

我们今天继续来看看RAG方向的话题,从技术角度,结合实际产品体验来谈谈更落地的事情。
回到工业界,如何结合自身的技术优势,在落地的具体过程中,贡献出自己的一套优势方案,是大家所关注的点。
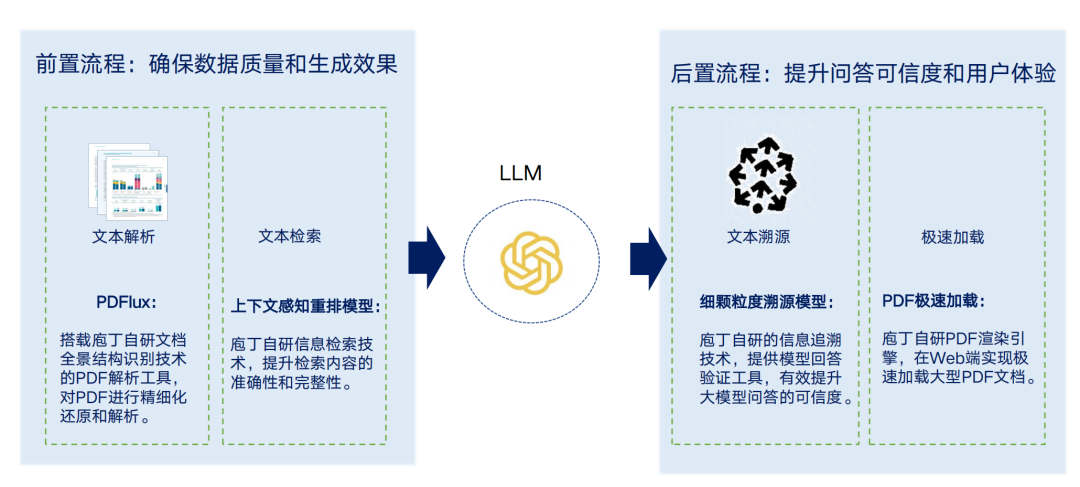
作为文档智能领域的一个领先公司,庖丁科技在文档处理领域深耕多年,尤其在金融、法律等垂直场景中文档解析、表格识别等任务上,推出了许多亮眼的产品。
尤其是PDFlux模型(https://pdfparser.io),精通表格理解,支持多种文档格式(PDF、扫描件、Word、txt、ePub和HTML等)。
而进入到大模型时代以来,RAG检索增强问答范式成为了近年来的一个热门方案,立足文档解析,庖丁科技也推出了自己的特色RAG方案,这也是今天我们要讲的2个特色技术,一个是融合目录层级及长文本重排的上下文检索,解决召回检索问题;一个是全球首创的划词细粒度溯源-TapSource,解决多粒度取信的问题。
一、核心技术1:融合目录层级及长文本重排的上下文检索
检索问题是RAG整体方案中十分重要和关键的一环,针对用户给定的问题,从既定的后台知识库中找到能够充分回答出该问题的上下文,是保证模型准确回答出问题的重要前提【当然,这个要求大模型的理解能力要足够】。
