
随着大模型的不断发展,多模态数据处理成为了新的热点领域。多模态生成任务主要通过整合多种类型的数据,如文本、图像、音频等,实现不同模态之间的相互转换与生成。
例如,将一段文字描述转换为生动的图像,或者把一段音频内容转化为对应的文本信息。但现有的多模态生成模型在处理复杂任务时,往往面临着诸多挑战。不同模态数据之间的差异巨大,如何有效地对齐和融合这些数据,成为了提高模型性能的关键难题。
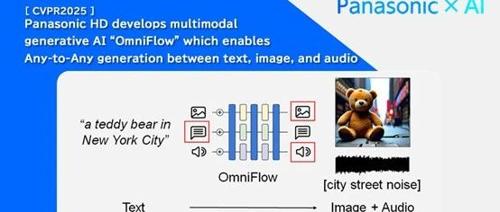
全球著名电器巨头松下开发了多模态大模型OmniFlow,能够高效处理包括文本到图像、文本到音频、音频到图像等多种模态之间的任意到任意生成任务。
OmniFlow 采用了模块化设计理念,允许模型的各个组件进行独立预训练。在实际应用中,不同的组件可以针对特定的模态或任务进行优化训练。文本处理模块可以在大规模文本数据集上进行预训练,以提升对语言的理解和生成能力;
图像生成模块则可以通过大量图像数据进行训练,增强图像生成的质量和准确性。这种独立预训练的方式大大提高了训练效率,避免了传统模型在整体训练时可能出现的资源浪费问题。
当各个组件完成预训练后,OmniFlow 能够将这些组件灵活地合并在一起,并进行微调。通过这种方式,模型可以根据具体的任务需求,快速组合出最适合的架构,实现高效的多模态生成。

不仅节省了大量的计算资源,还使得模型的扩展性和适应性得到了显著提升。在面对新的多模态生成任务时,只需要对相关组件进行适当调整和训练,就可以快速部署到新的场景中,无需重新构建整个模型。
多模态引导机制是 OmniFlow 的另一大技术亮点。该机制允许用户精确控制输入和输出模态之间的交互,从而增强了生成过程的可控性。在传统的多模态生成模型中,生成过程往往缺乏有效的引导,导致生成结果与用户期望存在偏差。而 OmniFlow 通过引入这一机制,使得用户能够根据具体需求,对生成过程进行细致的干预。
在文本到图像的生成任务中,用户可以通过设定特定的引导参数,如强调图像中的某个元素、调整图像的整体风格等,来控制生成图像的具体内容和特征。
在多模态输入处理与生成流程中,OmniFlow 首先会将多模态输入转换为潜在表示。对于文本输入,会通过自然语言处理技术将其转化为向量形式,提取其中的语义信息;对于图像输入,则利用卷积神经网络等技术对图像进行特征提取,得到图像的潜在特征表示;音频输入同样会经过相应的音频处理算法,转换为适合模型处理的潜在表示形式。
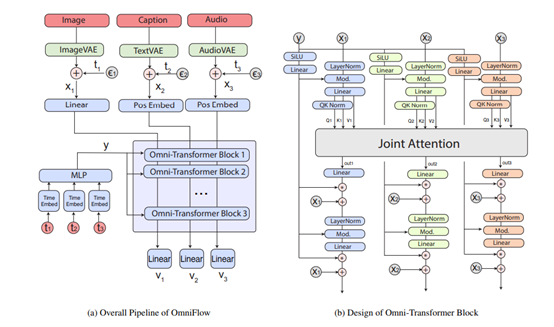
随后,这些潜在表示会通过时间嵌入编码和 Omni-Transformer 块进行进一步处理。时间嵌入编码能够将输入数据在时间维度上进行编码,捕捉数据中的时间序列信息,这对于处理音频等具有时间特性的数据尤为重要。
Omni-Transformer 块则是基于 Transformer 架构进行改进的模块,它能够有效地学习和整合来自不同模态的信息,通过多头注意力机制等技术,实现不同模态数据之间的交互与融合。
为了验证 OmniFlow的性能,研究团队进行了一系列全面而深入的实验。实验涵盖了多个不同类型的多模态生成任务。
在文本到图像生成任务的实验中,研究团队采用了多个公开的基准数据集,如MSCOCO-30K 和 GenEval 基准。实验结果显示,在 MSCOCO-30K 基准上,OmniFlow 生成的图像与输入文本的匹配度极高,通过 FID(Frechet Inception Distance)指标评估,其 FID 值相较于以往的模型有了显著降低。
在 GenEval 基准测试中,OmniFlow同样展现出了卓越的性能,生成图像的 CLIP 分数较高。CLIP分数反映了图像与文本之间的语义一致性,分数越高说明图像与输入文本在语义上的匹配程度越好。
在文本到音频生成任务的实验中,实验结果表明,OmniFlow 生成的音频在语音相似度方面表现出色,能够准确地将输入文本转换为与预期语音特征相符的音频内容。生成音频的质量评分也较高,音频清晰、流畅,没有明显的噪音或失真现象。
(文:AIGC开放社区)