



论文链接:
https://arxiv.org/abs/2505.20292
项目主页:
https://pku-yuangroup.github.io/OpenS2V-Nexus

亮点直击
全新的 S2V(Subject-to-Video)基准测试:引入了用于全面评估 S2V 模型的 OpenS2V-Eval,并提出了三种与人类感知一致的新自动评估指标。
S2V 模型选择的新见解:通过使用 OpenS2V-Eval 进行评估,揭示了多种主体到视频生成(S2V)模型的优势与劣势,提供了关键性见解。
大规模 S2V 数据集:构建了 OpenS2V-5M 数据集,包括 510 万条高质量常规数据和 35 万条 Nexus 数据,后者旨在解决主体到视频生成中的三个核心挑战。

TL;DR
领域问题
-
缺乏细粒度评估基准:现有的 S2V 生成评估主要继承自 VBench,侧重于视频整体质量和粗粒度评价,难以准确衡量主体一致性、自然性和身份保真度。
-
缺乏大规模、高质量的数据集:S2V 研究缺乏开放、可复用的大规模主体-文本-视频三元组数据集,限制了模型训练和评估。
-
评估指标与人类感知不一致:现有自动评估指标难以准确反映人类对生成视频的主观感受。
-
S2V 模型性能缺乏系统对比:缺少统一平台对不同 S2V 模型进行系统性评估和比较。
提出的方案
1. 构建 OPENS2V-NEXUS 基础设施,包括:
-
OpenS2V-Eval:一个聚焦主体一致性、自然性和身份保真度的细粒度评测基准;
-
OpenS2V-5M:一个包含 510 万条高质量主体-文本-视频三元组的大规模开放数据集。
2. 设计三种自动化评估指标:
-
NexusScore:衡量主体一致性;
-
NaturalScore:衡量生成视频的自然程度;
-
GmeScore:衡量文本与视频的相关性。
