


新智元报道
新智元报道
【新智元导读】谷歌首发具身智离线模型Gemini Robotics On-Device,实现VLA多模态大模型在具身机器人本地离线运行。无网络也能稳定运行,谷歌还开源了SDK,具身智能迈向实用化新阶段。
谷歌黑科技又出新品了。
但这次谷歌不卷商业大模型了,而是转而发布了首个在具身机器人上「本地&离线」就能运行的VLA模型——Gemini Robotics On-Device!

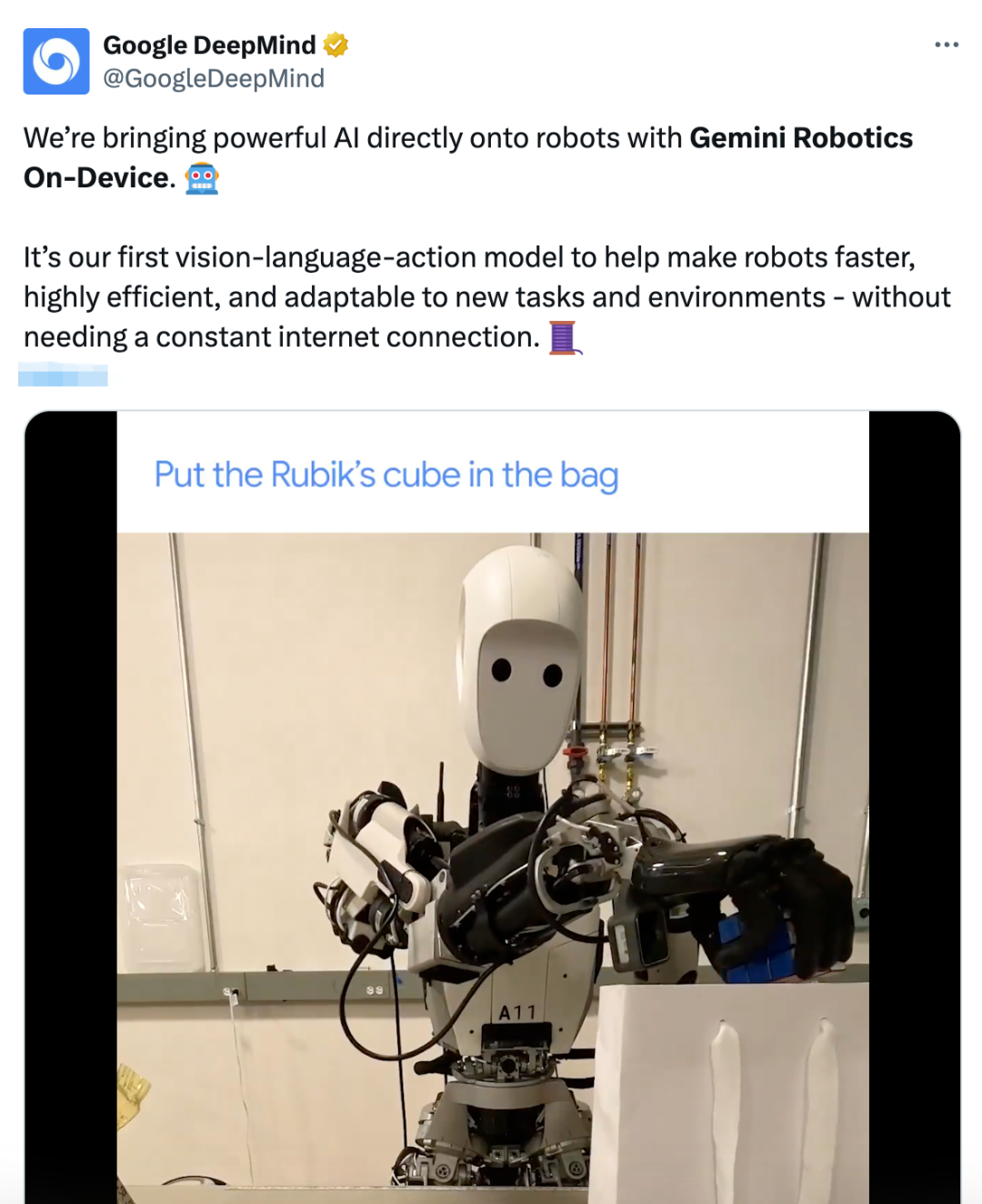
这个模型最初是为ALOHA机器人训练的,但谷歌对其进行了调整,能在双臂Franka FR3机器人以及Apptronik公司的Apollo人形机器人上运行。

