

作者|王晓磊 郑博文 李炳黔
机构|中国人民大学
最近,推荐系统正迎来一场“慢思考”革命。传统推荐算法往往依赖快速匹配用户历史行为,却难以捕捉深层次的偏好与情境需求;而新一代研究通过引入“慢思考”技术——模拟人类多步推理与动态反思的过程,正在突破这一瓶颈。我们将聚焦基于“慢思考”的推荐系统前沿论文,深入剖析它们如何通过慢思考的方式,显著提升推荐的准确性、多样性和可解释性。这些研究不仅为推荐系统注入了“深思熟虑”的能力,更为个性化服务开辟了新的技术路径。
1. DeepRec: Towards a Deep Dive Into the Item Space with Large Language Model Based Recommendation
链接:https://arxiv.org/pdf/2505.16810
简介:推荐系统领域正积极探索大语言模型的应用。然而,现有的基于LLM的推荐系统往往未能充分结合大语言模型(如世界知识和推理能力)与传统推荐模型(如推荐领域专业知识和高效性)的互补优势,从而限制了其对物品空间的深度探索。
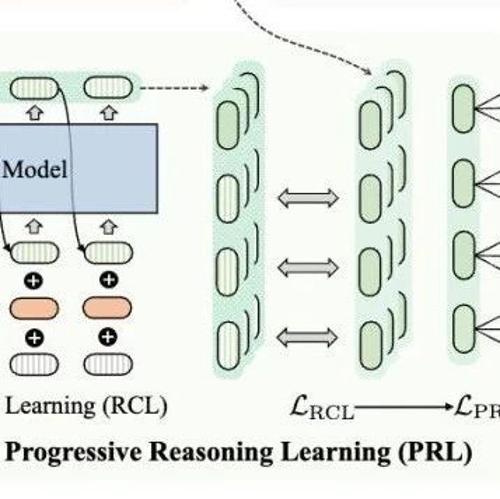
针对这一局限,本文提出DeepRec——一种支持LLMs与TRMs自主多轮交互的新型LLM推荐系统,旨在实现对物品空间的深度探索。该系统通过多轮交互机制运作:每轮交互中,LLMs分析用户偏好并与TRMs协同检索候选物品;经过多轮交互后,LLMs对检索结果进行排序生成最终推荐。本文采用了基于强化学习(RL)的优化框架,并从三个维度创新设计:
-
基于推荐模型的数据生成:引入偏好感知TRM,通过与LLMs交互构建轨迹数据;
-
面向推荐的层次化奖励:设计包含过程级与结果级的双重奖励函数,分别优化交互过程和推荐效果;
-
两阶段RL训练策略:第一阶段引导LLMs与TRMs有效交互,第二阶段专注推荐性能提升。
该系统通过LLMs与TRMs的协同进化,既保留了传统推荐系统的高效性,又融入了大语言模型的深层推理能力,为推荐系统的知识融合与决策优化提供了新范式。
