跳至内容
OpenAI CEO萨姆·奥特曼发帖预告的一系列更新如约而至。
今天,OpenAI研发小队直播宣布在API中正式推出GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano等新模型,称它们在编码、指令跟踪和长上下文方面进行了重大改进,变得更加专注于现实世界的实用性。
神奇的是,GPT-4.1比刚推出不久的GPT-4.5性能还要强,OpenAI官方同步表示,今天起将会在API中舍弃GPT-4.5预览版,API中的GPT-4.5预览版也将于三个月后(7月14日)关闭以便开发者有时间进行过渡。
不晓得奥特曼是否还能搞得清楚自家模型的版本号,反正这波“4.1>4.5”的操作,让网友们直接看懵了。
奥特曼自己也调侃道:“在今年夏天之前会确定新的模型命名规则,在此之前每个人都可以再花几个月的时间来取笑我们(这是我们应得的)。”
不过业内推测,奥特曼此番话可能也预示着大一统的GPT-5或许不远了。
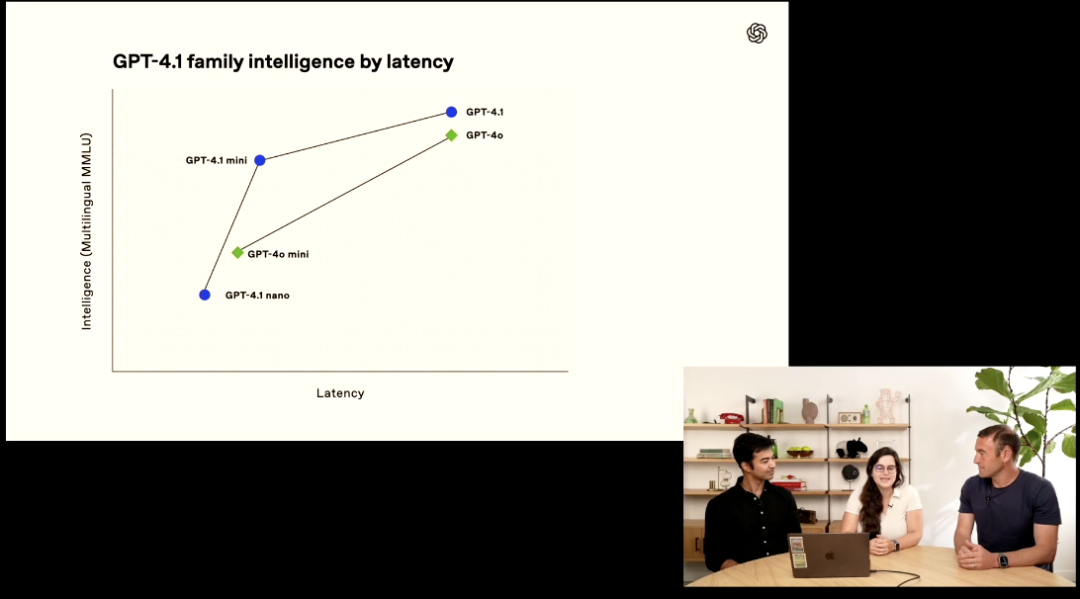
具体而言,三个新模型GPT-4.1、GPT-4.1 mini和GPT-4.1 nano的性能全面超越了GPT-4o和GPT-4o mini,在编码和指令跟踪方面均有显著提,不过,奥特曼表示GPT-4.1系列目前仅限API使用。
