


近年来,多模态指令数据合成方法多依赖人工设计复杂的合成提示词(prompt),耗费大量人力与时间成本。在文本数据合成领域,MAGPIE [1] 是一个非常成功的合成方法,该方法无需用户提供任何 prompt,仅以 <|im_start|> 这类特殊 token 作为模型输入,即可完成数据合成。
受启发于 MAGPIE,本文中来自同济大学、字节跳动和爱丁堡大学的研究者提出了一种新型多模态指令数据合成方法,只需用户提供图片(即,VLM 中常用的特殊 token <image>),Oasis 会自动完成指令合成、质量控制和回复生成,产出高质量的数据。
同时,为了支持进一步研究,该研究提供了一个全新的开源代码库 MM-INF,该库涵盖了 Oasis 和一些常用的多模态数据合成方法,并不断进行更新维护,欢迎大家试用并提供宝贵的反馈意见。

-
论文链接:https://arxiv.org/abs/2503.08741
-
代码链接:https://github.com/Letian2003/MM_INF
-
数据集链接:https://huggingface.co/datasets/WonderThyme/Oasis
研究动机
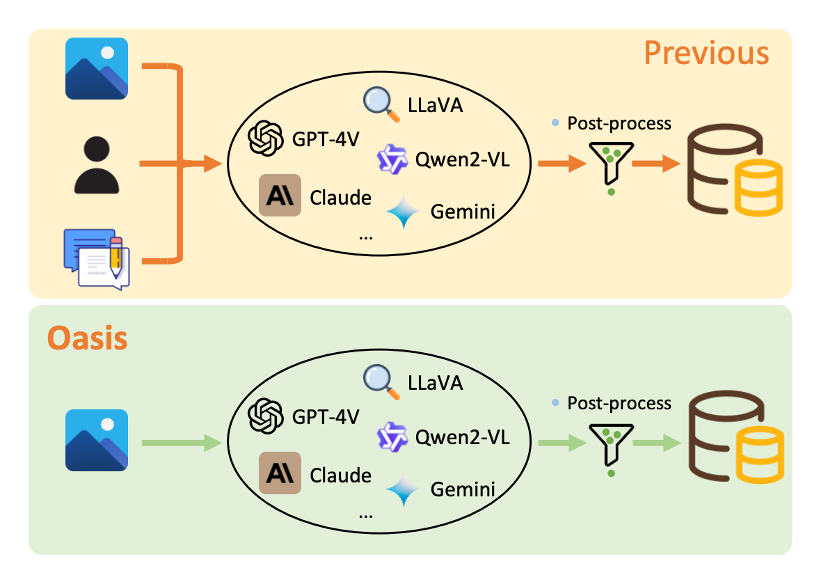
上图展示了常用数据合成链路与 Oasis 的流程对比,常用的数据链路可能会存在以下三类问题:
-
多样性缺失:大量方法依赖固定不变的提示词与合成流程,严重限制了数据的覆盖范围与难度层次,导致生成数据同质化严重;
-
质量不足:现有技术难以稳定产出能显著提升多模态大语言模型(MLLMs)表征能力的高质量合成数据,多数研究不得不退而求其次,采用基于图像描述(caption)的二次生成策略,效果与效率均不理想;
-
依赖人工:流程繁琐且成本高企。即便看似 「一站式」的合成框架,在关键环节(如设计数据模式、编写提示词等)仍需大量人工参与,不仅费时费力,还使整个数据合成过程低效且繁琐。
本文提出的 Oasis 仅依靠图像生成数据,打破了依赖预设文本提示词(<image> + [text prompt])的传统多模态输入模式。 该方法诱导强大的 MLLM 仅基于输入的图像(作为 < image> token 输入),利用其自身的知识和自回归特性,自主生成多样化、与图像内容相关的指令。完全不需要人工提供任何前置的文本提示词。研究者深入分析了高质量指令应具备的属性,并据此精心设计了一系列筛选标准,用于自动过滤掉生成指令中的低质量数据。
方法介绍
概述
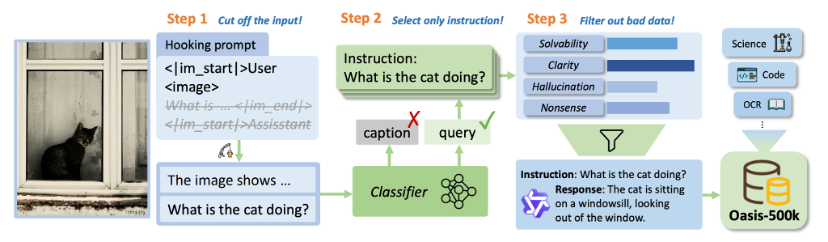
方法如上图所示,主要有三个步骤:
-
构造 「钩子提示词(hooking prompt)」以诱导模型进行自回归采样;
-
对采样结果进行分类,只保留指令型采样结果;
-
进行指令质量控制 & 回复生成。
我们以 Qwen2-VL 为例,详细介绍这三个步骤。
第一步:构造 「hooking prompt」 诱导模型进行自回归采样
