的基础上,通过增加warmup step、反向计算拆分和精细化计算通信调度,巧妙地让EP A2A通信与计算重叠,用计算时间掩盖通信延迟:
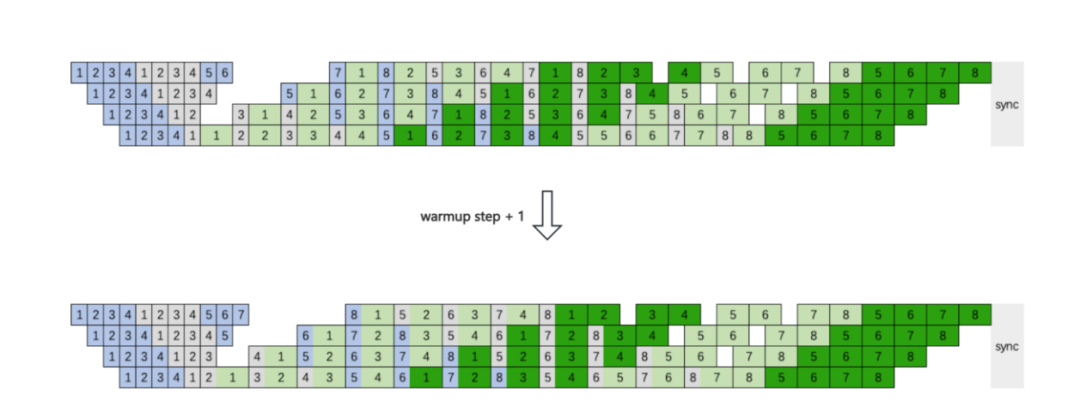
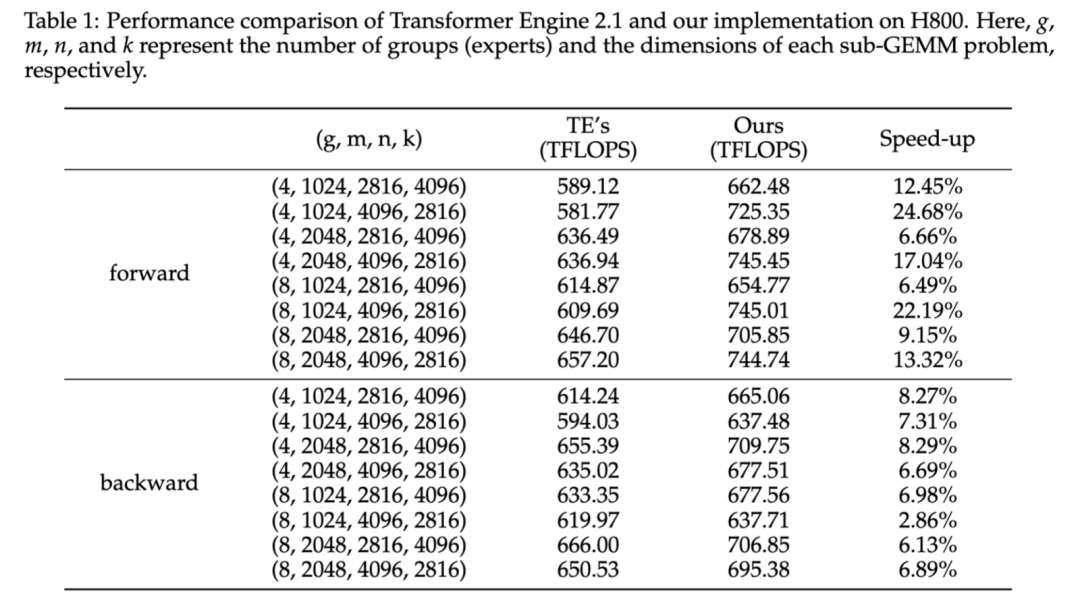
同时,团队还优化了Grouped GEMM实现,在H800上相比NVIDIA Transformer Engine,单算子前向计算平均提升14%,反向计算平均提升6.68%。
数据质量优先
在数据处理上,hi lab团队采用了三阶段精细化处理框架:
1. Web文档准备:先过滤有害内容,再提取HTML正文,最后进行语种过滤和去重
2. 规则处理:除了常规清洗,还引入了行级别去重策略——识别并删除文档首尾的噪声文本(如广告、导航栏)
3. 模型处理:
-
网页类型分类,保留文本核心内容
-