这些新模型拥有了更大的上下文窗口,最多支持达100万个上下文标记,追上了谷歌Gemini模型,能够更好地理解和利用上下文,知识截止日期更新到了2024年6月。
GPT-4.1系列其实是对GPT-4o系列的一次重大升级,适用于现实世界的软件工程工作,包括代理解决编码任务、前端编码、减少无关编辑、可靠地遵循差异格式、确保一致的工具使用等等。
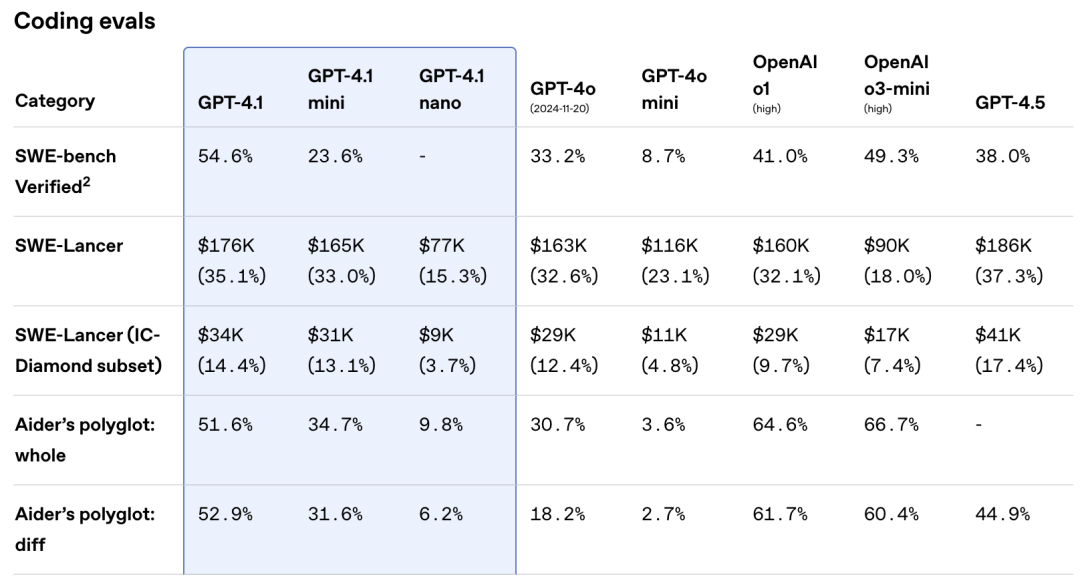
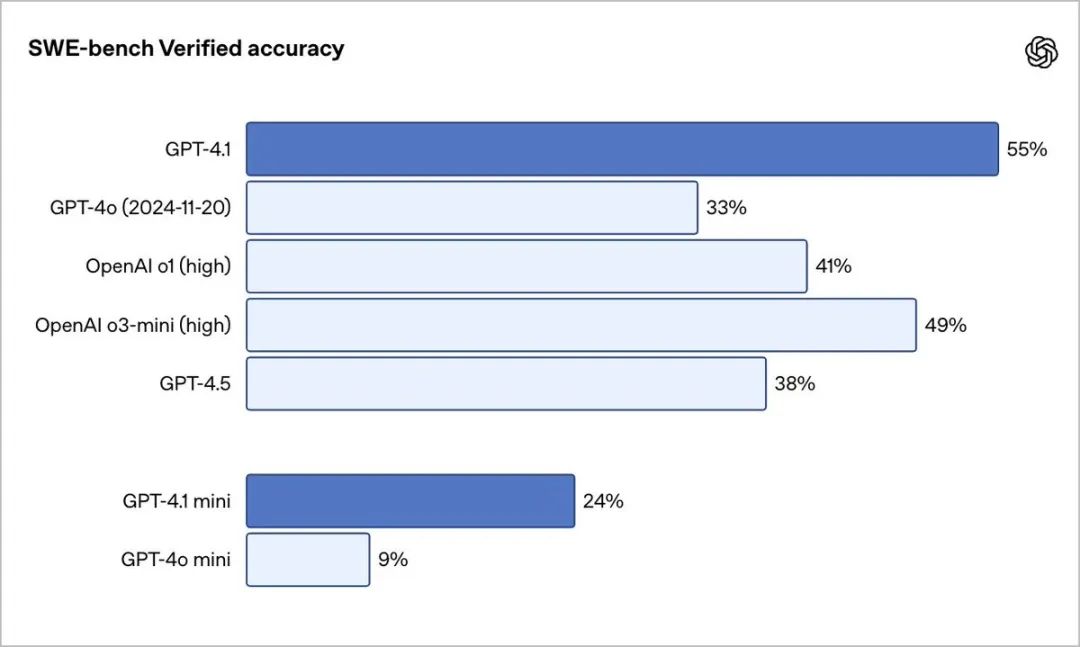
在衡量真实世界软件工程技能的SWE-bench Verified测试中,GPT-4.1完成了54.6%的任务,而GPT-4o的完成率为33.2%,GPT-4.5为38%,这反映了新模型在探索代码库、完成任务以及生成可运行并通过测试的代码方面的能力有所提升。
对于需要编辑大型文件的API开发者来说,GPT-4.1在跨多种格式的代码差异分析方面也更加可靠,在Aider的多语言差异基准测试中,GPT-4.1的得分是GPT-4o的两倍多,比GPT-4.5高出8%。
