

极市导读
本文作者通过分析MTEB排行榜前列的工作,总结出当前embedding模型主要特点,包括使用InfoNCE loss或类似损失函数、多任务训练以及基于大模型微调等,为读者提供了embedding技术发展的最新趋势和思路。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
导读
世界上本没有「不可能」,存在的「不可能」只是自己视角下的「不可能」。——爱工作的小小酥
LLM如何学习更好的embedding?
以往的训练embedding的模型都是以BERT架构为基础,使用MLM损失训练,得到模型可以在各种下游任务上微调,例如分类。
在大模型时代,我们经常采用语言模型损失建模,以预测下一个token的方式进行训练,这样训练的模型在很多任务上都超过了以前的模型,但这样的模型怎么提取embedding特征,用于其他检索相关任务呢?
最近注意到MTEB排行榜上多了很多基于现有的大模型训练的模型,在此整理一下embedding技术的发展,以备不时之需,但读的时候发现并不是所有论文都使用了LLM。
阅读了排行榜前排的工作,发现现在embedding模型主要有以下特点:
1、使用INfoNCE loss。
在之前训练BERT的时代,如果进行预训练,一般是用MLM任务,可能最近大家评测的很多任务或者大模型RAG的兴起,导致检索任务变得额外重要。下面的损失函数基本是用INfoNCE,个别使用了cosent loss(比较类似INfoNCE,是一个可以用于排序的loss)。
2、多任务训练。
使用INfoNCE loss进行训练的话,需要构建(query,正样本,负样本)三元组。对于检索类的任务,当然很容易构造,而对于分类、聚类的任务,就要想各种办法构造出这种格式,在下面的论文中主要涉及两种方式:
-
将分类、聚类的类别标签作为数据匹配的正样本或者负样本。(这个相对较多) -
将分类、聚类的同类别其他数据作为正样本,不同类别的其他数据作为负样本。
其次,在多任务训练的时候,经常针对不同任务采取不同的损失函数,或者尽管都采用INfoNCE,对于非检索任务,一般不再采用in batch negative。
3、Matryoshka Representation Learning
俄罗斯套娃表示训练方法,其因为可以同时训练多个维度的向量表示,又不会影响性能的优势,在目前的embedding模型中经常被采用。(而且很多都是最大到1972)
4、多阶段训练
可能借鉴于目前LLM的训练流程,目前很多不使用LLM的embedding模型,也采用了多阶段进行训练,一般是划分为2阶段,先使用低质量文本对训练,然后使用人工标注的检索类数据集训练。
5、困难负样本挖掘
困难负样本挖掘一直是对比学习的重点,在下面的几篇论文中,很多也很强调困难负样本的重要性,但主要方法也比较受限,主要是以下几点:
-
单独训练一个embedding模型,给负样本打分,选择高分数据作为困难负样本(用的较多) -
动态在训练过程中更换困难负样本,计算方式类似上面
6、使用合成数据
在大模型时代,经常使用LLM造数据,在embedding任务中,大家也是进行各种prompt工程构建检索类数据,主要是分为两阶段构造,先让模型「头脑风暴产生主题」,然后「根据主题生成三元组数据」。
7、文本表示方法
在这个方面和之前差不多,主要有以下几种:
-
使用最后一层特征的 mean pooling -
使用一个特殊的token。[CLS]或者[EOS] -
后面接一个attention pooling 层。
Piccolo2
Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
https://arxiv.org/abs/2405.06932
概要
这篇论文核心点主要有:
-
将不同的任务使用「不同的损失函数」进行训练,为检索、排序、分类、聚类配置不同的loss,从而兼顾每一种任务的特点,在各个任务上都可以达到最优的效果。 -
在训练过程中加入Matryoshka Representation Learning,从而训练出动态维度的向量。其中最高维度到1972。 -
使用合成数据训练。 -
负样本挖掘。使用piccolo-base-zh使用相似度排名在50-100的随机15个作为困难负样本。
模型结构依旧是bert,训练完的参数量为300M。
训练方式
(1)Retrieval and Reranking Loss
对于检索和排序任务,采用标准的INfoNCE loss,并使用in batch negative。
(2)Semantic Textual Similarity(STS) and PairClassification Loss
在这种任务中,其label一般不是一个绝对的值,例如相似度分数,如果将这种任务单纯的表示为INfoNCE中的三元组的形式,就丢失了这部分信息,因此,对于这些任务,作者使用了cosent loss。具体原理可参考下面的链接:
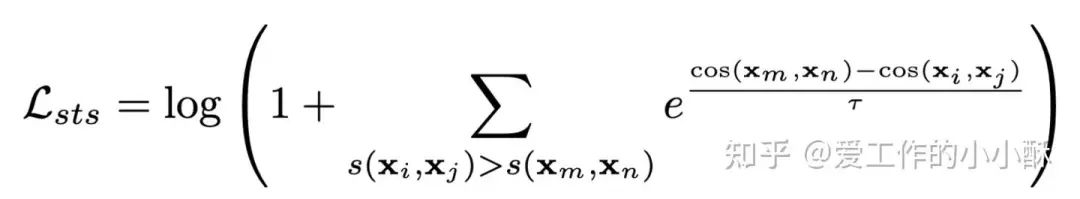
CoSENT(一):比Sentence-BERT更有效的句向量方案 – 科学空间|Scientific Spaces
https://kexue.fm/archives/8847
(3)Classification and Clustering Loss
在分类和聚类任务中,没有样本对的概念,而是一个标签。作者对于这种任务,是将其label和数据作为一个正样本pair,当前数据和其他label作为负样本pair,采样标准的INfoNCE loss进行训练,但不再使用in batch negative。
最终的损失函数为上述3个loss相加。
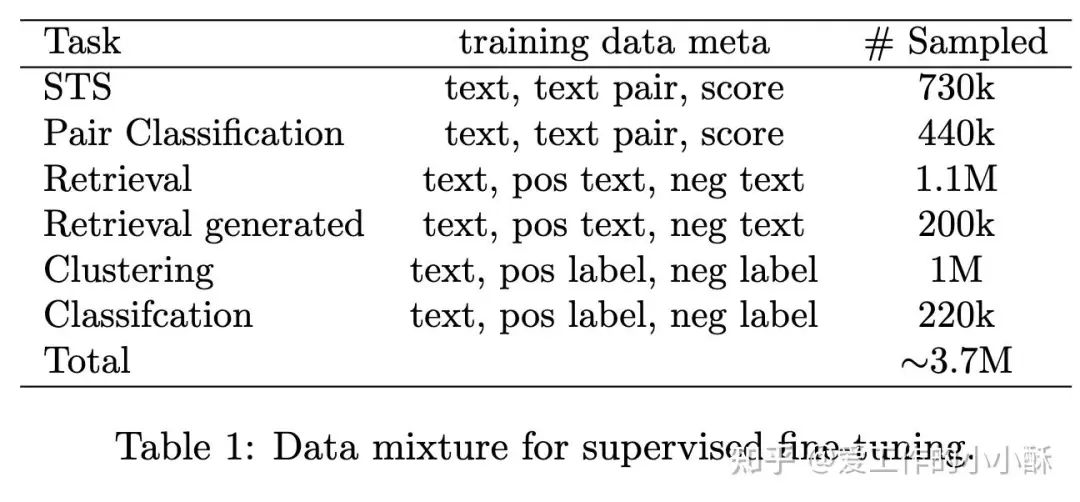
合成数据
为了构造出丰富多样的检索相关的数据,作者分为2个步骤进行,分别为生成话题、根据话题生成样本对。最后生成了200k的数据,下面为整个训练过程中采用的数据量。
Conan-embedding
Conan-embedding: General Text Embedding with More and Better Negative Samples
https://arxiv.org/abs/2408.15710
概述
困难负样本一直是对比学习训练过程中的一个关键点,困难负样本的好坏有时会非常影响模型的性能。现有的挖掘困难负样本的方法基本集中在训练之前,经常使用训练好的embedding模型计算负样本的相似度,将高相似度的负样本筛选出来作为困难负样本。但这样一次性决定困难负样本的方法是最优的吗?模型训练过程中会不会改变负样本的难度?
