

推理模型的现状与挑战
大型推理模型通过大规模的强化学习,能够进行长步骤的逐步推理,适用于科学、数学、编码等复杂领域。这种“慢思考”模式不仅增强了推理的逻辑连贯性和可解释性,但也带来了一个显著的问题:知识不足。在推理过程中,模型可能会遇到无法确定的知识点,导致整个推理链条的错误传播,影响最终的答案质量。
研究动机
在初步实验中,本文发现,类似OpenAI-o1的推理模型在处理复杂问题时,平均每个推理过程中会出现超过30次的不确定词汇,如“或许”、“可能”等。这不仅增加了推理的复杂性,还使得手动验证推理过程变得更加困难。因此,如何在推理过程中自动补充所需知识,成为提升大型推理模型可信度的关键。

Search-o1:自主知识检索增强的推理框架
为了解决上述问题,本文提出了Search-o1框架。该框架通过集成自主检索增强生成(Agentic Retrieval-Augmented Generation)机制和文档内推理模块(Reason-in-Documents),实现了在推理过程中动态获取和整合外部知识的能力。
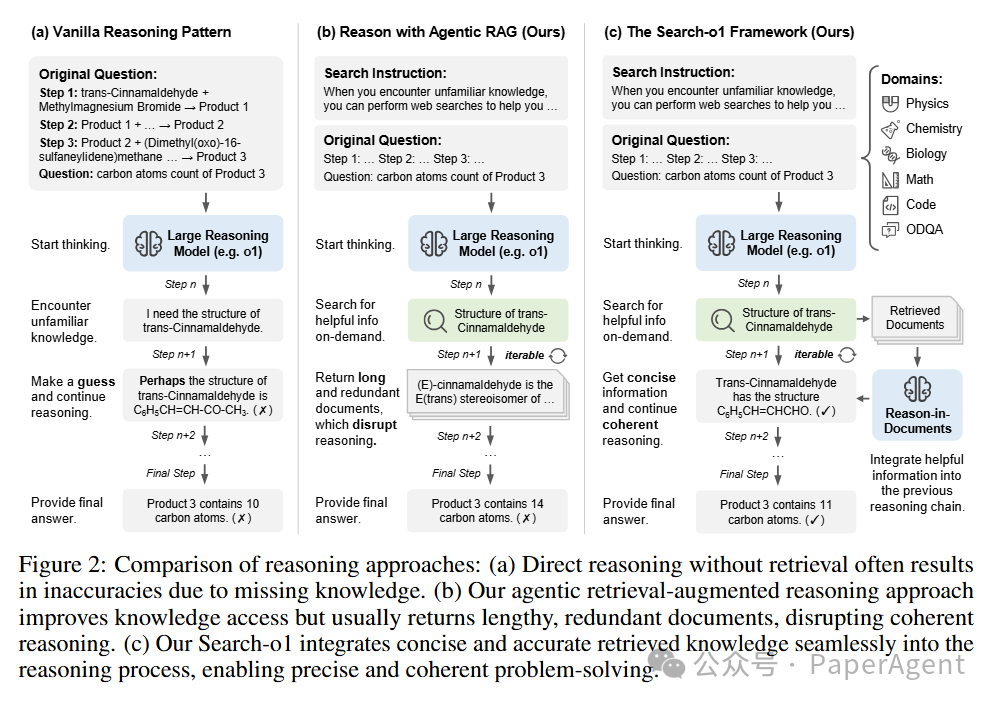
核心组件
1.自主检索增强生成机制:Search-o1 使模型能够在推理过程中自主决定何时检索外部知识。当模型在推理中遇到不确定的知识点时,会自动生成检索查询,获取相关的外部文档。这种动态检索方式相比传统的静态检索,更加灵活和高效。
2.文档内推理模块:为了避免直接插入冗长且可能含有噪音的检索文档,Search-o1 引入了知识精炼模块。该模块能够对检索到的文档进行筛选和精炼,提取出与当前推理步骤高度相关的关键信息,确保推理过程的连贯性和逻辑一致性。
推理过程
在Search-o1的推理过程中,模型会在生成推理链条的过程中,自动检测是否需要检索外部知识。当需要时,模型会生成特定的检索查询,获取相关文档,并通过文档内推理模块精炼这些文档,将精炼后的知识无缝整合到推理链条中。这一过程能够反复进行,确保模型在整个推理过程中都能获得所需的外部知识支持。