3. 覆盖七大类 S2V 场景,设计 180 条提示语,结合真实与合成数据,全面测试模型能力。
4. 系统评估 18 个代表性 S2V 模型,揭示不同模型在多种内容类型下的表现差异。


OpenS2V-Eval
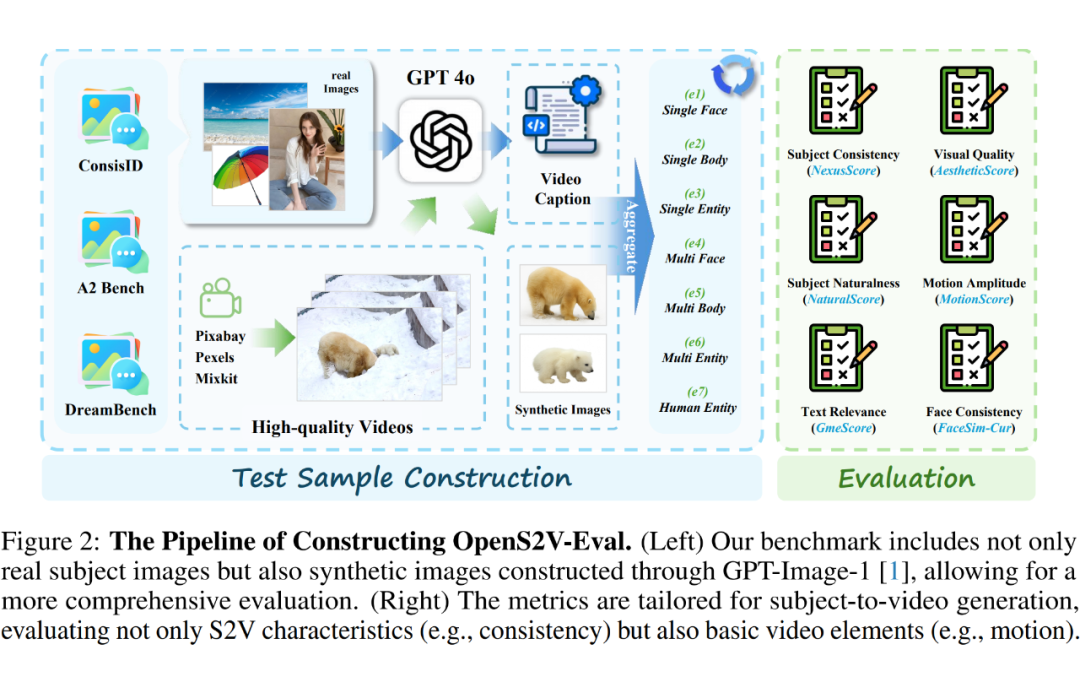
Prompt 构建
为了全面评估受视频模型的能力设计的文本提示必须涵盖广泛的类别,相关的参考图像必须符合高质量标准。
因此,为了构建一个包含多样视觉概念的受视频基准,将此任务分为七个类别:1 单面部到视频,2 单身体到视频,3 单实体到视频,4 多面部到视频,5 多身体到视频,6 多实体到视频,以及 7 人类实体到视频。
基于此,分别从 ConsisID 和 A2 Bench 收集了 50 和 24 对受文本,以构建 1、2 和 6。
此外,从 DreamBench 收集了 30 张参考图像,并利用 GPT-4o 生成标题以构建 3。
随后,从无版权网站获取高质量视频,使用 GPT-Image-1 从视频中提取主体图像,并使用 GPT-4o 为视频生成标题,从而获得其余的受文本对。每个样本的收集均手动进行,以确保基准质量。与之前仅依赖真实图像的基准 [13, 39] 不同,合成样本的纳入增强了评估的多样性和精确性。
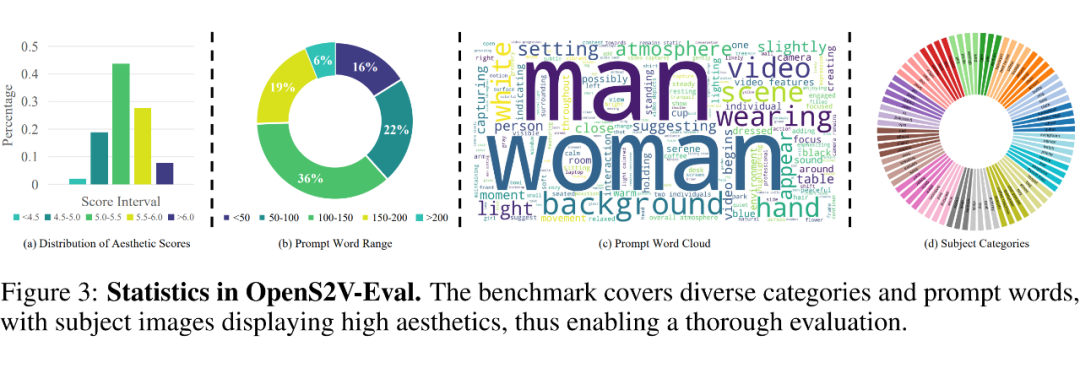
基准统计
收集了 180 对高质量的受文本对,其中包括 80 个真实样本和 100 个合成样本。除了 4 和 5 各包含 15 个样本外,所有其他类别均包括 30 个样本。数据统计如下图 3 所示。如(c)和(d)所示,S2V 任务的七个主要类别涵盖了广泛的测试场景,包括各种物体、背景和动作。
此外,与人类相关的术语,如“女人”和“男人”,占据了相当大的比例,从而能够全面评估现有方法保持人类身份的能力——这是 S2V 任务中尤其具有挑战性的方面。