而说到这个检索问题,其影响因素主要包括检索的chunk切分、检索索引的设定(如关键词倒排搜索、embedding索引)以及检索的策略(rank、rerank、hybrid混合检索)等。
而从这三个影响而言,chunk切分是源头地位,而chunk来源于底层的文档解析,chunk之间也很容易出现关联性丢失(如滑窗切分)等问题,也就是在文档切块阶段时,容易造成上下文缺失,如果不解决chunk自身的关联性问题,即便在后续做embedding或者做rank排序,都会在丰富上下的问题上出现不足的情况。
例如,原本紧密关联的多个段落可能会被拆分到不同的文本块中,造成信息割裂,影响检索效果,如下图,第一百二十三条被硬生生切掉。

又如下图:两个文本块均包含“公司”这一指代词,但在原文中,文本块 1的“公司”指华发集团,而文本块2的“公司”指华能信托。

当然,顺着这个思路我们会想,可以使用GraphRag去做,通过抽取实体、关系这些做关联,然后做图索引,做全局或者局部的检索,但这一步其实很费事费力,成本很高,并且涉及到动态更新的问题。
因此,作为直接的方式,其实就是利用文档自身的结构化层级信息,通过将文档做到细致,以得到较好效果。
这也就是庖丁科技的上下文相关的检索(Contextual Retrieval)方案,这个方案的细节在《为什么「上下文检索」是提升 RAG 系统问答准确度的关键?》(https://mp.weixin.qq.com/s/TFCuVTWQuu7JYZbbnhKsfA)有过论述。
