

0x00 前言
本文介绍vLLM中Triton Merge Attention States Kernel的实现,与 pytorch原生实现相比,该Triton kernel最高可实现 3-5 倍以上的算子加速。本文内容原为DefTruth:[vLLM实践][算子] vLLM算子开发流程: “保姆级”详细记录(
https://zhuanlan.zhihu.com/p/1892966682634473987)的一部分,现在单独摘出来继续展开写,作为本文Triton编程基础/进阶系列笔记的一部分,面向CUDA或Triton入门选手,目标是大家跟着Triton编程基础这个系列看完后,能掌握常见kernel编写,高阶用户请忽略。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的
LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计4k+ stars,传送门:https://github.com/xlite-dev/LeetCUDA

本人Triton相关笔记列表如下:
-
DefTruth:[Triton编程][基础] Triton极简入门: Triton Vector Add(https://zhuanlan.zhihu.com/p/1902778199261291694)
-
DefTruth:[Triton编程][基础] Triton Fused Softmax Kernel详解: 从Python到PTX(https://zhuanlan.zhihu.com/p/1899562146477609112)
-
DefTruth:[Triton编程][基础] vLLM Triton Merge Attention States Kernel详解(https://zhuanlan.zhihu.com/p/1904937907703243110)
-
DefTruth:[Triton编程][进阶] vLLM Triton Prefix Prefill Kernel图解(https://zhuanlan.zhihu.com/p/695799736)
本文内容包括以下部分:
-
0x00 前言
-
0x01 Merge Attention States 简介
-
0x02 PyTorch实现
-
0x03 Triton 基础算子
-
0x04 Triton 算子分析
-
0x05 NCU Profile分析
-
0x06 性能评估
-
0x07 总结
0x01 Merge Attention States 简介
本小节简单介绍一下Merge Attention States的概念。Merge Attention States在FlashInfer: https://www.arxiv.org/pdf/2501.01005的论文中2.2 Attention Composition小节中出现,然后在vLLM的Triton MLA实现中也被使用到。