此外,由于某些方法偏好长标题而其他方法偏好短标题,确保文本提示的长度各异,如(b)所示。还评估了收集的参考图像的美学评分,结果显示大多数得分超过 5,表明质量较高。
此外,保留了一些低质量图像以保持评估的多样性。由于现有 S2V 模型 [42, 18, 43] 的局限性,将每个样本的主体图像数量限制为不超过三个。
新的自动化指标
如前所述,现有的 S2V 基准通常是从 T2V 调整而来的,而不是专门定制的。对于受视频而言,评估不仅要考虑视觉质量和运动等全局方面,还要评估合成输出中的主体一致性和自然性。
NexusScore:为了计算主体一致性,先前的研究 [39, 54, 21, 36, 37] 直接计算未裁剪视频帧与参考图像在 DINO 或 CLIP 空间中的相似性。然而,这种方法引入了背景噪声,并且特征空间已被证明是不合理的。
为了解决这个问题,引入了 NexusScore,它利用图像提示检测模型和多模态检索模型。具体而言,参考图像和视频帧首先被输入到图像提示检测模型,该模型识别每帧中的相关目标并生成相应的边界框:
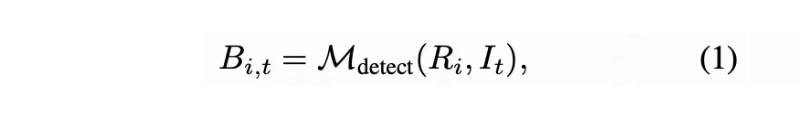
为了提高边界框的准确性,对于每个主体,裁剪区域以获得裁剪后的参考图像。然后,计算裁剪后的参考图像与统一文本-图像特征空间中相应的目标实体名称之间的相似性。这个相似性使用多模态检索模型进行计算:
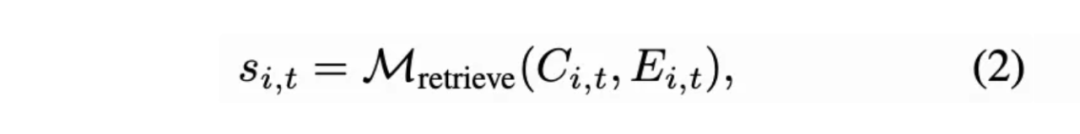
如果置信度超过预定义的阈值,将进入下一阶段。最后,在图像特征空间中评估相似性,得到:
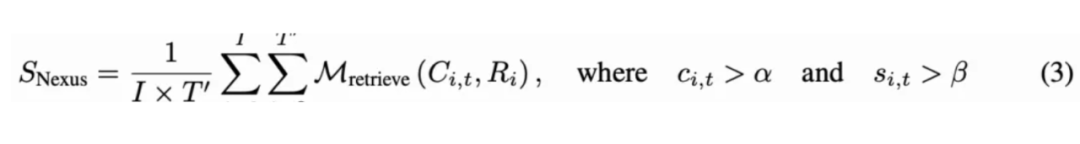
NaturalScore:与现有的以主体为中心的视频基准 [109, 21, 39, 54] 不同,这些基准仅关注主体一致性,还评估生成的主体是否看起来自然,即它是否符合物理规律。