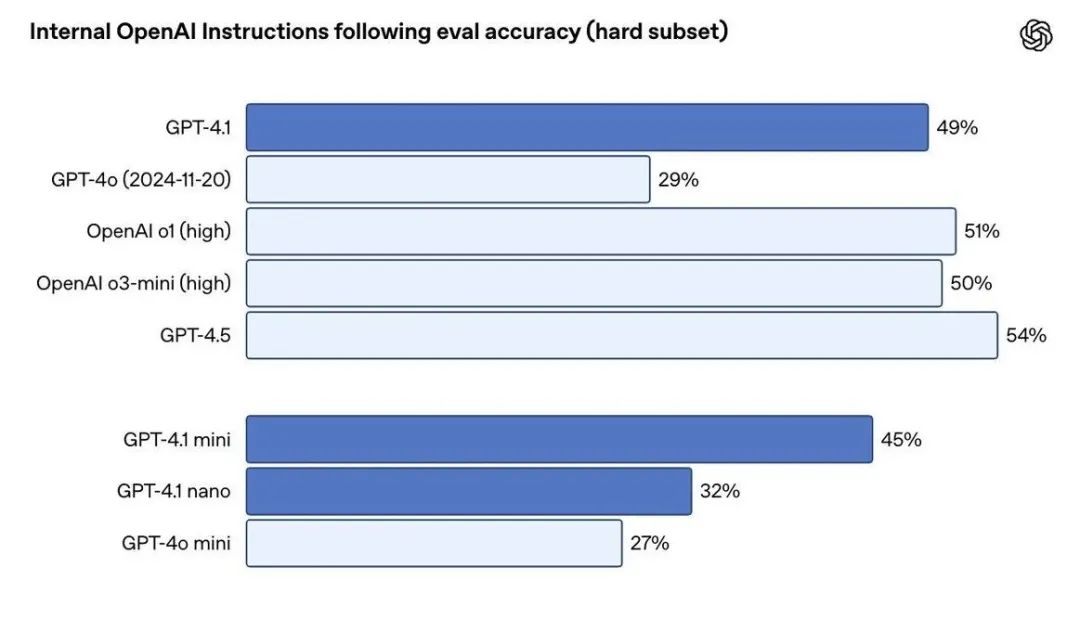
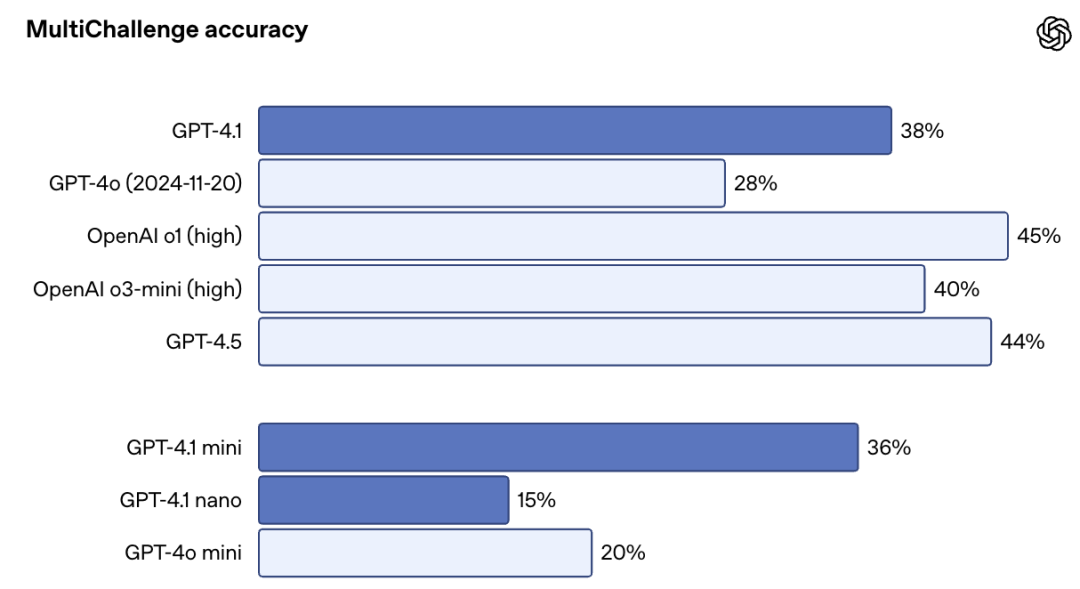
在内部评估中,GPT-4.1在格式遵循、服从负面指令和排序等任务上的得分均优于GPT-4o,多轮指令遵循对许多开发者来说至关重要,Scale的MultiChallenge基准测试是衡量这一能力的有效指标,GPT-4.1的表现比GPT-4o提高了10.5%。
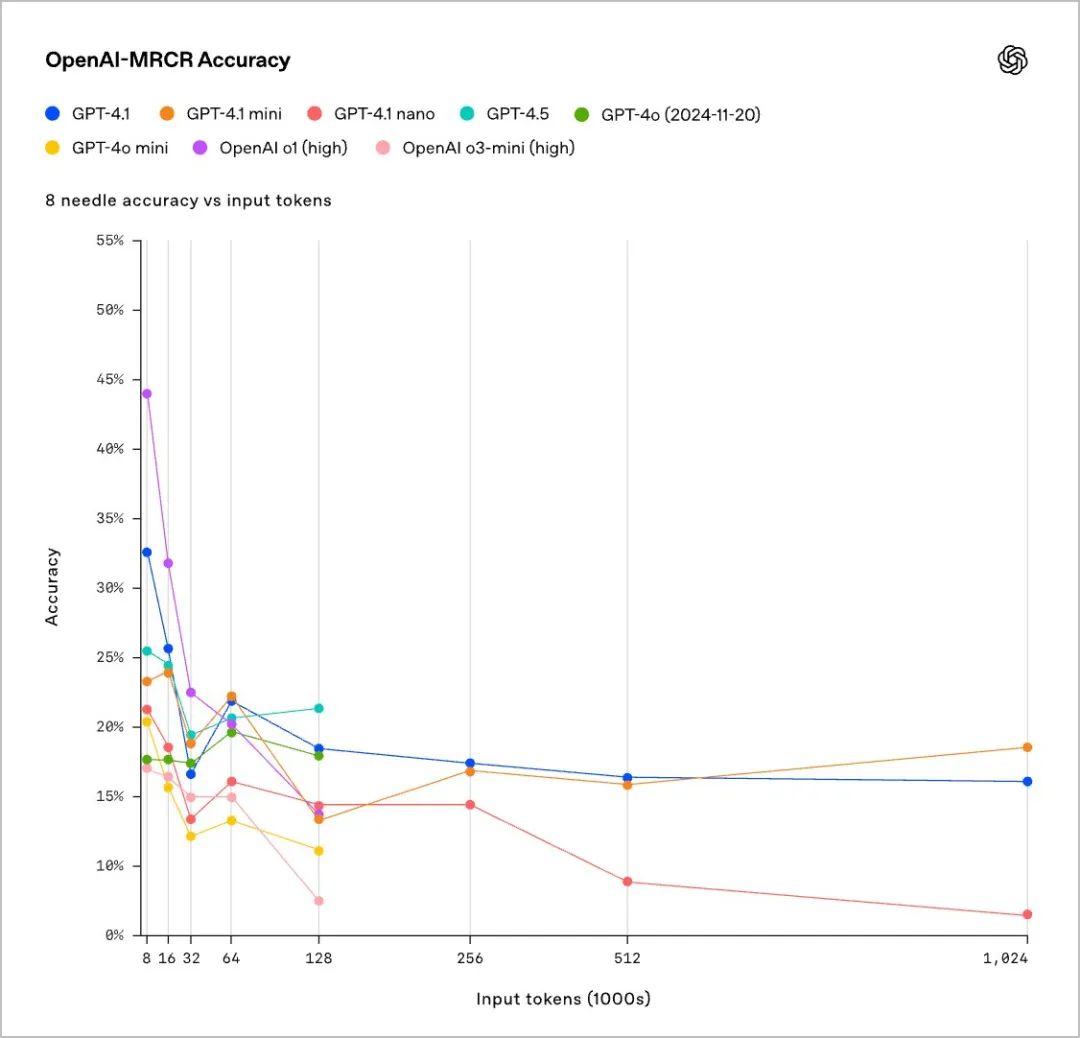
这三种新模型多达100万个上下文标记超过React代码库的8倍,因此它们可以处理大型存储库和大量长文档,而GPT-4o型号最多可以处理128000个,为了展示长上下文理解方面的进步,OpenAI还发布了OpenAI MRCR,这是一个新的开源评估基准,用于测试模型在上下文中关注特定信息的能力。
最后就是价格优势,GPT-4.1在曲线的每个点上都提升了模型性能,但比GPT-4o便宜约26%,4.1 nano版本是OpenAI迄今为止速度最快、成本最低的模型,而且,使用长上下文无需支付额外费用,只需支付正常的代币价格。
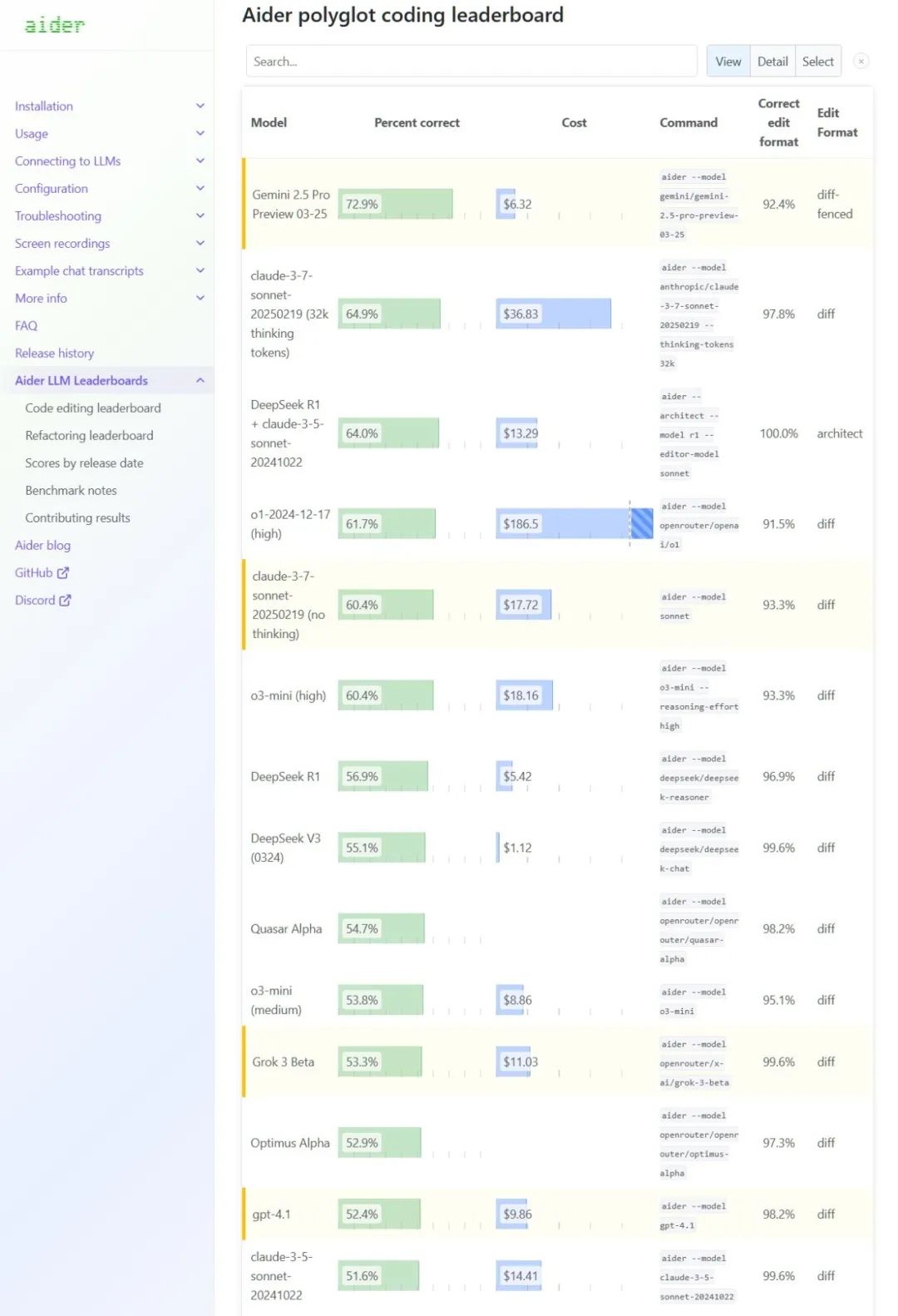