在这篇论文就是集中在这个问题上研究的,设计了一种在训练过程中挖掘负样本的方法,可以根据模型训练的状态选择合适的困难负样本进行学习。其次,为了进一步扩大负样本的数量,提出了Cross-GPU Batch Balance Loss (CBB)。
在模型结构上,依旧采用bert,使用的是BERT large模型,并且也使用了Matryoshka Representation Learning (MRL) 技术训练动态embedding,最大到1792。
训练方式
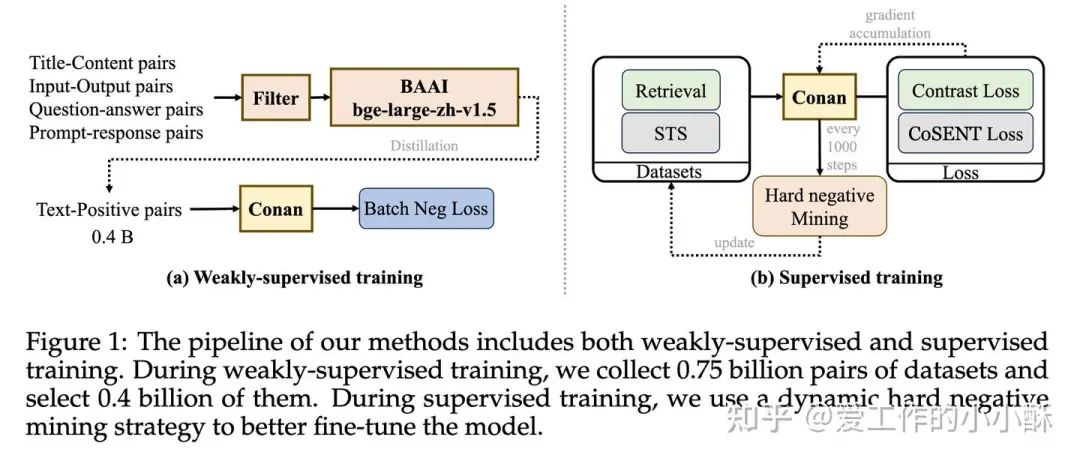
第一阶段,使用bge-large-zh-v1.5筛选出高质量数据(阈值高于0.4),这里的数据是常规文本对和合成数据,总共有0.75 billion。采用标准的INfoNCE loss 进行训练,并使用in batch negative。
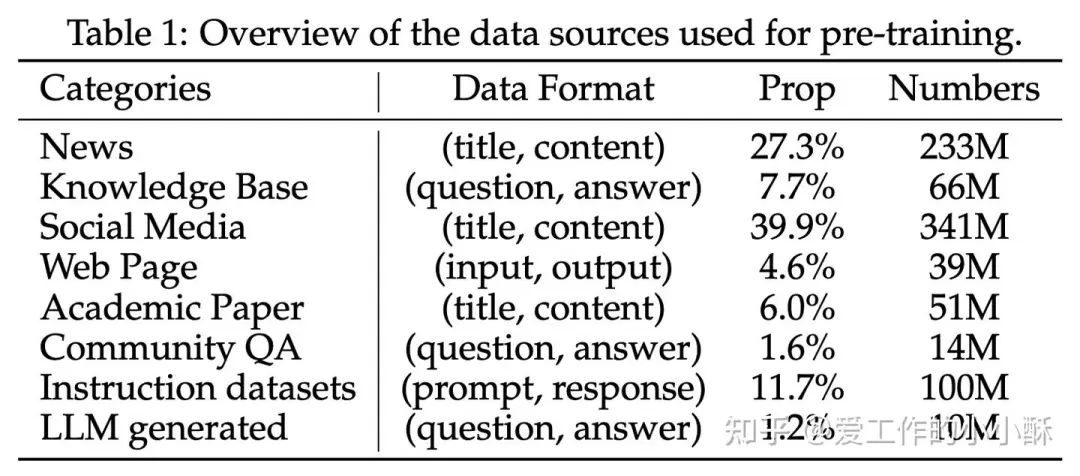
第二阶段,主要使用检索和 STS (semantic textual similarity)任务数据,并采用不同的损失函数,其中检索使用标准的INfoNCE loss,STS使用CoSENT loss。
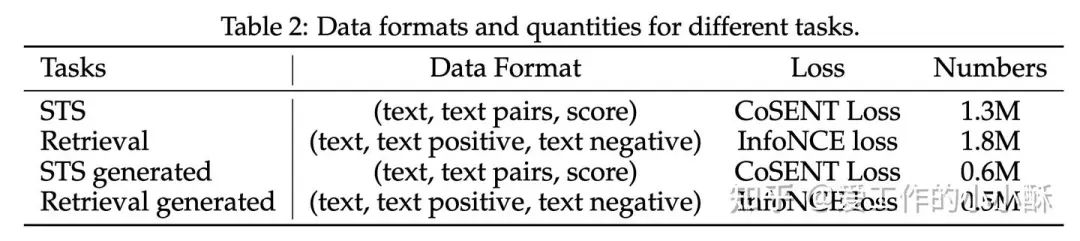
动态困难负样本
为了在训练过程中动态的选择困难负样本,作者在每100step进行检查一次,查看当前困难负样本乘以1.15是否小于原始的score并且绝对分数小于0.8,如果存在,则进行更换困难负样本。
对于第 轮,更换的时候,选择 到 之间的负样本,其中 为困难负样本的个数。(不懂为啥这样选??)