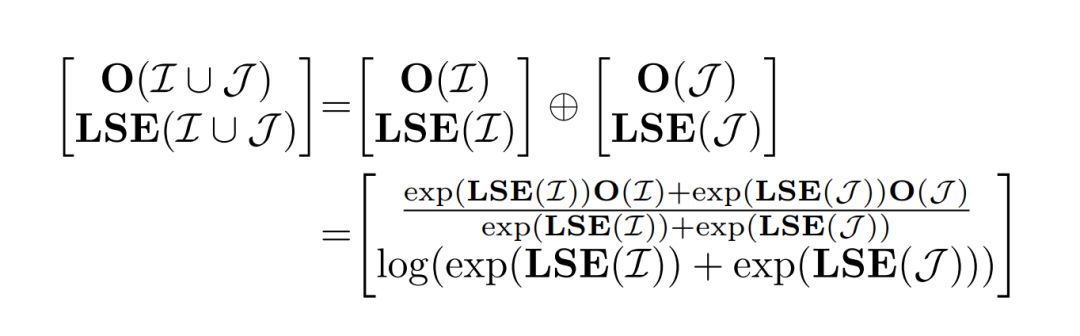
我们知道,Attention的计算是可以分块的。Block-Parallel Transformer (BPT)表明,对于相同的query以及不同的key/value,Attention Output(O)可以通过同时保留每个块的O及其缩放比例LSE来进行组合。其实就是,在decode阶段,我们们通常面临的是query很小,比如1,但是key和value很长,seqlen长度。因此,对于长序列,可以考虑对key/value先分块,每个块各自计算自己的Attention结果,记录块对应的LSE,最后通过缩放比例来合并。这就是所谓的”Merge Attention States“。这种用法,在Chunked-Prefill、Prefix-Cache和Split-KV的场景都会有意义。设 q 为一个query, 为一个索引集(也就是tokens)。LSE,log-exp-sum可以定义为:
为一个索引集(也就是tokens)。LSE,log-exp-sum可以定义为:
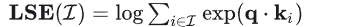
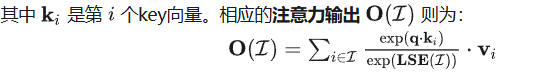

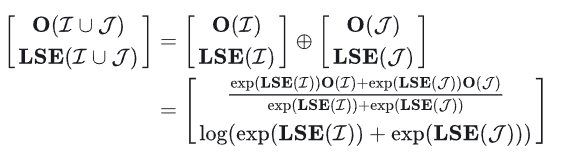
其实,Merge Attention States要做的事情很简单,就是对两个分块的Attention进行最终的校准。
0x02 PyTorch实现
首先,来简单写一个PyTorch版本的,方便后边和CUDA、Triton算子对数值精度。
# Naive PyTorch Implements section 2.2 of https://www.arxiv.org/pdf/2501.01005# can be used to combine partial attention results (in the split-KV case)def merge_attn_states_torch(output: torch.Tensor, # [NUM_TOKENS, NUM_HEADS, HEAD_SIZE]prefix_output: torch.Tensor, # [NUM_TOKENS, NUM_HEADS, HEAD_SIZE]prefix_lse: torch.Tensor, # [NUM_HEADS, NUM_TOKENS]suffix_output: torch.Tensor, # [NUM_TOKENS, NUM_HEADS, HEAD_SIZE]suffix_lse: torch.Tensor, # [NUM_HEADS, NUM_TOKENS]output_lse: Optional[torch.Tensor] = None, # [NUM_HEADS, NUM_TOKENS]):p_lse = prefix_lses_lse = suffix_lse# inf -> -inf 这里是为了避免inf值导致output为NAN, exp(inf)=nan, exp(-inf)=0p_lse[p_lse == torch.inf] = -torch.infs_lse[s_lse == torch.inf] = -torch.inf# max_lse [NUM_HEADS, NUM_TOKENS]max_lse = torch.maximum(p_lse, s_lse)# 减去最大值,safe softmax常规操作p_lse = p_lse - max_lses_lse = s_lse - max_lsep_lse_exp = torch.exp(p_lse)s_lse_exp = torch.exp(s_lse)out_se = (p_lse_exp + s_lse_exp)if output_lse is not None:output_lse = torch.log(out_se) + max_lse# 计算各自的scale值p_scale = p_lse_exp / out_se # [NUM_HEADS, NUM_TOKENS]s_scale = s_lse_exp / out_se # [NUM_HEADS, NUM_TOKENS]p_scale = torch.transpose(p_scale, 0,1).unsqueeze(2) # [NUM_TOKENS, NUM_HEADS, 1]s_scale = torch.transpose(s_scale, 0,1).unsqueeze(2) # [NUM_TOKENS, NUM_HEADS, 1]# 对结果校准得到最终Attention输出output = prefix_output * p_scale + suffix_output * s_scalereturn output, output_lse
不过需要注意的是prefix_output和prefix_lse的dim 0是不一致的,两者分别是[NUM_TOKENS, NUM_HEADS, HEAD_SIZE]以及[NUM_HEADS, NUM_TOKENS],这里是为了符合vLLM中chunk attention计算输出的张量shape的一个写法,其他框架,比如SGLang,则可能不是这样,比如我在SGLang中提的这个PR中的实现:https://github.com/sgl-project/sglang/pull/5428
0x03 Triton 基础算子
PyTorch实现的版本,当然性能是很低的,因为使用了很多的小op,以及对于Tensor进行了inplace的写操作。因此,vLLM中并不是直接使用PyTorch的实现,而是提供了一个基于Triton实现的kernel。完整代码链接:https://github.com/vllm-project/vllm/blob/main/vllm/attention/ops/triton_merge_attn_states.py。具体如下:
