



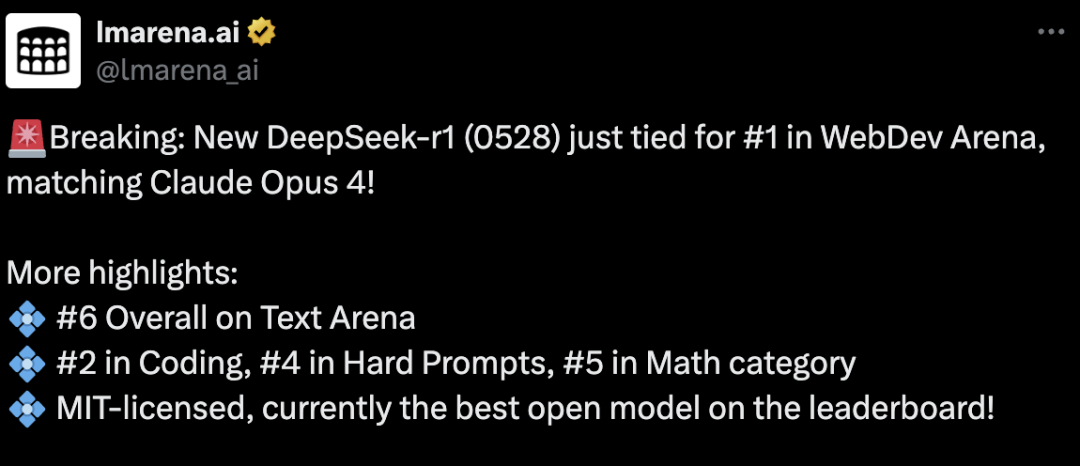
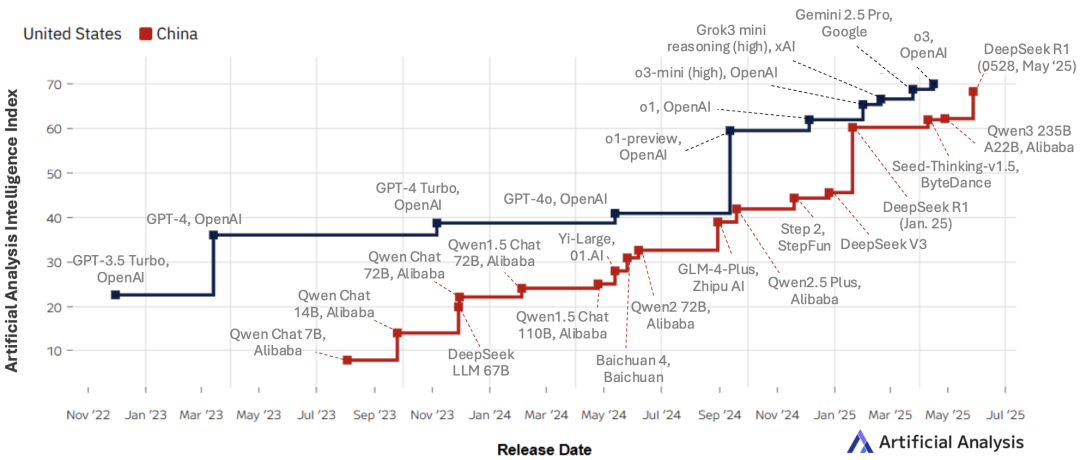
今天,根据基准测试开放平台lmarena.ai发布的最新消息,DeepSeek-R1-0528在WebDev Arena基准上与谷歌的Gemini-2.5-pro并驾齐驱,甚至略高于Anthropic的Claude Opus4,该基准专门用于比较AI模型在HTML、CSS和JavaScript等Web开发任务中的性能。
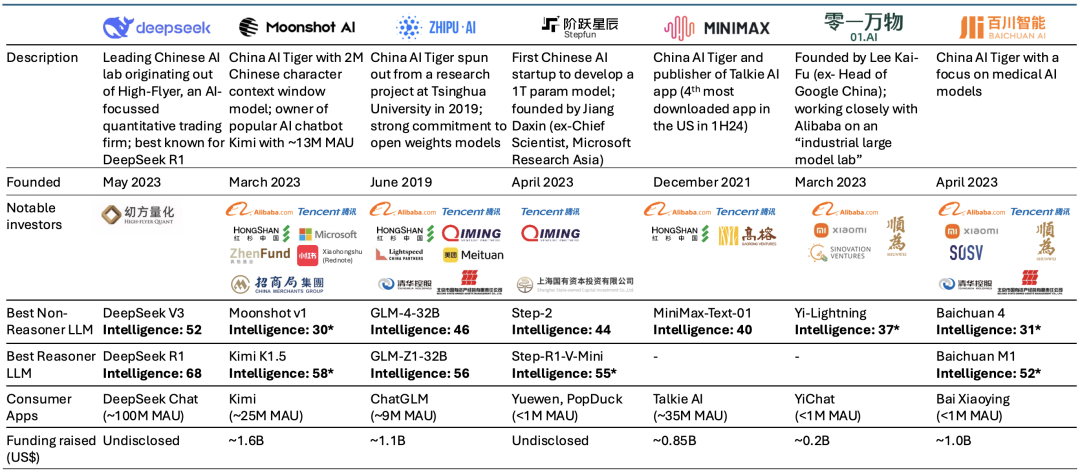
与此同时,国内“大模型六小虎”之中的月之暗面和MiniMax今天也先后发布了最新开源模型,竞逐之中展现出赶超DeepSeek之势。
不过从当前广泛的开发者认可度和影响力而言,DeepSeek和阿里Qwen系列模型仍是开源领域的佼佼者,留给“六小虎”的机会空间能有多少尚未可知。