这是由于当前 S2V 方法中普遍存在的“复制-粘贴”问题,在这种情况下,模型盲目地将参考图像复制到生成的场景中,导致即使输出未能与典型人类感知对齐,也会产生高一致性分数。
为了解决这个问题,一个简单的解决方案是使用 AIGC 异常检测模型 [103, 45, 62]。然而,发现开源模型的准确性不理想。
另一种方法是利用开源多模态大语言模型进行视频评分。然而,这些模型表现出较差的指令遵循性能,并容易出现显著的幻觉。因此,使用 GPT-4o 来模拟人类评估者,这提供了更高的准确性和灵活性。
具体而言,微妙地设计了一个基于常识和物理规律的五分评估标准。对于每个视频,均匀地采样 T 帧。这些帧随后输入到 GPT-4o 中,并根据五分量表提供推理过程即最终评分。
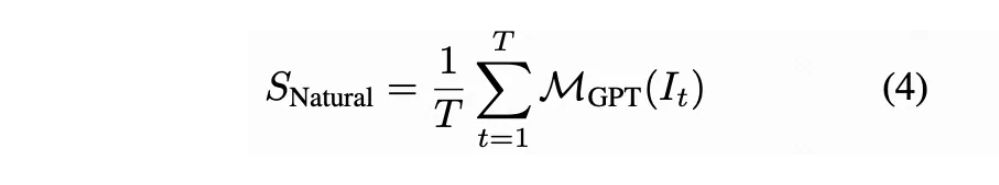
GmeScore:现有方法通常使用 CLIP 或 BLIP计算文本相关性。然而,一些研究,如 [57, 111, 97] 已经识别出这些模型特征空间中的固有缺陷,导致得分不准确。
此外,它们的文本编码器限制为 77 个标记,这使得它们不适合当前基于 DiT 的视频生成模型所偏好的长文本提示。因此,选择使用 GME,这是一个在 Qwen2-VL 上进行微调的模型,能够自然地适应不同长度的文本提示,并产生更可靠的分数。

OpenS2V-5M

数据构建
主体驱动处理。如前所述,现有的大规模视频生成数据集通常仅包含文本和视频,这限制了它们在开发复杂的主体到视频任务中的适用性。
为克服这一限制,本文开发了第一个大规模主体到视频数据集,原始视频来源于 Open-Sora Plan。鉴于元数据包括视频标题,我们最初选择包含人类的视频,因为这些视频通常包含更多的主体。