8倍速展示机器人运行效果
这种模型被称为「机器人的大脑」,目的是让机器人能理解复杂环境、执行精细任务,甚至适配各种形态。
简单梳理一下这个系列,Gemini Robotics是谷歌3月份就推出的VLA系列模型,VLA指的是视觉-语言-动作模型。
Gemini Robotics重点是将多模态大模型的能力「带到」现实世界。
而Gemini Robotics On-Device,顾名思义,就是专为在机器人设备本地运行而优化的模型。


Gemini Robotics作为具身智能的基础旗舰模型,以Gemini2.0为基底研发而来。

论文地址:https://arxiv.org/pdf/2503.20020
Gemini 2.0 已经具备多项与机器人相关的重要能力,比如对语义安全的理解能力以及处理长上下文信息的能力。
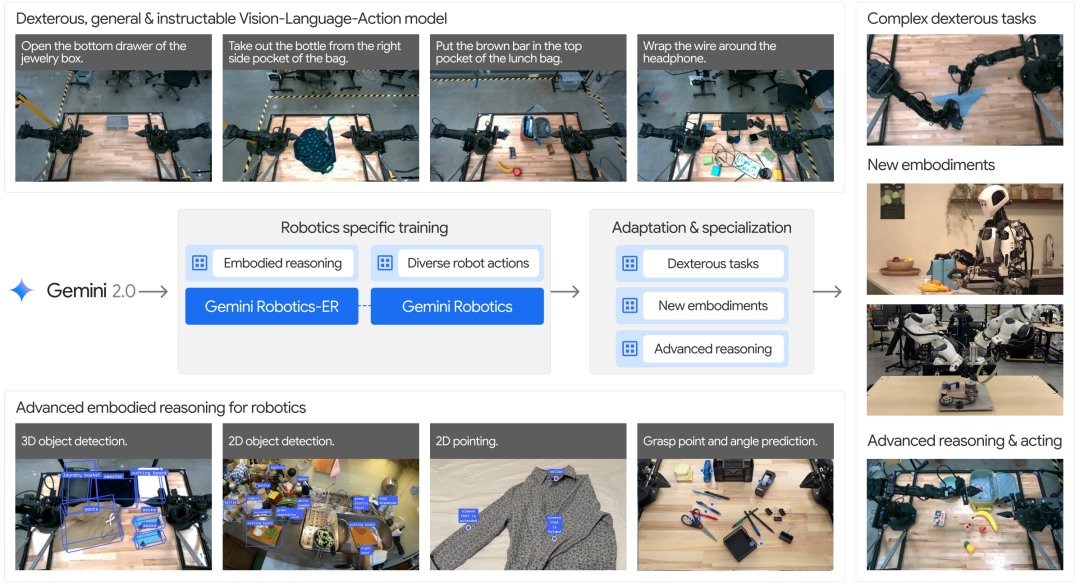
通过专门的机器人训练以及可选的专项优化过程,Gemini Robotics模型展现出多种面向机器人的能力。
这些模型不仅能够生成灵巧且具有反应性的动作,还可以迅速适应不同类型的机器人形态,并利用先进的视觉空间推理能力来指导自身的行为。
而新推出的Gemini Robotics On-Device无需网络即可运行,适用于对于延迟敏感的应用场景。
本地模型的优势就是能确保在网络连接间歇或无连接的环境中让具身机器人依然性能稳定。

