
今天是2025年6月13日,星期五,北京,晴
我们先来看三种embedding编码范式,包括Bi-encoders、Cross-encoder、ColBERT三种,比较直观的可视化。
另外,还是再看一个知识图谱结合RAG的思路,其实套路还是之前的,核心还是怎么选择最相关的三元组,然后讲一些故事,例如,跟query扩展做结合?
一、先看三种embedding编码范式
目前有一些典型的embedding编码范式,包括Bi-encoders、Cross-encoder、ColBERT三种。
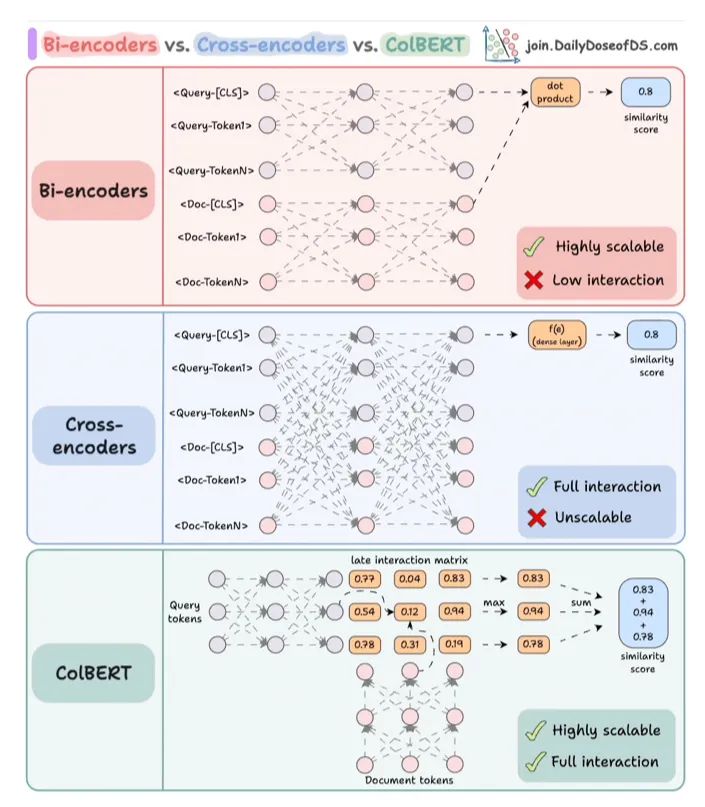
对于Bi-encoders,分别编码查询和文档。计算查询的[CLS]标记与文档之间的余弦相似度。这具有高度可扩展性,因为文档嵌入可以离线计算。但这种方式,失去了所有的交互,只是希望”关于查询和文档的全部信息都能很好地总结在【CLS)标记中。