-
数据load及inf处理

-
safe-softmax:减去最大值
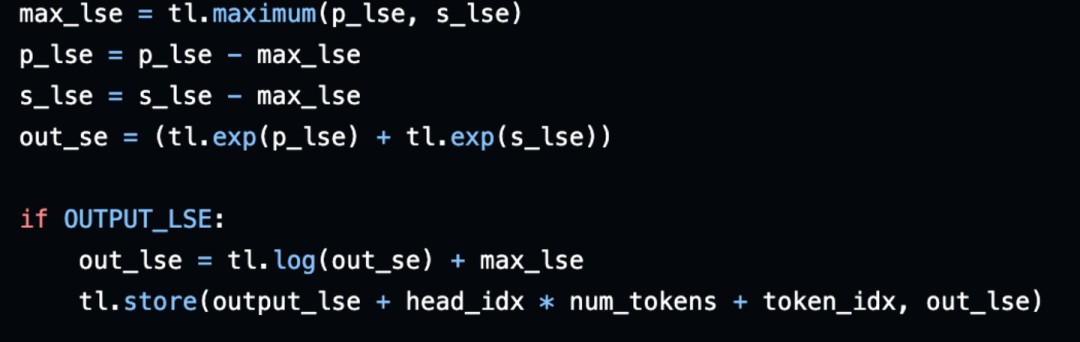
-
最后校准:计算prefix_output和suffix_output各自的scale值,然后求两者的加权和作为最后的输出。
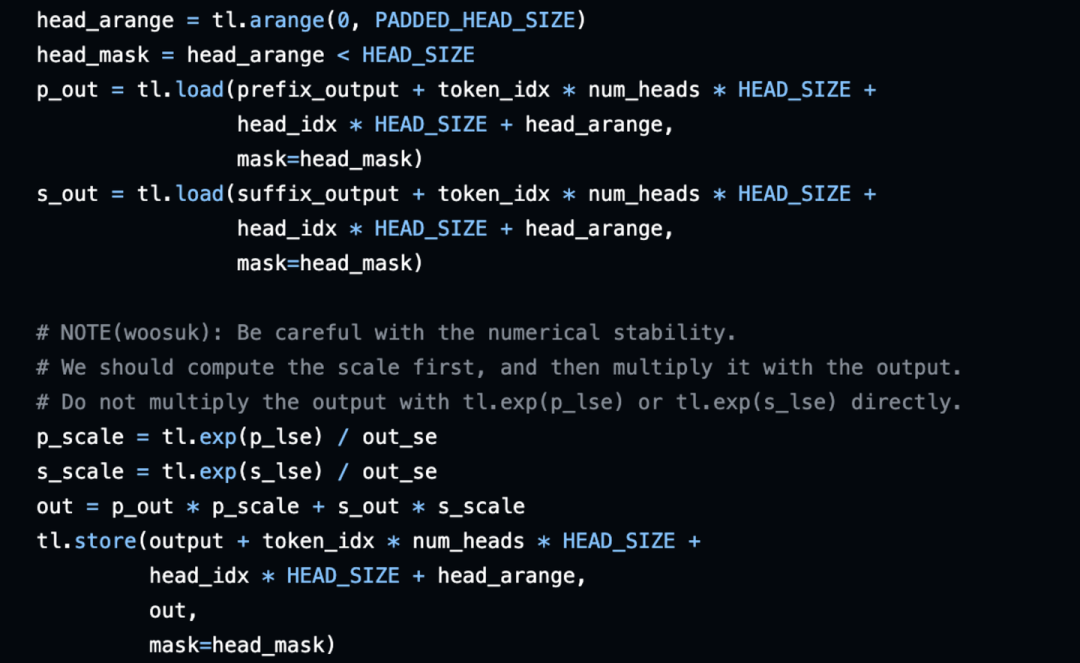
我们看到Triton kernel做的事情和PyTorch实现的一样的,但是将所有的操作都fused到一个kernel中,online判断inf值(寄存器)而不是修改global memory中的值,性能一般来说会更高。这个kernel的调用逻辑如下:
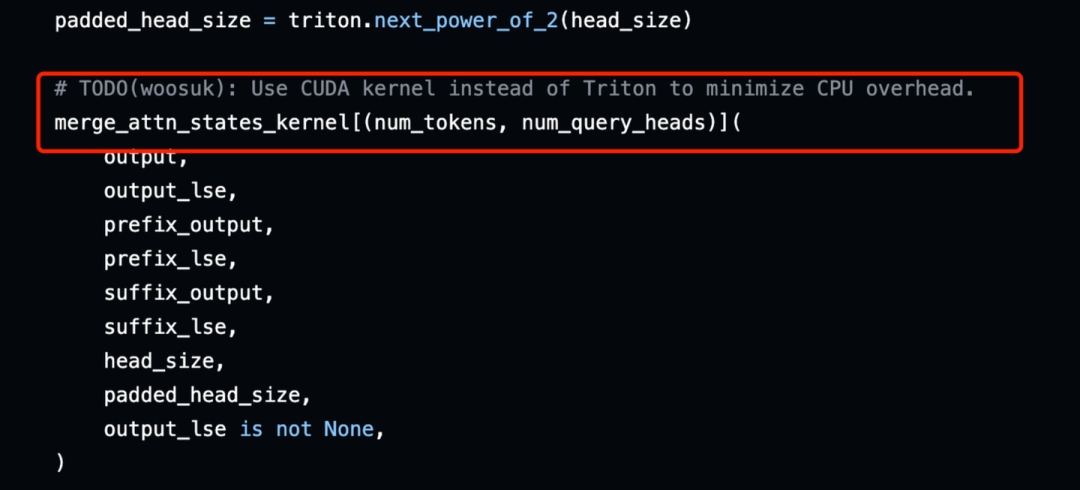
vLLM里边的实现,给merge_attn_states_kernel,分配(num_tokens, num_query_heads)个thread block,每个block处理当前head的所有值,比如head_size=128,则这个block处理128个值。
0x04 Triton 算子分析
-
基本分析
上小节我们知道,vLLM里边的实现,给merge_attn_states_kernel,分配(num_tokens, num_query_heads)个thread block,每个block处理当前head的所有值,比如head_size=128,则这个block处理128个值。但是,这样做,会出现一些问题。(1)当num_tokens、num_query_heads很大,而head_size很小(比如32)时,就会导致thread block数过大,每个block处理的数据量又过少,计算密度很小。而且,这种情况下,Triton也不一定能生成高效的kernel(下文会讲到);(2)Triton kernel在调用时会有一定CPU的overhead。

-
Gen code(PTX)分析
这里记录一下一个简单有效的分析Triton kernel的方法(当然ncu,nsys用上就更好了)。通常,我们也想知道,到底Triton实际上生成了啥kernel,比如说,生成的kernel PTX是怎么样的,有没有用上向量化,有没有cp.async,合并访存到底做好了没有。这个时候,我们可以指定TRITON_CACHE_DIR环境变量,把Triton生成的中间IR文件给保存下来,进行分析。