其核心思想就是:
通过长上下文重排模型同时对大量文本块进行重排,让文本块在重排阶段获取上下文信息;并通过目录结构模型识别文档的章节目录树,在切分的文本块前加入对应的章节目录,确保文本块的全局信息。
拆开来理解就是两块内容:
1、长上下文重排模型
长上下文重排模型,旨在同时输入多个检索到的文本块,让重排模型能够“看到”多个文本块的内容,其首先将检索到的n个文本块按照其在原文中的顺序进行拼接,形成一段语义连贯的长文本,再将这段长文本与用户提问一起输入模型。
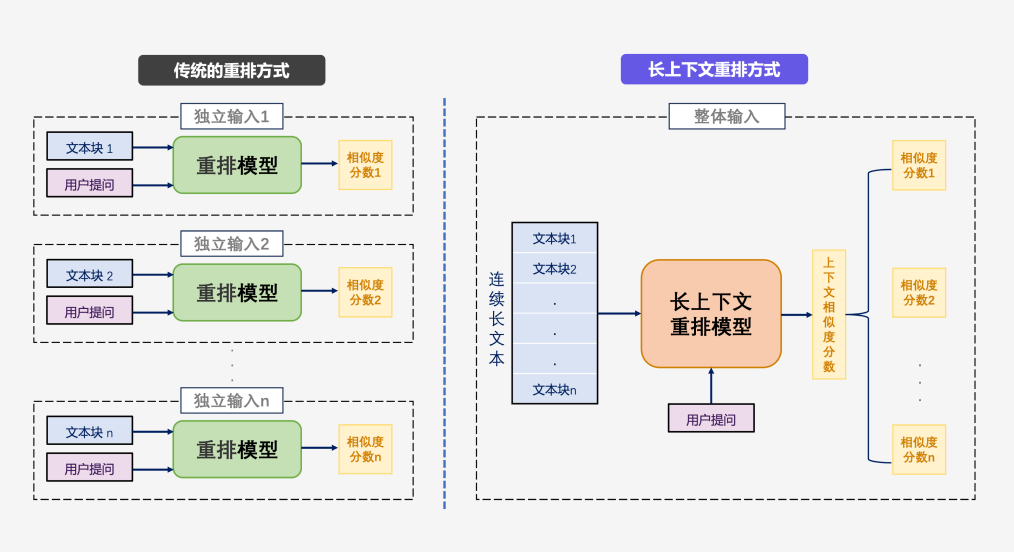
其中的,这个按照原文顺序进行拼接是核心,这个靠底层的索引实现,如前面这个“第一百二十三条”问题,同时获取文本块A和文本块B的内容,并结合语义,知道文本块B的前三条内容是文本块A内容的延续,能够同时让文本块A和文本块B获取较高的相似度分数。
2、文档的章节目录树
实际上,文档的章节目录树,对于第一条提到的长上下文重排模型是一个补充促进关系,
所谓的章节目录树,是一种层次化结构,展示了文档各章节及其子章节的组织方式,帮助明确文档框架并便于定位和引用特定内容,通常以树形结构呈现,其中根节点表示文档的整体内容,每个分支节点代表一个章节或小节,从而形成清晰的层次结构。