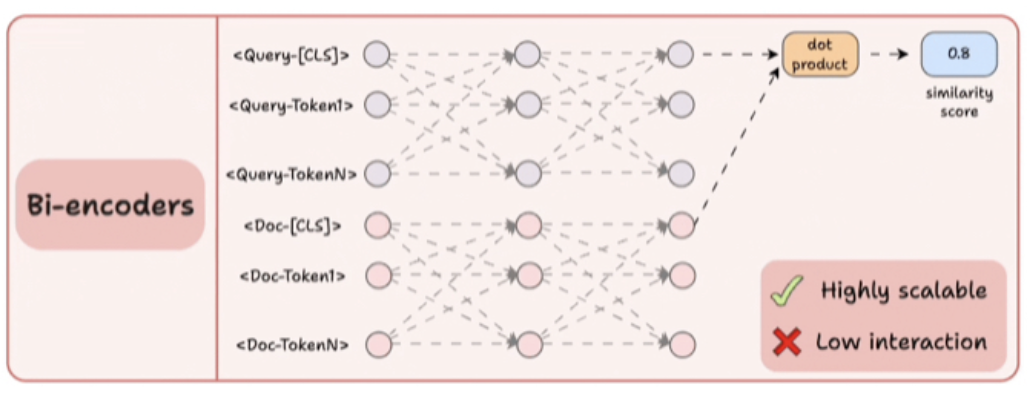
对于Cross-encoder,将查询文本和文档文本连接起来,使用类似BERT的编码器模型进行编码。对[CLS]标记表示应用一个转换(密集层)以获得相似性分数。由于模型同时关注两个上下文,这产生了极其语义表达力的表示。但它无法扩展,因为如果拥有10亿份文档,就必须执行10亿次前向传递,以确定与查询最相关的文档。
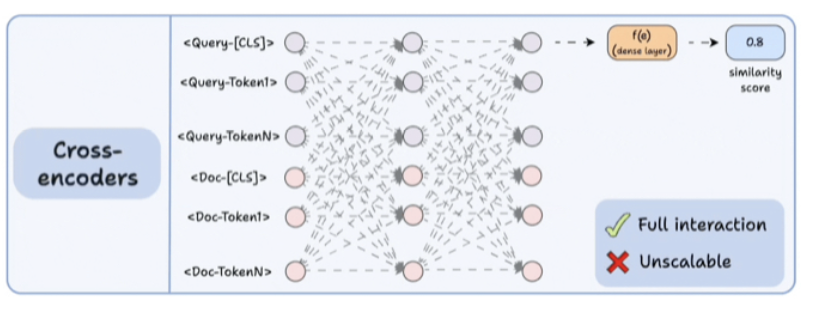
对于ColBERT,分别对查询和文档进行编码,计算一个延迟交互矩阵,该矩阵包含所有查询词与所有文档词之间的相似度得分(点积)。对于每个标记,确定所有文档标记的最大分数。将这些最大分数相加以获得匹配分数。
二、知识图谱与RAG结合思路KG-Infused RAG