以图像描述为例,一个典型的 MLLM 输入为 「<|im_start|>User\n<image>Describe the image.<|im_end|>\n<|im_start|>Assisstant」,MLLM 感知到当前的 role 为 Assistant 后,会生成关于指令的回复。
我们提取完整输入中的前缀 「<|im_start|>User\n<image>」,送入到 VLM 中进行采样,由此生成的回复是不受任何人为 bias 影响的,唯一的 condition 是图片自身;
在采样过程中,生成的数据大致可分为两类:指令型(instruction-following)和描述型(caption),这一现象可以通过交错的多模态语言模型(MLLM)图像 – 文本训练过程来解释。
第二步:采样结果分类
为了仅筛选出指令数据用于后续工作,我们设计了一种分类机制将数据归入指令型和描述型两类。
具体而言,我们驱动一个大语言模型(LLM)作为分类器来预测类别。若包含指令,则将其分类为指令遵循型数据,并从中提取一条指令;否则,将其分类为描述型数据并舍弃。我们采用 few-shot 策略以提高分类精度,完整的提示词模板见附录。
对于分类为指令型的采样结果,我们会进行质量控制和回复生成。
第三步:质量控制 & 回复生成
我们从指令的 可解性 / 清晰度 / 幻觉程度 / 无意义性 四个角度,对指令进行筛选,通过筛选的指令会用 Qwen2-VL 进行回复生成,组成一条完整的 「指令 – 回复」 训练数据;
每个维度均采用 1-5 级评分(1 分表示最差,5 分表示最优):
-
可解性 (Solvability):评估图像是否提供足够的信息来全面回答问题。如果图像缺失关键细节(如对象或上下文),指令可能无法被完全解决。
-
清晰度 (Clarity):评价问题传达意图的精确程度。指令应避免模糊性,确保能得出明确答案(例如,避免开放式或含糊的表述)。
-
幻觉程度 (Hallucination):衡量问题内容与图像实际内容的一致性。指令需避免引入图像中不存在的信息(如虚构对象或场景)。
-
无意义性 (Nonsense):检查问题在语法、连贯性和语义上的合理性。指令必须通顺、有意义,避免错误如语法混乱或逻辑矛盾。
具体的筛选细节见附录。另外,我们在消融实验中发现回复的质量控制是无效的,只对指令做质量控制即可。
Oasis-500k
我们基于 Cambrian-10M [2] 的图片,进行数据生产,最后合成约 500k 的训练数据,称之为 Oasis-500k;由于 Oasis 的生产只依赖图片,所以只要图片的数量是足够的,Oasis 可以轻松进行 Scaling,数据量级随着时间是线性增长的。
数据特性分析
我们对 Oasis 合成的数据和开源常用的指令数据 LLaVA-NeXT 进行了一系列属性的对比,包括指令和回复的长度、语言类型、动名词组合等。
指令和回复的长度
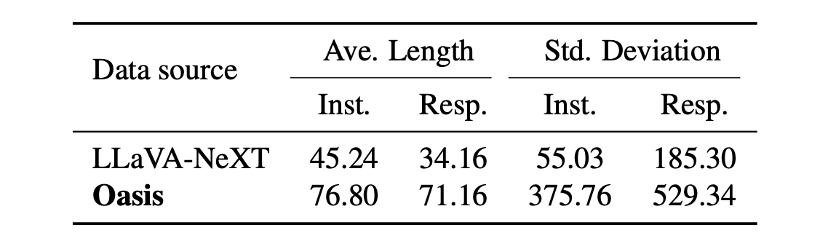