月之暗面发布的新模型为Kimi-Dev-72B,是一款专门面向软件工程任务的开源编码大语言模型,官方给出的数据显示,其在SWE-bench Verified基准测试中刷新了开源模型的最先进(SOTA)成果。

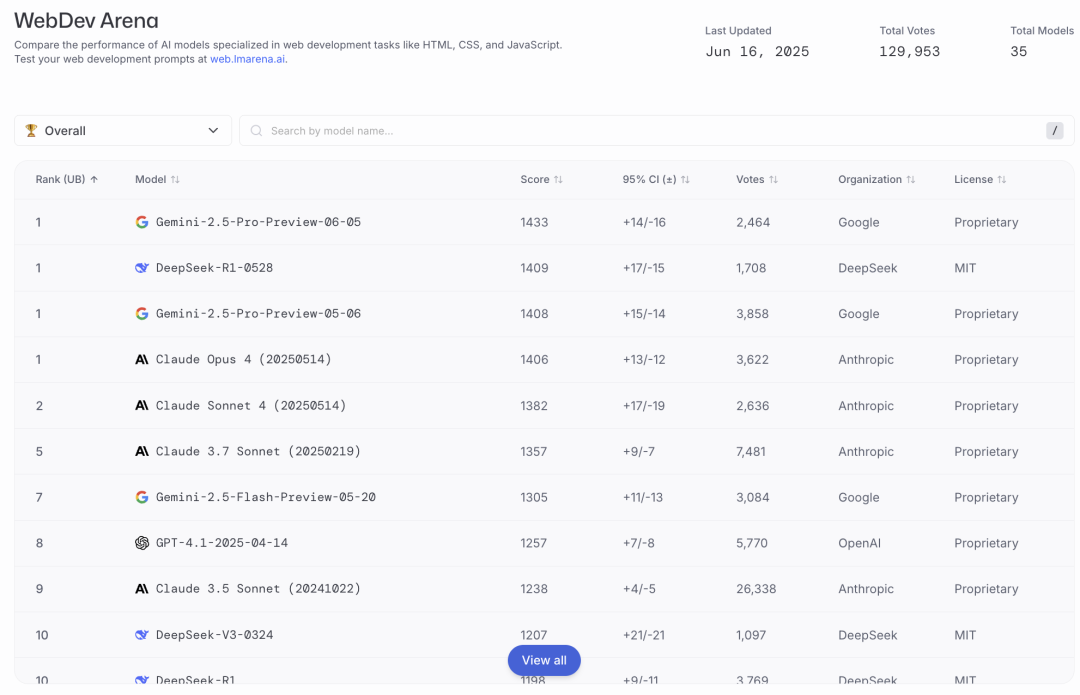
Kimi-Dev-72B在SWE-bench Verified基准测试中达到60.4%的性能表现,该模型通过大规模强化学习进行优化,可在Docker环境中自主修补真实代码仓库,仅当整个测试套件通过时才获得奖励,这一机制确保解决方案的正确性与鲁棒性,契合现实开发标准。
官方给出的性能指标显示超过了Qwen3-235B-A22B和DeepSeek-R1-0528,同时模型的参数仅有72B,比R1-0528的685B参数规模大大缩小。
月之暗面团队介绍了Kimi-Dev-72B的设计理念与技术细节,包括BugFixer(漏洞修复器)和TestWriter(测试生成器)双模块、中期训练、强化学习及测试时自博弈机制等。