2. Slow Thinking for Sequential Recommendation
链接:https://arxiv.org/pdf/2504.09627
简介:为构建高效的序列推荐系统,已有大量方法致力于建模用户历史行为。尽管这些方法表现有效,但它们均遵循相同的”快思考”范式——通过编码用户历史交互生成用户表征,并直接与候选物品表征进行匹配。然而传统轻量级推荐模型的能力局限,使得这种一步式推理范式往往导致次优的性能。
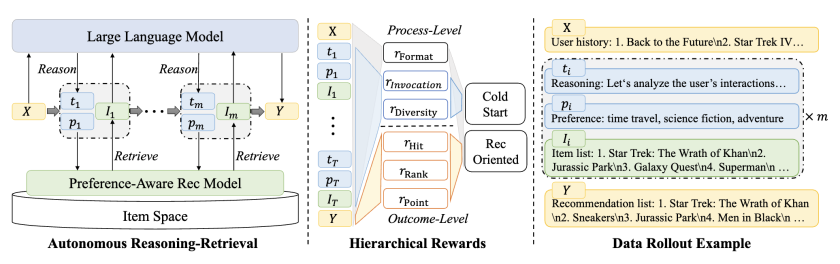
为解决这一问题,本文提出名为STREAM-Rec的新型”慢思考”推荐模型。该模型能够分析用户历史行为,生成多步骤的推理过程,并最终输出个性化推荐。本文重点攻克两个核心挑战:(1) 识别推荐系统中合适的推理模式;(2) 探索如何有效激发传统推荐模型的推理能力。为此,本文设计了三阶段训练框架:第一阶段通过大规模用户行为数据预训练模型,学习行为模式并捕获长程依赖;第二阶段设计迭代推理算法,通过渐进优化预测结果标注合适的推理轨迹,用于模型微调;第三阶段应用强化学习进一步提升模型泛化能力。
3. LARES: Latent Reasoning for Sequential Recommendation
链接:https://arxiv.org/pdf/2505.16865
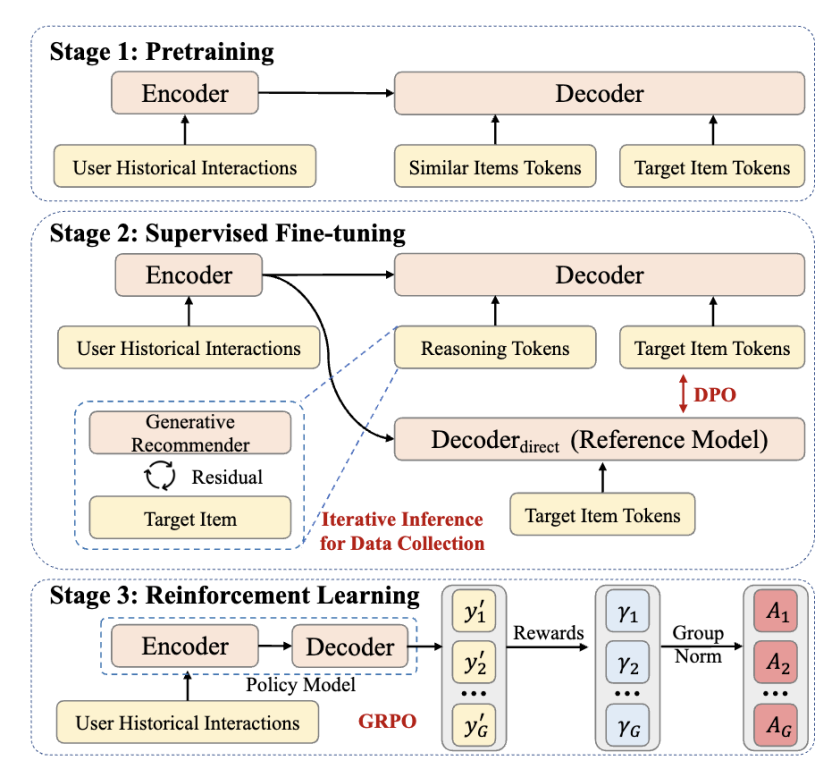
简介:序列推荐系统在建模用户行为序列以预测偏好的实际应用中日益重要。然而,现有序列推荐方法主要依赖非推理范式,这可能限制模型的计算能力并导致次优的推荐性能。为突破这些局限,本文提出LARES,通过深度循环潜在推理提高参数计算密度,从而增强模型的表示能力。LARES采用循环架构,可在不增加参数复杂度的前提下灵活扩展推理深度,有效捕捉动态且复杂的用户兴趣模式。LARES的关键创新在于,在每一步隐式推理中优化所有输入表征,以提高计算利用率。为充分释放模型的推理潜力,LARES设计了两阶段训练策略:
-
自监督预训练(SPT):结合轨迹级对齐和步骤级对齐目标,使模型无需额外标注数据即可学习面向推荐的潜在推理模式;