继续看知识图谱与RAG结合进展,来看看最近的工作《KG-Infused RAG: Augmenting Corpus-Based RAG with External Knowledge Graphs》(https://arxiv.org/pdf/2506.09542),主要目的是解决如何有效地从多个知识源(如文本和结构化知识)中整合证据,以及如何实现基于语义关联的检索和生成。
先看下和之前RAG方案的一些对比:
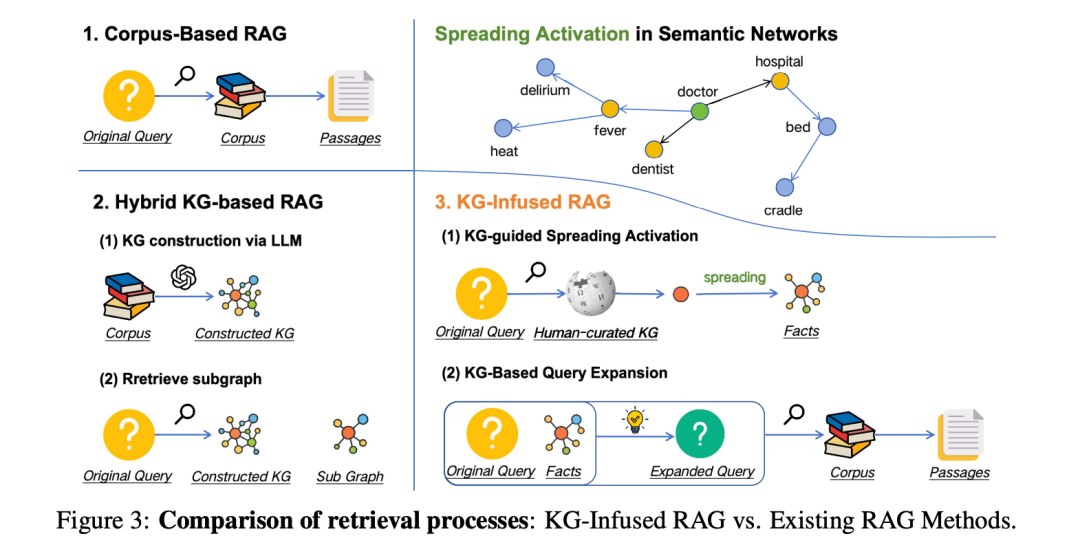
看下具体的实现思路:
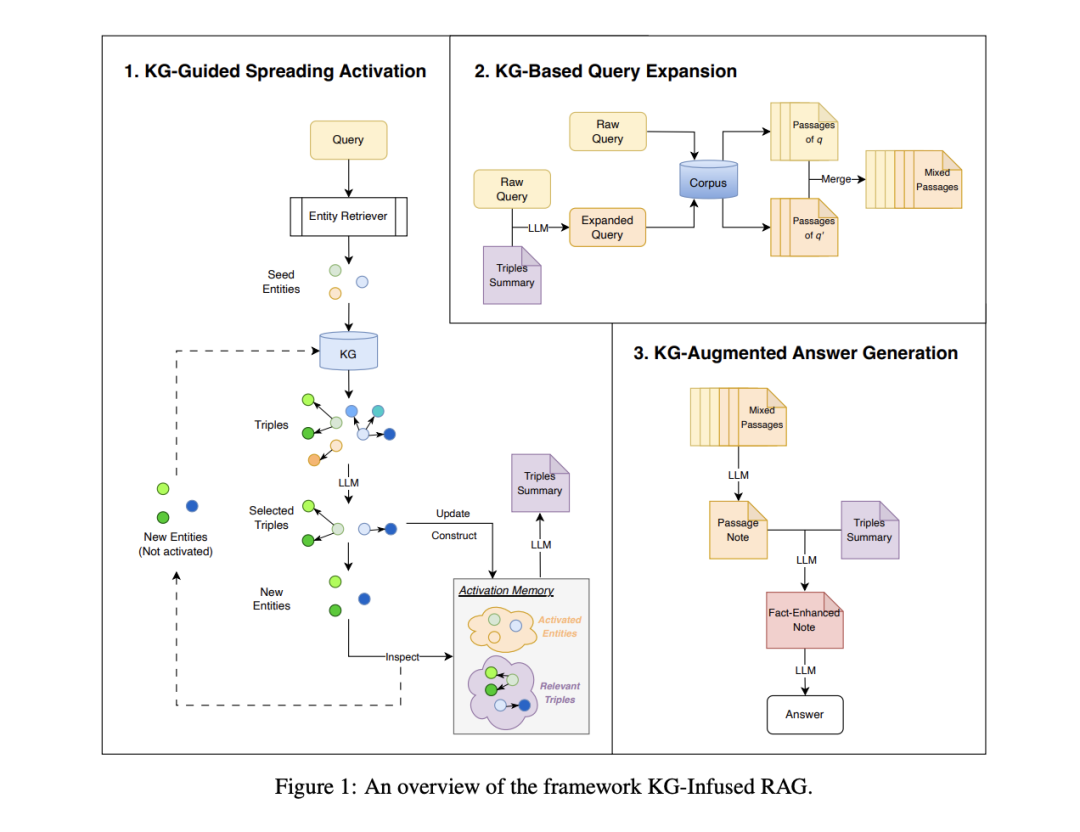
分成几个阶段:
1、KG-Guided Spreading Activation
