

今天是2025年6月28日,星期六,重庆,晴
我们来快速回顾下最近一周技术方面值得关注的利好落地的前沿进展。
一个是腾讯混元开源混合推理MoE模型,这个算是填补了70-90B之间的推理模型空白,看下模型特点和里面跟qwen很类似的思考模式think or nothink。
另一个是与RAG 场景落地关系比较密切的embedding进展,一个是多尺寸比较能打的qwen3-embedding系列,一个是多模态embdding的jina-v4版本,体现出现在embedding侧的一些变化,从单模态到多模态,从单一向量到多向量、从固定维度到自定义维度(MRL俄罗斯套娃)、开始转向使用大模型作为基座模型、开始使用合成数据等方式挖掘难样本、针对特定任务补充能力项
一、开源推理大模型的进展
腾讯混元开源混合推理MoE模型Hunyuan A13B,技术亮点为混合专家(MOE)模型,拥有800亿总参数和130亿激活参数,包含1个共享专家和64个非共享专家,训练时只有8个非共享专家被激活。
1、相关地址
先看地址:
体验入口地址在https://hunyuan.tencent.com/;
API地址在https://cloud.tencent.com/product/tclm;
Github地址在https://github.com/Tencent-Hunyuan;
HuggingFace地址在https://huggingface.co/tencent。
2、模型特点
原生支持256K上下文窗口,优化Agent能力,采用分组查询注意力(GQA)策略,支持多量化格式;

支持快思考和慢思考两种模式,模型的默认输出是慢思考模式,若想让模型进行快思考,可在guery前附加上”/no think”,这个是采用与qwen类似的think/no_think模式,这是成为标配。

这个在训练过程中,也是靠数据策略来控制如下,构建dual-cot数据进行训练:

快思考模式的训练示例在“<think>”内容块中不包含详细的推理步骤;慢思考的训练示例在“<think>”内容块中显式包含逐步推理。
3、模型训练
预训练分为三个阶段:基础训练阶段处理20万亿token,学习率采用三阶段调度;快速退火阶段在3000亿token上实现快速衰减;长上下文训练阶段将上下文窗口扩展到256K。

后训练阶段包括4步,通过监督微调(SFT)和强化学习(RL)进一步提升模型性能。SFT阶段使用高质量的指令-响应数据集,涵盖数学、代码、逻辑和科学推理等任务。RL阶段利用结果奖励模型和沙盒反馈,进一步增强模型的推理能力。
二、Qwen3-embedding及Jina-embeddings-v4
Embedding是RAG等应用场景的重要组件,当前的一些趋势就是,从单模态到多模态,从单一向量到多向量、从固定维度到自定义维度(MRL俄罗斯套娃)、开始转向使用大模型作为基座模型、开始使用合成数据等方式挖掘难样本、针对特定任务补充能力项
所以,可以看看一些大致的细节,两个工作。
1、Qwen3-embedding中的数据合成思路和多尺寸系列
既然说到embedding,这个就再温习下Qwen3-embedding,提供了多种模型大小(0.6B、4B、8B),适用于嵌入与重排序任务,满足用户在不同部署场景下对效率或效果优化的需求。
所以,其核心点就是,基于Qwen3LLM做工作,先看地址:
GitHub在https://github.com/QwenLM/Qwen3-Embedding;
技术报告在https://github.com/QwenLM/Qwen3-Embedding/blob/main/qwen3_embedding_technical_report.pdf;
Qwen3-Embedding模型地址在https://modelscope.cn/collections/Qwen3-Embedding-3edc3762d50f48;
Qwen3-Reranker模型地址在https://modelscope.cn/collections/Qwen3-Reranker-6316e71b146c4f
1)双塔及单塔训练架构
训练架构上,Embedding模型和Reranker模型分别采用了双塔结构和单塔结构的设计。
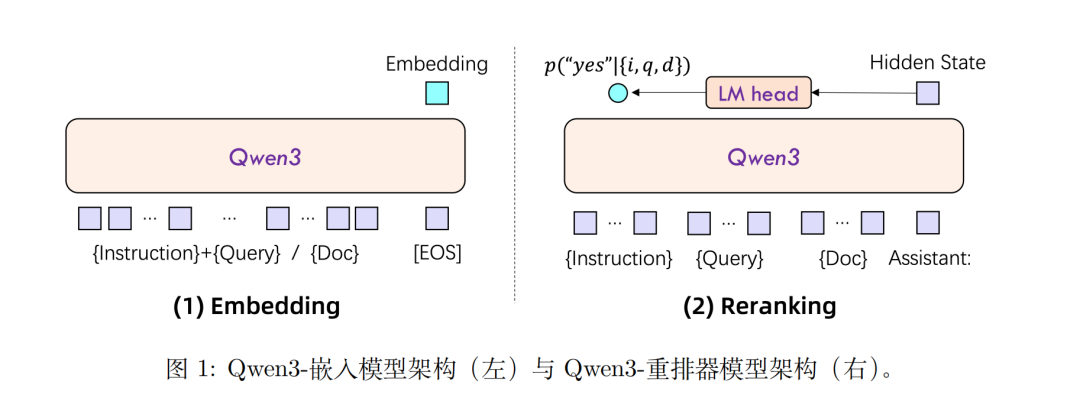
通过LoRA微调,最大限度地保留并继承了基础模型的文本理解能力。
其中:
Reranker模型接收文本对(例如用户查询与候选文档)作为输入,利用单塔结构计算并输出两个文本的相关性得分,根据给定输入计算相关性得分,也就是评估下一个token 为“是”或“否”的似然。

