


程序员最有价值的技能已经不再是编写代码了,而是精确地向 AI 传达意图。一份完善的规范才是包含完整意图的真正「源代码」。
这是 OpenAI 研究员 Sean Grove 在 AIEWF 2025 的演讲中提出的观点。前不久,Andrej Karpathy 也针对于提示词提出了他的观点,不同的是,Karpathy 聚焦如何给 AI「喂更多地料」,让 AI 更理解你的意图。Karpathy 认为,提供完整且恰当的上下文往往比编写好的提示词更重要。
Sean Grove 的视角则聚焦在如何形成一份完善、可执行的「规范」,以此精准地向 AI 传达意图。
在某种程度上,两者的观点都深刻地体现了一点:生成代码已经不是重点了,软件工程的本质是人与 AI 之间的「沟通」。
而且,这也可以看作是对 Jason Wei 提出的验证者规律的回应,规范本身就是一种可验证的标准。
在演讲中,Sean Grove 从 AI 时代「新代码」的角度,分享了他对于软件工程的看法。Sean Grove 认为,提示词是规范,不应被用过一次后即被丢弃,捕捉其中的意图和价值观非常重要,最有价值的成果不是代码,而是源规范。此外,Sean Grove 还分享了如何让规范可执行、如何向模型传达意图,模型的「谄媚问题」、规范如何参与模型训练与演化等内容。
Sean Grove:OpenAI 对齐团队的研究员,从事模型对齐推理的研究工作。此前,曾创立了一家 GraphQL 开发人员工具初创公司 OneGraph,后来被 Netlify 收购。
Founder Park 联合外滩大会组委会、将门创投,征集能真正改变生活的 AI 硬件,寻找 AI 硬件的新可能。
-
30 万大赛奖金
-
创业扶持礼包
-
更多头部资源链接机会

扫码即可报名
01
编程真正的价值在于结构化沟通,
而不是代码本身
我们先从一个简单的问题开始:在座的各位有写过代码的吗?请举个手。好,请那些「以编写代码为职业」的朋友继续举着手。如果你觉得自己最有价值的专业产出是代码,也请继续举着手。
看到很多手还举着,我觉得这很正常。我们都在努力解决问题:与人沟通、收集需求、思考实现细节、整合各方资源。最终,我们产出的是代码,一个可以明确指出、可以衡量、可以讨论的成果。它让人感觉「成果落地」。但我想指出,这在某种程度上其实低估了你们的实际工作。代码可能只占你所创造价值的 10% 到 20%,其余 80% 到 90% 在于结构化沟通。

当然,每个人的情况不同,但工作流程通常是这样的:
-
与用户交流,了解他们的挑战;
-
提炼信息,构思解决方案;
-
明确要实现的目标,并制定计划;
-
和同事分享这些计划,然后才将计划转化为代码,这无疑是关键一步;
-
最后,进行测试和验证,但验证的并非代码本身,而是它在运行时是否达成了最初的目标,是否解决了用户的痛点,也就是代码对世界产生的实际影响。
所以,交流、理解、提炼、构思、规划、分享、转化、测试、验证——在我看来,这些全是结构化沟通。而结构化沟通正是瓶颈所在:明确该做什么、如何与人沟通并收集需求、怎样实现、为何要这么做,以及最终判断做得对不对,是否真正达成了初衷。
AI 模型越先进,这个瓶颈就越明显。因为在不远的将来,沟通能力最强的人,将是最有价值的程序员。事实上,能有效沟通,你就能编程。
以「氛围感编程」(Vibe-driven Programming)为例,它之所以体验很好,正是因为它从根本上将沟通置于首位,代码只是沟通的下游产物。我们可以描述自己的意图和期望看到的结果,然后让模型来处理繁重的工作。
02
一份完善的规范
才是真正的「源代码」
即便如此,我们现在与模型互动的方式还是有些奇怪。我们通过提示词(Prompt)与模型沟通意图和价值观,得到一个代码成果。然后,我们似乎就把提示词扔到了一边,视其为一次性的东西。这很不合理。
如果你写过 TypeScript 或 Rust,你不会在编译出二进制文件后就心满意足了。二进制文件不是目的,它只是有用的产物。事实上,每次编译或运行时,我们总是从源代码重新生成二进制文件。最有价值的成果是源代码,是源规范。
然而,当我们给模型输入提示词时,却做了相反的事:保留生成的代码,丢弃提示词。这就好比你撕掉了源代码,却小心翼翼地对二进制文件进行版本控制。
这就是为什么在规范中捕捉意图和价值观如此重要。一份书面的规范,能让人们在共同的目标上达成一致,并让我们清楚地知道是否达成了共识。这是一个你可以用来讨论、辩论、参考和同步的成果,至关重要。