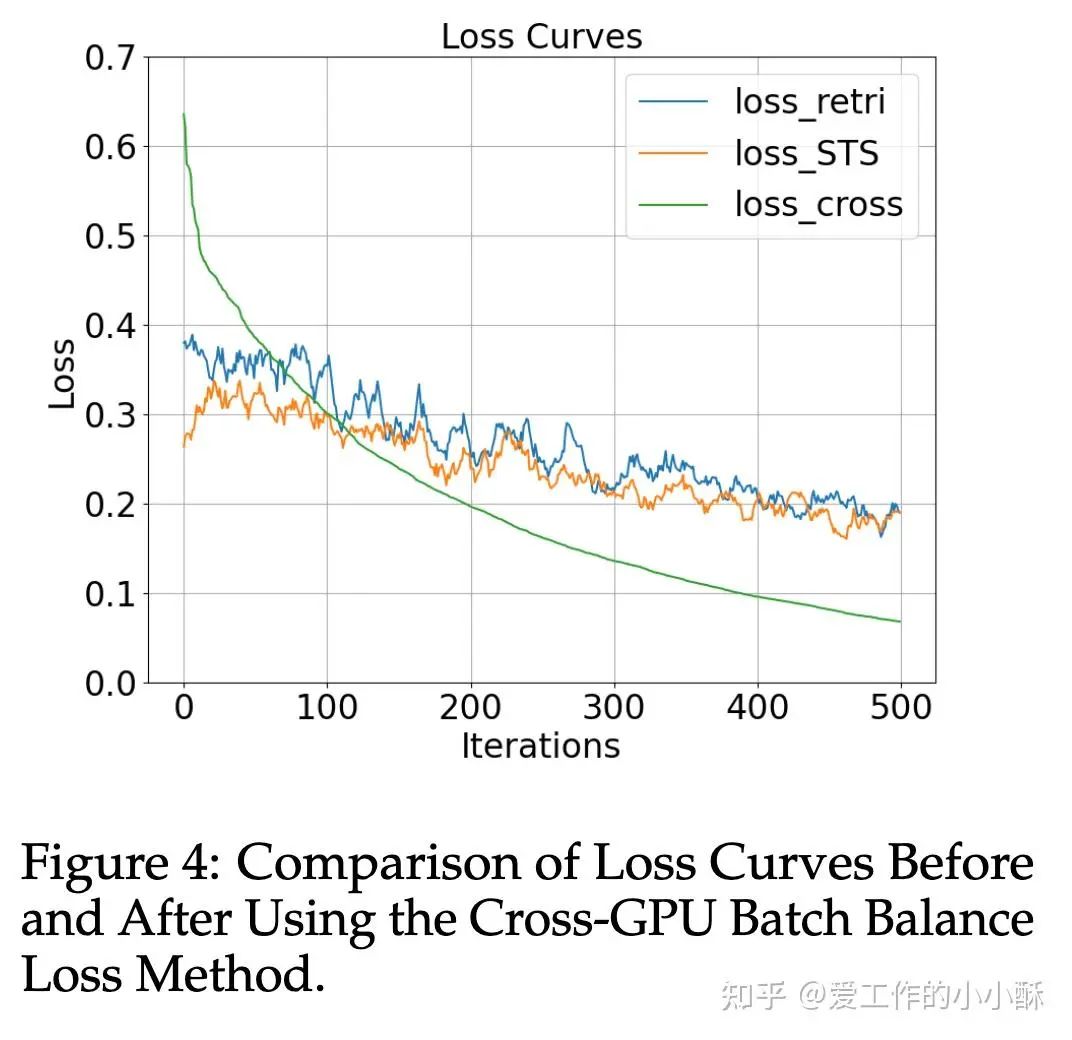
Cross-GPU Batch Balance Loss
由于训练过程中针对不同任务采用了不同的损失,在以往的训练过程中,是每一个batch都采样同一来源的数据,但这样训练会导致不稳定性,具体可看下图,cross是合并后的损失。
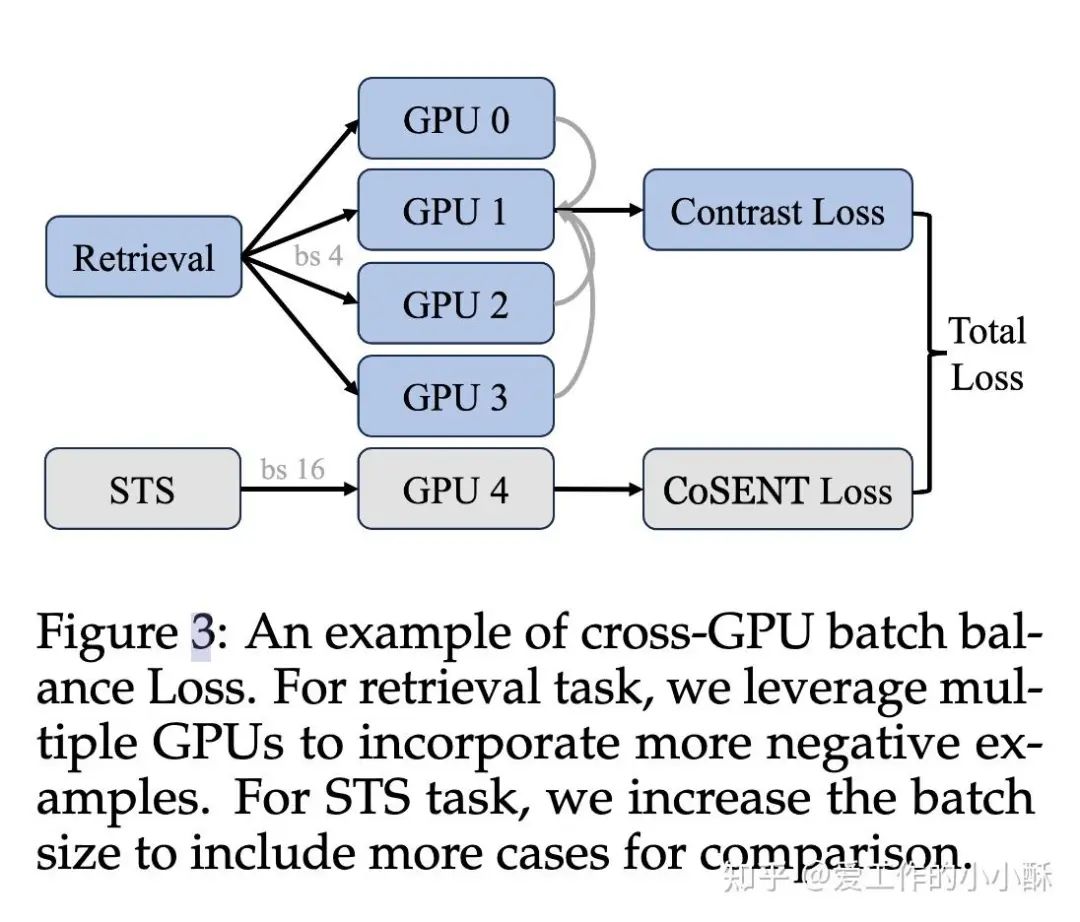
因此,作者将两种任务合并训练,损失为两者的相加,使用不同的gpu来平衡batch的大小。
GTE
Towards General Text Embeddings with Multi-stage Contrastive Learning
https://arxiv.org/abs/2308.03281
概要
阿里GTE系列模型的第一个版本,和以往训练bert不一样的地方在于:
-
收集大量数据 -
分为两阶段进行训练 -
采用升级版对比学习损失,扩大了负样本 -
更关注检索任务
模型结构依旧采用bert,感觉主要是靠大数据量造就了一个比较好的效果。
模型结构
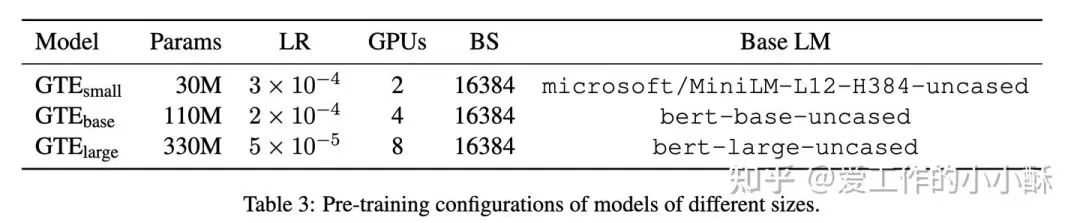
模型的整体结构没有作出改变,加载预训练的MiniLM、bert分别训练出3种大小的模型,分为small、base、large,不同规模的模型参数如下:
损失函数
均衡采样
在预训练阶段由于混合了多种来源的数据,而不同来源的数据数量存在较大差异,为了缓解这种多种数据源数据严重不均衡的问题,使用了基于原始数据量的采样。具体来说,在每一轮的训练过程中,从每个来源采样的概率为其在所有数据中所占的一个大致比例,具体公式如下:
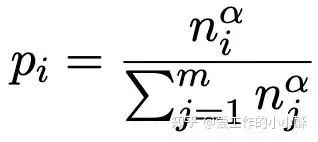
对于上述公式中的 ,论文中取的是0.5。并且为了不让模型「偷懒」,确保每个batch内都是相同类别的数据(后续的mGTE也沿用了这种采样方法)。
升级版InfoNCE
对于(query, document) 这样的数据对来说,原始的InfoNCE是in batch negative,即每一个query和同batch内的其他document构成负样本。因此,在常规的对比学习任务中,一般是batch越大越好,这样样本见到的负样本会更多,会更有利于模型学习,但batch又收到机器显存的限制。
因此,在这篇论文中,在不增大batch的情况下,为了增大每个样本的负样本数量,作者在原始InfoNCE loss的基础上做了进一步的改进,即不再仅仅使用「单向的负样本」,而是使用了「双向的in batch query」和「document negative」。
