

随着人工智能技术的快速发展,文档解析作为自然语言处理和计算机视觉领域的关键任务,正逐步从传统的规则引擎和启发式方法向深度学习模型演进。
文档解析的目标是将文档中的文本、表格、公式、图像等内容进行结构化识别和语义理解,从而实现信息的高效提取与处理。
然而,现有方法在准确性和效率之间往往难以取得平衡,尤其是在处理多语言、多格式、多模态的复杂文档时,面临诸多挑战。
为了解决这些问题,本文介绍了一种名为MonkeyOCR 的新型文档解析模型,其核心创新在于采用 Structure-Recognition-Relation (SRR) 三元组范式。该范式通过将文档解析任务分解为三个核心问题——“结构在哪里?”、“内容是什么?”、“它们如何组织?”——实现了对文档内容的高效、精准解析。
与传统的流水线方法和端到端模型相比,MonkeyOCR 在多个方面展现出显著优势,包括更高的解析精度、更快的处理速度以及更广泛的适用性。
一、项目概述
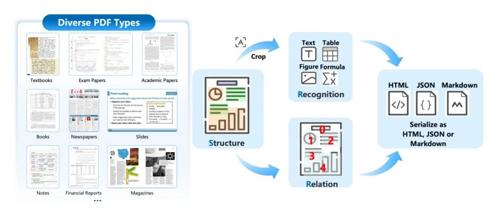
MonkeyOCR 是一个基于 Structure-Recognition-Relation (SRR) 三元组范式 的文档解析模型,旨在通过结构检测、内容识别和关系预测三个阶段,实现对文档的高效、精准解析。该模型在多个中文和英文文档类型上均表现出色,尤其在表格、公式等复杂内容的识别上,相比现有方法有显著提升。此外,MonkeyOCR 支持多页文档的快速解析,推理速度达到 0.84 页/秒,远超其他主流模型。
二、技术原理
(一)SRR 三元组范式
MonkeyOCR 的核心思想是将文档解析任务分解为三个关键步骤:
1. 结构检测(Structure Detection) :通过布局分析,识别文档中的各个区域(如文本块、表格、公式、图像等),并为其分配类别标签和边界框坐标。
2. 内容识别(Recognition) :对每个检测到的区域进行内容识别,包括文本、表格、公式等,使用统一的多模态大模型(LMM)进行识别。
3. 关系预测(Relation Prediction) :预测各个区域之间的逻辑关系,重建文档的结构化内容,确保输出的语义一致性。
这种三元组范式有效结合了流水线方法的模块化优势和端到端方法的全局优化能力,既保证了解析的准确性,又提升了处理效率。
(二)MonkeyDoc 数据集
为了支持MonkeyOCR 的训练和评估,研究团队开发了 MonkeyDoc,这是目前最全面的文档解析数据集之一。MonkeyDoc 包含 390 万个块级实例,涵盖超过 10 种文档类型,支持中英文双语标注。数据集的构建过程包括:
-
结构检测:从多个公开数据集中提取并统一标注,补充合成高质量中文样本。
-
内容识别:通过自动标注和人工校验,确保文本、表格、公式等的识别准确。
-
关系预测:通过多任务学习和模型辅助策略,建立区域之间的逻辑关系。
MonkeyDoc 的多任务、多语言、多领域的覆盖能力,为模型的泛化训练提供了坚实基础。
三、主要功能
(一)多语言支持
MonkeyOCR 支持中英文双语文档的解析,能够处理中文和英文的文本、表格、公式等复杂内容。对于中文场景,还可以使用专门的结构检测模型 `layout_zh.pt ` 来提高识别效果。
(二)多格式支持
模型支持对PDF、图像等多种格式的文档进行解析。用户可以通过命令行或 Gradio 界面上传文件,并获取结构化输出。
(三)高精度识别
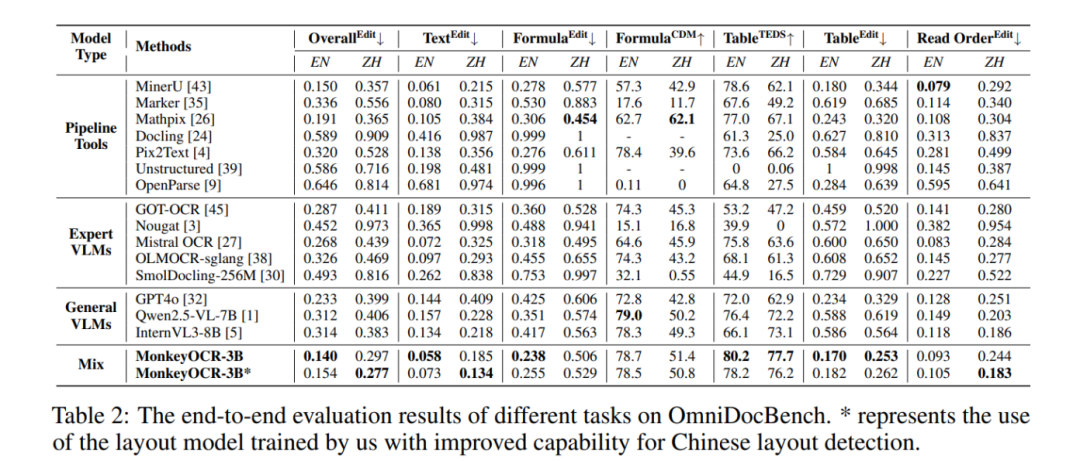
在多个基准测试中,MonkeyOCR 在表格识别、公式识别等任务上表现优异。例如,相比 MinerU,MonkeyOCR 在表格识别任务上的 TEDS(Textual Edit Distance)提升了 8.6%,在公式识别任务上的 CDM(Correct Document Match)提升了 15.0%。
(四)快速部署