Kimi-Dev-72B为双模块设计了相同的极简框架,仅包含两个阶段:(1)文件定位;(2)代码编辑,这种双模块设计构成了Kimi-Dev-72B的技术基石。
此外,使用约1500亿高质量真实数据进行中期训练。以Qwen 2.5-72B基础模型为起点,收集数百万GitHub问题与PR提交作为训练数据集,数据构建遵循严格规则,使模型学习开发者如何基于GitHub问题推理、编写修复代码及单元测试。
中期训练增强了基础模型在实际漏洞修复和单元测试方面的知识,为后续强化学习提供更优起点。
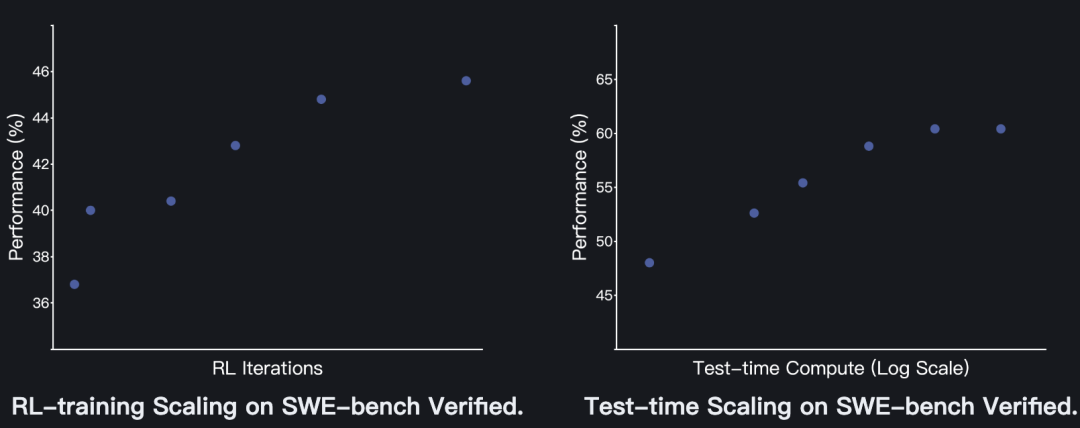
经过合理的中期训练与监督微调(SFT),Kimi-Dev-72B在文件定位任务中已表现出色,强化学习阶段则聚焦提升代码编辑能力。
针对SWE-bench Verified基准任务,月之暗面团队进行了3个关键设计:
1、仅基于结果的奖励机制:仅使用Docker最终执行结果(0或1)作为奖励,训练过程中不引入任何基于格式或流程的奖励。