如上表所示,从指令和回复的平均长度来看,Oasis 数据均长于 LLaVA-NeXT,且整体标准差更大。更长的长度表明 Oasis 数据可能包含更丰富的信息,而更大的标准差则说明其数据任务更多元。
语言类型
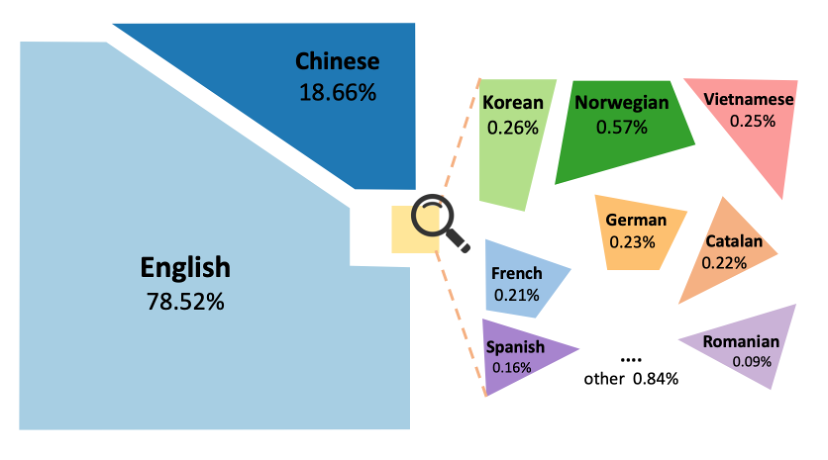
得益于该方法的自回归特性,基于图像的自回归过程不会引入显式语言偏差,因此生成的指令覆盖广泛语种。借助 langdetect 库,对 Oasis-500k 数据的语言类型分布进行可视化分析发现:除英文(78.52%)和中文(18.66%)外,还包含韩语、挪威语、越南语、法语、德语等小语种,语言多样性显著。
动词名词组合
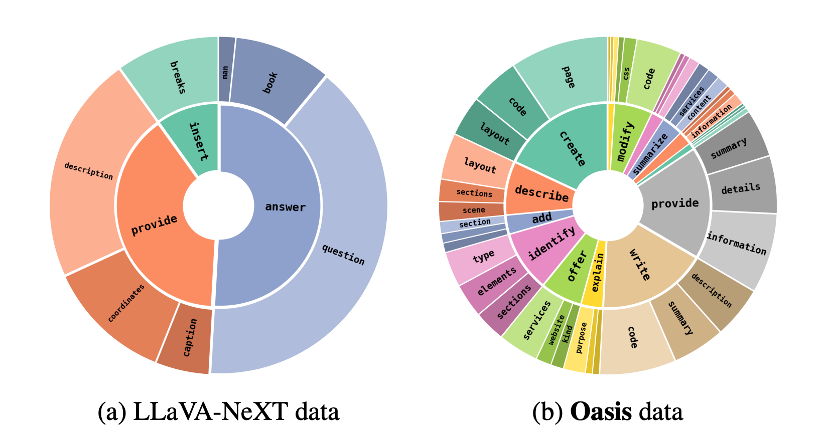
基于 spaCy 库,解析了数据集的根动词(root verbs)与高频名词对象(top noun objects,即出现频率超过 1% 的根动词及与其关联的前 3 位名词对象)。上图展示了两类数据中最常见的根动词及对应名词对象分布,相较 LLaVA-NeXT,Oasis 数据的根动词具有以下优势:
-
表达自然性:覆盖更自然实用、信息量更丰富的动词语汇;
-
对象多样性:高频名词对象呈现更丰富的语义分布。
值得注意的是,LLaVA-NeXT 对 「answer question」 组合的高度依赖,反映出其在任务设计上可能过度偏重问答(QA)场景。
数据示例

Oasis 数据集的示例如图所示,可见 Oasis 的指令生成能力很强,可基于图像主题生成细节丰富且信息密度高的指令。另外生成的任务覆盖广度好,涵盖跨领域任务场景,如目标识别(Object Recognition)、场景描述(Scene Description)和代码理解(Code Comprehension)等。这些可视化同样佐证了前文关于数据多样性的观点。
实验结果
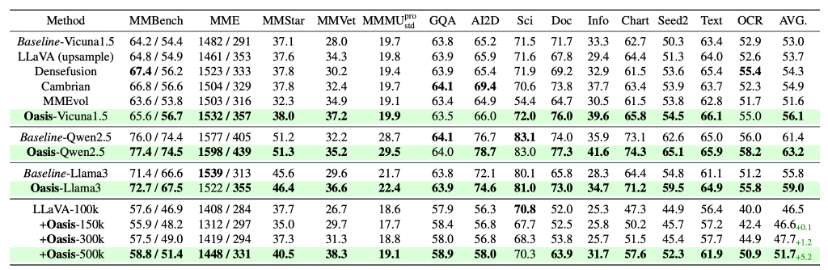
Oasis 有效性
我们将 LLaVA-NeXT 设置为 baseline,在其 SFT 数据上做增量改进,观察相对于 baseline 的提升。我们在 14 个 benchmark 上对基于 Oasis 训练的 MLLM 进行了全面评估。
如上表所示,Oasis 作为基线的增量数据引入,较基线实现全面且显著的性能提升。
在 Vicuna1.5/Qwen2.5/Llama3 等基座网络上,平均提升分别 3.1%/1.8%/3.2%;以 Vicuna-7B-v1.5 为例,通用知识 MMBench-EN/CN 准确率提升 + 1.4% / +2.3%;OCR 任务 TextVQA 与 OCRBench 精度分别提高 2.7% 和 2.1%;在文档分析任务上较基线提升 4.3% 和 6.3%;
上述结果不仅证明了合成数据的多样性,更揭示了 Oasis 在增强 MLLM 泛化能力上的有效性。
对比其他合成方法