接下来,根据美学、运动和技术分数筛选出低质量视频,最终得到 5,437,544 个视频片段。在此基础上,遵循 ConsisID 数据 pipeline,我们利用 Grounding DINO 和 SAM2.1 从每个视频中提取主体,生成适合主体到视频任务的常规数据。
最后,为确保数据质量,使用美学和多模态检索模型为参考图像分配美学分数和 GmeScore,使用户能够调整阈值以平衡数据数量和质量。
Nexus 数据构建。现有的 S2V 方法主要依赖常规数据,其中提取的主体通常与训练帧中的视图相同,并且可能不完整,这导致了前文中讨论的三个核心挑战。
这一限制源于直接从真实视频中提取参考图像,导致模型通过将参考图像复制到生成视频上而不是学习底层知识,从而减少了泛化能力。为克服这一问题,引入 Nexus 数据,包括通过跨帧关联以及 GPT-Image-1 构建的两类样本。常规数据与 Nexus 数据之间的比较如下图 5 所示。

数据集统计
OpenS2V-5M 是第一个开源的百万级主体到视频(S2V)数据集。它包含 510 万常规数据,这些数据在现有方法中被广泛使用 [39, 21, 54],以及通过 GPT-Image-1 和跨视频关联生成的 35 万 Nexus 数据。该数据集有望解决 S2V 模型面临的三大核心挑战。

实验
评估设置
评估基线。评估了几乎所有的 S2V(Subject-to-Video)模型,包括四个闭源模型和十二个开源模型。
这些模型涵盖了支持所有类型主体的模型(例如 Vidu、Pika、Kling、VACE、Phantom、SkyReels-A2 和 HunyuanCustom),以及仅支持人物身份的模型(例如 Hailuo、ConsisID、Concat-ID、FantasyID、EchoVideo、VideoMaker 和 ID-Animator)。
应用范围。OpenS2V-Eval 提供了一种自动评分方法,用于评估主体一致性、主体自然性和文本相关性。