Gemini Robotics On-Device是一款面向双臂机器人的机器人基础模型,设计目的是仅需最低限度的计算资源就能让机器人具备「智能」。
基于Gemini Robotics的任务泛化能力和灵巧操作能力,模型具有以下特点:
-
专为快速实验灵巧操作而设计。
-
可通过微调以适应新任务,从而提升性能。
-
优化用于本地运行,实现低延迟推理。
Gemini Robotics On-Device在多种测试场景中展现出强大的视觉、语义和行为泛化能力,能够遵循自然语言指令,完成如解开袋子或折叠衣物等高度灵巧的任务。
以解开袋子为例,可以看到左右机械臂的配合很像人类「旋转」打开拉链的过程。
不过在过程中,依然可以发现一些小的瑕疵,比如左机械臂在「固定」袋子上并不是很稳定,会「手滑」。

2.5倍速展示
在谷歌评估中,完全本地运行的Gemini Robotics On-Device模型展现了强大的泛化性能。
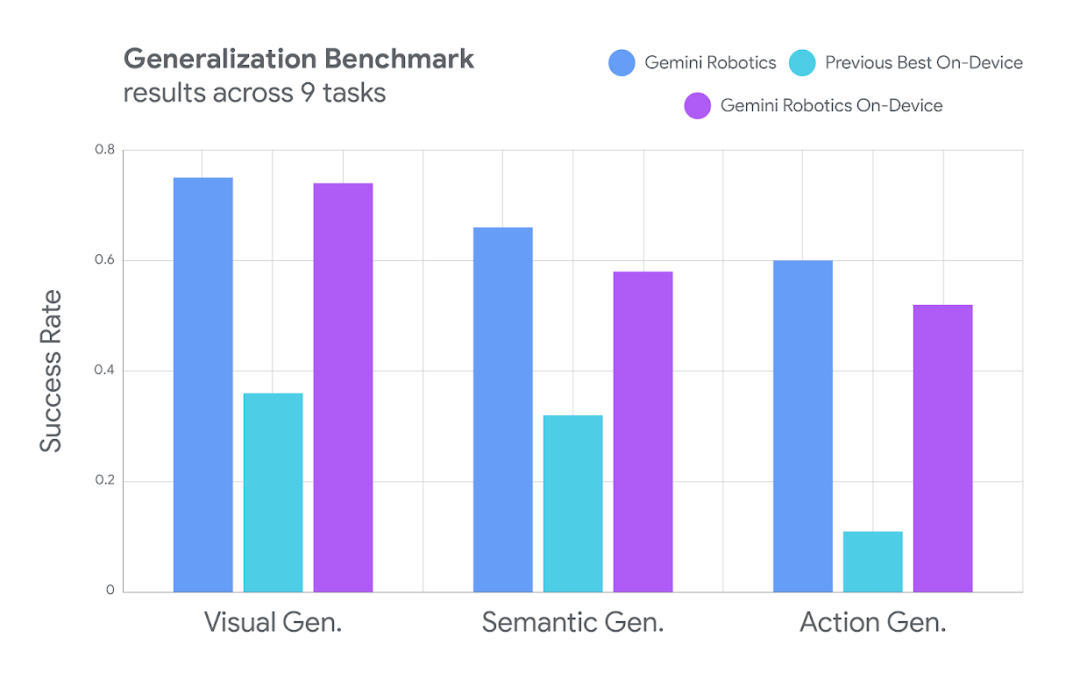
Gemini Robotics On-Device的泛化性能,与其旗舰版Gemini Robotics模型及之前最佳的设备端模型相比,On-Device远超之前最佳模型,并接近旗舰模型。
Gemini Robotics On-Device 在更具挑战性的分布式任务和复杂的多步骤指令方面,也优于其他设备端替代方案。
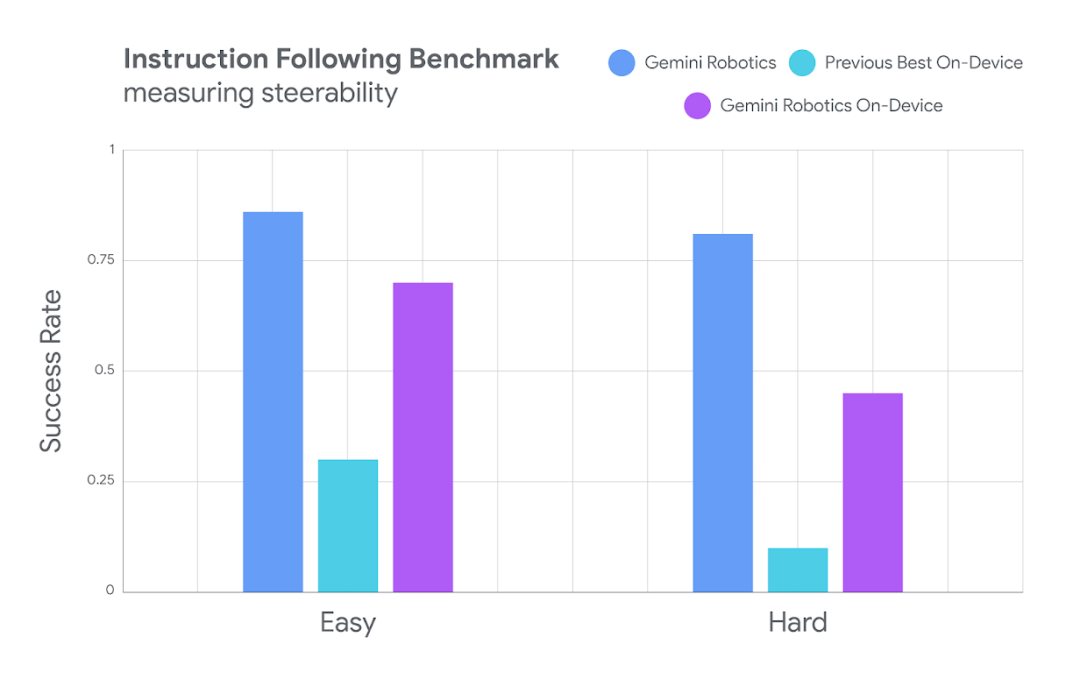
Gemini Robotics On-Device也是一款首次提供用于微调的VLA模型。