export TRITON_CACHE_DIR=$(pwd)/cachepytest -s test_merge_attn_states.py# Triton生成的中间IR cache文件cache git:(dev) ✗ tree ..├── ALGAAi8N-ErdaDbXXL8N91RokvTI-e8O2oEwd0SL3N0│ └── __triton_launcher.so├── p4IOvvpWkyeVkuyW8j50rO-ANYlCc5AJOEr70sQD93A│ ├── __grp__merge_attn_states_kernel.json│ ├── merge_attn_states_kernel.cubin│ ├── merge_attn_states_kernel.json│ ├── merge_attn_states_kernel.llir│ ├── merge_attn_states_kernel.ptx│ ├── merge_attn_states_kernel.ttgir│ └── merge_attn_states_kernel.ttir└── q4oIpkjOtdHHfi8xBkm4jC4JWIk5AjKtN8WRkZb8MD8└── cuda_utils.so
这里边,我们主要关注merge_attn_states_kernel.ptx这个PTX文件就可以了。比如,对于当num_tokens=512和num_query_heads=16,head_size=32,生成的PTX部分如下:
@%p8 ld.global.b16 { %rs3 }, [ %rd16 + 0 ]; // 非向量化load// ......@%p8 ld.global.b16 { %rs4 }, [ %rd17 + 0 ];// end inline asm.loc 1 85 30 // triton_merge_attn_states.py:85:30div.full.f32 %r15, %r16, %r17;// ......mov.b32 %f49, %r15;.loc 1 86 30 // triton_merge_attn_states.py:86:30// ......mov.b32 %r23, %f54;// begin inline asmcvt.rn.bf16.f32 %rs6, %r23;// end inline asmand.b32 %r30, %r25, 96;setp.eq.s32 %p10, %r30, 0;// begin inline asm@%p10 st.global.b16 [ %rd18 + 0 ], { %rs6 }; // 非向量化store
我们能看到,这种情况下,Triton并没有生成高效的向量化ld/st指令,而是使用ld.global.b16和st.global.b16。因此,如果我们自定义CUDA Kernel,并且手工确保合并访存的话,应该会有一定的性能收益。CUDA算子优化,可以看我的另一篇文章:
https://zhuanlan.zhihu.com/p/1892966682634473987
0x05 NCU Profile分析