操作过程也比较简单,可以想一想对于一个batch内的所有数据来说,一条(query, document) 是不是和其他所有的(query, document) 都可以形成负样本,并且不限于(query, document) 这种格式。
那么,我们就可以在原始(query, document) 的基础上扩展(query, query) 和(document, document) 也构成负样本。
具体可以看一下下面的公式,对于一个包含(query, document) 的batch数据:
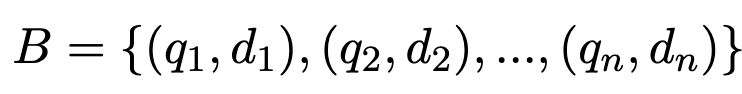
改进版的InfoNCE的负样本构成如下:
-
当前query和其他document(原始InfoNCE的负样本) -
当前query和其他query(新增) -
其他query和当前document(新增) -
其他document和当前document(新增)
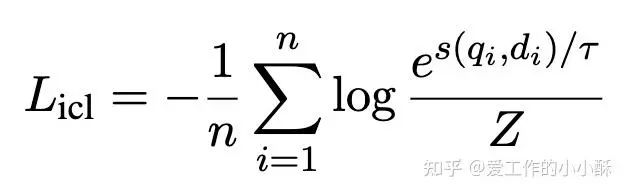
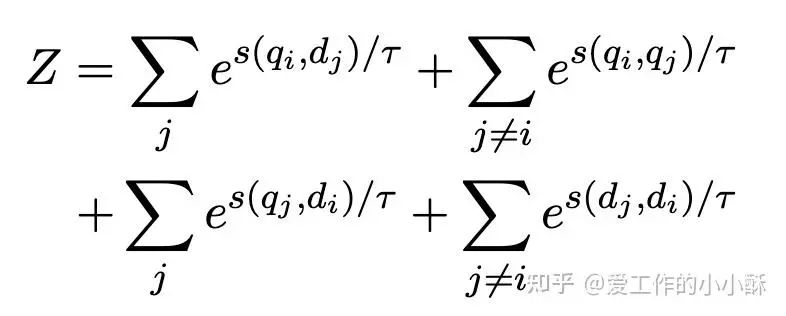
训练方式
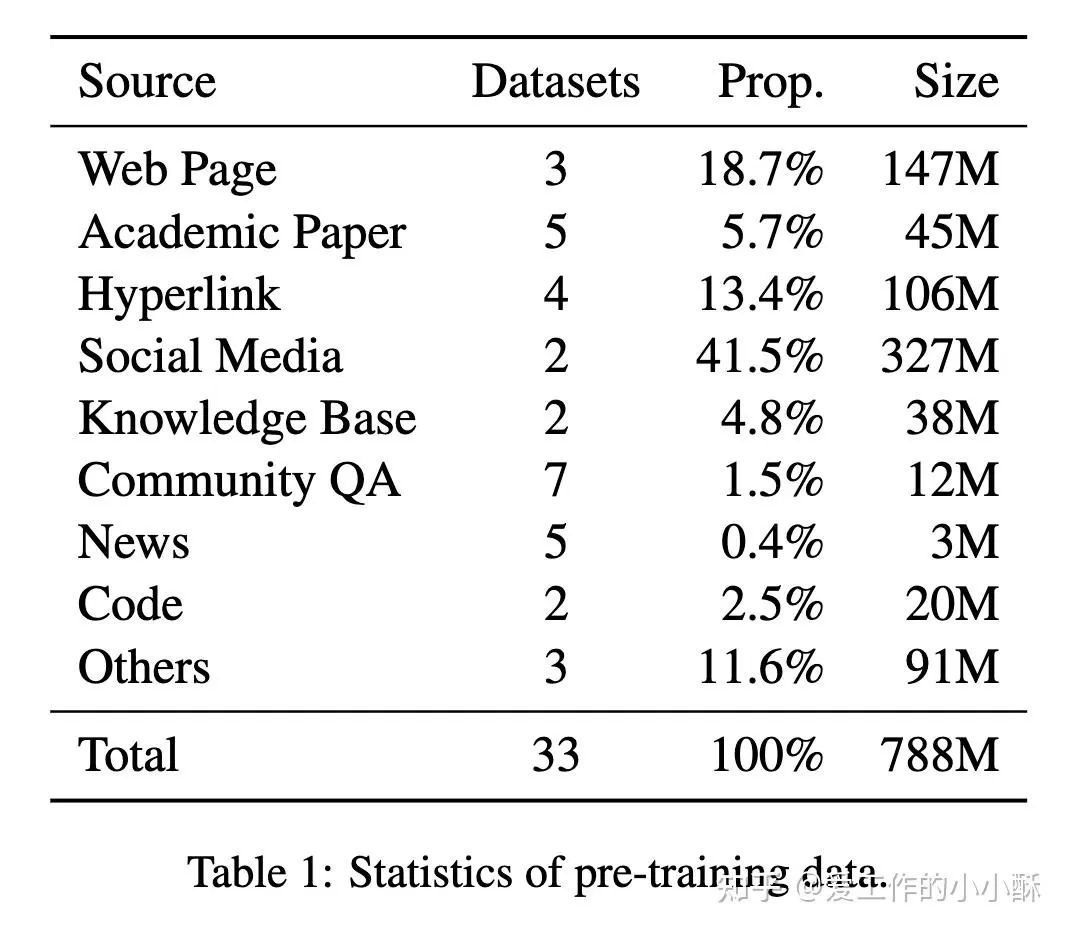
第一阶段 无监督预训练
整篇论文主打多种数据、大批量数据训练,此部分就将各种来源的text pair数据进行了混合,数据量总共为788M,具体比例如下:
第二阶段 监督微调
为了在下游检索任务上得到更好的效果,此部分使用更高质量的人类标注pair数据,并使用其他的检索器抽取困难负样本,包括web search (e.g., MS MARCO),open-domain QA (e.g., NQ), NLI (e.g., SNLI), fact verification (e.g., FEVER), paraphrases (e.g., Quora),总共大约3M pairs。
mGTE
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
https://arxiv.org/abs/2407.19669
概要
从模型的名称mGTE就可以看出,这篇论文主要着重点在「多语言」上,除此之外,论文还着重强调在「长文本」上的优越性。
和以往的BERT系列模型不同,此模型支持8192长度(之前都是512长度),并采用较为复杂的多阶段训练流程,同样和GTE类似,使用了大量的数据,最后不仅训练出召回模型,同时也得到了一个优秀的reranker模型。
由于在此时这个阶段,对于如何学习更好的embedding问题?已经出现了各种各样的技术,而在这篇论文中我们可以看到的主要有可以同时训练出多个维度embedding的Matryoshka Embedding方法(俄罗斯套娃embedding方法)、增强训练效率的unpadding技术、以及扩展长文本的Rotary Position Embedding编码技术。