因此,如果预先拿到文档的章节目录树,或者提前知道“第一百二十三条”的整体body,再应用到chunk切分上,会有直接的收益。
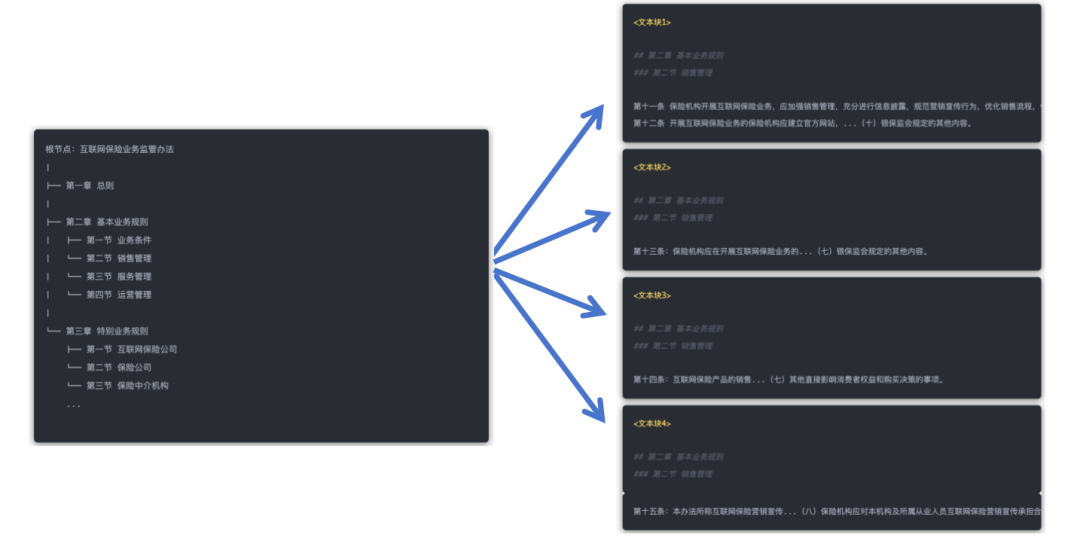
但是问题来了,拿到这个章节目录树其实并不容易,目前开源的一些项目工具,无论是基于pipeline,还是多模态的方案,对于细粒度的层级信息都较难捕获。
这也是庖丁科技的一个重要门槛,训练了目录结构模型,该模型能够在文档解析阶段,根据文档中的文字和图像信息识别出文档的章节目录树。
一个典型的例子如下,这个文档本身是没有目录树的,如下:
但可以直接成生成,可以得到这个文章的目录结构。
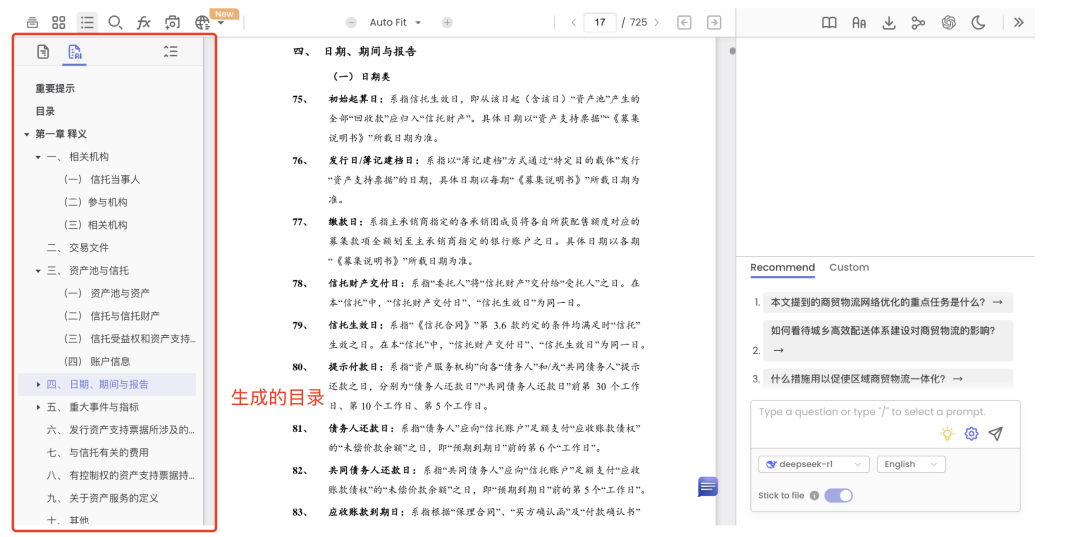
又如,针对这类具有明显层级的,可以达到答案和定位信息,如下:
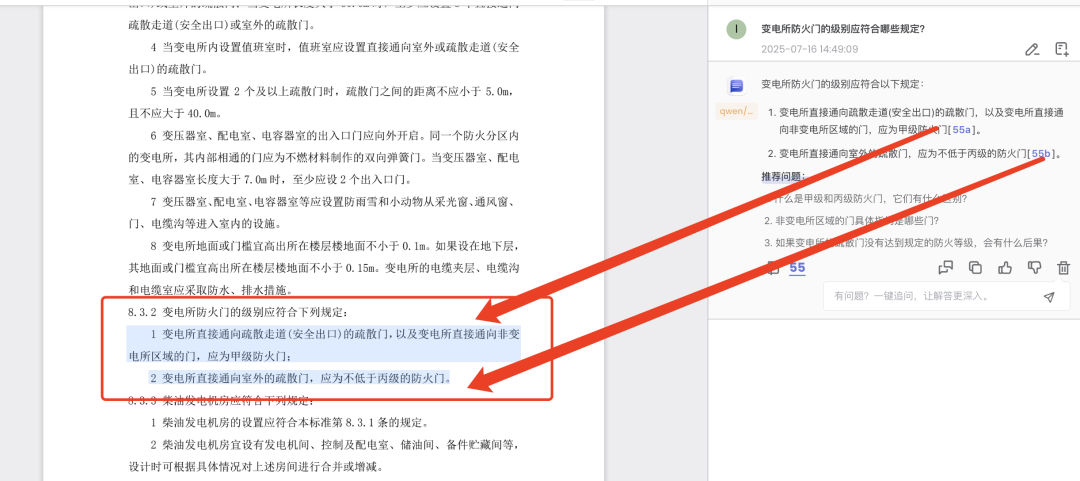
再上点难度,柴油发电机房应符合什么规定,这个问题实际上是个明显的层级性问题,包括9 条,且存在着跨页问题,效果也不错,都可以找到,并且准确定位:
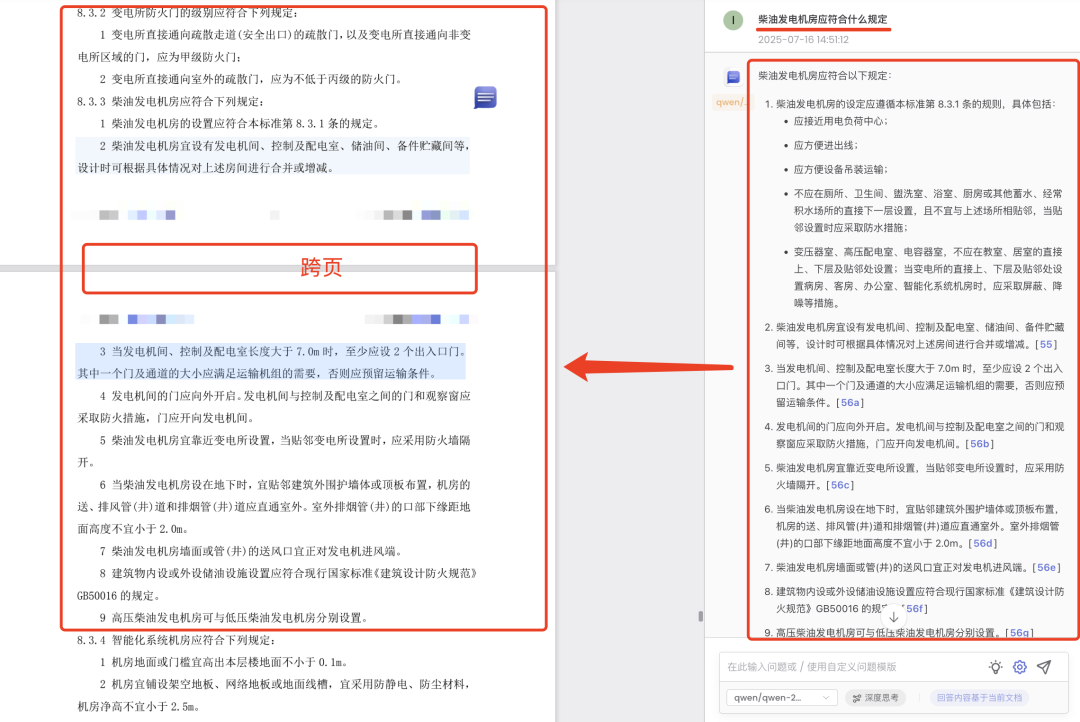
欢迎大家前去测试,这其实是真实的应用case。
二、核心技术2:全球首创的划词细粒度溯源-TapSource