如果你没有规范,你就只有一个模糊的想法。现在我们来谈谈为什么规范总体上比代码更强大。
因为代码本身就是从规范的一种有损投射(Lossy Projection)。就像你反编译一个 C 语言的二进制文件,你得不到清晰的注释和恰当的变量名,你必须反向推导作者的意图。这些关键信息在转换过程中丢失了。同样,代码本身,即使写得再好,通常也无法完整包含所有的意图和价值观。阅读代码时,你还是要去推断这个团队最终想要实现什么。
所以,当沟通的成果沉淀为一份书面规范时,它就比代码更好,因为它包含了生成代码所必需的所有前提和意图。
就像一份源代码可以通过编译器适配多种架构(如 ARM64、x86、WebAssembly),一份完善的规范交给模型,同样能生成优质的 TypeScript 代码、Rust 服务器、客户端应用、文档、教程、博客文章,甚至一期播客。
我们来做个思维练习:在座各位,有谁的公司是服务于开发者的吗?如果把你们公司的整个代码库、所有文档,也就是运行业务的全部代码都丢进一个播客生成器,它能生成一期足够有趣、能吸引并教会用户如何成功的播客吗?恐怕不能,因为这些关键信息并不在代码里。
所以,未来的关键技能是编写能充分捕捉意图和价值观的规范。掌握这一技能的人,会成为最有价值的程序员,而他们很可能就是今天在座的各位。
03
规范可以直接用于训练和调优 AI 模型
这和我们现在做的事已经很相似了。产品经理写产品规范,立法者写法律规范。这是一个普遍原则。
那么,规范到底是什么样的?我以 OpenAI 的「模型规范」为例。去年,OpenAI 发布了模型规范,这份动态文档旨在清晰、明确地阐述我们希望模型向世界展现的意图和价值观。它在今年 2 月进行了更新,并且已经开源。
注:今年 2 月,OpenAI 进行了模型规范更新 https://openai.com/zh-Hans-CN/index/sharing-the-latest-model-spec/
你可以去 GitHub 上看看模型规范的实现,它其实就是一堆 Markdown 文件。
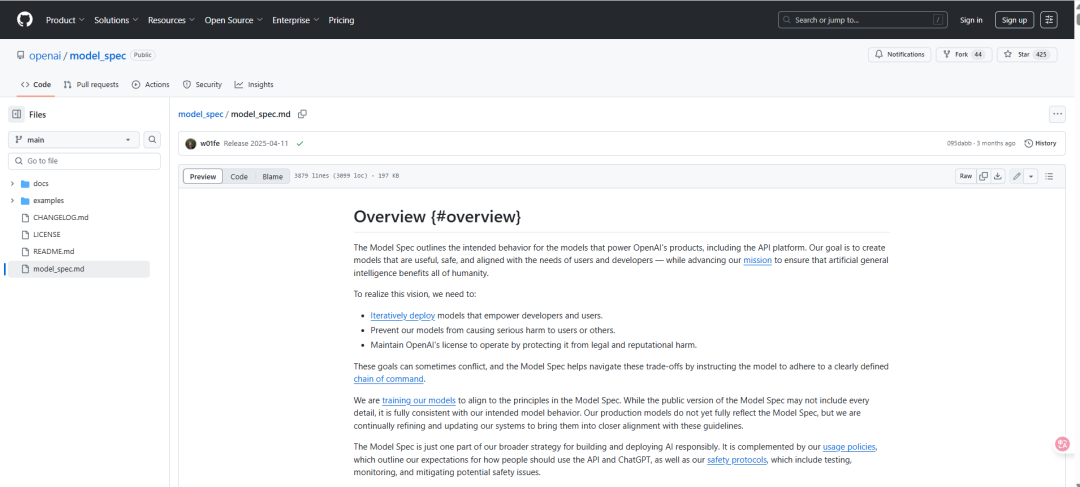
Markdown 非常了不起。它便于人类阅读,有版本记录和变更日志。而且,由于它是自然语言,公司里所有人都能参与进来——无论是产品、法律、安全、研究还是政策团队的成员,大家都能阅读、讨论、辩论并为同一份「源代码」做出贡献。这是一个能让全公司在核心意图和价值观上达成一致的通用媒介。
尽管我们努力使用明确的语言,但有时细微之处依然难以表达。为此,模型规范中的每个条款都有一个唯一 ID(例如 SY703)。通过这个 ID,你可以在代码仓库中找到对应的文件(sy703.md),里面包含了一到多个针对该条款的、极具挑战性的测试用例。这样一来,这份文档本身就内嵌了它的成功标准:被测试的模型必须能够给出符合该条款精神的回答。
我们来谈谈「谄媚问题」(Sycophancy)。不知道大家有没有听说,前段时间 GPT-4 的一次更新出现了严重的谄媚倾向。在这种情况下,模型规范有什么用?它的作用就是让人们在一系列共同的价值观和意图上达成一致。
举个例子,有用户指出模型为了谄媚而牺牲了客观事实,模型的回应却是非常友好地称赞用户「有洞察力」。其他研究人员也发现了类似的、令人担忧的例子。这样的谄媚会侵蚀信任,造成伤害,并引发了关于「这是故意设计还是意外失误」的争议。
注:「谄媚问题」 是指大型语言模型(LLM)的一种行为倾向,即模型会刻意迎合用户的观点、信念或情感,即便用户的观点是错误的、有偏见的或不符合事实的。
幸运的是,模型规范自发布之初就明确规定了「不要谄媚」。这份规范解释,虽然谄媚在短期内可能让人感觉良好,但长远来看对谁都没有好处。因此,我们通过规范表达了我们的意图,并为公众提供了一个可以参考的基准。如果模型的行为与规范不一致,那它就是一个漏洞(Bug)。
所以我们回滚了更新,发布了相关的研究和博客文章,并修复了这个问题。在此期间,规范扮演了信任锚点的角色,让所有人都能清楚地知道,什么是我们预期的行为,什么不是。
即便模型规范唯一的作用只是让人们达成共识,它也已经非常有价值了。但理想情况下,我们还能让模型及其产出也与这份规范保持一致。
04
如何用「规范」训练模型?
我们曾发表过一篇名为《Deliberative Alignment: Reasoning Enables Safer Language Models》的论文,探讨了如何自动化地让模型与规范对齐。简而言之,就是将规范和高难度的提示词交给一个模型,然后让一个更强大的「裁判模型」根据规范,来为它的回答打分。通过这种方式,我们可以强化模型的权重,将规范从「每次都要提醒」的推理成本中解放出来,「压入」模型的权重之中,让遵循规范成为模型的「肌肉记忆」。
注:《Deliberative Alignment: Reasoning Enables Safer Language Models》
论文地址:https://arxiv.org/abs/2412.16339
尽管模型规范只是 Markdown 文件,但将它们视为代码会很有帮助,因为它们非常相似:
-
可组合:可以模块化地发布和引用。
-
可执行:可以包含自身的单元测试。
-
可测试:可以像类型检查器一样,自动发现不同规范间的冲突。
-
可审查:可以构建工具来检查语言的模糊性,因为模糊的表述不仅会困扰人类,也会困扰模型。
规范实际上给我们提供了一套全新的工具链,它针对的是意图,而非语法。
05
规范是跨角色通用的语言
我们再来想想「作为程序员的立法者」这个概念。美国宪法其实就是一份国家层面的模型规范。它有书面文本,作为我们讨论的共同基础;它有版本化的修正案,可以更新和发布;它还有司法审查机制,由「评分者」(法官)来评估具体案例与政策的契合度。
当法律条文出现模糊或遗漏时,司法审查的过程就变得非常耗费精力。而一旦做出裁决,就会确立一个先例(判例)。这个先例就如同一个「输入-输出」对,作为一个单元测试,来消除原始规范的歧义并强化它。这个系统通过持续的执行和裁决,如同一个训练循环,帮助整个社会在共同的意图上达成一致。这是一个能够有效传达意图、裁决合规性并安全演进的成果。