除了 Oasis 数据,我们引入了 4 种增量改进,来进一步说明 Oasis 的有效性。
-
Oasis 图片的原始标注数据(指令 + 回复),验证 SFT 图片多样性增加的影响;
-
LLaVA-NeXT 原始 SFT 数据的上采样,排除数据量级对效果的影响;
-
MMEvol 数据 [3]
-
DenseFusion-1M 数据 [4]
如上表所示,Oasis 作为增量数据引入时,依然表现出了更好的综合性能,再一次佐证关于数据多样性的观点;
数据 Scaling 效果
我们基于 100k 的 LLaVA-NeXT 数据,对 Oasis 的数据量进行了 3 组 Scaling 实验,即,在 LLaVA-100k 的基础上分别加入 150k/300k/500k 的 Oasis 合成数据。整体趋势上来看,Oasis 数据量从 0 增至 500k 的过程中,模型性能稳定提升,添加 500k 条 Oasis 数据后,平均得分提高 5.2%;300k→500k 带来了 + 4.0% 的显著增益,也进一步说明该数据的可扩展性;
垂域数据合成能力
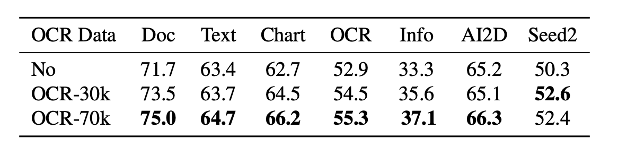

受益于 Oasis 只依赖图片输入的特性,它非常善于合成垂类的数据。我们以 OCR 为例,验证 Oasis 在垂域数据合成上的有效性。我们从 Cambrian-10M 中筛选出了 24 个和 OCR 相关的数据集(共 311k 图片),然后基于这些图片进行 Oasis 数据合成了 70k 的垂域训练数据。如上表所示,这份 OCR 垂域数据在 OCR 相关的 benchmark 上带来了非常明显的提升。另外如上图所示,Oasis 合成的数据不仅仅关注文字提取任务,同样也考察了模型对于上下文的理解、属性推理等能力。
消融实验

描述数据的回收利用
在数据合成流程的第二步中,我们使用了 LLM 来对第一步中模型自回归采样出的数据进行筛选,去掉 caption 类型的数据。这一步的通过率为 49.9%,占比约一半的 caption 类型数据被丢弃,这导致合成效率受到较大的影响。
因此,我们采用一些策略来对此类 caption 数据进行回收利用。首先,我们使用一些规则来对数据中的特殊字段(如乱码等)进行去除。然后,我们使用 Qwen2.5-72B-Instruct LLM 来对 caption 数据的质量进行三个维度评估,最终我们得到了约 250k 的高质量 caption,并与 LLaVA 论文中给出的图像详细描述指令进行随机匹配。
我们在原始的 OASIS 数据上额外加入这 250k 数据进行训练,如上表所示,加入 caption 后多数指标有上升,并带来了总体 0.3% 的提升。这说明我们可以低成本地回收利用数据合成过程中被丢弃的数据,并带来额外的实验收益。
指令质量控制的必要性
在完成数据分类之后,我们对指令质量进行了控制,从四个维度筛除低质量指令:可解性、清晰度、幻觉成都和无意义内容。为了评估这一质量控制机制对数据质量和模型性能的影响,我们进一步进行了消融实验。