做过RAG的都知道,RAG检索增强虽然一定程度上缓解了事实性幻觉,但本质上,RAG的落地问题,很多时候是一个取信问题,也就是所谓的“保证高质量的检索增强问答;同时,答案中的每个细节都有迹可循。”
而正如我们所见,为了解决这个取信问题,常用的方案都是答案的某些句子后添加了引用链接,加上标引。
但这个标引,有必然会涉及到一个标引准确性和粒度的问题,在准确性方面,很多时候,不是每句话后都有引用。
在粒度上,段span级,还是句子级,段落级,还是页面级,都会有着不一样的使用体验,也对应不同的难度。
从技术的实现角度而言:
如果是页面级,则只需要提前记录某个文本所在的页面信息,但是有些文本其实又存在明显的跨页问题,段落跨页,表格跨页等。
如果是段落级,则需要预先对文档的段落进行准确解析,而段落本身又存在合并段落、阅读顺序的问题。此外,对于一个文档而言,其所包含的元素很多,包括表格、段落、页面页脚、图片等多种要素,如何将这些要素进行分割、合并,都具有一定的挑战性。如下图,庖丁ChatDOC的段落合并效果。

如果是句子级或者是span级别(字句、短语、),那么要求就更高了,其中,对于表格这种类型,其涉及到单元格的切分和定位,尤其是对于合并单元格的定位,其不单单需要准确识别出单元格所在页面的boundingbox,还需要识别出表格的结构以及对应的OCR信息,如下图是庖丁ChatDOC的表格合并效果。