-
强化后训练(RPT):利用强化学习(RL)激发模型探索能力,进一步优化推理性能。
在真实场景基准测试中,LARES展现出卓越性能,并与现有先进模型无缝兼容,显著提升其推荐效果。

4. Reason4Rec: Large Language Models for Recommendation with Deliberative User Preference Alignment
链接:https://arxiv.org/pdf/2502.02061
简介:尽管当前将大语言模型(LLMs)与推荐任务对齐的研究已展现出巨大潜力并取得显著成效,但现有的对齐大模型与推荐目标的方法仅聚焦于优化模型直接生成用户反馈,而缺乏深思熟虑的推理过程。为突破这一局限,Reason4Rec创新性地提出了Deliberative Recommendation任务,将用户偏好的显式推理作为额外的对齐目标。基于此,Reason4Rec开发了”推理驱动推荐框架”(Reasoning-powered Recommender),该框架通过分步骤利用用户语言化反馈来增强推理能力,从而实现审慎的用户偏好对齐。具体而言,该框架采用协作式分步专家机制,并为每个专家模块量身定制训练策略。该框架在提升推荐预测准确性和推理质量方面均展现出卓越性能。
5. Reason-to-Recommend: Using Interaction-of-Thought Reasoning to Enhance LLM Recommendation
链接:https://arxiv.org/pdf/2506.05069
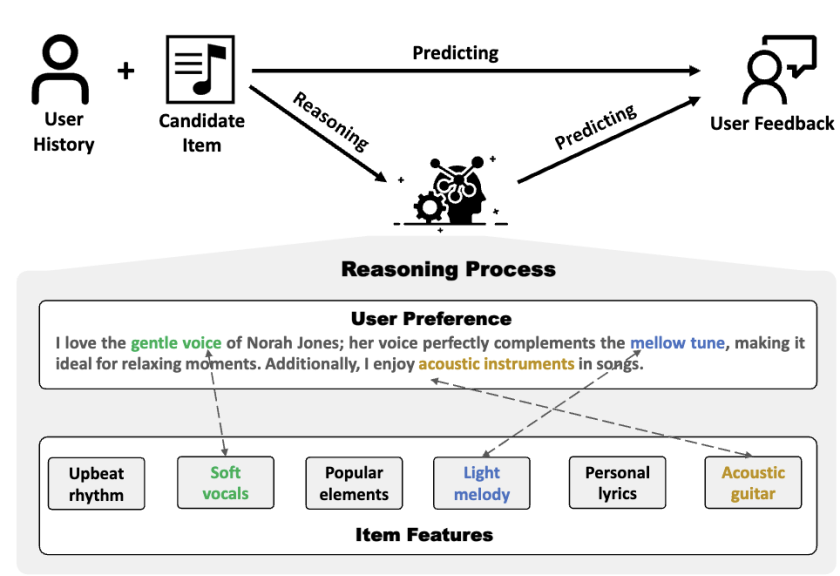
简介:随着大语言模型(LLMs)技术的快速发展,其强大的语义理解能力和基于提示的灵活性使其在推荐任务中的应用日益受到关注。现有研究主要通过将用户-物品交互数据或元数据编码至提示词来实现推荐功能。与此同时,得益于测试时扩展技术和强化学习的赋能,LLM的推理能力已在数学、编程等具有明确定义推理路径和客观正确性验证信号的领域取得显著成功,既实现了高性能输出又保证了良好的可解释性。然而,由于用户反馈的隐含特性以及交互数据缺乏推理监督信号,直接将这类推理技术迁移至推荐任务的效果并不理想。