通过结合现有的视觉质量、运动幅度和人脸相似度指标(例如 Aesthetic Score、Motion Score 和 FaceSim-Cur),它实现了对 S2V 模型在六个维度上的综合评估。此外,还可以利用人工评估以提供更精确的评估。
实现细节。闭源 S2V 模型只能通过其接口手动运行,而开源模型的推理速度相对较慢(例如 VACE-14B 在单张 Nvidia A100 上生成一个的视频需要超过 50 分钟)。
因此,对于每个基线模型,仅为 OpenS2V-Eval 中的每个测试样本生成一个视频。然后使用上述六个自动化指标对所有生成视频进行评估。所有推理设置均遵循官方实现,并将随机种子固定为 42。
综合分析
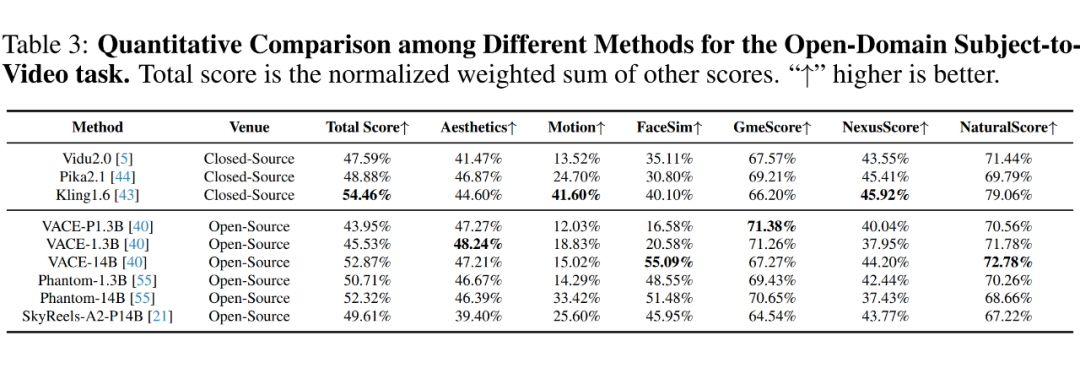
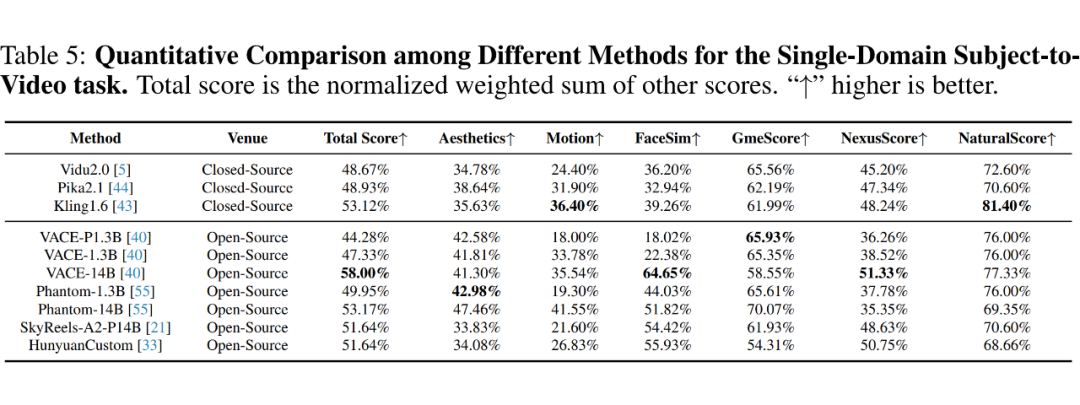
定量评估。首先展示不同方法的全面定量评估,结果显示在下表 3、4 和 5 中。所有模型都能生成具有高视觉质量和文本相关性的视频。
对于开放域 S2V,闭源模型通常优于开源模型。其中,Pika 获得了最高的 GmeScore,表明其生成的视频与提供的指令更为一致。Kling 则生成了保真度和真实感更高的视频,获得了最高的 NexusScore 和 NaturalScore。
虽然 SkyReels-A2 在开源模型中拥有较高的 NexusScore,但其相对较低的 NaturalScore 暗示存在复制粘贴问题。VACE-1.3B 和 VACE-14B 通过扩大参数规模和数据集,在整体生成质量上优于 VACE-P1.3B。
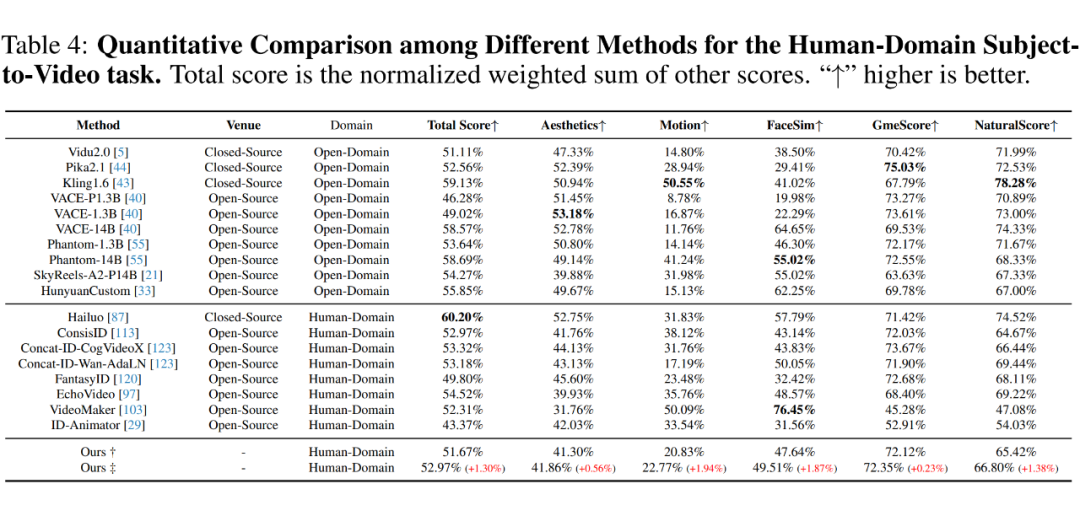
在人类领域的 S2V 任务中,专有模型在保持人类身份方面优于开放域模型,尤其是 Hailuo,其获得了最高的总分 60.20%。