200个类别的数据均衡模型,提高知识类内容比例
-
行噪声删除模型,进一步清理长尾噪声
这套流程确保了11.2T训练数据的高质量,无需依赖合成数据就达到了优秀的效果。
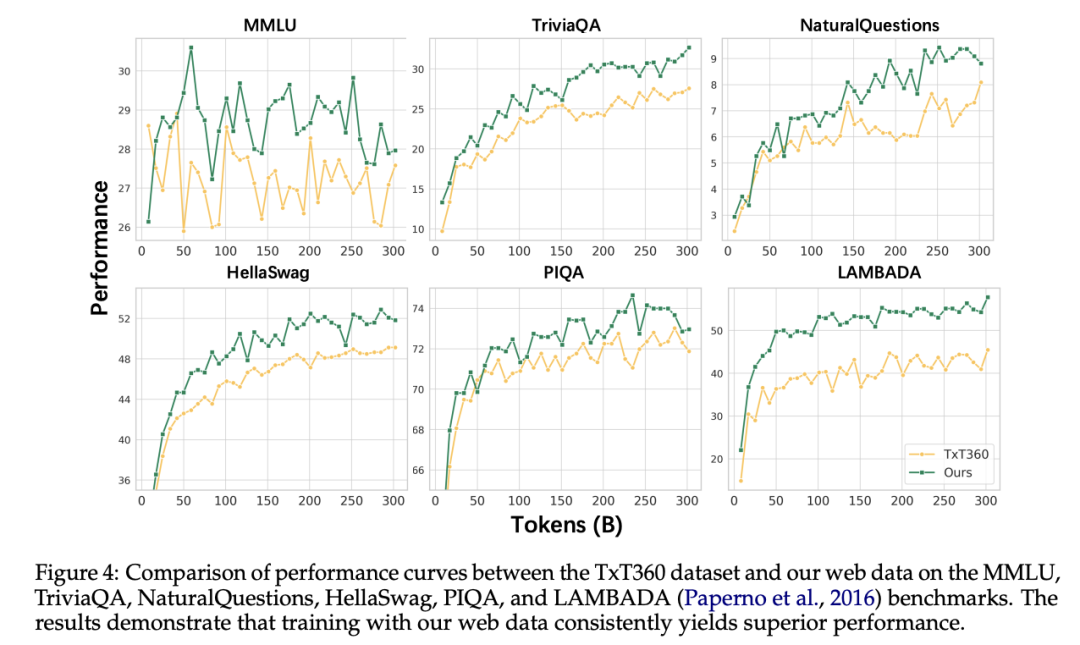
经过上述处理流程,hi lab团队得到了一份高质量的预训练数据,并经过人工校验和实验验证,证明该数据质量显著优于开源TxT360数据。
训练稳扎稳打
dots.llm1采用WSD学习率调度,整个训练过程非常稳定:
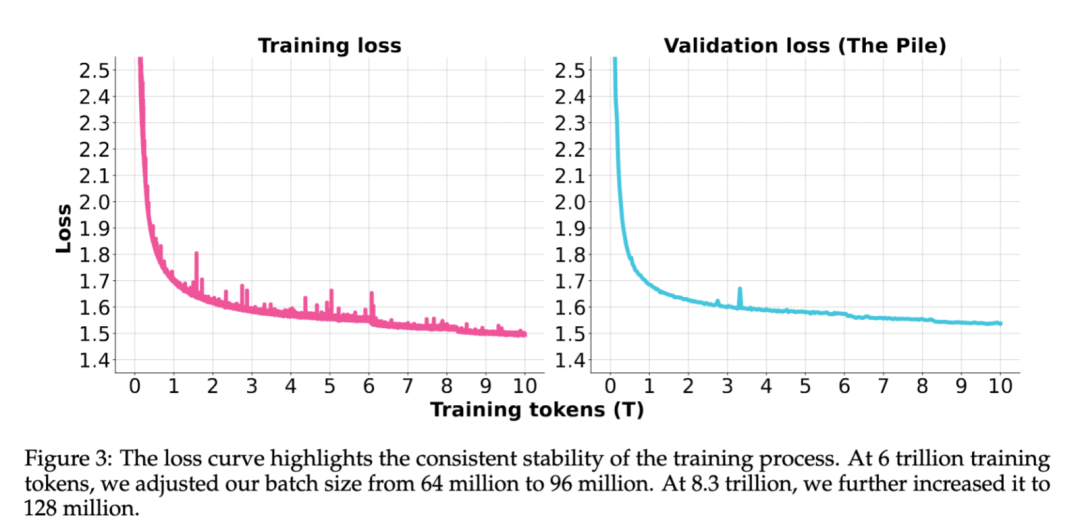
主训练阶段用了10T token,学习率从0逐步warmup至3e-4后保持稳定。
训练期间两次提升batch size,从初始的64M增加到96M,最终达到128M,通过渐进式扩大batch来提升训练效率。
全程无严重loss spike,无需回滚。