Embedding模型接收单段文本作为输入,在输入序列末尾附加一个[EOS] token,饭后取模型最后一层「EOS」标记对应的隐藏状态向量,作为输入文本的语义表示。
其中,MRL支持”表示嵌入模型是否支持自定义最终嵌入的维度,这个用的很多,已经成为标配。
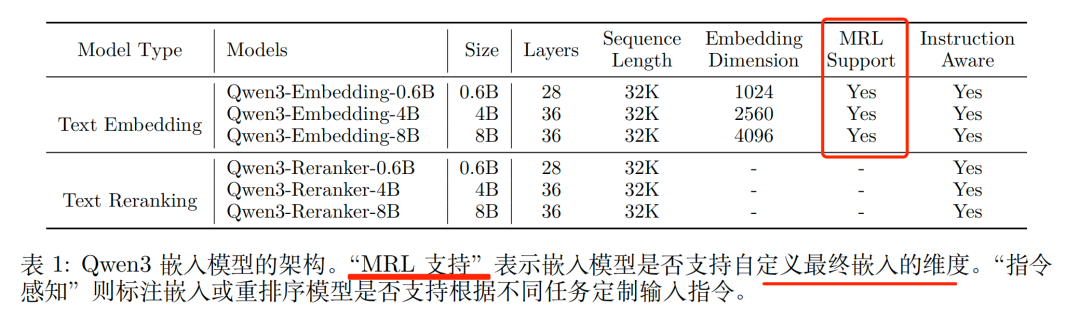
也可以进行Embedding模型的进一步微调,以适应特定领域的embedding数据需求;
2)三阶段训练路线
训练方式上,采用“合成数据驱动的弱监督+高质量数据的有监督微调+模型合并”的三阶段训练Pipeline。
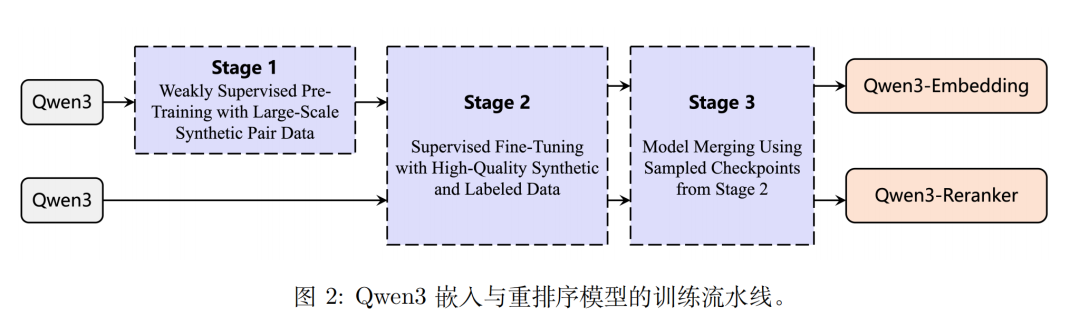
1)阶段1-大规模弱监督预训练(WeaklySupervisedPre-Training),基于Qwen3-32B,构建了四种类型的合成数据——检索、双语挖掘、语义文本相似度和分类,以使模型在预训练期间能够适应各种相似度任务。
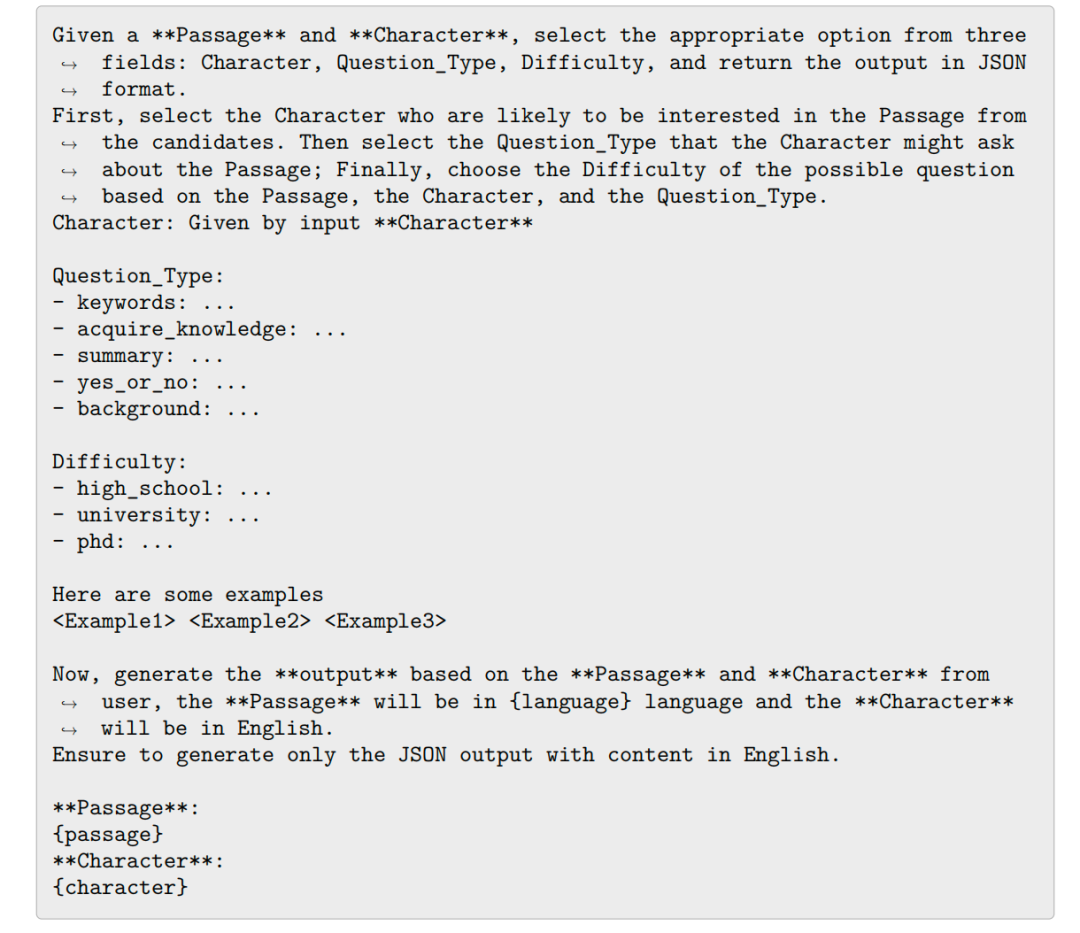
具体做法是,为通过设计的模板与prompt,将原始多语种文档转化为“查询-文档”对,先在“Configuration”阶段为每段文档挑选角色(Character)、问题类型(Question_Type)、难度(Difficulty);
再在“QueryGeneration”阶段根据上述配置生成用户角度的查询句,最终合成约1.5亿对多任务弱监督训练数据,然后采用改进的InfoNCE对比损失;