为突破这一局限,本文提出了推理增强型推荐框架R2Rec。该框架创新性地从用户-物品图中采样交互链,并通过渐进式掩码提示策略将其转化为结构化的”交互思维链”——其中每个思维节点都代表基于用户-物品交互情境的渐进式推理。这种转化使LLM能够基于隐含交互模式模拟逐步决策过程。为内化这种推理能力,R2Rec设计了两阶段训练流程:监督微调阶段通过高质量标注轨迹传授基础推理技能,强化学习阶段则基于奖励信号提供可扩展的监督,既优化推理过程又缓解显式交互推理数据的稀缺问题。显式推理链的引入,揭示了LLM的决策过程,显著提升了模型的可解释性。
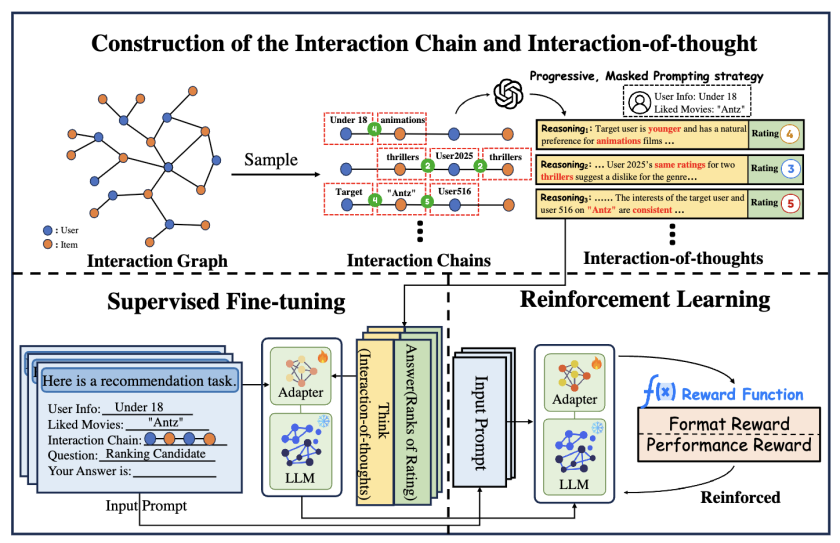
6. Think Before Recommend: Unleashing the Latent Reasoning Power for Sequential Recommendation
链接:https://arxiv.org/pdf/2503.22675
简介:序列推荐旨在通过挖掘用户历史交互的时序规律预测下一项物品,在现实推荐系统中具有关键作用。然而,现有方法普遍采用直接前向计算范式——仅用序列编码器的最终隐状态作为用户表征。本文认为,这种计算深度受限的推理范式难以捕捉用户偏好的复杂演化特性,尤其对长尾物品缺乏细粒度理解,最终导致性能瓶颈。
为此,本文提出ReaRec——首个面向推荐系统的推理时计算框架,通过隐式多步推理增强用户表征。具体而言,ReaRec采用自回归方式将序列末状态循环输入推荐模型,同时引入推理位置嵌入技术,实现原始物品编码空间与多步推理空间的解耦。此外,本文设计两种轻量级推理学习方法:集成推理学习(ERL)和渐进推理学习(PRL),以充分释放模型的推理潜能。
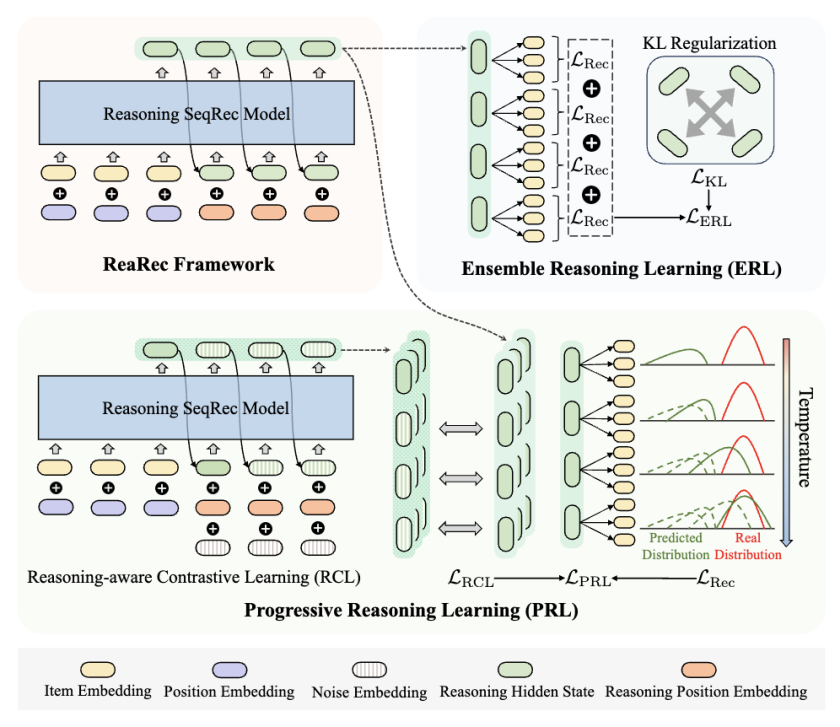
7. Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