退火阶段分两步走——
第一阶段1T token,学习率从3e-4缓慢下降至3e-5,强化推理和知识语料;第二阶段200B token,学习率继续下降至1e-5,提升数学和代码能力。
最大力度开源
这次开源的内容之全面,堪称业界之最猛力度,业界良心,包括:
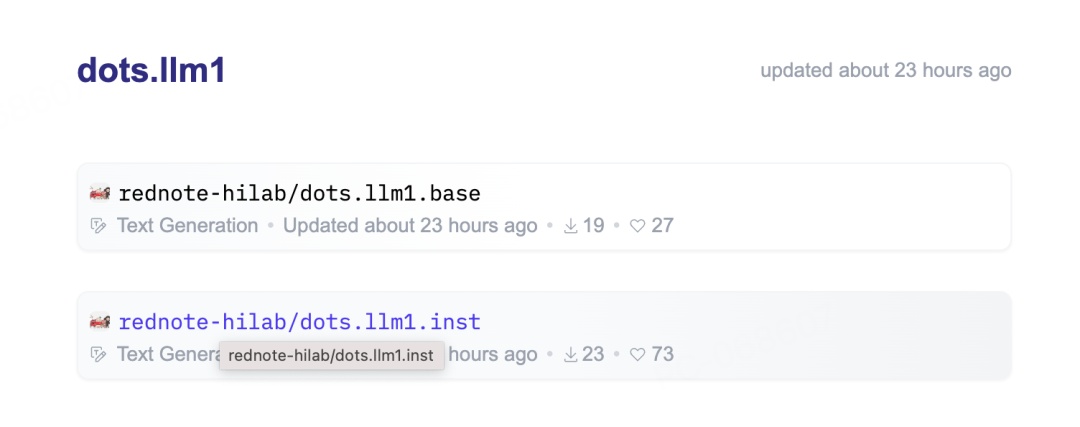
-
✅ dots.llm1.inst指令微调模型
-
✅ dots.llm1.base基础模型,每1T token的中间checkpoint(共11个)
-
✅ 退火阶段前后的模型
-
✅ 长文本base模型
-
✅ 详细的训练超参数和scheduler 信息
对于研究人员和GPU Poor (比如我……)来说,这些中间checkpoint极其宝贵——可以研究模型的学习动态,也可以从任意阶段继续训练。
这是首个开源如此完整训练过程的千亿参数级MoE模型!