谷歌提供了一个Gemini Robotics SDK,以帮助开发者评估Gemini Robotics On-Device在其他任务和环境中的表现。
开源地址:https://github.com/google-deepmind/gemini-robotics-sdk
尽管许多任务可以直接开箱即用,但开发者也可以选择对模型进行适配,以使其在特定应用中实现更佳的性能。
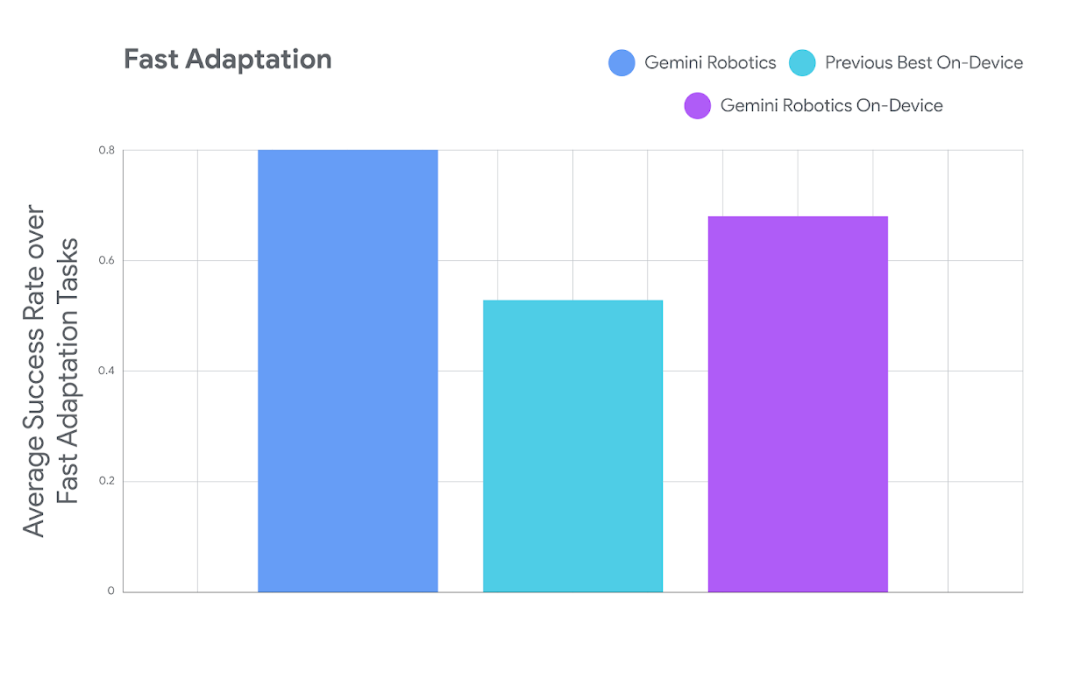
谷歌在七个不同难度级别的灵巧操作任务中测试了该模型,包括拉上便当盒拉链、抽取卡片和倒入沙拉酱等操作。
下图展示了Gemini Robotics On-Device的任务适应性能,远超目前最好的设备端模型。
进一步,谷歌将Gemini Robotics On-Device模型适配到了不同的机器人实体上。
在双臂Franka机器人上,该模型能够执行通用指令跟随,包括处理以前未见过的物体和场景,完成诸如折叠连衣裙等需要灵巧操作的任务,或执行需要高精度和灵活性的工业传送带装配任务。
在Apollo人形机器人上,谷歌对该模型进行了适应性调整,以适配显著不同的实体形态。
同一个通用模型可以遵循自然语言指令,并以通用的方式操作包括先前未见过的各种不同物体。
Gemini Robotics的能力来源于Gemini 2.0。
Gemini 2.0在具身推理方面表现出色——它能够识别二维中的物体和关键点,利用二维的指点操作进行抓取和轨迹规划,还能在三维空间中进行关键点对应和物体识别。
以下展示的所有能力均由Gemini 2.0 Flash实现。