目标是从查询相关的实体开始,通过迭代扩展语义相关的三元组来构建任务特定的子图Gq,给定一个问题和一个检索到的实体三元组集合,只选择与问题相关的三元组。当然,前提是有一个图谱,这里用的是Wikidata5M-KG。
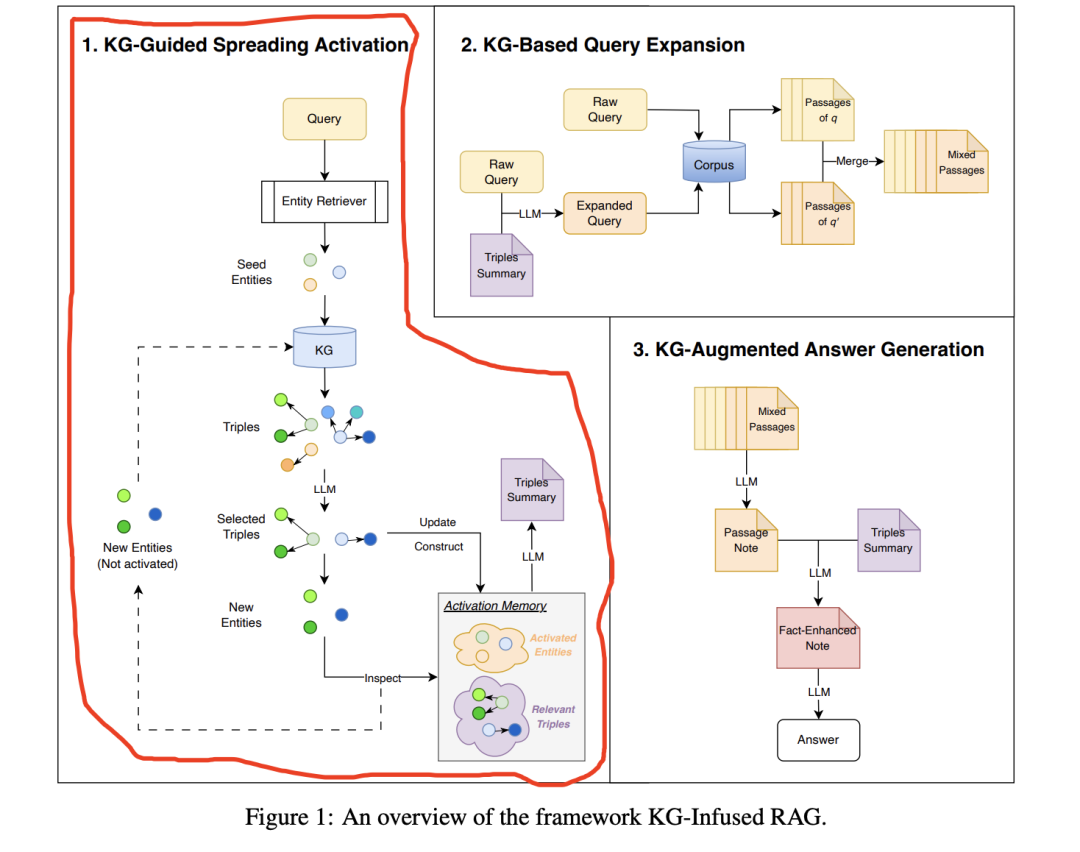
具体步骤如下:
种子实体初始化:从知识图谱中检索与查询最相关的实体,并选择描述相似度最高的实体作为初始种子实体,因为要做相似度,所以会有一些条件,每个实体e必须有一个文本描述d,该描述可以被向量化以便与查询进行相似性计算。
迭代扩散激活:从种子实体开始,通过迭代方式扩展语义相关的三元组,逐步构建任务特定的子图Gq。
每个迭代轮次包括:
1)三元组选择:从当前激活实体中选择与其相关的三元组。这里的激活并不高大上,就是提示prompt让大模型进行挑选。

2)激活记忆更新:维护一个激活记忆M,记录多轮激活过程中检索到的所有查询相关三元组。这里可以理解就是一个redis。