2)阶段2-高质量数据有监督微调(SupervisedFine-Tuning),沿用InfoNCE损失对嵌入模型进行微调,重排序模型直接采用SFT(二分类交叉熵)损失;
3)阶段3-模型合并(ModelMerging), 在有监督微调阶段保存的多个检查点(checkpoints)之间,通过球面线性插值(slerp)技术,将不同阶段或不同任务偏好模型进行“合并”。
2、Jina-embeddings-v4多模态向量模型
Jina-embeddings-v4,参数规模38亿,为多模态Embedding模型,对于RAG应用,该模型还新增了处理视觉丰富图像(也称为视觉文档)的功能,即包含文本和图像混合的材料,如表格、图表、图示及其他常见混合媒体。
先看地址在https://huggingface.co/jinaai/jina-embeddings-v4;
API地址在https://jina.ai/embeddings/;
技术报告地址在https://arxiv.org/abs/2506.18902。
1)看训练架构
将其底座模型更换为 Qwen2.5-VL-3B-InstructQwen2.5-VL模型作为主干。与Qwen2.5-VL类似,支持文本和图像两种输入模态,并以相同的方式处理输入。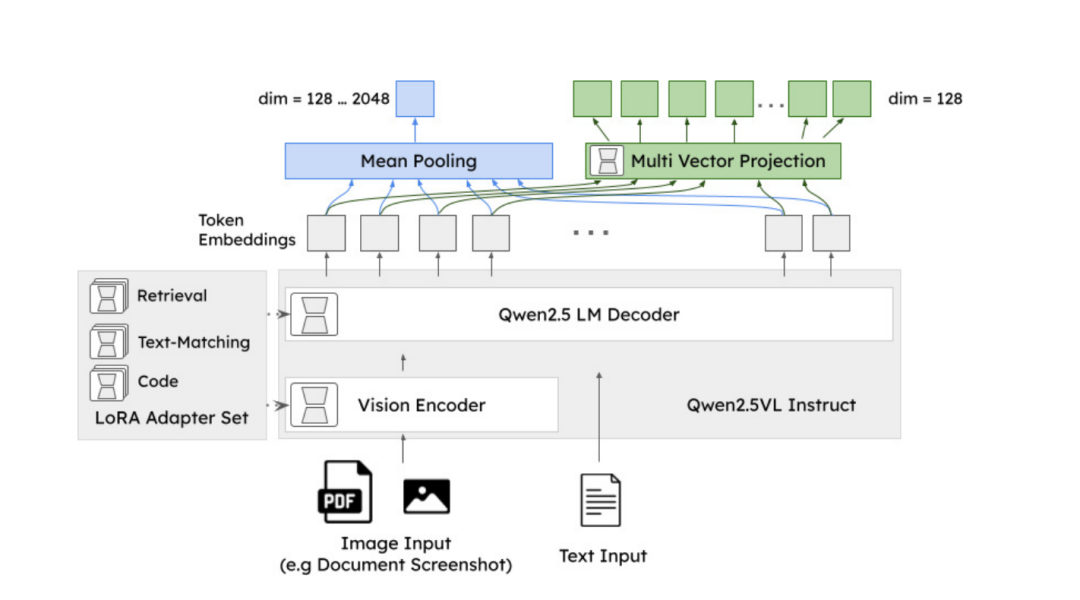