Gemini Robotics-ER利用Gemini 2.0的二维指点能力,可以预测从上往下的抓取方式。
Gemini Robotics-ER能利用Gemini的具身推理(ER)能力。

Gemini 2.0能够通过关联不同视角下的二维点,来理解三维场景。
对于每一组图像,左侧图像标注了点的坐标,右侧图像则未标注,模型需要预测左图中哪些标注点在右图中可见,并给出这些可见点在右图中的坐标。

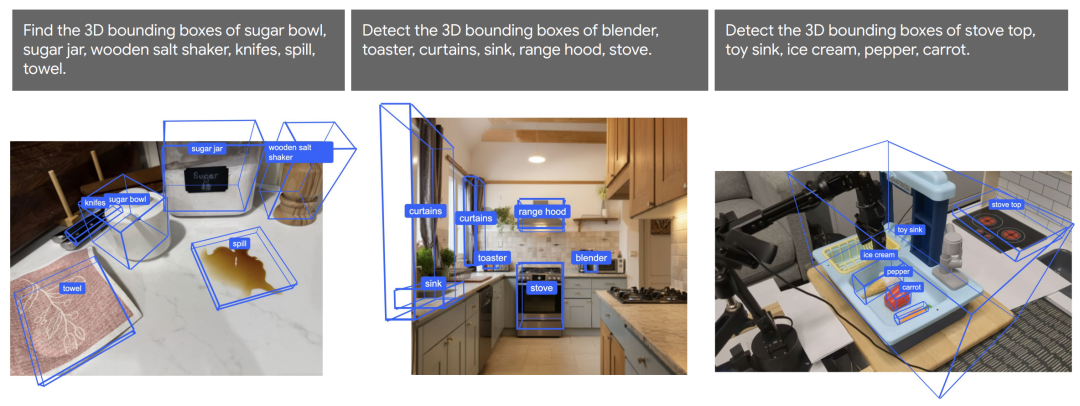
Gemini 2.0还可以直接预测开放词汇的三维物体边界框。
Gemini Robotics将多模态大模型赋能具身智能,打破虚拟与现实的界限。
而Gemini Robotics On-Device更进一步,实现了具身智能的完全离线运行。
这一系列技术突破,预示着人机携手共进的新时代已悄然来临。
(文:新智元)