这块,不得不提开源的ocrflux(https://www.modelscope.cn/models/ChatDOC/OCRFlux-3B),是我测下来目前实现最好的(其他闭源的产品还没有完善好,估计过段时间更新),支持跨页表格/段落合并(这是所有开源项目中首个支持此功能的)。
但是,回归到现实目前的状态是,很多产品都只是链接到原文的某个页面,或者某个页面的某个段落,但仍需用户在该页面中搜索具体的相关内容。
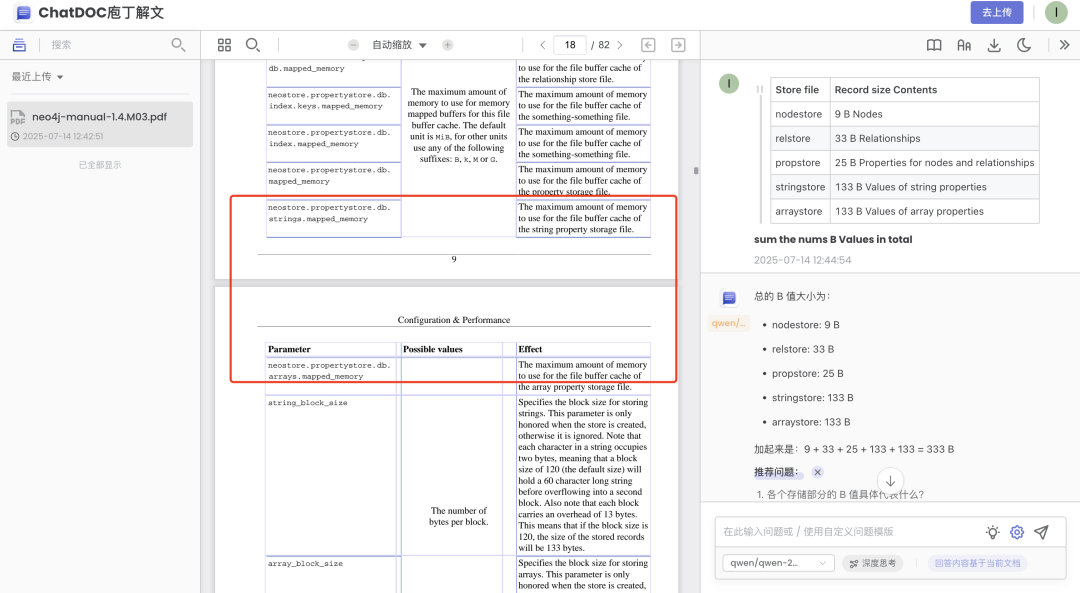
因此,将这个事情做到更细粒度,庖丁科技推出TapSource技术,提供细粒度的原文溯源,方便验证答案,支持对答案中的任何部分溯源,划选任意想溯源的文本片段,细粒度定位到原文中相关的句子、表格单元格等内容。
下面是比较具有代表性的几个例子,两种玩法,一种是从原文出发,细粒度自由选取问答;一总是从问答答案出发,可以进行各种粒度的原文溯源,整个回答的,关键信息的,划词的,很方便。
1、从原文出发,细粒度自由选取问答
Case2: 对于段落,直接划词进行提问:
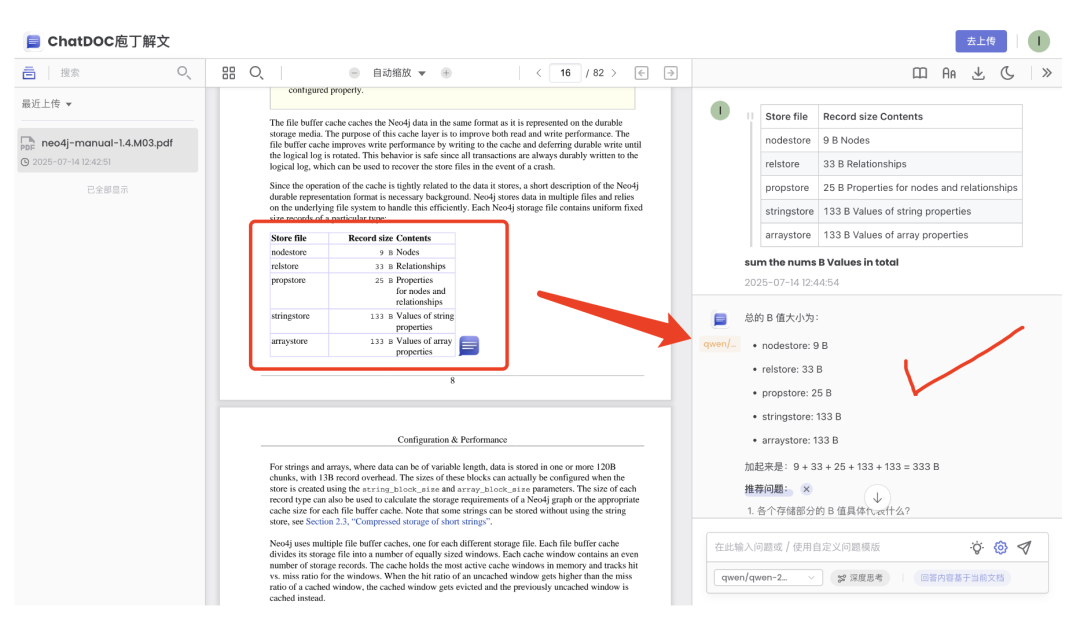
2、从问答结果出发,细粒度原文溯源
Case1:问题回答溯源到原文表格
下图的例子中,其中回复中提到的表格,可以直接定位到原文当中。