国外网友又一次炸了
看完模型相关信息,其实我的大体评价是:还行,有得玩,有点意思……

但上网一看,才发现网友们居然又一次炸了……这届网友对中国模型的炸点似乎有点偏心的低啊(也许是Meta 实在太拉胯了吧😂)
从X 到reddit 和电报、discord,我看下来整个国外技术圈对小红书这次开源反应可算是相当热烈,毕竟很多人在 TikTok 避难时就认识了这家中国公司——天然自带温暖感吧。
网友Teortaxes(@teortaxesTex) 深度分析了技术细节:
小红书在LLM领域首次亮相就带来了dots.llm1。又一个内部AGI部门(hilab),自豪地基于DeepSeek V2技术栈构建。DS-MoE架构、无辅助损失平衡、DualPipe变体、142B总参数/14B激活参数……还分享了中间训练检查点。虽然没有MLA,但下一个目标明确:「复制DeepSeek V3」。
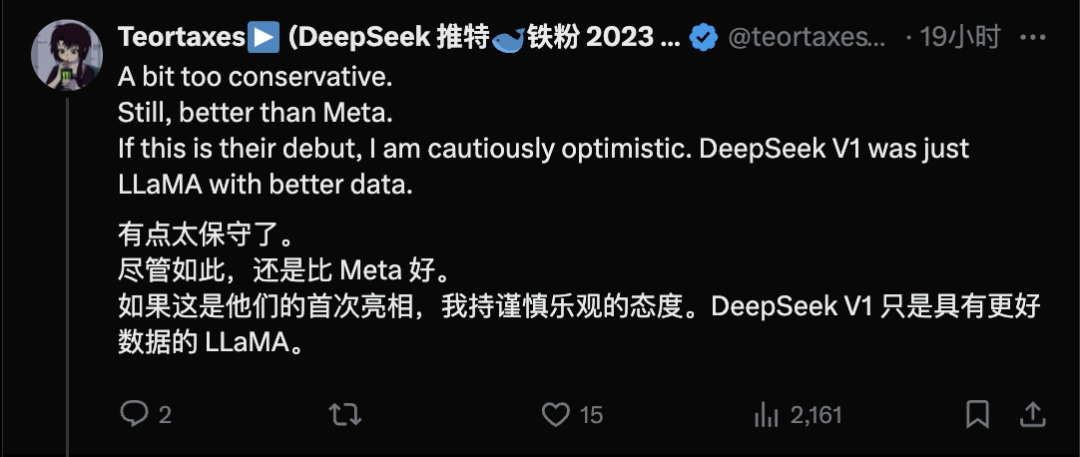
他还补充道:
有点太保守了,但还是比Meta强。如果这是他们的首秀,我持谨慎乐观态度。要知道DeepSeek V1也只是用了更好数据的LLaMA。
George(@georgejrjrjr) 给出了更深入的技术评价:
保守但被低估了:
自Nemotron-340B以来首个超过100B的开源基础模型 训练集中没有垃圾数据 WSD学习率调度+开放检查点,意味着你可以在任何你想要的数据分布上进行退火训练 这可能是迄今为止最具可塑性的开源发布。
网友vitens(@intervitens) 则好奇其中的一个技术细节:
MHA(多头注意力)是个奇怪的选择,特别是对于MoE模型。这让高效服务变得非常困难。
Ilyas Salaoui(@IlyasSalaoui) 总结了中国AI的优势:
中国正在发生的不仅仅是规模扩张——而是效率革命。他们正在设计智能、精简的模型,其性能远超其成本。这是游戏规则的改变者。
mrfakename(@realmrfakename) 提出了优化思路:
很好奇这些专家实际上有多少被利用了。@kalomaze 在修剪Qwen3的专家方面做了一些有趣的工作,想知道是否可以对这个模型做类似的事情。
LordZealot(@0dongfeng) 幽默地补充:
「比Meta更好」,这……让我笑死了😭

而Anna Kensor(@AnnaKensor) 则评论称:
小红书的成本性能优势。一股安静的潮流,真的。对于那些一直在观察的人来说,事情总是朝着这个方向发展,不是吗?只是比一些人希望的要晚一些。
总体看下来,以技术层面的认可为主,也有对快速追赶的惊讶。
特别是在成本控制和工程效率上,这次的dot.llm1 又一次让中国模型在国际AI 圈展现出了极大的优势。
实战之开箱即用
Docker部署(推荐)
最简单的方式是使用官方Docker镜像:
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
rednotehilab/dots1:vllm-openai-v0.9.0.1 \
