
腾讯AI大模型,伴随着业务需求更新,实现了多维度的更新。看我文章的老朋友应该还记得8月份的时候写过一篇《腾讯大语言模型VITA》推文,它通过先进的多模态交互体验,推动了人机交互的自然性和无缝集成。

项目背景与技术亮点
神经机器翻译(NMT)在处理日常文本翻译方面已取得显著进展,但在翻译文学作品时,特别是隐喻和明喻等修辞手法时,仍面临巨大挑战。
这些表达通常蕴含深厚的文化和语境含义,简单的直译往往无法准确传达其内涵。
为了解决这一难题,腾讯研究院开发了DRT-o1系列模型,其主要通过长思维链(long chain-of-thought,简称CoT)技术,更能理解比喻和隐喻等,从而提高文学作品的翻译质量。
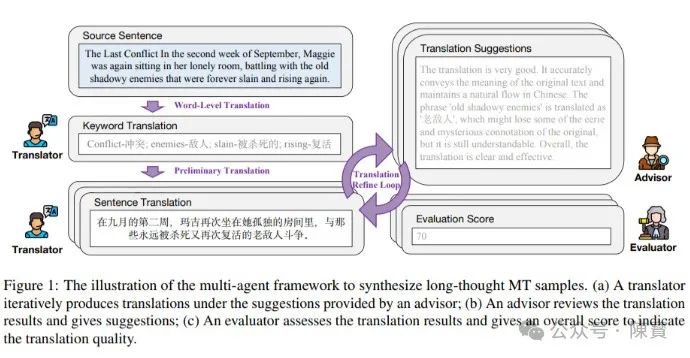
多智能体框架与工作流程
DRT-o1系列模型采用了一种创新的多智能体框架,包含翻译员、顾问和评估员三个角色。
这种框架通过反复迭代,不断提升翻译质量,具体工作流程包括三个主要步骤:
1. 关键词翻译:翻译者首先识别句子中的关键词,并提供它们的翻译。
2. 初步翻译:然后,翻译者根据源句子和关键词的双语对应关系提供一个初步的翻译。
3. 翻译精炼循环:在精炼循环中,顾问评估前一步的翻译并提供反馈,评估者根据预定义的评分标准给出整体评分。翻译者根据反馈和评分提供新的翻译,当评分达到预定义的阈值或迭代次数达到最大值时,循环停止。
最终的翻译结果会由GPT-4o进行润色,确保流畅性和可读性,最终数据集包含22264个经过深度思考的机器翻译样本。
性能表现与实际应用
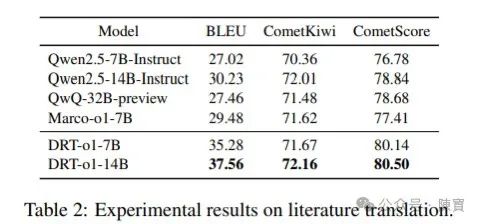
实验结果表明,DRT-o1系列模型在处理复杂语言结构方面表现出色。
DRT-o1-7B的性能甚至超过了更大的模型QwQ-32B,BLEU分数高出7.82分,CometScore高出1.46分。
原文:“The mother, with her feet propped up on a stool, seemed to be trying to get to the bottom of that answer, whose feminine profundity had struck her all of a heap.”
在DRT-o1模型的翻译下,最终被翻译为:“母亲将双脚搭在凳子上,似乎在努力探究那个答案,那答案中女性特有的深刻性令她猛然心生震撼。”
⋯ ⋯
1. 忠实原文(信)
DRT-o1系列模型通过关键词翻译和初步翻译两个步骤,能够较好地实现忠实原文的目标。例如,开发者提供的例子中,原文的情感色彩在翻译后得到了保留,这体现了模型在“信”方面的出色表现。
2. 通顺易懂(达)
DRT-o1系列模型通过多智能体的框架,包含翻译员、顾问和评估员三个角色,通过反复迭代,不断提升翻译质量。这样的工作流程有助于不断优化翻译质量,使译文更加通顺易懂。
3. 优美文笔(雅)
DRT-o1模型在处理复杂语言结构方面表现出色,其性能甚至超过了更大的模型QwQ-32B。这表明DRT-o1系列模型在实现忠实原文和通顺易懂的基础上,还能提升文笔的优美程度。
腾讯公司推出DRT-o1系列AI模型在长链思考推理方面表现出色,能够显著提升文学翻译的质量。通过创新的多智能体框架和反复迭代的工作流程,该模型在实现文学翻译“信达雅”方面具有显著优势。
(文:陳寳)