所以,未来的立法者可能成为程序员,反之亦然。这是一个非常普遍的规律:
-
程序员通过代码规范,来统一芯片的行为。
-
产品经理通过产品规范,来统一团队的目标。
-
立法者通过法律规范,来统一民众的行动。
而在座的每个人,当你们输入提示词时,其实就是在制定一种「原型规范」(Proto-spec)。你们都在从事让 AI 模型向着共同意图对齐的工作。无论你是否意识到,在这个时代,你就是一名规范的制定者。规范能让你更快、更安全地发布成果。每个人都能做出贡献。无论是业务分析师、产品经理、立法者、工程师还是营销人员,只要编写了规范,就成了程序员。
软件工程的本质从来就不是关于代码本身。回到之前那个问题,许多朋友放下了手,因为你们认为自己产出的核心不是代码。但工程的本质从来就不是这个。编码是一项非常重要的技能和宝贵的资产,但它不是最终目的。工程,是人类为了解决自身问题,而对软件方案进行的精确探索。 一直都是如此。
我们只是在从五花八门的机器编码,转向一种统一的人类编码——用更自然的方式,来表达我们解决问题的思路。
06
未来 IDE 不仅是写代码的工具,
而是「集成式思维澄清器」
我想请大家在开发下一个 AI 功能时,尝试将这个理念付诸实践:从规范开始。明确你期望达成的效果和成功标准,确保规范清晰、准确,并让它变得可执行,最终根据规范来测试你的模型。
鉴于编程和规范制定有如此多的相似之处,这引出了一个有趣的问题:未来的集成开发环境(IDE)会是什么样子?
我想,IDE 可能会演变成一种「集成思维澄清器」(Integrated Thought Clarifier)。当你在编写规范时,它能实时指出其中的模糊之处,帮助你理清思路,让你能更有效地向他人和模型传达意图。
最后,我想向大家请教一个问题,这个问题也关乎我们如何大规模地实现智能体(Agent)的对齐:规范需要具备哪些特性,才能既易于机器处理,又能够满足人类复杂的需求?
我很喜欢一句话:你终将意识到,你从未真正告诉过它你想要什么,或许连你自己也从未完全弄明白。
总之,我在此呼吁大家重视规范。OpenAI 已经成立了一个新的「Agent 稳健性团队」(Agent Robustness Team)。加入我们,一同为全人类的福祉,交付安全、可靠的通用人工智能。
谢谢大家!
原视频链接:https://www.youtube.com/watch?v=8rABwKRsec4

(文:Founder Park)