

极市导读
本文深入探讨了多模态大模型训练中常见的“模态懒惰”和“模态偏差”问题,即不同模态在信息贡献上的不平衡以及模型过度依赖某一模态的现象,并详细总结了现有的解决方法,包括训练方式、算法细节设计和训练数据分布优化等方面。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本篇继续说明MLLM中多模态对齐的难点以及现有的解决方法,本系列要说明的主要难点有:
-
多模态数据构建
-
跨模态差异影响融合效果
-
模态对齐评估效率比较低
本篇开始总结跨模态差异影响融合效果部分。具体来说就是不同模态特征分布差异显著(如图像与文本的嵌入空间不匹配),会阻碍深度融合从而影响MLLM的效果。
这块部分在多模态学习中也叫“模态懒惰”问题。在多模态学习中,不同的数据模态(如文本、图像、音频等)可能在信息贡献上存在不平衡,导致一些模态在学习过程中显得更为主导,而其他模态则被忽视,这种现象就被称为模态懒惰。这会导致多模态学习系统的性能不佳。
另外除了“模态懒惰”外,“模态偏差”也常常跟着被一起提到,MLLMs在处理多模态数据时,往往会过度依赖于某一模态(如语言或视觉),而忽视其他模态中的关键信息,从而导致模型生成不准确或不相关的回答。目前这种模态偏差主要表现为语言偏差(language bias)和视觉偏差(vision bias)。
-
语言偏差:比如在回答“熊的颜色是什么?”时,模型可能基于大多数熊是棕色的常识,忽略了输入图像中显示的北极熊是白色的。
-
视觉偏差:指模型过度关注图像细节,而忽略了文本问题的真正意图。例如,在回答“房子在左边吗?”时,模型可能提供了过多的图像细节,而没有准确理解文本问题。体现出来可能觉得模型回答过于冗余但并没有回答到点上。
下面是具体的解决方法,主要分为训练方式、算法设计和训练数据分布优化。
训练方式这里就不做赘述了,比较常见的是渐进式解冻训练:先fix住某一模态编码器权重,再训练另一模态权重,最后全网络整体训练。
本篇主要讲述算法细节设计和训练数据分布优化的详细内容,下面是一个快捷目录。
一、算法细节设计
-
最小化模态间投影误差 -
模态间交叉引导融合不同模态特征差异
二、训练数据分布优化
-
在不同模态的不同语义层级设计对齐约束 -
主动学习实现更平衡的数据选择 -
引导偏好优化(BPO),惩罚某一模态的依赖行为
注意这里的训练数据优化相对于于上一篇中的数据构建有所区别,主要强调基于已有数据进行分布优化以及不同模态链接,更便于缓解跨模态差异实现深度融合。
算法细节设计
1. 最小化模态间投影误差(如文本→图像映射的均方误差)
结合最优传输理论(Optimal Transport)建模分布对齐,解决语义密度差异问题。
这里举一个ICLR 2024的论文《Multimodal Representation Learning with Alternating Unimodal Adaptation》的例子。这篇论文提出了一种名为MLA(Multimodal Learning with Alternating Unimodal Adaptation)的方法:
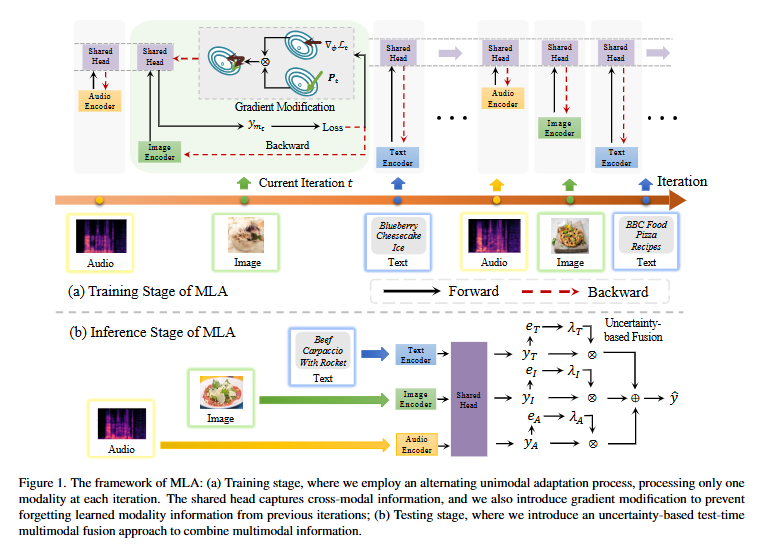
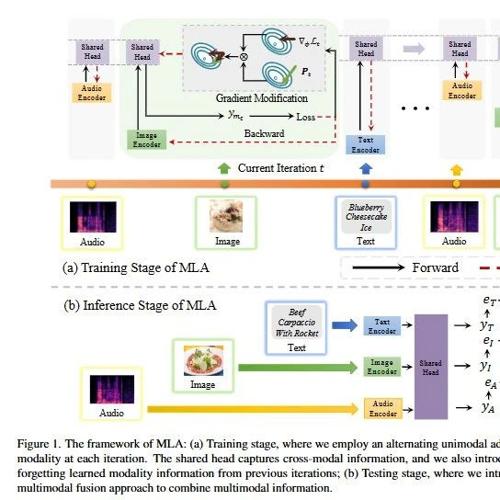
主要包括下面四个核心步骤,笔者觉得实际中都很实用。
1) 交替单模态学习:把传统的多模态联合优化过程转变为交替的单模态学习过程。在每个训练步骤中,只优化一个模态的编码器,从而减少模态之间的干扰,使每个模态都能独立地被优化。
2)共享头部:每个模态独立优化,但用一个跨所有模态的共享头部来捕获跨模态的交互信息。共享头部在不同模态之间持续优化,有助于整合多模态信息。