具体来说,我们使用经过质量控制和未经质量控制的 20 万条数据分别训练模型,比较所得模型的性能。在质量筛选过程中,高质量指令的接受率为 50.9%,因此,未经质量控制的 20 万条数据中,会包含约 10 万条 「低质量」 指令。
根据上表第二部分展示的实验结果。在应用质量控制机制的情况下,模型整体性能显著提升了 1%。在 DocVQA 和 InfoVQA 这两个任务中,模型性能分别提升了超过 7%。这一结果充分证明了在 Oasis 框架中,数据质量控制机制是非常必要的。
回复质量控制的必要性
为探究响应质量控制的必要性,我们尝试了两种低质量响应过滤方法:
-
负对数似然(NLL)拒绝采样法:对每条指令采样 5 个回复,计算其负对数似然,保留置信度最高的回复作为最终输出(参考 [5]);
-
多模态大语言模型(MLLM)评分法:使用 Qwen2-VL-72B-Instruct 模型从有用性(helpfulness)、真实性(truthfulness)、指令遵循性(instruction-following)三个维度进行 1-5 分评分,过滤未获满分(5 分)的回复。
如上表所示,证明两种方法均导致模型平均得分下降(-0.7% 与 -1.6%),证明对回复做质量控制无效甚至有害。高质量指令本身即可驱动 MLLM 生成高质量的回复,引入对回复的质量控制可能会引入额外的人为 bias;
开源代码库 MM-INF

-
代码链接:https://github.com/Letian2003/MM_INF
该研究还开源了一个数据合成的 codebase MM-INF。该 codebase 依托于开源代码库 ms-swift [6] 实现了一个数据合成引擎,可以串联起若干个基于 LLM/VLM 的数据合成步骤。代码库内涵盖了 Oasis 的实现以及一些常用的多模态数据合成链路(如图片描述、基于描述生成 QA 等),欢迎大家试用并提供宝贵的反馈意见。
参考文献
[1] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, ICLR 2025.
[2] Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs, NeurIPS 2024.
[3] MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct, arxiv 2409.05840.
[4] DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception, NeurIPS 2024.
[5] SimPO: Simple preference optimization with a reference-free reward, NeurIPS 2024.
[6] https://github.com/modelscope/ms-swift

©
(文:机器之心)