模型结构
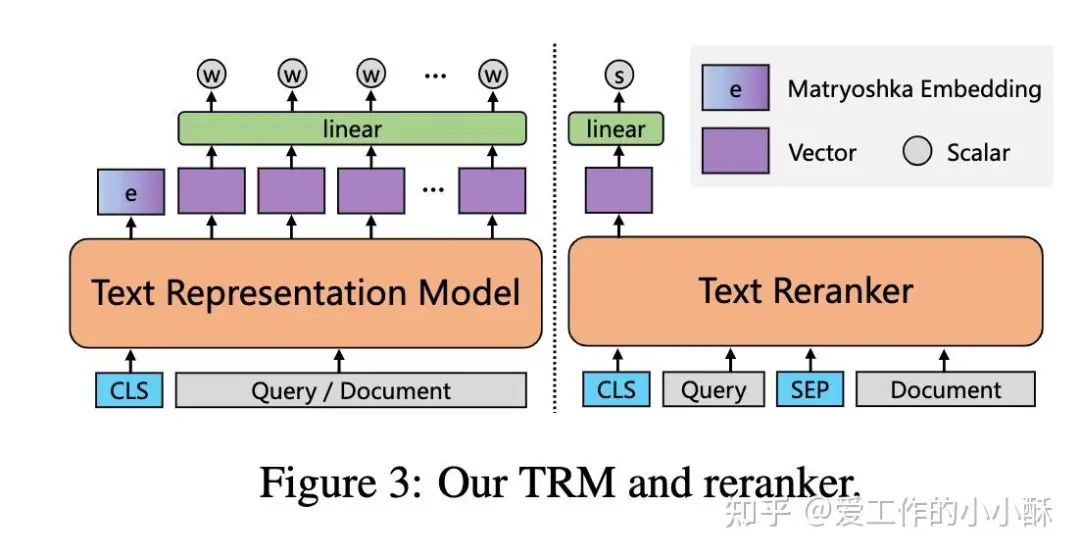
在模型结构上依旧采用常规的BERT结构,在其中加入了很多技巧性的工作。整体而言,如下图所示,总共产生了5个模型。这5个模型由一个复杂的训练流程串联起来,最终使用的主要是检索模型(TRM)和精排模型(reranker)。
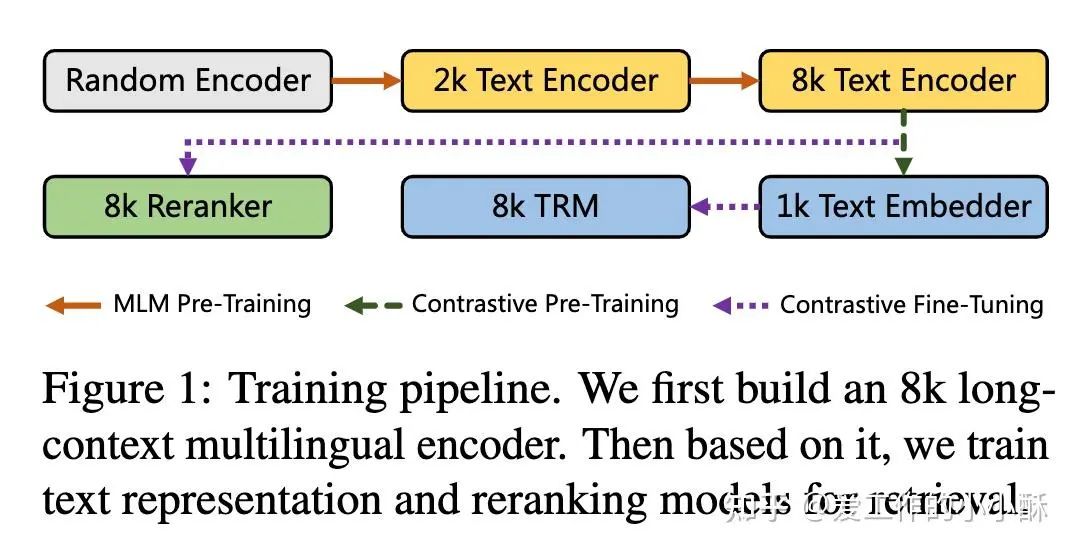
虽然训练流程较长,但差异性并不是很大,下面先进行简短的总结一下:
-
2k Text Encoder 和 8k Text Encoder 采用相同的数据和训练方法,只是输入的最大长度及个别训练参数不一样。并且采用以往bert使用的MLM损失进行训练。 -
1k Text Embedder 是向检索任务过度的一个模型,采用常规infoNCE进行训练。 -
8k TRM和8k Reranker采用相同的数据和训练损失,只是加载的基础模型不同(从图中也可以看出),且输入方式不同(毕竟一个双塔一个单塔)。
Text Encoder&Text Embedder
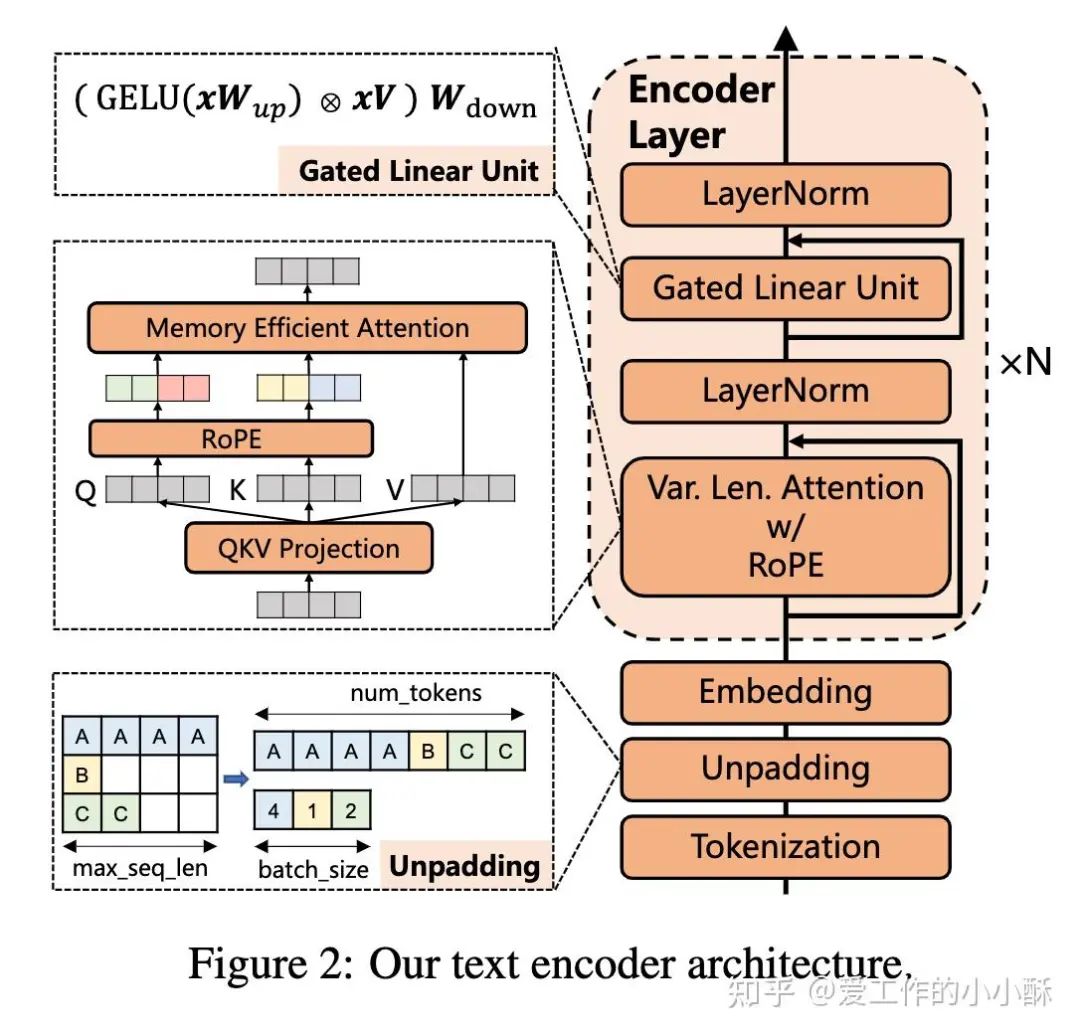
从bert之后,已经出现了很多如何更好的学习embedding的新技术,在这篇论文中主要用到有
-
大模型经常采用的Rotary Position Embedding编码方法可以扩展到训练未见过的长度 -
unpadding技术可以更有效的训练 -
为了使用FlashAttention,将bert中的FFN改为gated linear unit (GLU)。
各种技术的原理可以再去查找相关资料,本文不再赘述,下面给出2篇unpadding相关的论文。
A Bidirectional Encoder Optimized for Fast Pretraining
https://mosaicbert.github.io/
https://arxiv.org/pdf/2208.08124
TRM&Reranker
对于检索和排序模型而言,整体的模型结构和上述类似,只不过是输入的方式不同。
在检索模型中,query和document是分别输入,使用CLS token向量作为整体的特征表示。
在精排模型中,query和document是拼接输入,同样使用CLS token向量作为整体的特征表示。
同样的,在微调这个阶段,在上述预训练的基础上,也额外使用了很多embedding的各种技术,包括Matryoshka Embedding方法(俄罗斯套娃embedding方法)、可以增强长文本能力的Sparse Representation loss。