链接:https://arxiv.org/pdf/2503.24289
简介:本文提出REC-R1——一个通过闭环优化连接大语言模型(LLMs)与推荐系统的通用强化学习框架。与提示工程(prompting)和监督微调(SFT)不同,REC-R1直接利用固定黑盒推荐模型的反馈来优化LLM生成,既无需依赖GPT-4o等专有模型生成的合成SFT数据,也避免了数据蒸馏所需的高昂成本。为验证REC-R1的有效性,本文在产品搜索和序列推荐两大典型任务上进行了评估。实验结果证实了REC-R1的性能优势和持续适应性。REC-R1为LLM与推荐系统的协同进化提供了免蒸馏、可扩展的新范式。
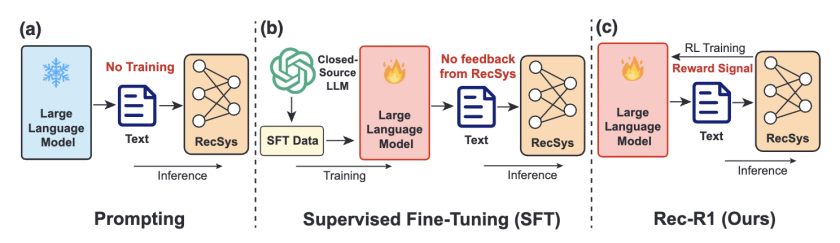
8. Reinforced Latent Reasoning for LLM-based Recommendation
链接:https://arxiv.org/pdf/2505.19092
简介:大语言模型(LLMs)在复杂问题求解中展现出的卓越推理能力,激发了研究者对其在推荐系统偏好推理中应用的广泛兴趣。现有方法通常依赖显式思维链(CoT)数据进行微调,但面临两大实践瓶颈:(1)推荐场景中高质量CoT数据难以获取;(2)生成CoT推理导致的高延迟。为此,本文探索了一种创新路径——从显式思维链推理转向紧凑、信息密集的潜在推理。这种方法通过少量潜在令牌即可完整捕获推理过程,既无需生成显式CoT,又显著提升推理效率。
基于此,本文提出推荐强化潜在推理框架(LatentR3)——首个不依赖任何CoT数据的端到端训练方案。该框架采用两阶段训练策略:先通过监督微调初始化潜在推理模块,再采用纯强化学习训练,基于规则化奖励设计促进探索。本文的RL实现基于改进版GRPO算法,既降低训练计算开销,又通过连续奖励信号提升学习效率。
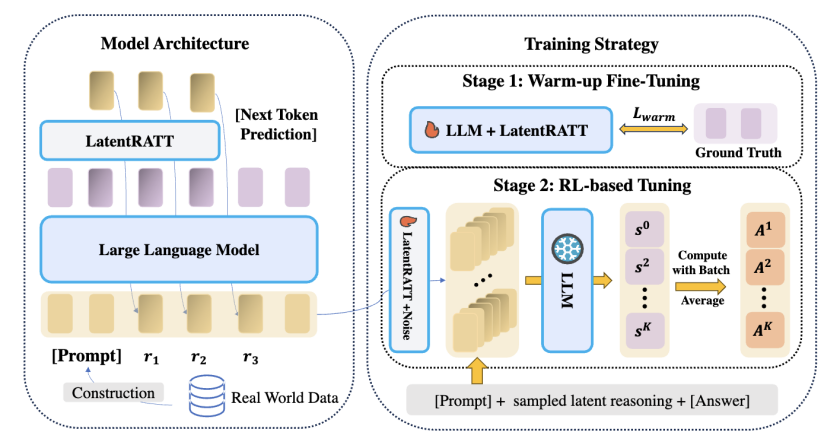
9. RecLLM-R1: A Two-Stage Training Paradigm with Reinforcement Learning and Chain-of-Thought