此外,NaturalScore 显示,尽管开源模型如 ConsisID 和 Concat-ID 拥有相对较强的 FaceSim,但仍存在严重的复制粘贴问题。
相比之下,EchoVideo 在开源人类领域模型中获得了最高分。由于 HunyuanCustom 仅开源了单主体版本,我们额外提供了单域场景的结果,如下表 5 所示。
值得注意的是,尽管 HunyuanCustom 在主体保真度方面表现出色,其生成的风格往往呈现出人工特征,导致输出不够真实。
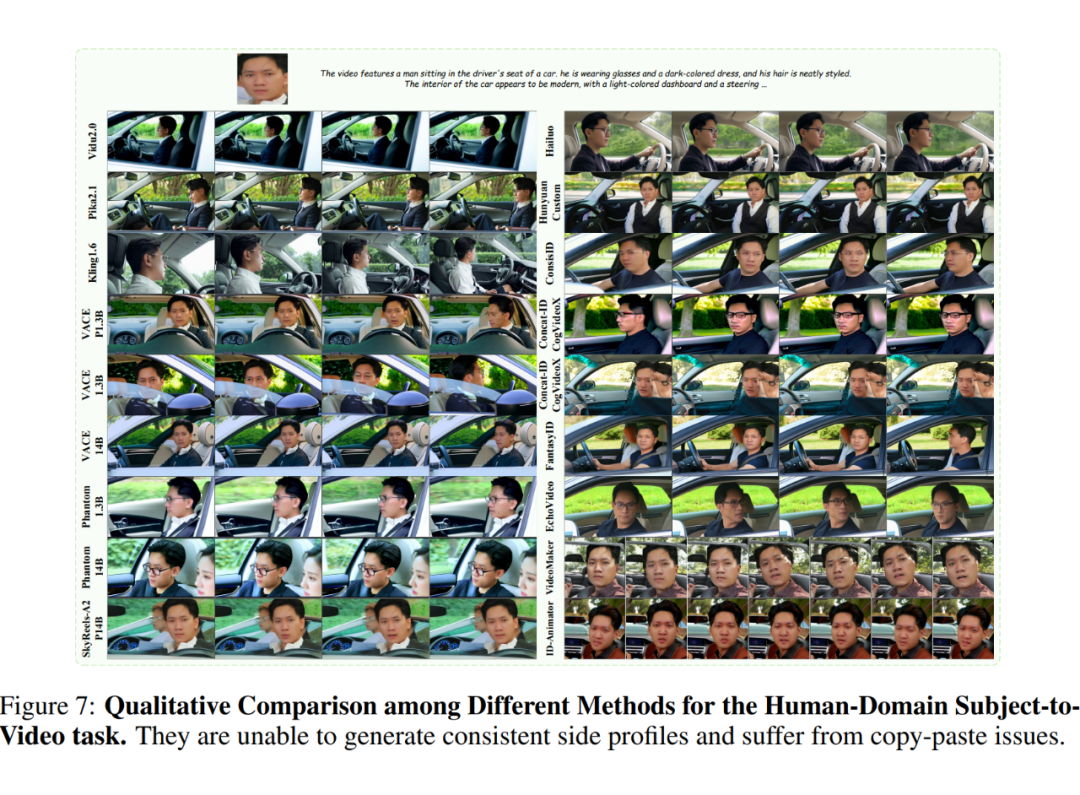
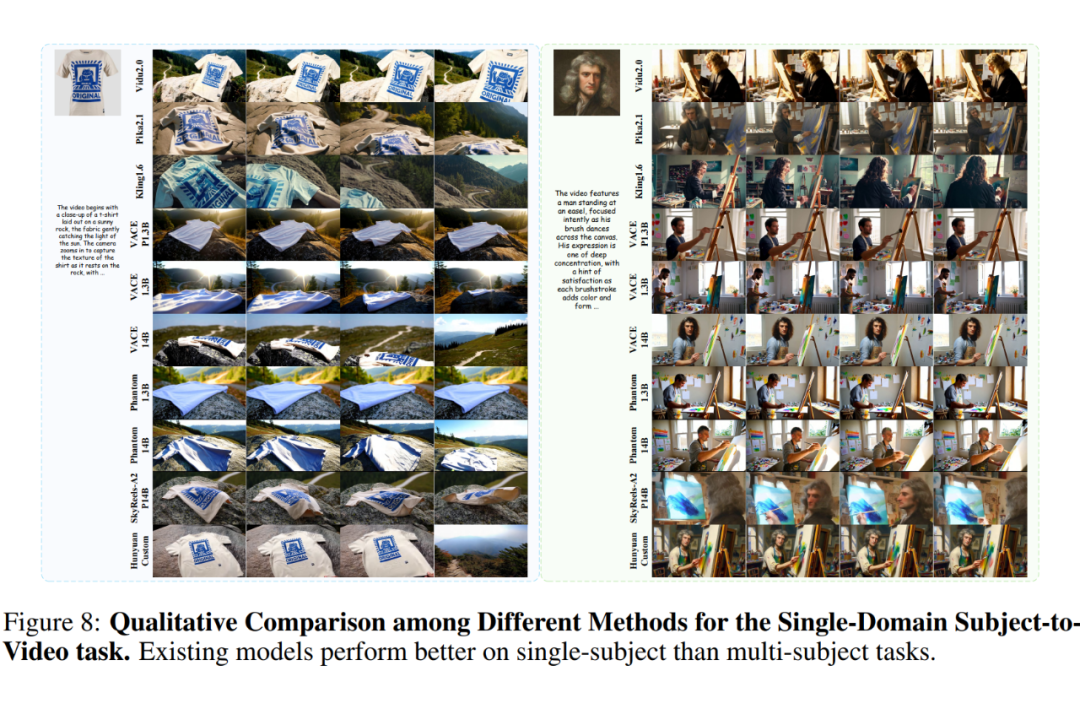
定性评估。接下来,随机选择三个测试数据进行定性分析,如下图 6、7 和 8 所示。总体而言,闭源模型在整体能力方面表现出明显优势(例如 Kling)。以 Phantom 和 VACE 为代表的开源模型正在逐步缩小这一差距。
然而,这两种模型都存在以下三个共同问题:
(1)泛化能力差:某些主体的保真度较低。例如,在下图 6 的案例 2 中,Kling 生成了错误的操场背景,而 VACE、Phantom 和 SkyReels-A2 生成了保真度较低的人物和鸟类;
(2)复制粘贴问题:在图 7 中,SkyReels-A2 和 VACE 错误地将参考图像中的表情、光照或姿态复制到生成视频中,导致输出不自然;
(3)人类保真度不足:在图 6 的案例 2 中,只有 Kling 在视频的前半段保持了人类身份,而其他模型在整个视频中都丢失了大量面部细节。
图 7 显示所有模型都未能准确渲染人物侧脸。此外,观察到:(1)随着参考图像数量的增加,保真度逐渐下降;(2)初始帧可能模糊或直接被复制;(3)保真度随时间逐渐下降。