训练方法
Text Encoder
在此部分,主要是为了增强模型对文本的理解能力,以及扩展长文本能力。因此,采用了常规的MLM的损失函数,将mask比例设置为30%,并使用了课程学习的训练方法,将文本长度从2k扩展到8k。
由于这篇论文主打「多语言」,因此在整个训练语料上加入了各种各样语言以及来源的数据,在这一阶段中,总共包括75种语言数据,总token数为1028B。
除此之外,在训练过程中,采用了一个采样的小技巧。为了平衡采样不同语言的数据,以防数据过多的数据被训练更多次,首先计算出每种语言所占的比例,然后采用下述多项式分布的方式进行采样,并且确保一个batch内是同一种来源的数据。
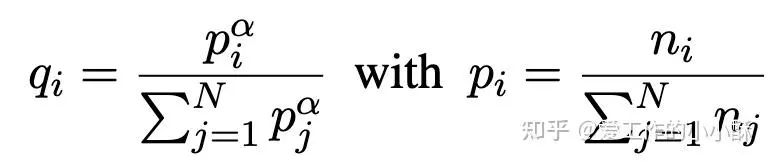
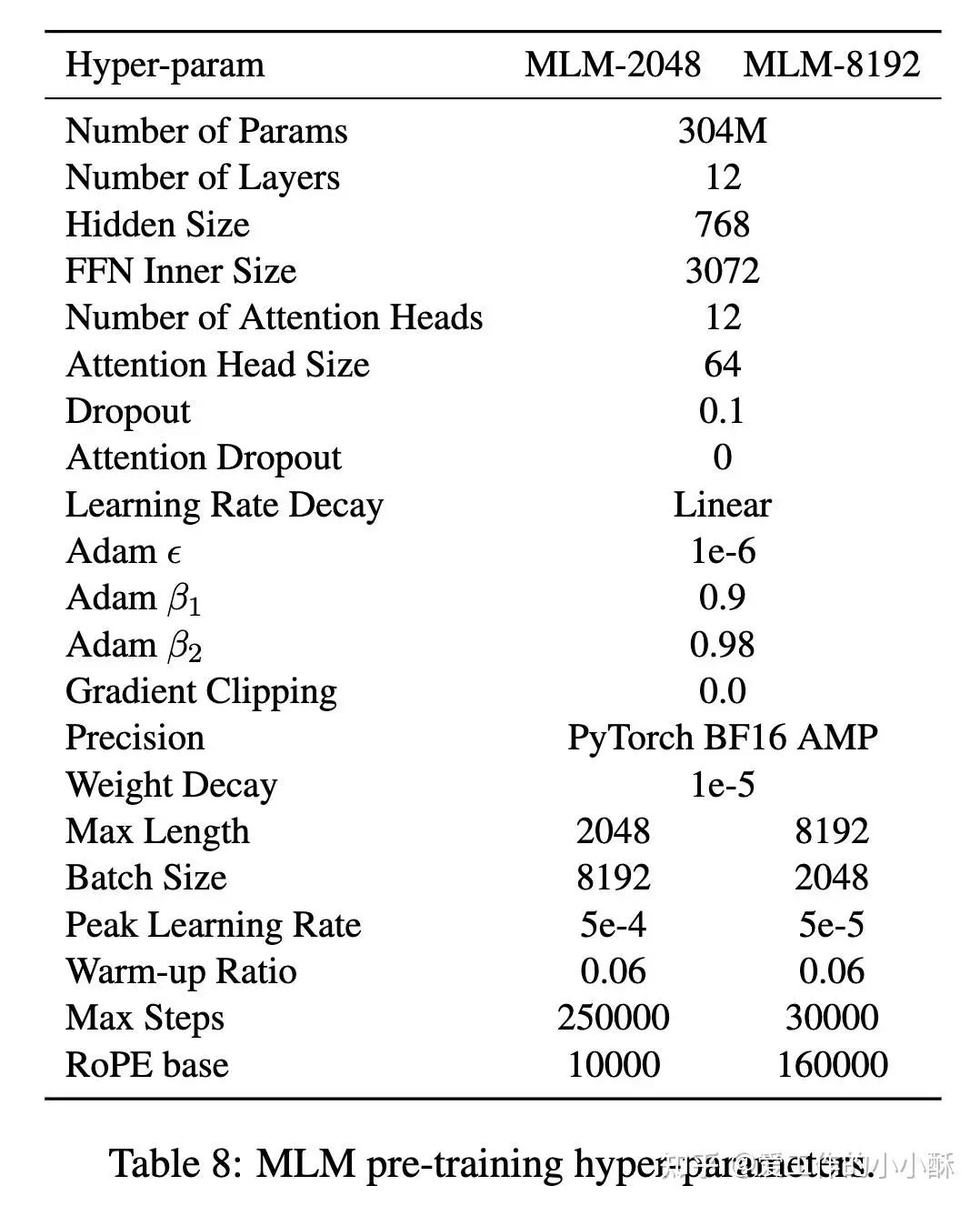
在这一过程中的训练参数如下:
Text Embedder
通过上述MLM损失训练后的模型,可以对文本有较好的语义理解能力,但在检索任务中可能效果没有那么好。而对于目前针对检索任务训练的各种召回和排序模型而言,基本采用对比学习的方式。
因此,为了增强模型在下游检索任务上的效果,作者同样采用对比学习损失做了继续预训练(CPT),损失函数为InfoNCE loss和in batch negative。
训练数据同样包括了各种语言各种来源的数据,主要有英文数据对、中文数据对、多语言、交叉语言指令和翻译数据对,总共2,938.8M pairs。
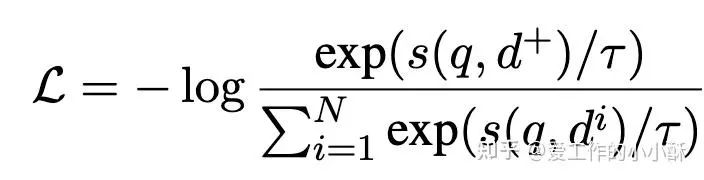
TRM&Reranker
得到一个适合检索的预训练模型之后,已经可以很好的做检索相关的任务了,但还不是一个reranker模型,无法做到精确排序。因此,在上述模型的基础上,作者进一步筛选高质量的pair数据,使用更贴合这个场景的训练损失,以得到更优的检索和排序模型。
这里的TRM和reranker训练过程大体一致,只是采用的预训练模型不一样,TRM使用1k Text Embedder作为基础模型,reranker使用8k Text Encoder 作为基础模型(官方也尝试使用1k Text Embedder,但无增益)。两者采用的训练数据如下:
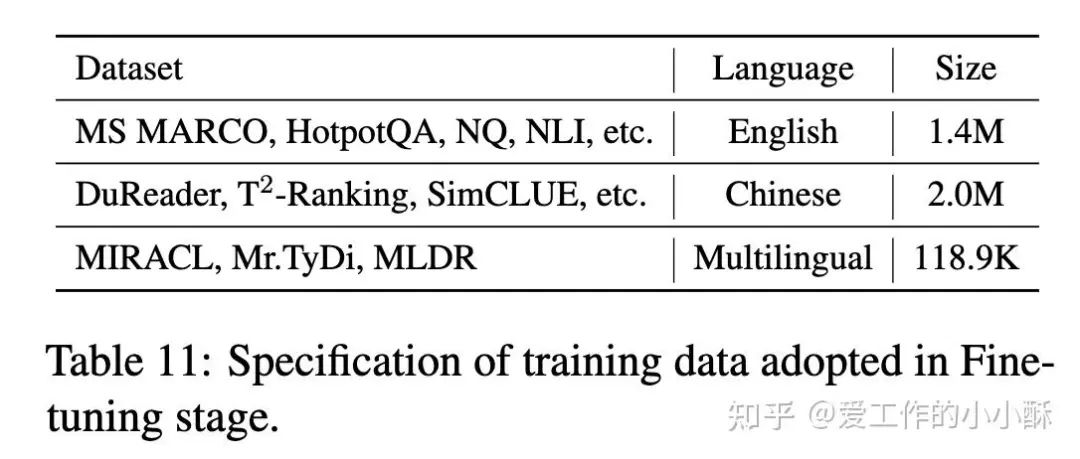
真个微调过程中,在标准的infoNCE 损失的基础上,使用Matryoshka Embedding方法(俄罗斯套娃embedding方法)得到动态的embedding维度,使用可Sparse Representation loss进一步增强长文本能力。