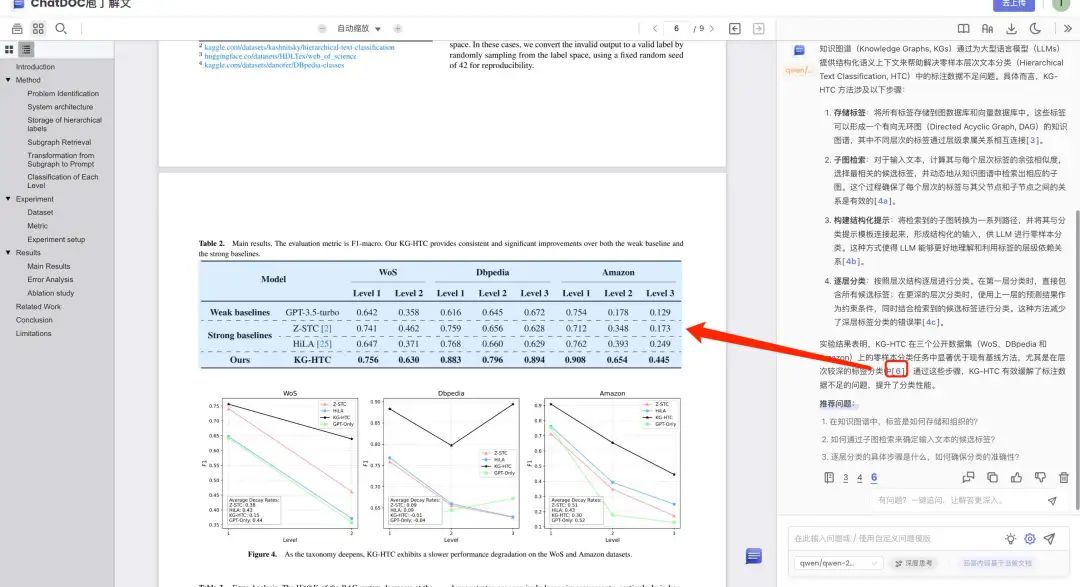
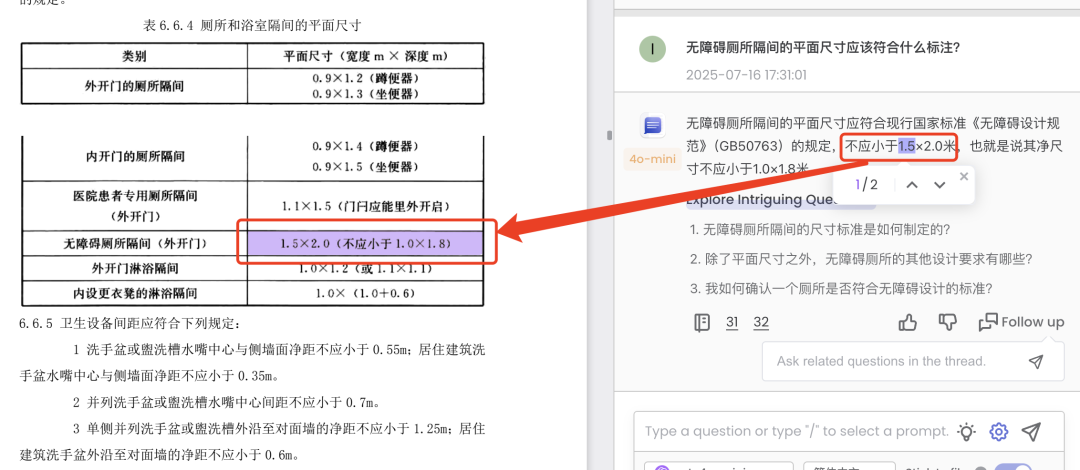
Case2:问题回答溯源到原文表格的单元格粒度
因为预先已经将表格的单元格也进行了解析,因此,也可以很方便的定位到表格中的单元格级别(这也是表格的特殊所在),如下面这个例子:“不小于1.5×2.0米”,准确溯源到了表6.6.4的这个单元格。
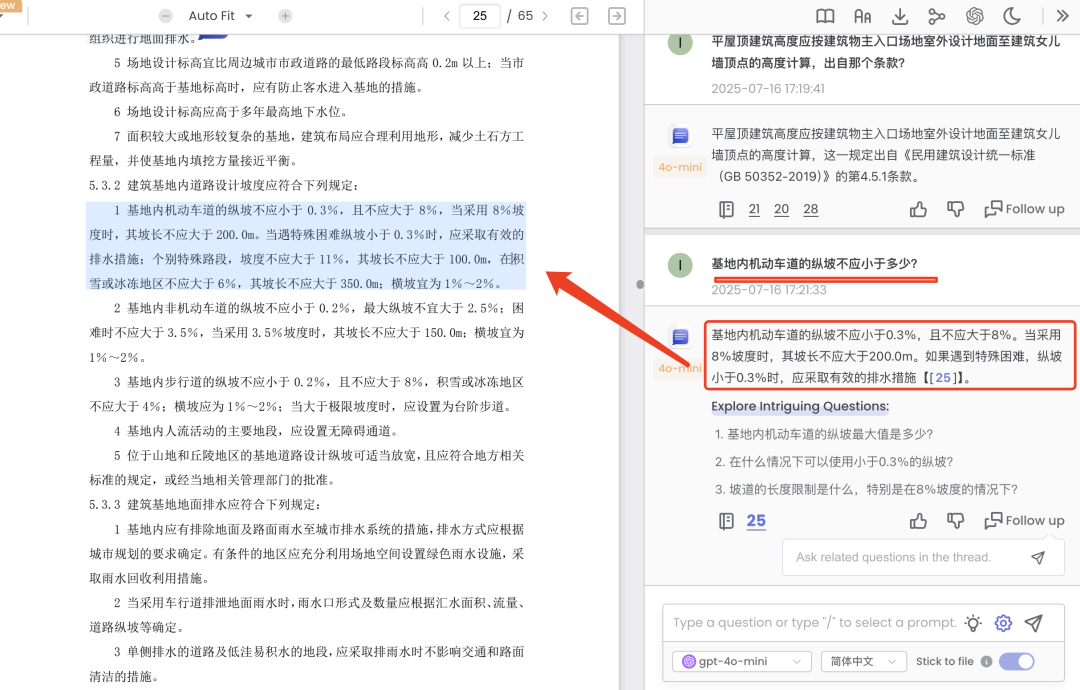
Case3:问题回答溯源到原文段落级别
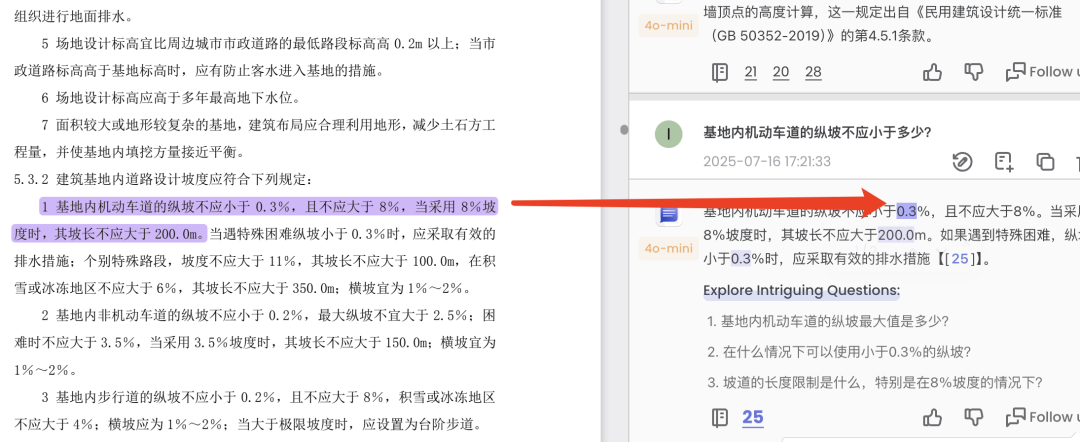
询问问题:““基地内机动车道的纵坡不应小于多少?”时,准确的定位到了所在的段落。
Case4:问题回答中的关键信息溯源到原文句子
我们注意看,其在回答的内容中,还额外突出了“0.3%”等更为细粒度的答案索引,这是一个关键信息。
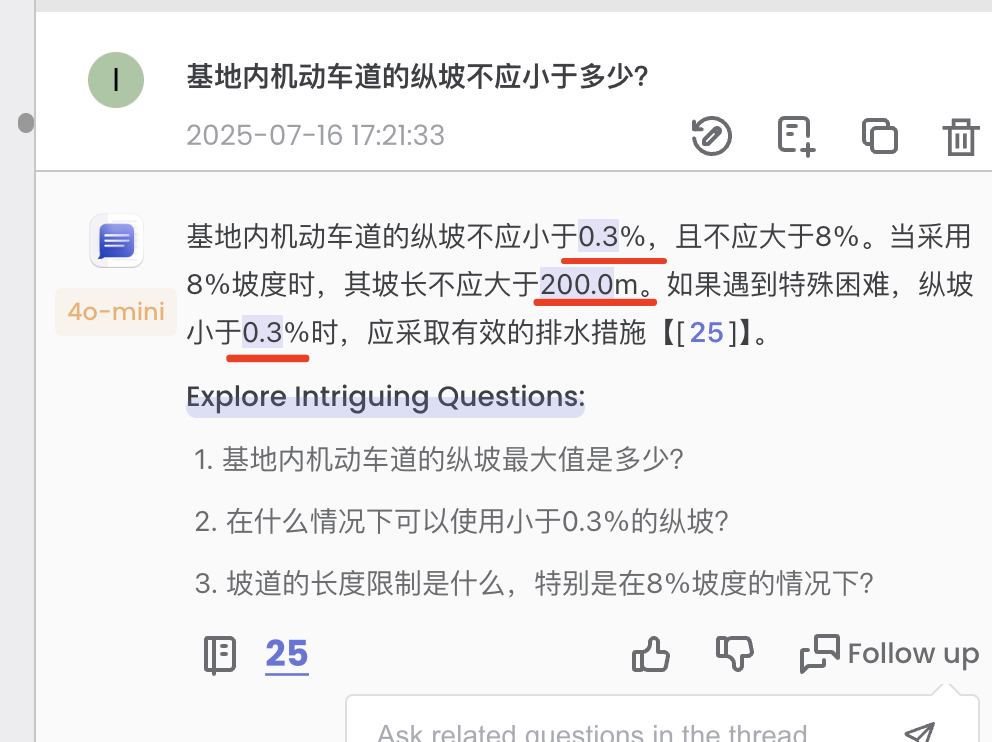
可以进行进一步索引,如对“0.3”,溯源到了具体的位置:
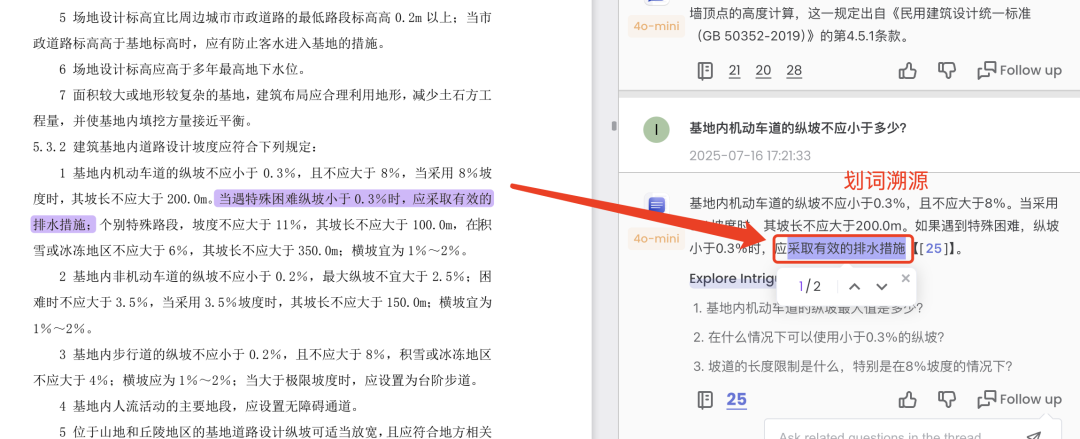
Case5:问题回答中的内容自由划词进行原文溯源
更进一步的,还可以通过直接自由的划词,找到对应的溯源位置,如图,选取了“采取有效的排水措施”, 溯源到了原句子中:
此外,里面也有一些新的功能,也内置了不同的模型,可以选用不同的模进行问答,也有了预设推荐问题,自动生成对于文档可以问的问题,这个测试的链接,大家也可以直接体验:https://chatdoc.site/chatdoc/#/share/ifw_KUYlGKVzIZH5k2zDIi2KIzovC9XbHQwthkLCaGI
当然,这些功能其实还是持续优化中,总会有 badcase,大家可以多测试体验,地址在https://chatdoc.site
参考文献
1、https://mp.weixin.qq.com/s/TFCuVTWQuu7JYZbbnhKsfA
关于庖丁科技
庖丁科技已在文档智能领域深耕七年,取得多项国内外人工智能及金融科技领域的专利技术,产品的准确率、稳定性均保持在业内领先水平,具备多项能力:
ChatDOC,基于庖丁的PDFlux模型基座,优势在于更高效:精通表格理解;公式识别;图片理解;多轮追问;多文档问答;支持多种文档格式(PDF、扫描件、Word、txt、ePub和HTML等);更精准:答案支持一键溯源至原文;答案中的数字支持溯源。
体验地址可以直接访问:
海外版官网:https://chatdoc.com;
国内企业版(庖丁解文)官网:https://paodingjiewen.com
(文:老刘说NLP)