不过,GPT-4.1在Aider LLM排行榜上的位置这次并没有冲到前几名,Aider的多语言基准测试针对C++、Go、Java、JavaScript、Python和Rust等语言,通过225道具有挑战性的编码练习题来对大语言模型进行测试。
目前在Aider LLM排行榜上,谷歌的Gemini 2.5 Pro Preview排在第一名,GPT-4.1虽然有了一定的性价比和性能提升,但性能排名尚未超过Claude 3.7 sonnet、DeepSeek R1、DeepSeek V3-0324、Grok 3 Beta等其他公司的顶尖模型。
有意思的是,Aider榜上近日有两个新晋模型Quasar Alpha和Optimus Alpha表现在GPT-4.1之上,目前尚未有信息披露是谁家的新模型。
GPT-4.1虽然在OpenAI模型阵营中已算实力不弱的存在,但放眼现在的顶尖模型行列PK,似乎并没有机会掀起太大的颠覆性。
网友吐槽这是OpenAI首次在谷歌之后发布新模型,且性能落后于谷歌,怎么跟Gemini 2.5 Pro或Gemini 2.0 Flash对线竞争是个挑战,且性价比依旧不如开源之王DeepSeeK。
好在,GPT-4.1的实际表现不错,经住了各路网友们的测试挑战,甚至有些表现比Gemini 2.5 Pro处理得更好,实用性可圈可点。
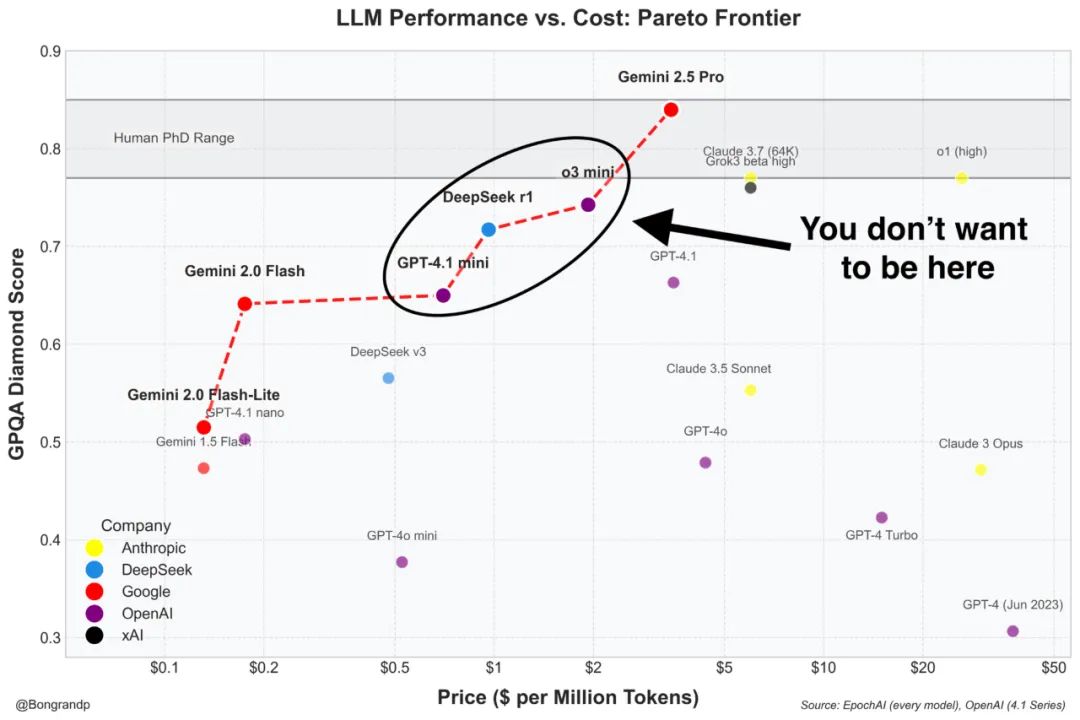
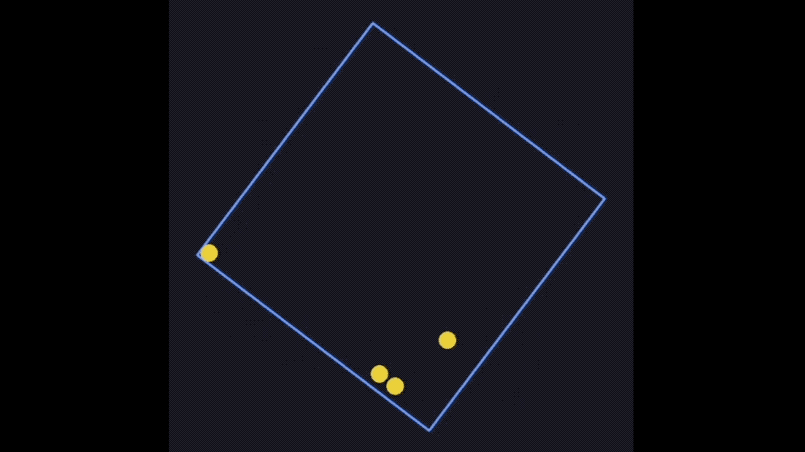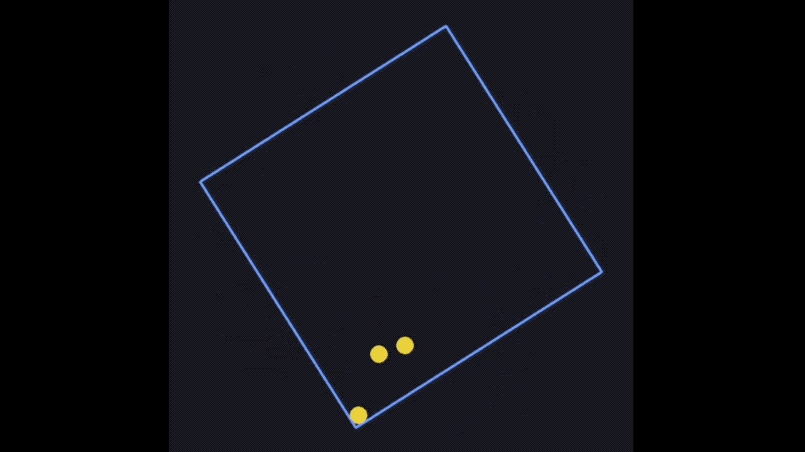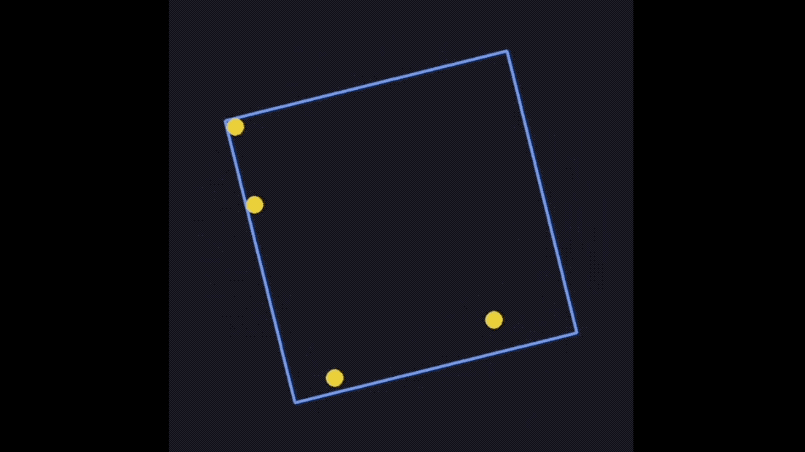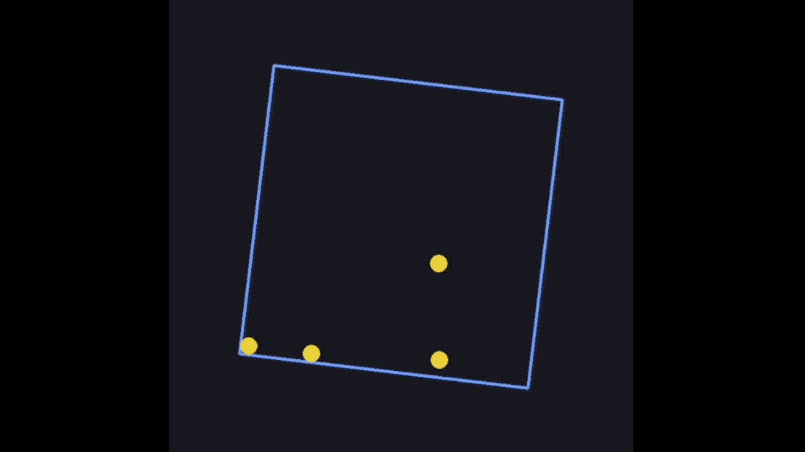
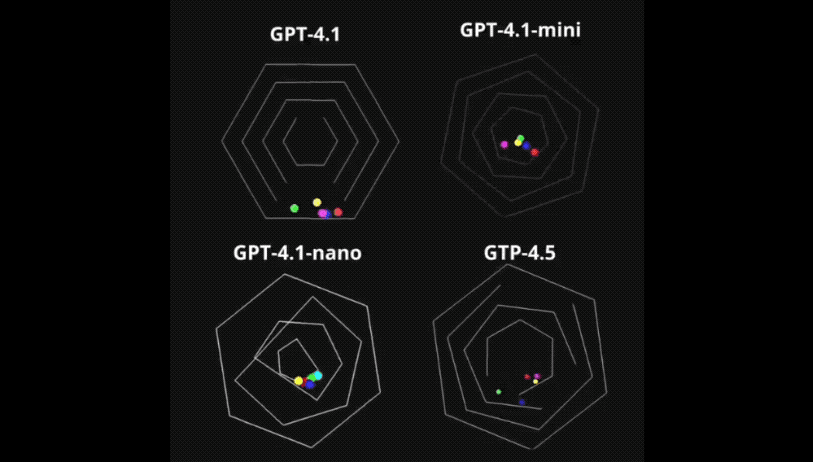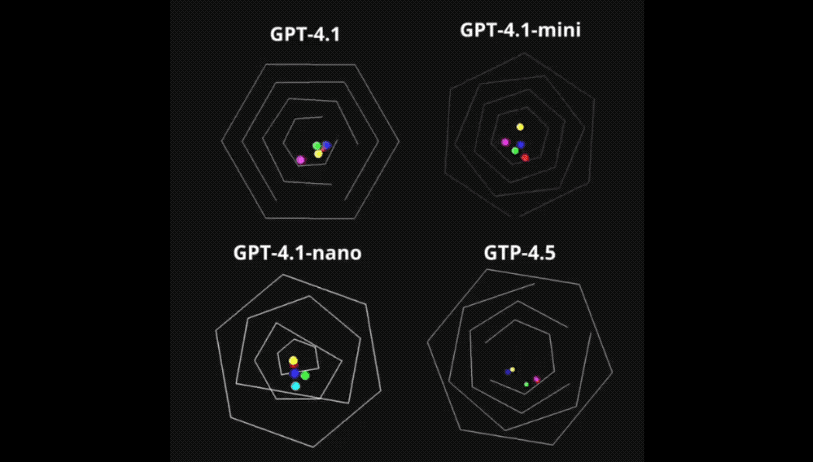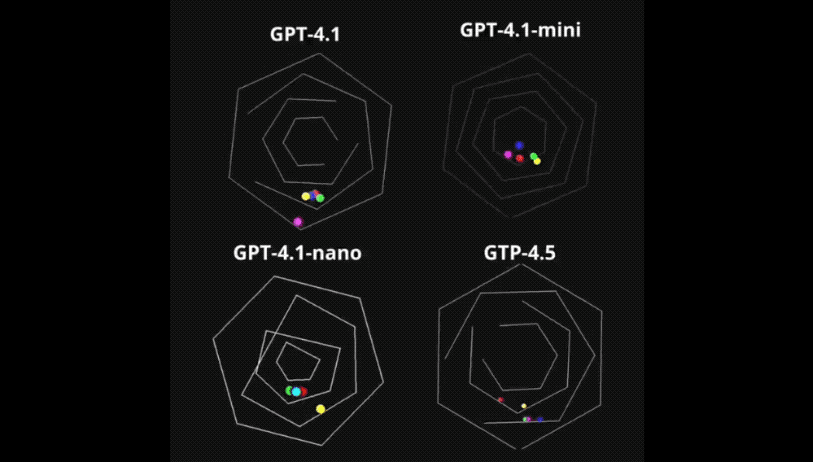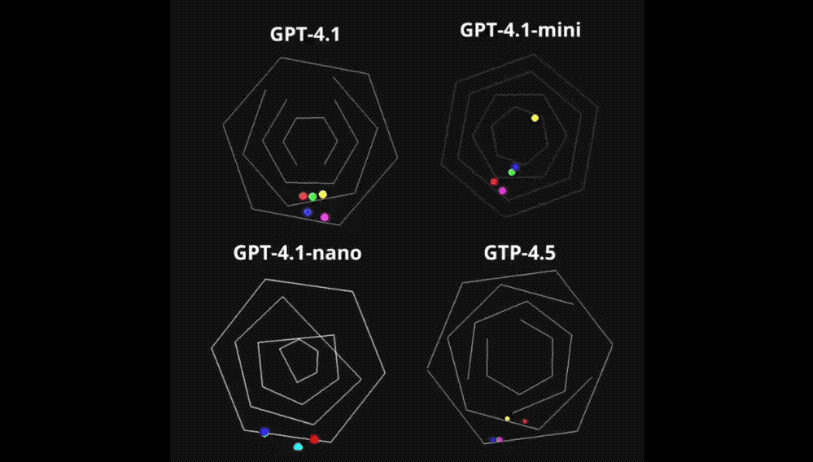
例如最常见的旋转框小球弹跳测试,输入提示词:使用Pygam(或其他合适的库)编写一个Python程序,模拟几个在围绕其中心旋转的正方形内受重力影响的弹跳球。这些球应该对于旋转正方形墙壁的碰撞做出反应,并通过速度变化、重力效应和旋转感知碰撞检测来保持物理真实感。