(1)Matryoshka Embedding方法
原始的embedding模型中,输出是一个固定维度,例如768,最后使用768这个向量计算一个loss。在推理的时候,同样只能使用768维度的向量,无法压缩到512或者扩展到更高维度(除了重新训练模型)。
Matryoshka Embedding方法即是为了解决这种问题而提出的,这个直译「俄罗斯套娃embedding方法」。意思是将原先的768维度缩小为多个维度,例如[32, 64,128, 256,768],训练的时候每一个维度后面单独使用一个线性分类器进行转换一下,然后分别计算损失,最后所有损失相加得到最终的损失。
Matryoshka Representation Learning
https://arxiv.org/abs/2205.13147
(2)Sparse Representation方法
这个方法来源于BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation(https://arxiv.org/abs/2402.03216)。
在标准的INfoNCE loss的计算过程中,我们需要计算一个query和document的相似度,这里一般采用余弦相似度或者内积,在这个方法中,主要是对这个相似度计算方法进行改变的,具体来说,为每个token计算一个权重
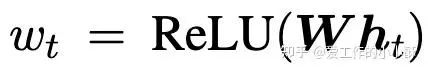
然后计算「每个pair中相同的token的权重乘积和」作为当前pair的相似度,替换掉标准INfoNCE中的相似度计算方式。整个微调过程中的损失为:
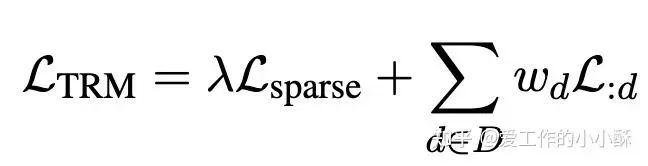
其中,前一部分为上述的Sparse Representation loss,第二部分为Matryoshka Embedding 的loss。
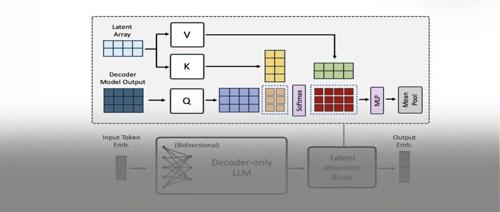
NV-Embed
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
https://arxiv.org/abs/2405.17428
概述
LLM学习embedding表示的方法都有什么?
目前很多论文基本将最后一个
因此,在这篇论文中,提出一个Latent Attention Layer对LLM最后的embedding进一步编码,以得到信息融合程度更高的embedding表示。
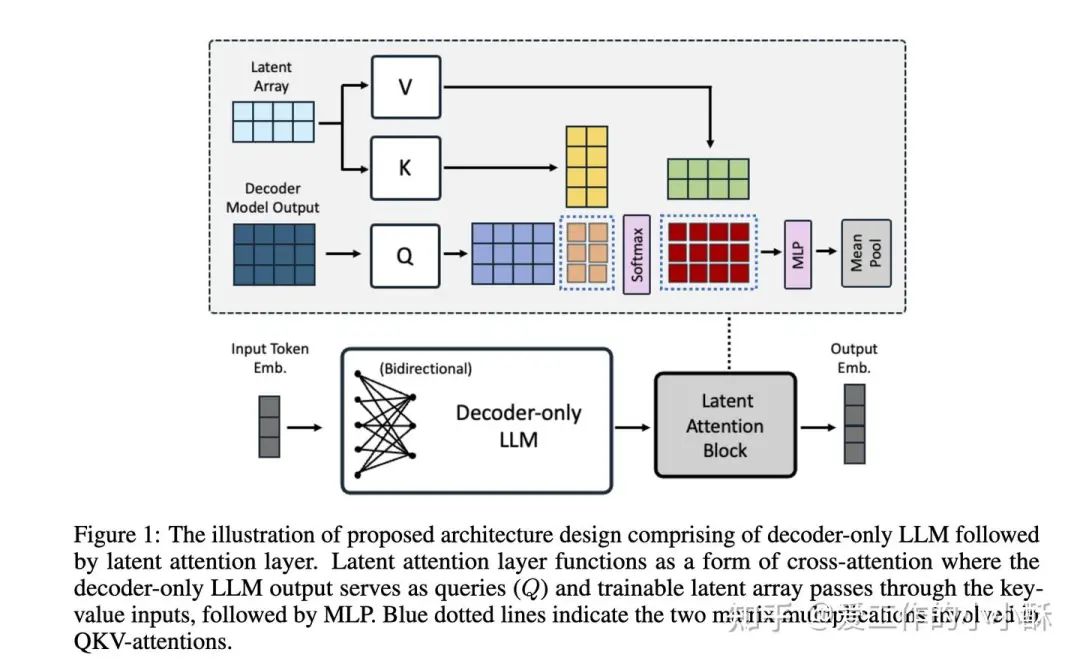
那模型的其他设置有什么特殊的地方吗?