--model rednote-hilab/dots.llm1.inst \
--tensor-parallel-size 8 \
--trust-remote-code \
--served-model-name dots1
启动后可以通过curl测试:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "dots1",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
],
"max_tokens": 32,
"temperature": 0
}'
Hugging Face推理
文本补全示例:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "rednote-hilab/dots.llm1.base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16
)
text = "人工智能的未来发展方向是"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
对话模型使用:
model_name = "rednote-hilab/dots.llm1.inst"
# ... 加载模型代码同上
messages = [
{"role": "user", "content": "用Python实现一个快速排序算法"}
]
input_tensor = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
)
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=200)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
vLLM高性能部署
vllm serve rednote-hilab/dots.llm1.inst --port 8000 --tensor-parallel-size 8
SGLang部署
python -m sglang.launch_server --model-path dots.llm1.inst --tp 8 --host 0.0.0.0 --port 8000
两种方式都会在http://localhost:8000/v1提供OpenAI兼容的API服务。
实测
让我们通过几个实际案例,感受一下dots.llm1的能力。
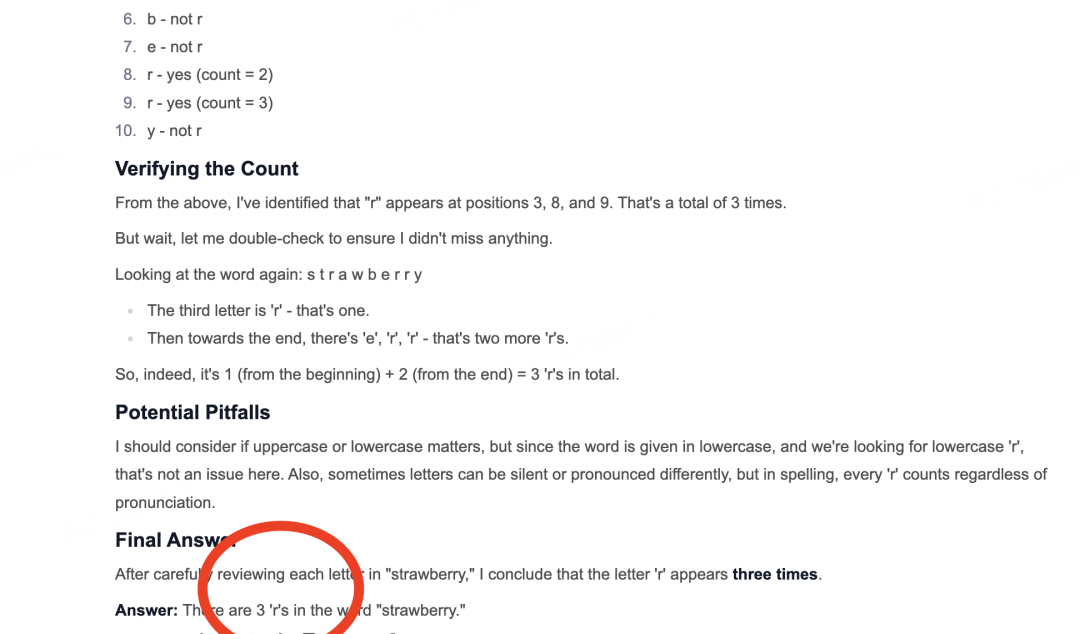
先来道数字母的题:

预期之中,轻松过关:
那就得上点难度了——模型靠不靠谱的标准考题:
我有70块钱,我借给小明五十块钱,他又用这五十块在我这里买了五十块钱的水果。第二天我借给小明30块钱,小明用这30块钱买了30块钱的牛奶,小明还欠我多少钱?请先推理,最后给出结论

同样回答正确!
还自带推理和思维链,从不同角度进行了验证、并提示了可能的误区,通过智力考试,是个“靠谱的智能模型”!