2、高效提示集筛选:过滤掉模型在多样本评估中成功率为零的提示,以有效利用大批量训练;采用课程学习策略,逐步引入新提示以增加任务难度。
3、正例强化机制:在训练最后阶段,将前几轮迭代中的成功样本纳入当前批次,帮助模型强化成功模式并提升性能。
最终,Kimi-Dev-72B通过可扩展的问题解决任务训练获得显著提升。
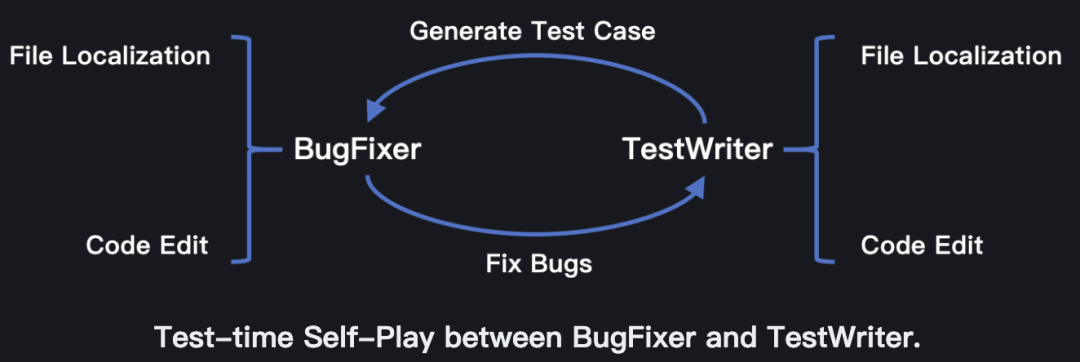
在完成强化学习训练后,Kimi-Dev-72B会同时掌握BugFixer和TestWriter的双重角色,在测试阶段,模型会采用自博弈机制来协同其漏洞修复与测试编写能力,测试时自博弈过程中,每个问题会生成最多40个补丁候选和最多40个测试候选。
月之暗面团队表示,目前正积极研发扩展Kimi-Dev-72B能力的方法,并探索更复杂的软件工程任务,未来迭代将聚焦于与主流集成开发环境(IDE)、版本控制系统及CI/CD流水线的深度整合。
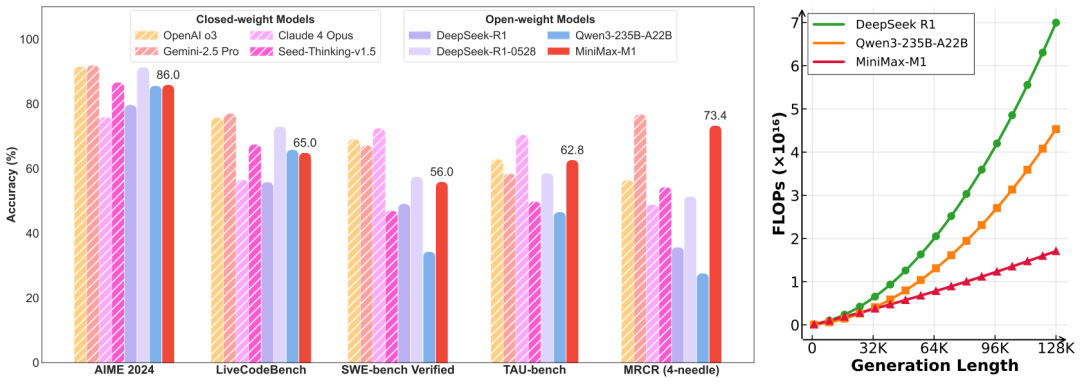