基本没有了,在训练方式上,和常规模型比较类似,采用2阶段训练方式。loss为和标准的INfoNCE,模型使用Mistral-7B,并使用lora进行训练,设置rank=16,alpha=32。
并且作者强调自己没有使用合成数据。
样本构造方式
对于(query,document)数据对,只在query前面加上指令,document前面不添加。后续也有工作指出推理的时候都可以添加,不会导致不一致。
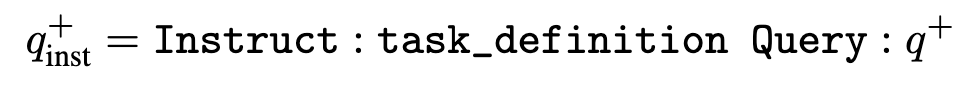
训练方式
(1)第一阶段
采用公开检索数据,并使用in batch negative进行训练,训练之前使用单独训练的embedding 模型筛选高质量数据。
(2)第二阶段
这一部分采用非检索数据集,主要包括分类和聚类数据集,从MTEB英文训练集中筛选的各种分类数据集。为了将这种数据转为(query,document)数据对,作者按照标签进行归类,将同类别的数据作为正样本,不同类别的样本作为负样本(其他工作是将label作为匹配的数据)。
Improving Text Embeddings with Large Language Models
Improving Text Embeddings with Large Language Models
https://arxiv.org/abs/2401.00368
概要
现有的训练embedding表征的模型常常采用大批量的数据,2阶段方式进行训练。这篇论文不再使用那么复杂的流程,只使用合成数据,并且只有一个阶段训练流程,就达到了有竞争力的效果。
模型配置
和以往的LLM embedding模型差不多,同样使用Mistral-7b进行lora训练,并将lora设置为16。
损失函数依旧采用标注的INfoNCE loss和in batch negative。
最后训练的时候加入一些带标注数据,总共1.8M。
合成数据构造方法
为了构造出具有较强多样性的数据,作者将任务归为2类进行设计prompt,分别为非对称任务和对称任务。但都是使用gpt3.5-Turbo和gpt4进行生成。
(1)非对称任务
非对称任务主要包括短-长匹配、短-短匹配、长-短匹配、长-长匹配。对于这些子任务,分别设计prompt。并将生成数据的流程拆分为2步,先生成task名称,再针对task生成相应的数据。
(2)对称任务
作者将这部分任务分为monolingual semantic textual similarity (STS) 和 bitext retrieval。对于这种任务,直接使用1步生成相应的数据,具体可以看下面的示例。
为了进一步增强数据的多样性,在prompt构造的过程中,随机选择生成的长度和生成的语言,最终构造出500k数据。

GRIT
Generative Representational Instruction Tuning
https://arxiv.org/abs/2402.09906
概要
一个模型可以兼容生成和embedding任务吗?
常规大模型基本是以生成方式进行建模,如果要借用大模型架构构建embedding模型,一般是将生成损失改为INfoNCE,但这样建模的模型就失去了生成能力。
这篇论文就从这个角度出发,不丢弃任何一方,同时使用INfoNCE和生成损失训练模型,让大模型兼顾生成能力和embedding能力。
模型配置
但混合两种任务一起训练会有一个问题,对于embedding任务来说,一般都是采用双向注意力机制,让模型充分学习token之间的语义关系;但对于生成任务来说,一般采用 causal attention,后面的token只能看到前面的token。因此,作者将不同任务的attention矩阵进行了更改,并且embedding任务取最后一层特征的mean pooling作为最后的特征向量,具体的模型结构如下:
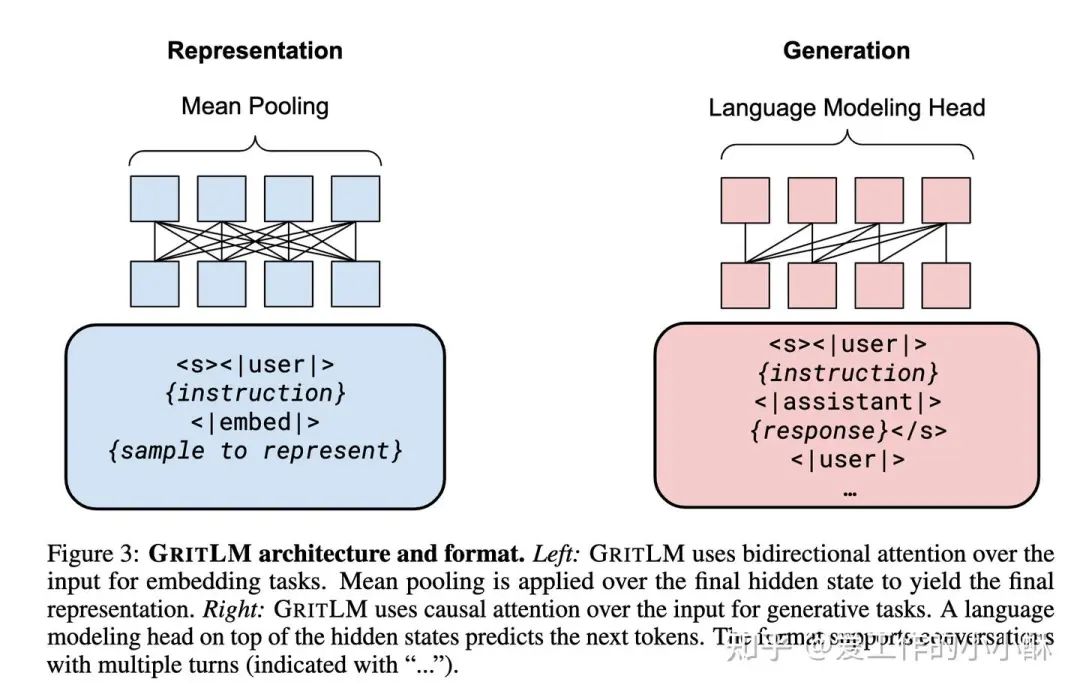
使用的基础模型和其他的模型差不多,也是Mistral 7B,同时也训练出了Mixtral 8x7B,都是全量训练(前面有的是lora训练)。
损失函数
对于embedding任务,采用标准的INfoNCE loss,并使用in batch negative。对于生成任务,采用保准的生成损失(预测下一个token),两者加权得到最终的损失。
Reranker
虽然模型没有单独为排序任务训练,但也进行了reranker的评测,借鉴的是另一篇论文:arXiv reCAPTCHA(https://arxiv.org/abs/2304.09542),将召回的结果,拼接到prompt中,借助模型的生成能力进行排序,具体使用的prompt格式如下:

总结
随着大型语言模型(LLM)的发展,模型的通用能力逐渐增强。通常,这些模型通过混合各种任务数据进行训练,并采用多阶段训练策略。
通过阅读上面的论文,发现embedding模型也在朝这个方向发展,开始采用混合多种任务数据的训练方式。然而,由于嵌入模型的特殊性,不同任务通常使用不同的损失函数。并且根据数据的质量或其与下游任务的契合程度,将数据分为两批,进行多阶段训练。
在写这篇文章的时候,突然想到一个问题:知乎文章和视频号是不是很类似,都是选题、调研、整理、归纳的过程。而这整个过程是特别考验一个人的学习能力的,如何快速找到核心点,学明白,然后整理成别人很容易理解的样子?有时候并不是一时半会可以掌握的。
(文:极市干货)