GPT-4.1轻松处理了旋转帧、重力和碰撞响应问题。
例如输入提示词模拟夜晚霓虹灯照亮的赛博朋克城市景观,带有动画灯光和雾,所有内容都在一个HTML文件中呈现,如下图所示,GPT 4.1(上)理解和生成的效果层次要比Gemini 2.5 Pro(下)更为细致。
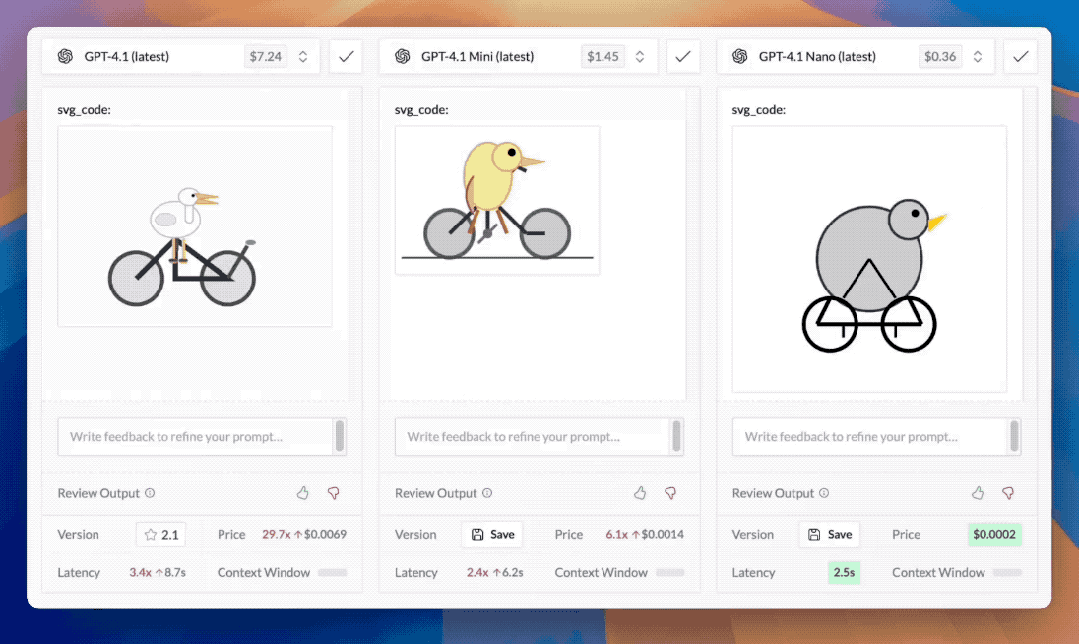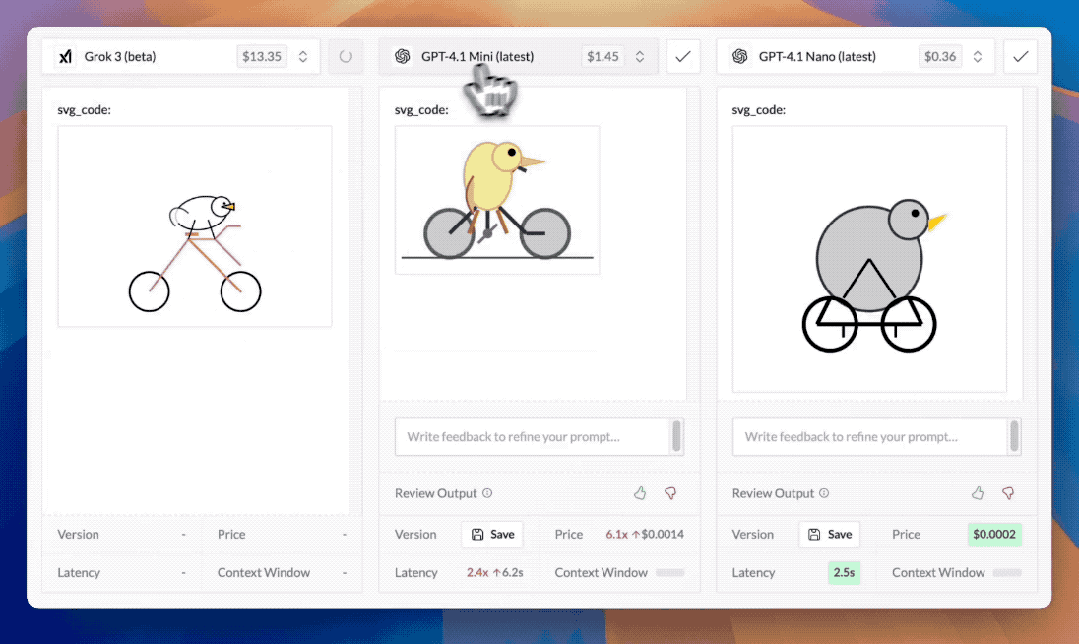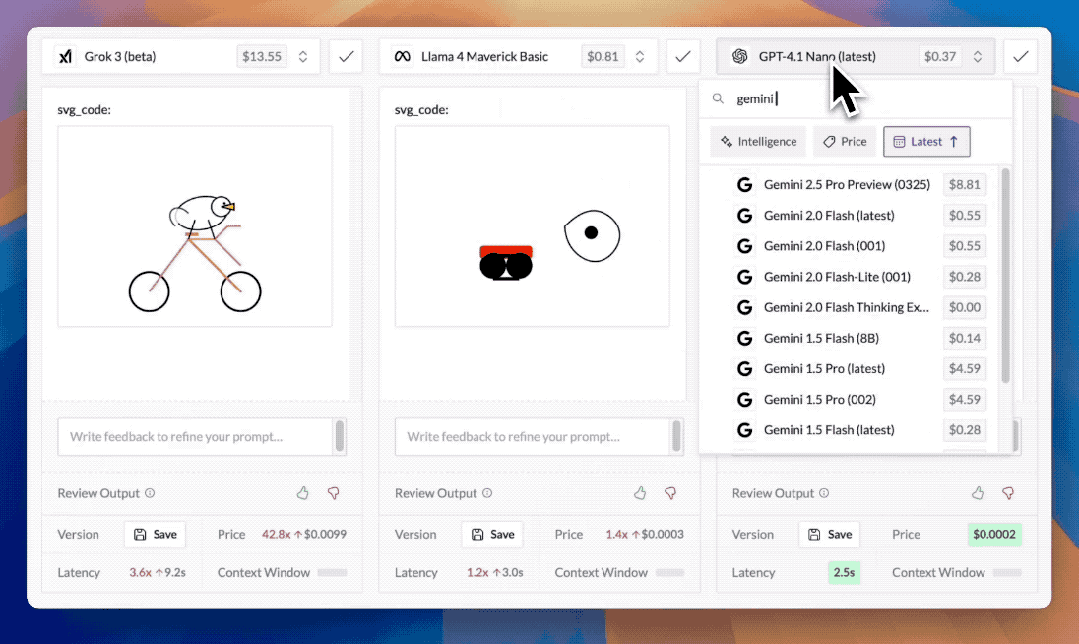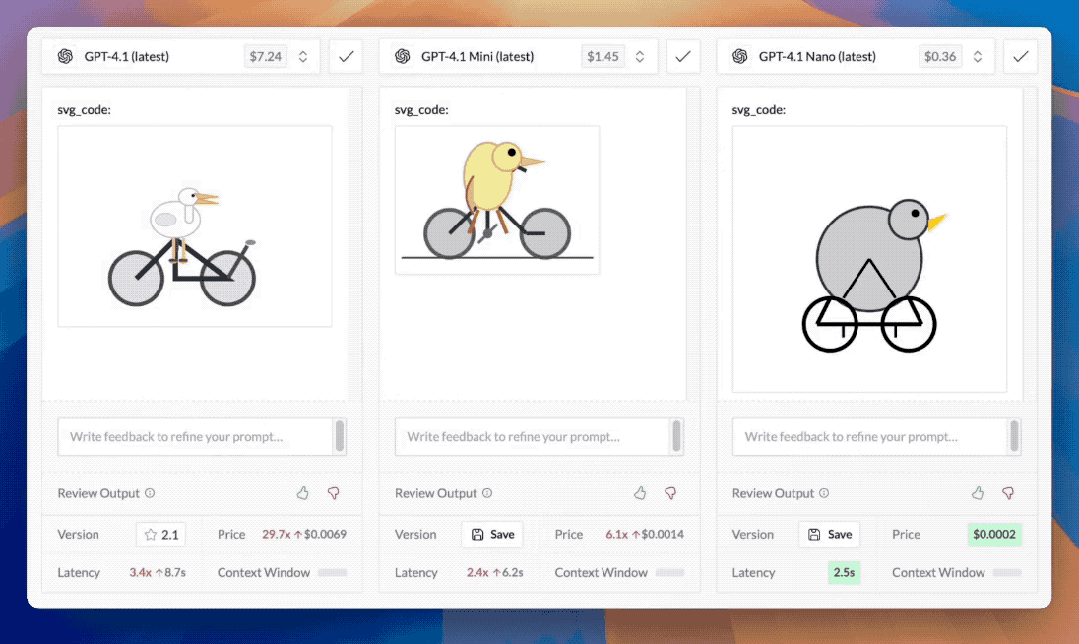
还有各家模型的噩梦svg_code绘图测试:请模型画一只骑自行车的鹈鹕,GPT-4.1的表现也很好,比Grok3、Gemini 2.5 Pro等模型生成的图样协调很多,而Meta发布的最新开源模型Llama 4在这样的测试中再次翻车。
从实测表现来看,GPT-4.1与GPT-4.5在编程领域和物理知识处理方面都非常出色,但GPT-4.1 mini和GPT-4.1 nano的表现是拉垮的,可能难以满足开发者们的高级使用需求,不过性价比在GPT阵营中靠前。