3)下一轮激活实体:从当前三元组的尾部实体中选择新的激活实体,排除已经在激活记忆中的实体,确保每次迭代只引入新的实体。这个也是一些废话,因为去重是一定的。

子图总结:使用大模型对扩展后的KG子图进行总结,生成自然语言摘要以便在后续阶段中使用。
这里同样也是提示大模型去做:

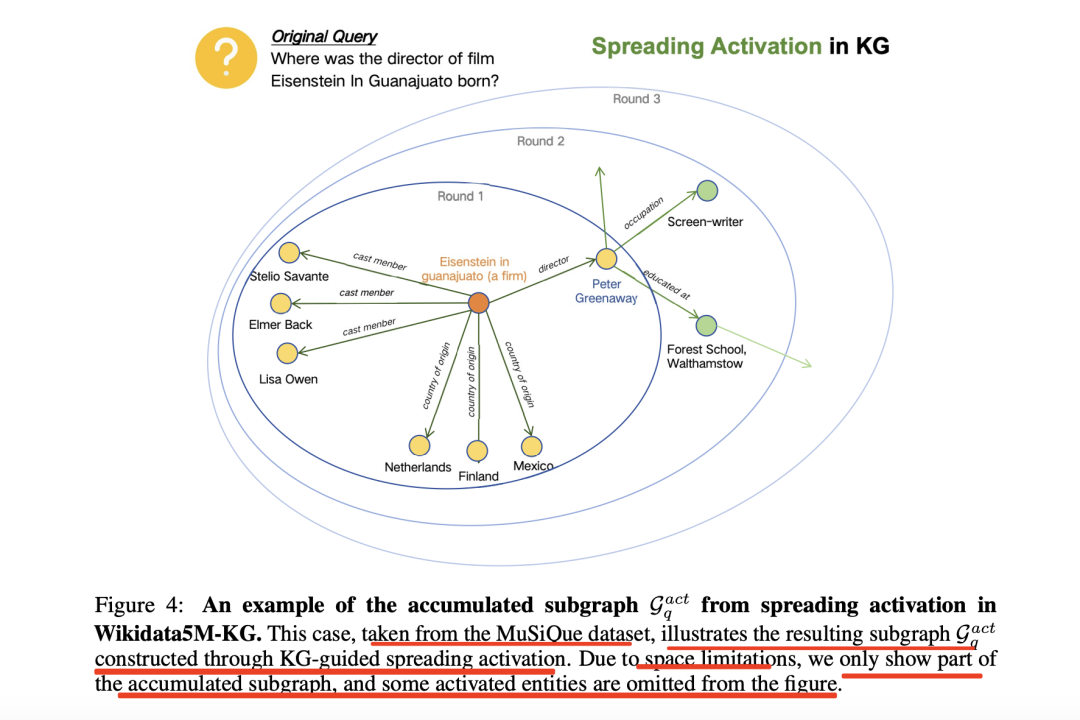
一个具体的效果,如下图所示:
2、KG-Based Query Expansion (KG-Based QE)
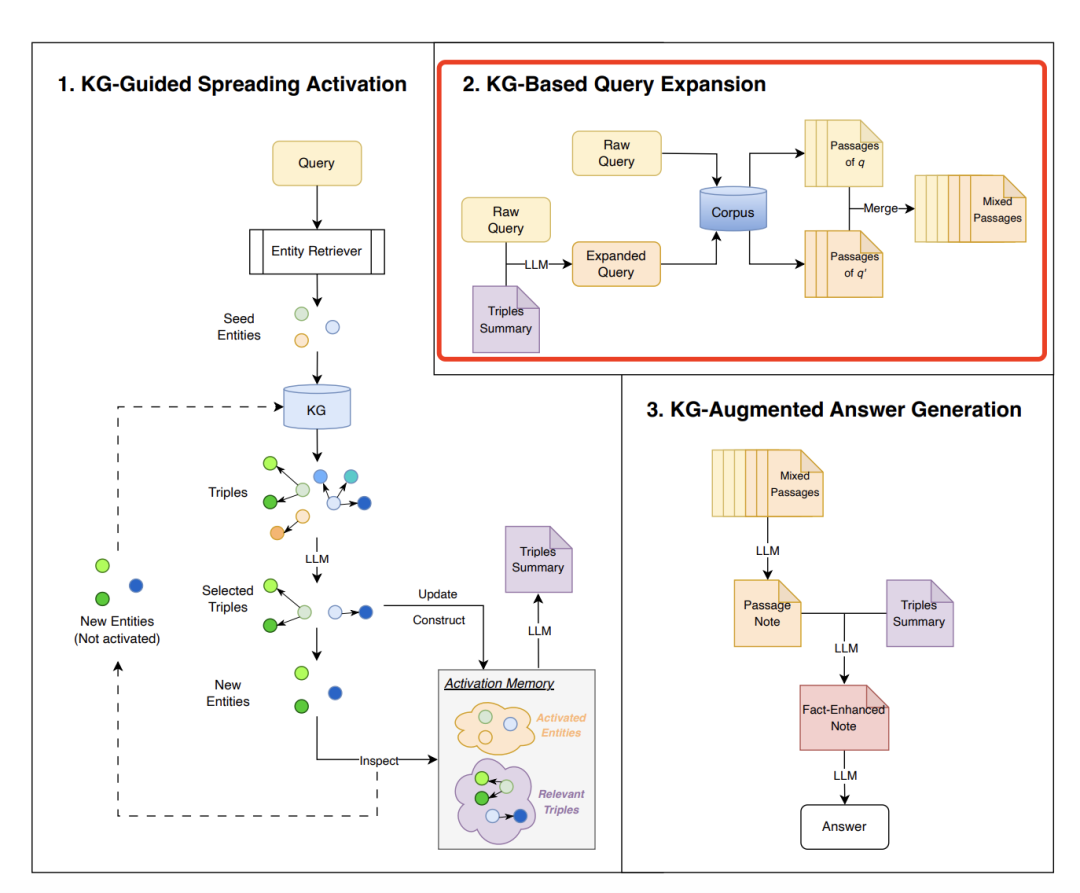
目标是利用原始查询和扩展的KG子图生成扩展查询q′,以提高对语料库Dc的检索效果。主要实现步骤分三步:
提示LLM:将原始查询q和KG子图摘要SG,qact一起输入到LLM中,生成扩展查询q‘。