两个改动点。
1)多任务LoRA扩展
添加LoRA扩展以提升特定任务的性能,包括三个针对特定任务的LoRA适配器(每个含6000万参数),整体参数的2%额外新增。
分别是非对称查询-文档检索、语义相似度与对称检索、代码(即计算机编程语言)检索,用户可以在推理时从中选择。
2)单向量和多向量输出
与Qwen2.5-VL及其他一般嵌入模型不同,用户可在两种输出选项间进行选择,即传统的单一(稠密)向量嵌入,以及适用于延迟交互策略的ColBERT风格多向量嵌入。
单向量嵌入的维度为2048,但可以截断至128,且几乎不会损失准确率,这个主要得益于通过Matryoshka表示学习进行训练,因此单向量嵌入的标量值大致按语义重要性排序,去除最不重要的维度对准确率的影响微乎其微。
多向量嵌入是通过Transformer模型处理token后未池化的结果,对应于模型在分析token时根据其上下文所得到的token。输出向量的长度与输入token(包括“图像token”)的数量成正比,每个token对应一个128维的输出向量。
该输出可直接与ColBERT和ColPali生成的未池化嵌入进行比较,并适用于延迟交互比比较【这个就是主流的了,多模态RAG常用】。
参考文献
1、https://github.com/QwenLM/Qwen3-Embedding/blob/main/qwen3_embedding_technical_report.pdf
2、https://github.com/Tencent-Hunyuan
3、https://arxiv.org/abs/2506.18902
(文:老刘说NLP)