与Kimi-Dev-72B主攻AI编码不同,MiniMax发布的M1模型定位是全球首款开放权重的大规模混合注意力推理模型,在SWE-bench Verified基准上达到了56%的性能表现,成绩略低于Kimi-Dev-72B的60.4%。
官方评测显示,该模型性能与原始DeepSeek-R1和Qwen3-235B等领先开放权重模型相当或更优,尤其在复杂软件工程、工具利用和长上下文任务中表现突出,聚焦语言模型智能体方向。
MiniMax-M1采用混合专家混合(MoE)架构与闪电注意力机制相结合的设计,总参数量达4560亿,每个token激活459亿参数。
M1模型原生支持100万tokens的上下文长度,是DeepSeek R1上下文规模的8倍,也比目前所有开放权重的大型推理模型(LRMs)大一个数量级,这种特性使M1特别适合处理需要长输入和深度推理的复杂现实任务。

此外,在生成长度为64K tokens时,M1的浮点运算量(FLOPs)消耗不到DeepSeek R1的50%,在100K tokens长度下,仅消耗约25%的FLOPs,这种计算成本的大幅降低也使M1在推理和大规模强化学习(RL)训练中显现出更高效率。
除了闪电注意力机制之外,MiniMax团队还提出了一种新型RL算法:CISPO,以进一步提升RL效率,CISPO通过裁剪重要性采样权重而非token更新,性能优于其他竞争性RL变体。混合注意力与CISPO的结合,使MiniMax-M1在512块H800 GPU上完成全RL训练仅需三周,算力租赁成本仅53.47万美元。
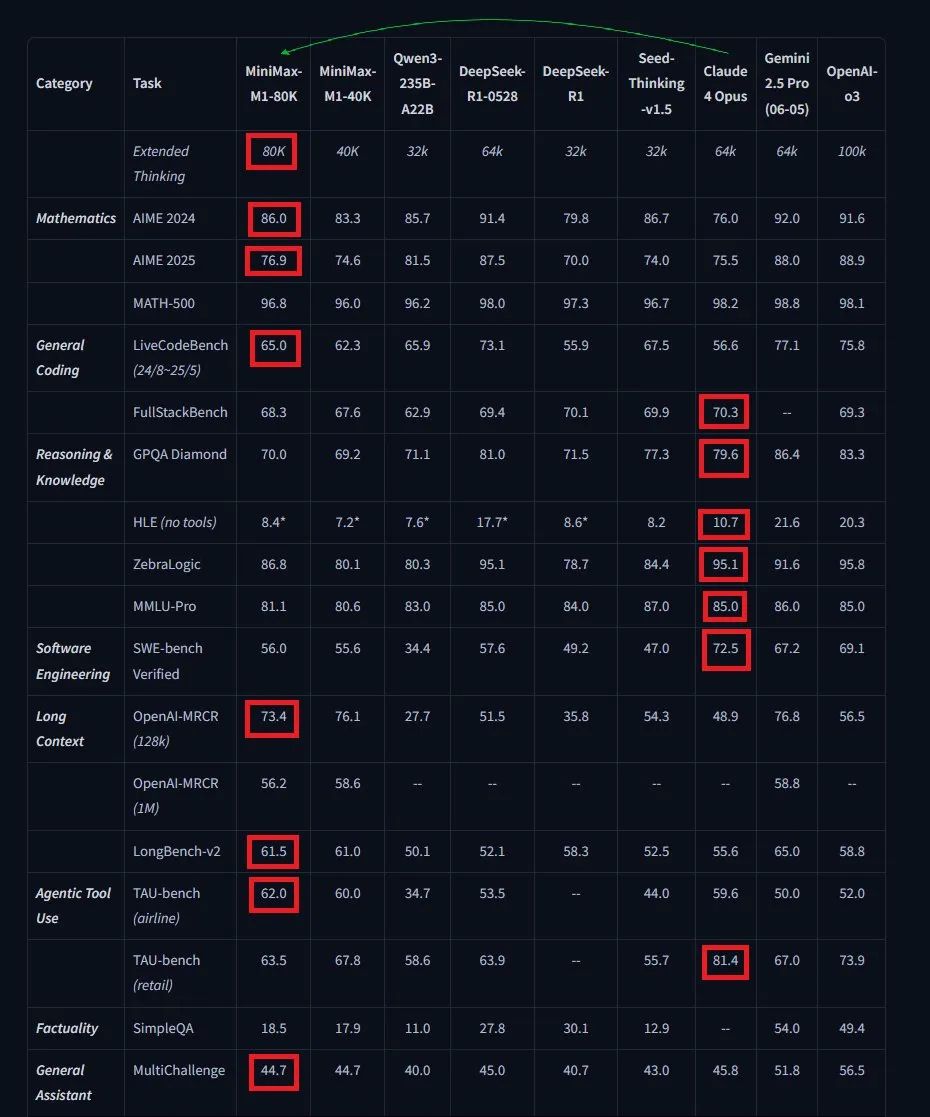
不过,与最新的DeepSeek-R1-0528模型相比,MiniMax-M1在数学和编码竞赛中仍有差距,但在更贴近现实的工具使用和长上下文场景中性能相当或更优,另外,MiniMax-M1在智能体工具使用基准TAU-Bench上也展现出了一些高于Gemini 2.5 Pro和R1-0528的性能,在长上下文理解基准中优于OpenAI o3和Claude 4 Opus。