链接:https://arxiv.org/pdf/2506.19235
简介:传统推荐系统长期面临”信息茧房”效应、外部知识利用率低、模型优化与业务策略迭代脱节等核心痛点。针对这些挑战,本文提出RecLLM-R1——一个融合大语言模型(LLMs)并借鉴DeepSeek R1方法论的创新推荐框架。该框架通过精心设计的数据构建流程,将用户画像、历史交互和多维度物品属性转化为LLM可理解的自然语言提示。随后采用两阶段训练范式:第一阶段通过监督微调(SFT)赋予LLM基础推荐能力;第二阶段引入GRPO强化学习技术,结合思维链(CoT)机制,通过可灵活定义的奖励函数引导模型进行多步推理与全局决策,同步优化推荐准确性、多样性及定制化业务目标。
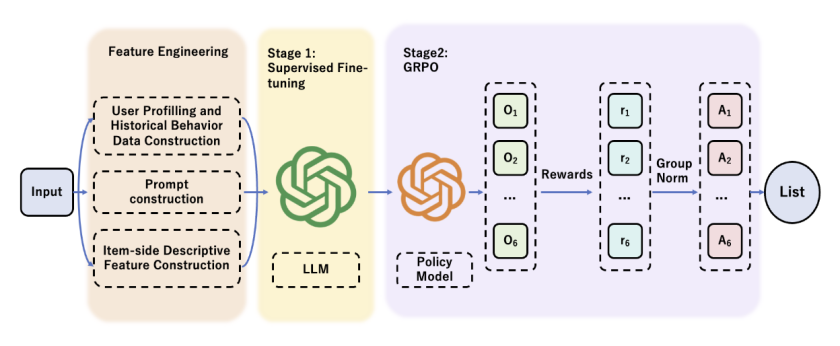
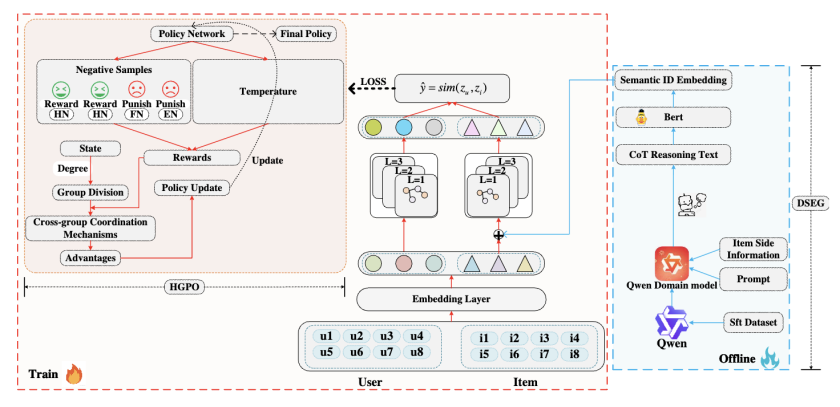
10. LLM-CoT Enhanced Graph Neural Recommendation with Harmonized Group Policy Optimization
链接:https://arxiv.org/pdf/2505.12396
简介:图神经网络(GNNs)通过建模交互关系推动了推荐系统的进步,但现有基于图的推荐模型仍存在明显局限:一方面依赖稀疏ID特征而未能充分挖掘文本信息,导致表征信息密度不足;另一方面,图对比学习面临随机负采样可能引入假阴性样本、固定温度系数难以适应节点异质性等挑战。此外,当前利用大语言模型(LLMs)增强推荐的研究尚未充分发挥其思维链(CoT)推理能力来指导表征学习。
针对上述问题,本文提出LGHRec(基于LLM-CoT推理与协调群体策略优化的图神经推荐框架)。该框架主要引入两种方法:
-
语义增强:利用LLMs的CoT推理生成语义ID,通过丰富推理过程提升表征的信息密度与语义质量;
-
对比优化:设计协调群体策略优化算法(HGPO),动态调整对比学习中的负采样策略与温度系数,在提升长尾推荐效果的同时保证跨群体优化一致性。
(文:机器学习算法与自然语言处理)