智商还行,要看情商了,接下来几个刁钻的测试,来感受一下这个a14B的MOE 模型到底有多少能耐。
测试一、高难度文学风格模仿
——用鲁迅的文风写职场(上为dots-llm,下为deepseek v3):


这个小文学测试中,dots.llm1算是展现出了对文学风格的精准把握——不仅模仿了鲁迅的句式结构,还融入了对现代职场文化的辛辣讽刺。
相较于DeepSeek V3更直接的描述,dots.llm1通过对经典意象的创新运用,赋予了文本更强的张力,推测是小红书能用到的语料,对比deepseek 的浮夸风来说,还会要更稳和可控,也更可用一些。
测试二、复杂指令融合与创意写作
——霸总文学改写白蛇传(上为dots-llm,下为deepseek v3):


面对「用霸总文学风格改写白蛇传,让许仙是个AI工程师」这个脑洞大开的要求,dots.llm1构思的「数字幽冥」白素贞和「网络安全专家」法海,在设定上显得更有新意。
它成功地将古典传说与现代元素结合,创造出了一个充满想象力的故事框架。这种处理方式体现出其对题意的理解更深,文风把握可算是非常到位。
三、跨领域知识应用
——经济学解释原神抽卡(左为dots-llm,右为deepseek v3):

dots.llm1用「经济学原理解释原神抽卡机制为什么让人上瘾」的回答中,准确运用了边际效用递减、沉没成本谬误等经济学概念,分析深入浅出。
相较DeepSeek V3,dots5的「票赋效应」和「心理账户」概念,更精准地解释了玩家「抽到角色后反倒更愿意花钱」的心理。
四、最有意思的是共情与情绪理解能力:
(上为dots-llm,下为deepseek v3):


综合智商情商来看,dots.llm1 称得上是双商完全在线,对得住a14B的MOE 模型的预期和刁钻考验。
不过也有指令遵循和理解方面的不足,当我用mac 自带语音识别提问:请画一个页面时,dots.llm1 回答「我没有作画能力」,虽然我本质上,预期的是写html 即可。
另外,从目前的资料来看,dots.llm1 还具备function call 能力——不过我没进一步进行测试,有兴趣的可以测测看。
同时,从目前官方的使用页面上来看,dots.llm1 还有artifacts 相关的支持,相信会迅速完善优化。(现在能用,但还不够好用)
后起新秀
小红书hi lab(Humane Intelligence Lab,人文智能实验室)是小红书内部的大模型技术与产品研发团队。在团队的介绍中,特别提到了「多元智能」和「拓展人机交互的边界」,可见文本大模型只是一个起点。
小红书从2023年开始投入基础模型研发,dots.llm1是其首次开源尝试——通过开源,小红书向技术社区展示了一个重要态度:开放交流,共同进步。
如团队所说,开源让技术对话成为可能。
一方面为开发者提供更多选择,另一方面也能从社区的反馈和改进中获得成长。在最新的HuggingFace热门开源模型榜单中,中国模型的占比已经超过50%,这种百花齐放的局面正是开源精神的体现。
而小红书的内容生态优势也不容忽视。
作为生活方式分享平台,小红书积累了海量高质量UGC内容。这些数据在生活场景、消费决策、情感表达等领域的丰富度和真实性,为模型训练提供了独特的养分。
结合此前推出的「点点」AI搜索助手——一个垂直于生活场景的AI产品,通过聚合全网生活经验为用户解答美食、购物、旅游等问题,小红书正在构建自己的AI 技术体系。
有数据显示,小红书日均搜索量已接近6亿次,70%的月活用户使用搜索功能,这些都为AI能力的落地提供了丰富的应用场景。
从dots.llm1的表现来看,模型在中文理解、生活场景对话、创意写作等方面已经展现出独特优势。这预示着,基于平台特色训练的垂直能力,或将成为小红书AI 的差异化方向。
值得关注的开源新选择
对于开发者而言,dots.llm1带来了几个独特价值。
极致的开源透明度让研究和二次开发变得前所未有的便利,优秀的性价比意味着14B激活参数就能达到72B模型效果,部署成本大幅降低。
在中文场景的突出表现,以及基于小红书内容特色在生活、消费、创作等场景的潜在垂直能力,都是值得深挖的方向。
写在最后
随着dots.llm1的发布,凭借独特的内容生态、扎实的技术实现和开放的开源策略的小红书,正逐渐展现出成为大模型领域重要玩家的潜力。
对于整个行业而言,这是一个积极信号——
更多元的参与者、更开放的生态、更创新的技术路线,将推动中国大模型技术继续向前发展。
而这,还只是小红书的第一个开源模型。
下一步,值得期待!
相关链接
GitHub: https://github.com/rednote-hilab/dots.llm1
[2]Hugging Face: https://huggingface.co/rednote-hilab
[3]技术报告: https://github.com/rednote-hilab/dots.llm1/blob/main/dots1_tech_report.pdf
(文:AGI Hunt)