开源模型“卷“起来让不少开发者喜出望外,实际PK起来孰强孰弱?
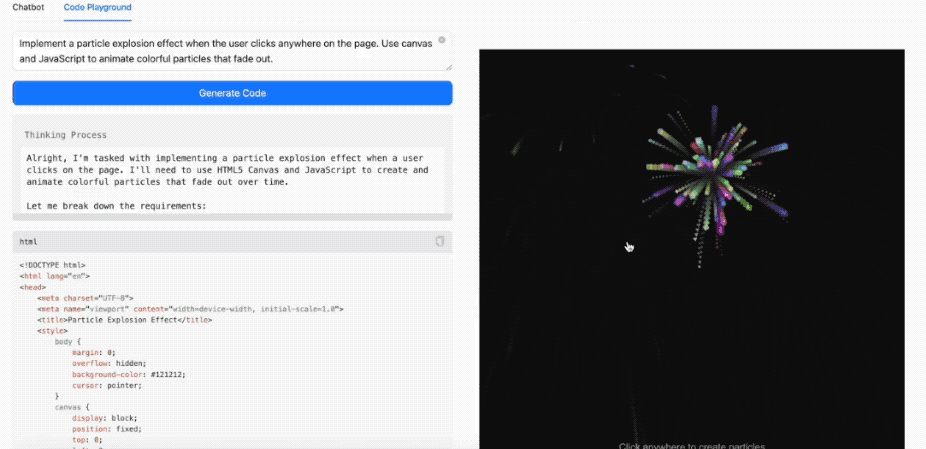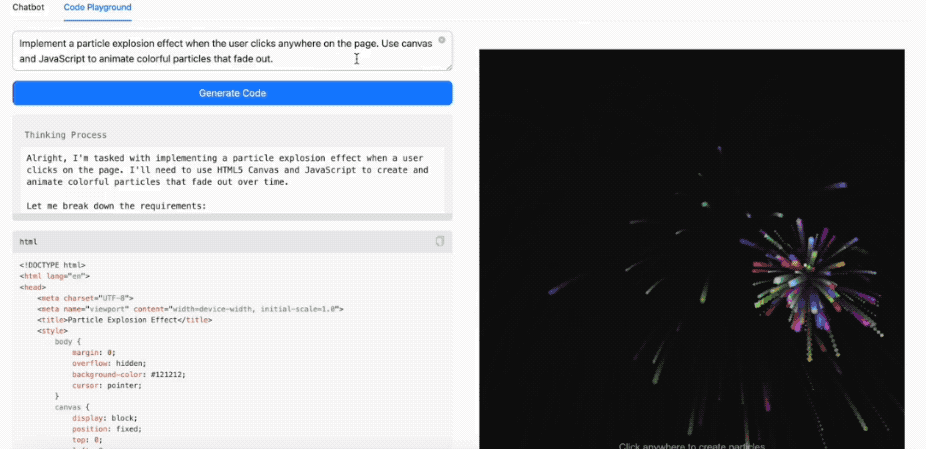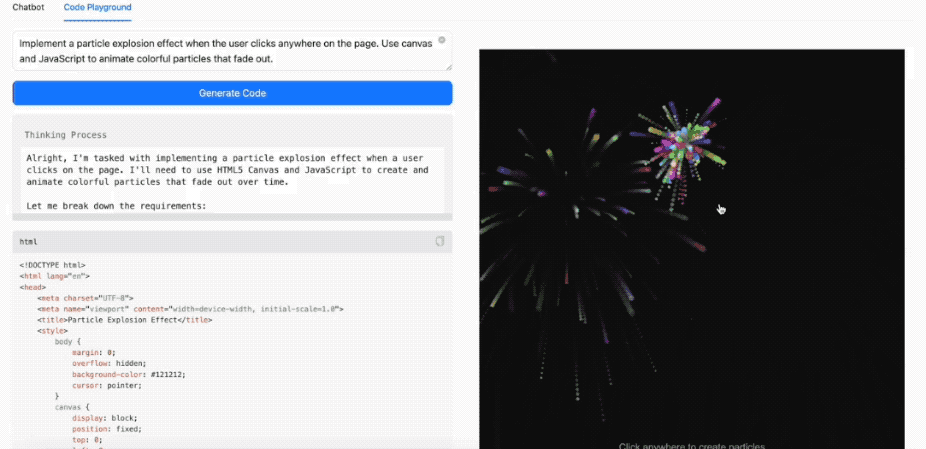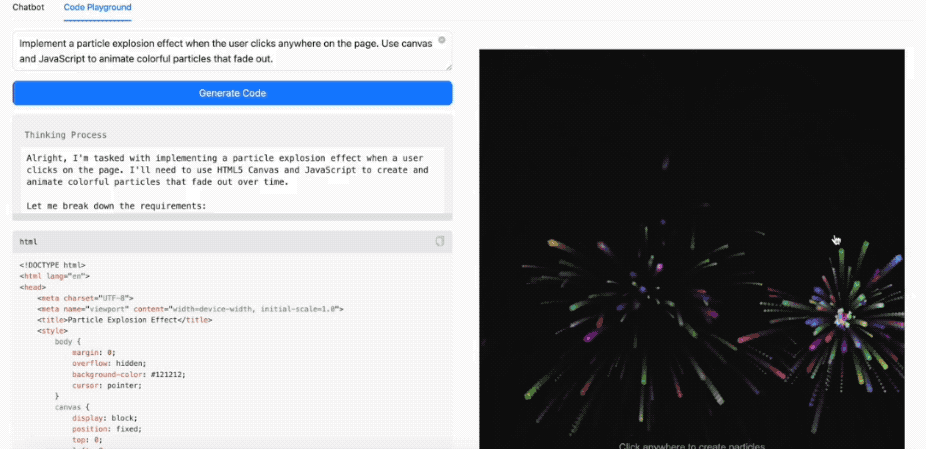
有开发者网友同时比较了MiniMax-M1-80K、Kimi-Dev-72B和DeepSeek-R1-0528写代码实测,如写一个拆烟囱的demo。

其中MiniMax-M1-80K在指令要求下一次性完成了任务,意味着它的代码训练材料足够新, 能把ES的引入一次性写对, 而且它在思考的时候反复了好几次,成功避免了可能出现的bug,不过生成的光影效果、前端页面样式等没有DeepSeek好看。



-END-

(文:头部科技)