人类偏好。然后,通过人工交叉验证验证指标的有效性。随机选择与提示语对应的 60 个生成视频,并邀请 173 名参与者进行投票,从而得出评估结果。为提高用户满意度,采用二元分类问卷格式。下图 9(a)展示了自动化指标与人类感知之间的相关性。
显然,三项提出的指标——Nexus Score、NaturalScore 和 GmeScore——与人类感知一致,能够准确反映主体一致性、主体自然性和文本相关性。此外,所提出的指标在人类偏好上与其他指标 [17, 6, 16] 相当。
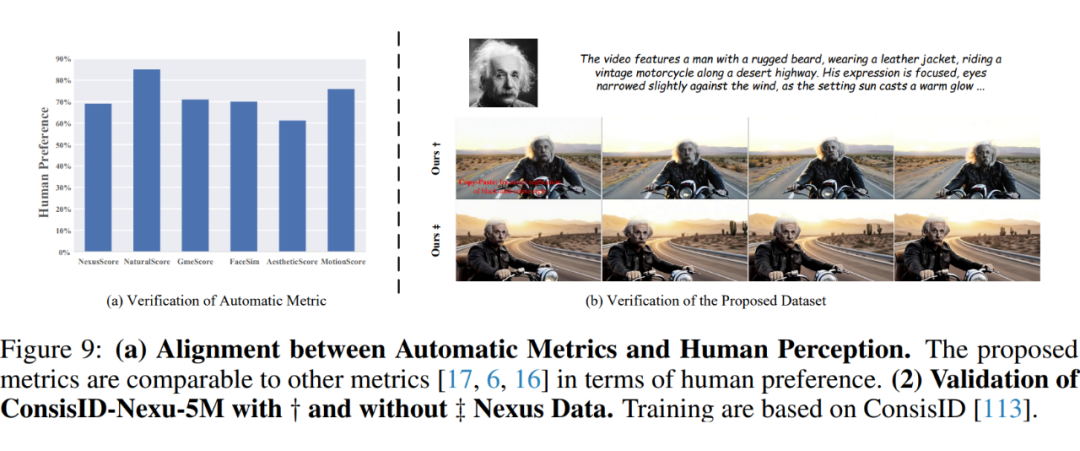
OpenS2V-5M 的验证。最后,为评估 OpenS2V-5M 的有效性与鲁棒性,采用 ConsisID 方法对基于 Wan2.1 1.3B 权重初始化的模型进行微调,仅使用 MSE 损失函数并省略掩码损失。
受限于算力条件,从 OpenS2V-5M 中随机选取 30 万样本进行训练,且仅聚焦于单一人物身份的学习。如图 9(b)所示,实验结果表明:本文数据集成功将文本生成视频模型转化为特定主体生成视频模型,由此验证了所提出的数据集及其数据收集流程的有效性——其中 Nexus Data 发挥了关键作用。
由于模型尚未完成完整训练周期,当前性能未达最优状态,本实验仅作验证用途。

结论
OpenS2V-Eval,第一个专门用于评估主体到视频(S2V)生成的基准。该基准解决了现有基准的局限性,这些基准主要源自文本到视频模型,忽略了诸如主体一致性和主体自然性等关键方面。
此外,提出了三种与人类一致的新自动化指标——NexusScore、NaturalScore 和 GmeScore。还引入了 OpenS2V-5M,这是第一个开源的百万级 S2V 数据集,不仅包含常规的主体-文本-视频三元组,还包括使用 GPT-Image-1 和跨视频关联构建的 Nexus 数据,从而促进社区内的进一步研究,并解决 S2V 的三个核心问题。
(文:PaperWeekly)