最后,我们可以再用ncu抓一下实际跑的PTX和SASS到底是啥。Triton kernel通过ncu抓出来的长这样,这个case用的是ld/st.global.b16(num_tokens=512, num_heads=16, head_size=128),我实验了多次,有些情况下,成功生成了向量化的代码,有些情况又没有生成。因此,这个Triton Kernel还可以进一步通过手写CUDA算子进行访存优化,见:DefTruth:[vLLM实践][算子] vLLM算子开发流程: “保姆级”详细记录(
https://zhuanlan.zhihu.com/p/1892966682634473987)
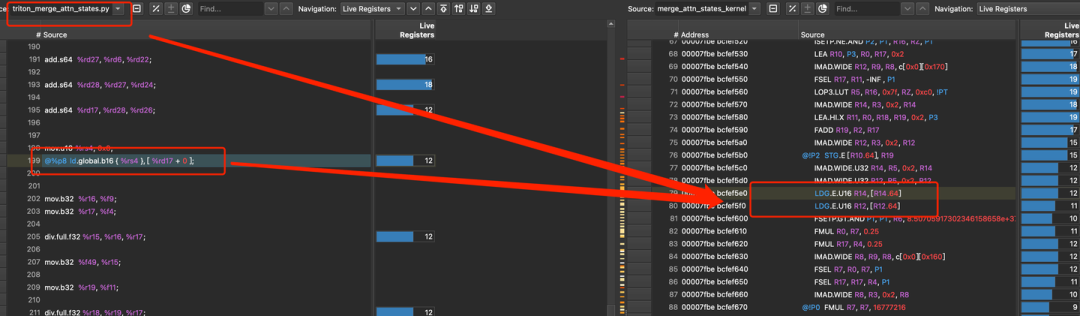
对比一下memory throughput: 45.67(Triton kernel) -> 60.57 (CUDA kernel)

-
ncu profile(然后用NCU客户端打开profile文件即可)
ncu -o merge_attn_states.prof -f pytest -s test_merge_attn_states.py0x06 性能评估
跑完单测后,会自动生成一个包含性能对比的markdown表格。使用Triton Kernel,可以大量减少访存开销从而提升kernel性能。与 pytorch原生实现相比,Triton kernel最高可实现 3-5 倍以上的算子加速。
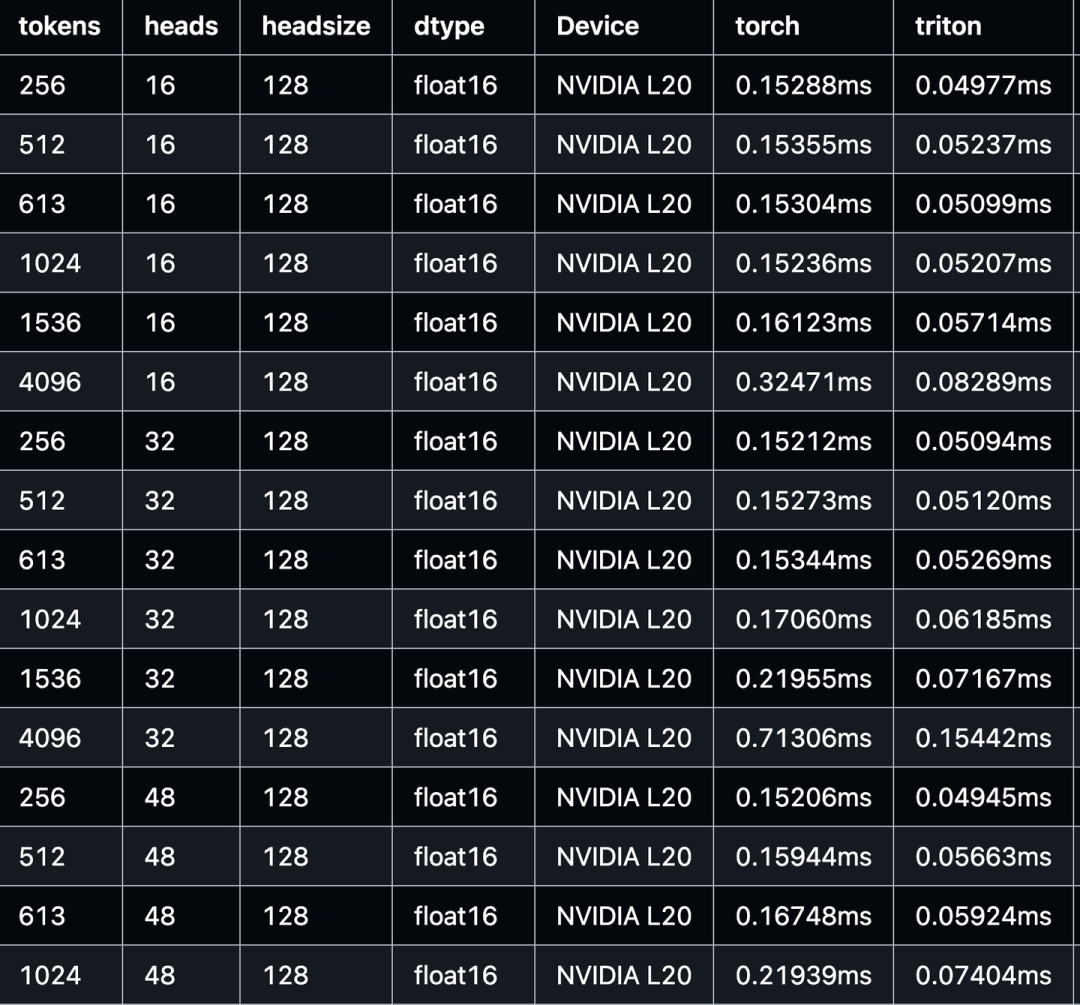
0x07 总结
本文介绍了vLLM中merge_attn_states triton算子的实现,内容包括:Merge Attention States 简介、PyTorch实现、Triton 基础算子、Triton 算子分析、NCU 分析、性能评估。最终,与 pytorch原生实现相比,Triton kernel最高可实现 3-5 倍以上的算子加速。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(
https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的
LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计 4k+ stars,传送门:
https://github.com/xlite-dev/LeetCUDA
这个kernel目前也单独摘了出来放在我的学习笔记中,方便大家尝试:
https://github.com/xlite-dev/LeetCUDA/tree/main/kernels/openai-triton/merge-attn-states
老样子,错误先更后改……
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)