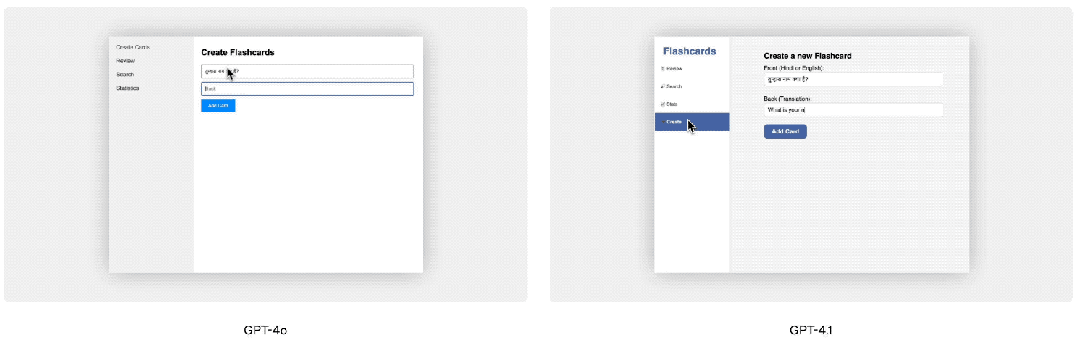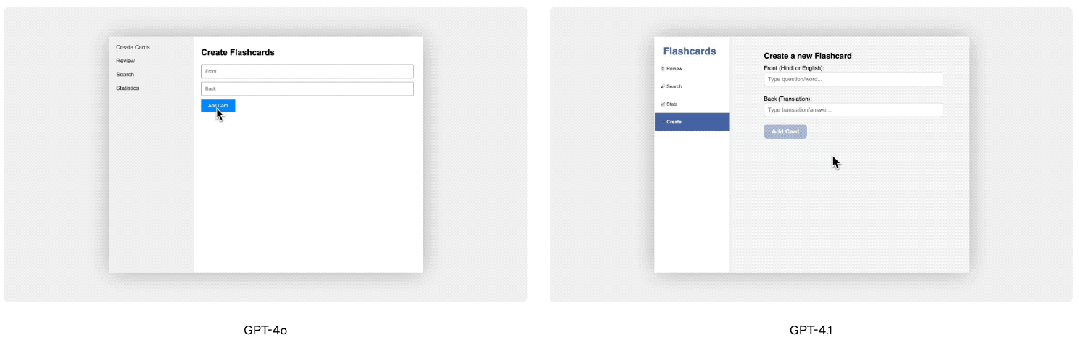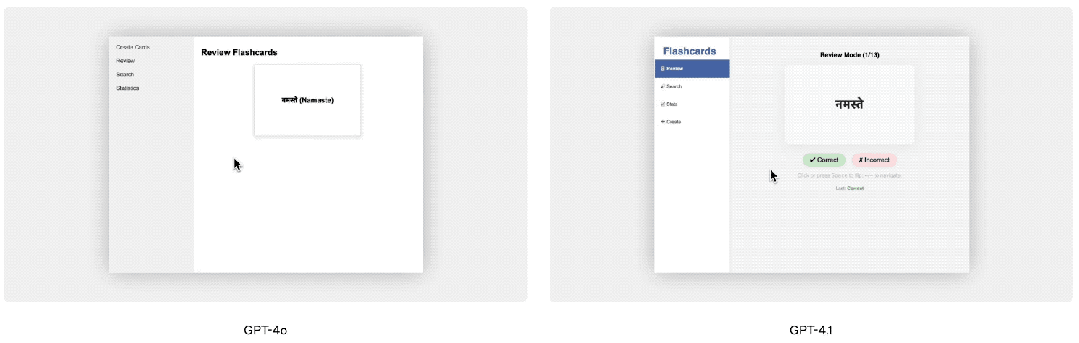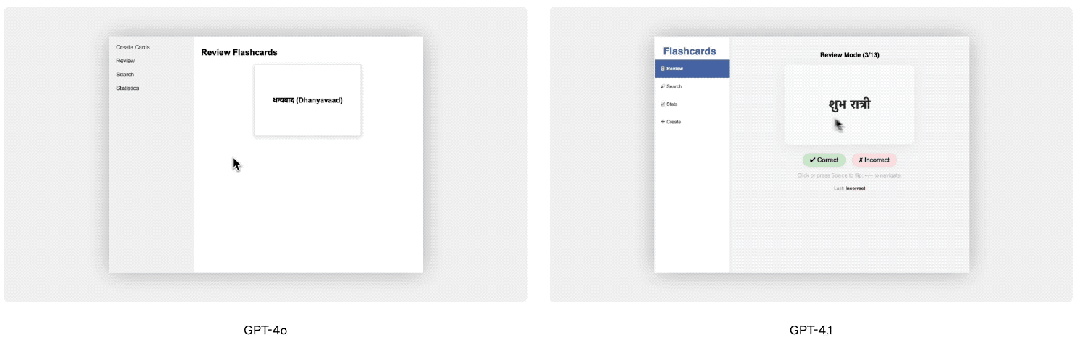
另外,GPT-4.1在前端编码方面比GPT-4o有了显著提升,能够创建功能更强大、更美观的Web应用,付费人工评分员80%的评分结果显示,GPT-4.1开发的网页效果比GPT-4o的呈现效果更受欢迎。
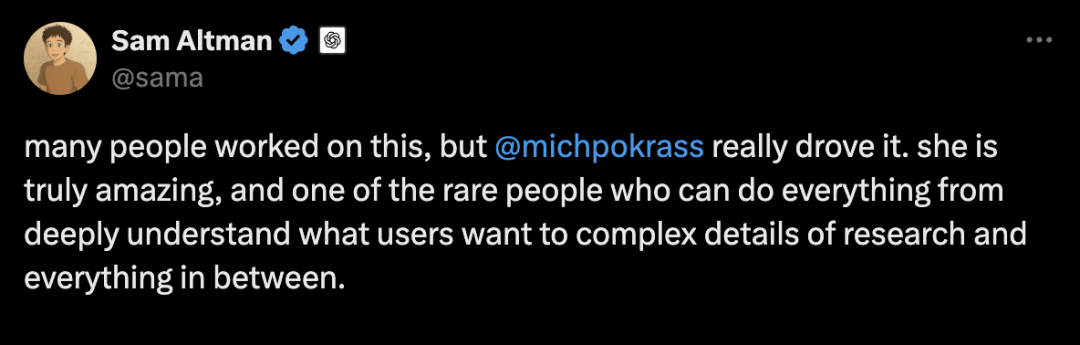
正如奥特曼点名@表扬的GPT-4.1幕后推动者Michelle Pokrass发帖所说,GPT-4.1系列模型实际上更多地关注现实世界的使用和实用性,而不是基准测试(尽管这些基准测试结果也相当不错)。
至于为什么GPT-4.1系列仅在API中推出,OpenAI方面暂未有太多解释。
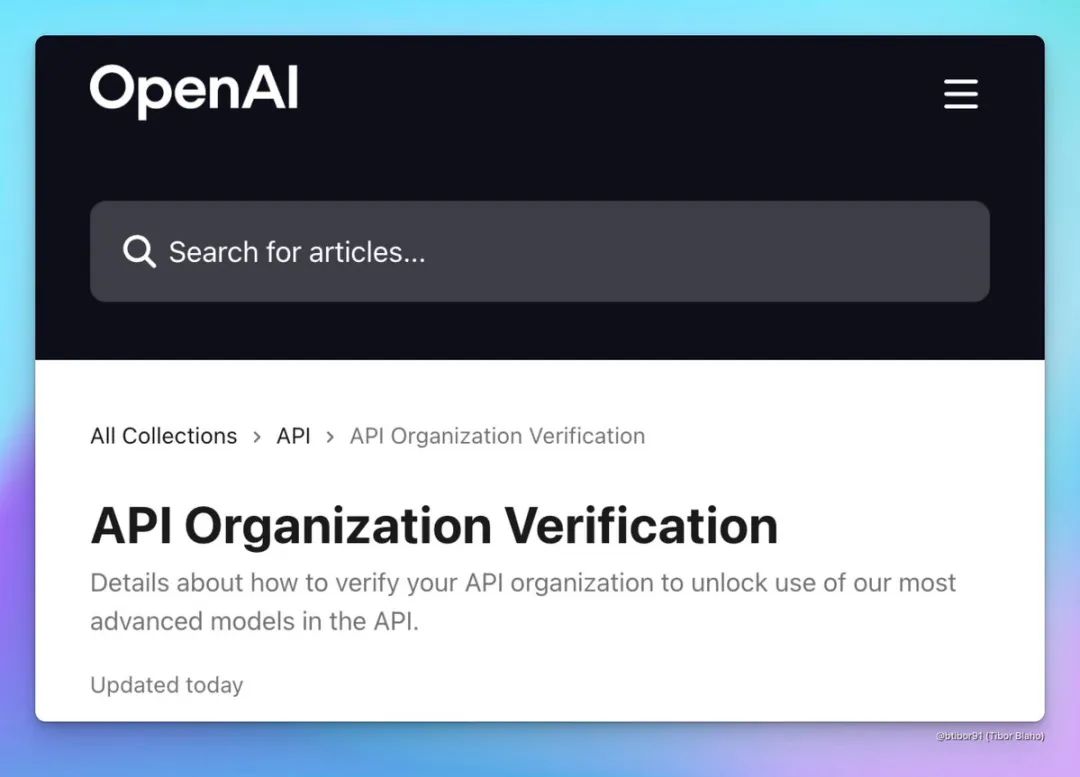
不过,OpenAI最近正在严格化对其最新模型的使用情况,日前,该公司网站上更新的页面显示,OpenAI可能很快会要求组织完成身份验证过程才能访问某些未来的AI模型。