双查询检索:使用原始查询q和扩展查询q′,分别对语料库进行检索,得到两个检索结果集合Dc,q和Dc,q′。
合并结果:将两个检索结果集合合并,得到最终的检索结果Dc,(q,q′)
3、KG-Augmented Answer Generation (KG-AugGen)
目标是通过整合检索到的段落和知识图谱摘要来生成答案,以实现答案的事实性和可解释性。
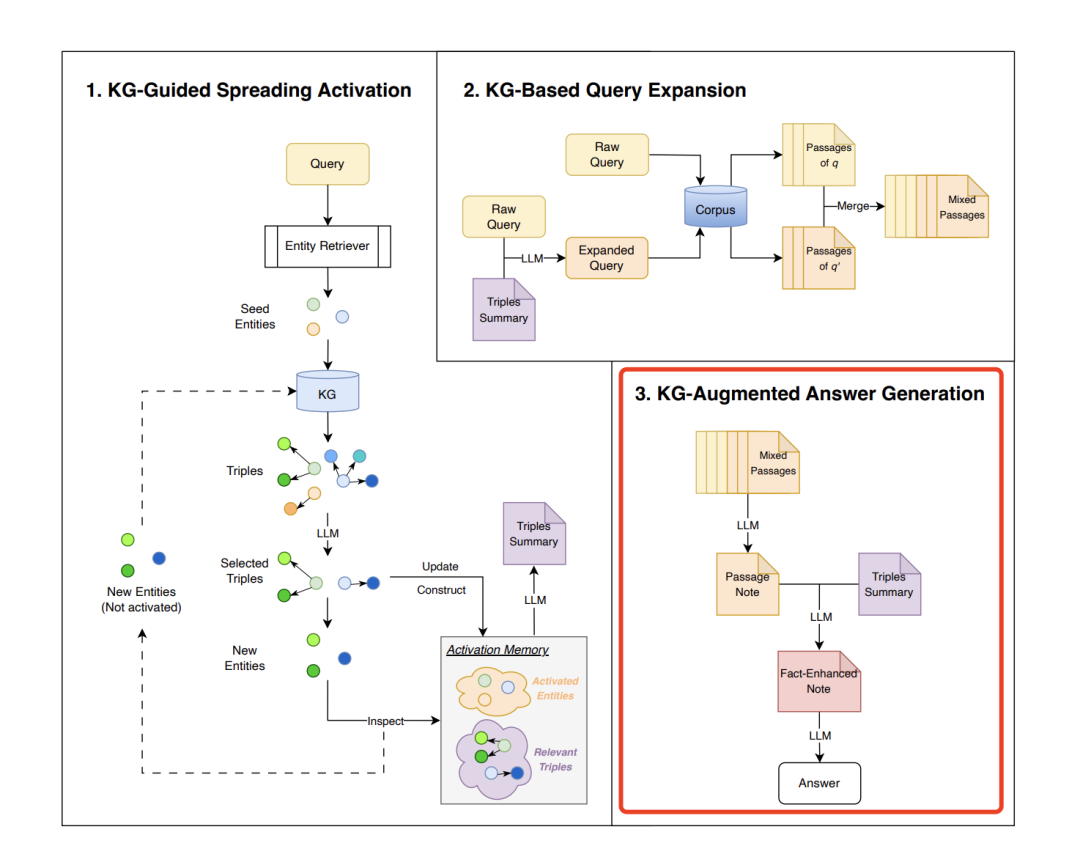
这个不用多说,直接写prompt送入llm做生成即可。
但是,为了进一步提升LLM对上述任务的指令遵循能力,所以还是搞了个DPO进行训练。
这个工作并没无太多新意,更像是传了个工程流程,讲了一个更好的故事,但大致思路可以借鉴。
参考文献
1、https://arxiv.org/pdf/2506.09542
(文:老刘说NLP)