MonkeyOCR 支持多种部署方式,包括命令行工具、 Docker 容器和 FastAPI 服务。用户可以根据需求选择合适的部署方案,快速启动模型并进行测试。
四、基准测试
为了验证MonkeyOCR的有效性,官方在OmniDocBench上对其与开源和闭源方法进行了全面比较。OmniDocBench是一个用于评估真实世界文档解析能力的基准测试,包含981个PDF页面,涵盖9种文档类型、4种布局风格和3种语言类别。通过这个基准测试,我们能够对MonkeyOCR的文档解析能力进行全面评估。
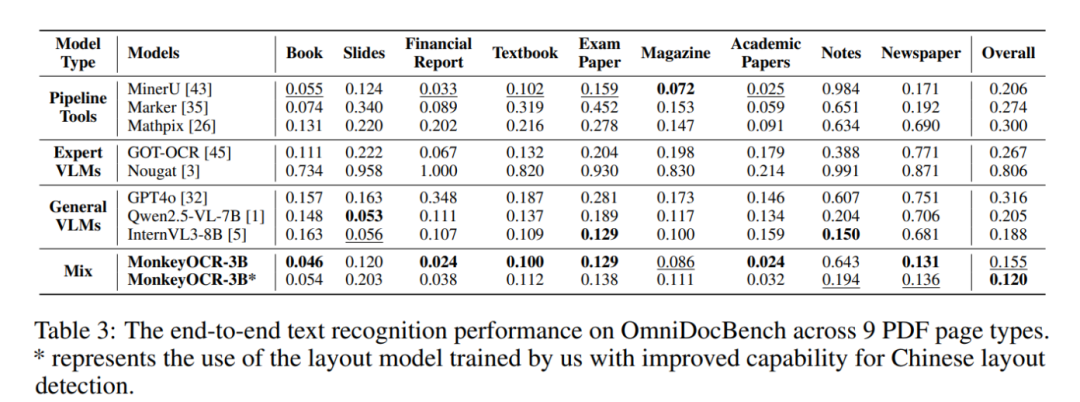
为了进一步评估MonkeyOCR处理不同类型文档的能力,官方在OmniDocBench基准测试中对九类文档进行了全面比较。如下图所示,MonkeyOCR在所有九类文档中均取得了最佳的整体性能。
五、应用场景
(一)电子书与学术论文
MonkeyOCR 可用于电子书、学术论文等复杂文档的结构化解析,帮助研究人员快速提取关键信息,提升文献管理效率。
(二)企业文档处理
在企业环境中,MonkeyOCR 可用于自动化处理合同、财务报告、会议纪要等文档,提高文档处理的效率和准确性。
(三)教育与考试系统
在教育领域,MonkeyOCR 可用于自动解析学生作业、考试试卷等,辅助教师进行批改和分析。
(四)医疗与法律文档
在医疗和法律领域,MonkeyOCR 可用于解析病历、法律文书等,确保信息的准确性和可追溯性。
六、快速使用
(一)环境准备
首先,安装必要的依赖库:
# 创建conda环境conda create -n MonkeyOCR python=3.10conda activate MonkeyOCR# 克隆代码git clone https://github.com/Yuliang-Liu/MonkeyOCR.gitcd MonkeyOCR# 安装依赖# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda versionpip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124pip install -e .
(二)下载模型
从HuggingFace 下载 MonkeyOCR 模型:
pip install huggingface_hubpython tools/download_model.py # 自动下载HuggingFace预训练权重
(三)模型推理
使用以下命令进行模型推理:
# 在MonkeyOCR目录下运行python parse.py path/to/your.pdf# 或者使用图片作为输入pyhton parse.py path/to/your/image# 指定输出路径和模型配置文件路径python parse.py path/to/your.pdf -o ./output -c config.yaml
(四)Gradio 界面
启动Gradio 界面,上传 PDF 或图像进行解析:
cd demopython demo_gradio.py
七、结语
MonkeyOCR 是一个基于 SRR 三元组范式的创新文档解析模型,通过结构检测、内容识别和关系预测三个阶段,实现了对复杂文档的高效、精准解析。在多个基准测试中,MonkeyOCR 表现出色,尤其在表格和公式识别任务上优于现有方法。未来,研究团队将继续优化模型性能,提升多语言支持,并探索更多应用场景。
八、项目资料
开源仓库:https://github.com/Yuliang-Liu/MonkeyOCR
模型地址:https://huggingface.co/echo840/MonkeyOCR
技术论文:https://arxiv.org/abs/2506.05218
在线体验:http://vlrlabmonkey.xyz:7685
(文:小兵的AI视界)