验证需要提供OpenAI API支持的国家/地区政府签发的身份证件信息,OpenAI表示,一个身份证件每90天只能验证一个组织。
业内分析认为,随着OpenAI产品变得越来越复杂和强大,新的验证流程或旨在增强其产品的安全防护壁垒,检测和减少其模型被恶意使用,也为了防止知识产权被违规利用。
今年早些时候,OpenAI曾调查与DeepSeek有关联的组织是否在2024年底通过其API窃取了大量数据用于训练开源模型,这违反了OpenAI的使用条款,最终没有实质发现和结论。
作为OpenAI最大的开源竞争对手,DeepSeek正在低调酝酿大动作。
根据其开发团队在Github上更新的一篇帖子显示,DeepSeek团队宣布将进一步把内部推理引擎回馈给开源社区,其训练框架依赖于PyTorch,推理引擎则基于vLLM,这两者都对加速DeepSeek模型的训练和部署起到了重要作用。
另外,DeepSeek团队在4月初与清华大学合作的一篇论文中探讨了通用奖励建模在推理时的可扩展性,并提出了DeepSeek-GRM模型,被外界视为可能是在为R2模型的推出做技术准备和铺垫。
下一步能再次搅动AI行业发展走向的因素,可能就是开源R2和GPT-5的正面交锋了。
(文:头部科技)