3)梯度修改机制:为了防止共享头部在遇到新模态时丢失之前学习到的信息(即模态遗忘问题),通过正交化梯度方向来减少不同模态之间的干扰。
4)推理阶段动态模态融合:在inference阶段,基于不确定性的模型融合机制来整合多模态信息;评估每个模态在预测中的重要性,并根据这个评估来分配权重,然后结合所有模态的预测结果。
2. 模态间交叉引导融合不同模态特征差异
比较常见的是跨模态交叉注意力(Cross-modal Cross-Attention)显式建模不同模态特征的融合,Query来自一模态,Key/Value来自另一模态;或者基于输入内容自适应调整各模态贡献权重,抑制低质量模态噪声。
另外时间与空间交叉引导对齐也开始有一些论文在提到:
CVPR 2025中的论文《Magma: A Foundation Model for Multimodal AI Agents》中的预训练学习任务SoM和ToM。
Set-of-Mark (SoM) for Action Grounding,在图像中标注可操作区域(如 GUI 中的可点击按钮),帮助模型学习如何定位和识别这些区域;在每个图像中,提取一组候选区域或点,并在这些位置上标注数字标签,形成一个新的标记图像。模型需要从这些标记中选择正确的标记,从而显著简化了行动定位任务。
Trace-of-Mark (ToM) for Action Planning,在视频中标注动作轨迹,帮助模型学习如何预测未来的动作。在视频序列中,提取每个帧中的标记位置,并预测这些标记在未来帧中的轨迹。这不仅使模型能够理解视频中的时间动态,还能“提前规划”未来的动作。
训练数据分布优化
1. 在不同模态的不同语义层级设计对齐约束
论文《DenseFusion-1M: Fusing Multi-visual Experts for Fine-grained Understanding》提出了一种名为“Perceptual Fusion”的方法,使用低成本但高效的字幕引擎生成详尽准确的图像描述,便于生成不同语义粒度的更高质量的图像-文本数据集。
有一个非常关键的视觉专家集成(Mixture of Visual Experts),可以利用多种视觉专家模型来提供图像理解的中间信息。视觉专家一共包括下面四类:
-
图像标注模型(Image Tagging Model):提供场景级别的理解。
-
目标检测模型(Object Detection Model):精确检测图像中的物体。
-
文本识别模型(Text Recognition Model):识别图像中的所有文本元素。
-
世界知识(World Knowledge):提供背景信息和细节,增强模型的知识密度。

那么在做对齐的时候从局部和全局入手,局部可以对齐图像区域与文本单词(如目标检测框与名词短语);从全局对齐整体图像与句子语义,避免细节丢失。
2. 主动学习实现更平衡的数据选择
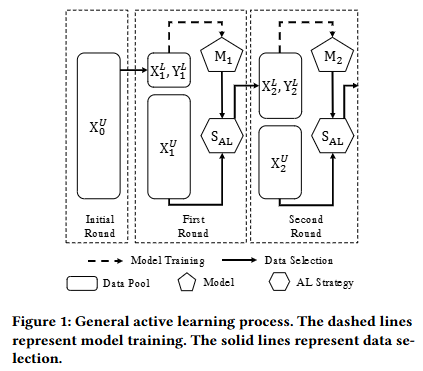
这里之前的文章也有提过,使用Shapley值来估计每个模态对最终多模态预测的贡献,不需要真实标签。
通过计算模型输出(即预测概率)在包含和不包含某个模态特征时的变化,来估计该模态特征的边际贡献,然后对所有可能的子集选择取平均值,从而得到该模态的Shapley值。
论文《Towards Balanced Active Learning for Multimodal Classification》 把模态贡献定义为该模态的Shapley值的绝对值与所有模态的Shapley值绝对值之和的比值。并且提出了三个原则:
1)优先选择贡献更平衡的样本:如果两个多模态数据样本的传统主动学习(CAL)策略的获取分数相等,那么具有更平衡单模态贡献的样本应具有更高的平衡多模态主动学习(BMMAL)策略的获取分数。
2)减少强模态和弱模态数据样本平均获取分数的差距:为了避免偏向强模态的数据选择,应减少强模态主导的数据样本和弱模态主导的数据样本之间的平均获取分数的差距。
3)保持模态贡献与获取分数的正比关系:为了防止偏向弱模态的数据选择,需要确保每个模态对获取分数函数的贡献与其对模型输出在样本级别的贡献成正比。
因此在训练时结合此原则可以调整训练方法进行选择:
1)调整梯度嵌入:首先计算多模态分类器的梯度嵌入,然后根据每个模态的贡献比例,分别对每个单模态的梯度嵌入进行缩放。具体来说,对于两个模态的情况,如果一个模态的贡献大于另一个模态,那么其对应的梯度嵌入会被乘以一个权重,该权重小于1且与模态贡献的差异成正比。这样,不平衡的样本的梯度嵌入的幅度会被抑制,从而降低它们被K-Means++算法选择的可能性。
2)样本选择:最后,使用K-Means++算法对调整后的梯度嵌入进行聚类,选择具有显著影响的多样化多模态数据样本用于模型训练。
3. 引导偏好优化(BPO),惩罚某一模态的依赖行为
可以通过引入扰动来减少某些模态的信息内容,迫使模型在生成负面响应时依赖特定模态。比如前面提到的两个”模态偏差“的例子,棕色的北极熊和对于”房子在左边吗?“问题的不精准回答,把这些生成的偏差响应都作为负面样本,形成了一个新的偏好优化数据集。
论文 《 Debiasing Multimodal Large Language Models via Noise-Aware Preference Optimization》提出了噪声感知偏好优化算法(NaPO)动态识别噪声数据并减少对这些样本的优化权重。具体实现如下:
1)结合MAE和BCE:NaPO通过负Box-Cox变换将DPO中的二元交叉熵(BCE)与噪声鲁棒的平均绝对误差(MAE)结合起来。BCE收敛速度快但容易过拟合噪声数据,而MAE具有更好的噪声鲁棒性但收敛速度慢。通过调整噪声鲁棒性系数q,可以在两者之间取得平衡。
2)动态调整噪声鲁棒性系数:基于数据噪声水平动态调整q,通过分析数据的奖励边际(reward margin),可以评估数据的质量,并据此调整q的值。具体公式为:
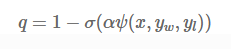
其中,ψ(x,yw,yl)是奖励边际公式,α是归一化因子,σ是sigmoid函数。通过这种方式,NaPO能够根据数据的噪声水平自适应地调整其噪声鲁棒性。
需要注意的是,不同模态的数据融合的处理方法存在较大差异,比如文本与图像、图像与点云、视频与轨迹等,细分领域的专业性较强;本篇只总结了一些比较常见的方法。
参考文献:
[1]Multimodal Representation Learning with Alternating Unimodal Adaptation
[2] Magma: A Foundation Model for Multimodal AI Agents
[3] DenseFusion-1M: Fusing Multi-visual Experts for Fine-grained Understanding
[4] Towards Balanced Active Learning for Multimodal Classification
[5] Debiasing Multimodal Large Language Models via Noise-Aware Preference Optimization
(文:极市干货)