实验结果
为了验证Search-o1的有效性,本文在多个复杂推理任务和开放域问答基准上进行了广泛的实验。以下是主要的实验结果:
复杂推理任务
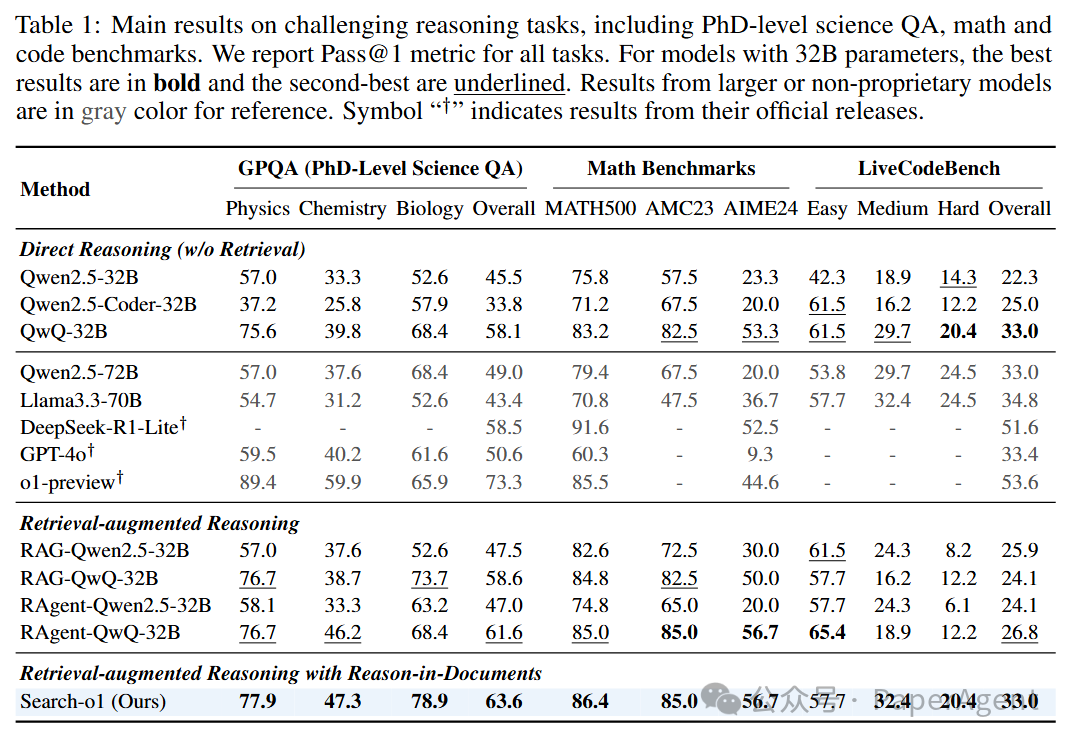
在复杂推理任务中,包括PhD级别的科学问答(GPQA)、数学(MATH500、AMC2023、AIME2024)和编码能力(LiveCodeBench),Search-o1均显著优于传统的直接推理方法和标准RAG方法。
-
大型推理模型的优势:即使在没有检索增强的情况下,QwQ-32B-Preview模型在多个任务上也表现优异,甚至超过了一些更大规模的模型,如Qwen2.5-72B和Llama3.3-70B。这展示了大型推理模型在推理任务中的强大能力。
-
自主检索增强的效果:使用自主RAG机制的RAgent-QwQ-32B在大多数任务上超越了标准RAG和直接推理的QwQ-32B,表明自主检索能够有效提升推理模型的知识获取能力。
-
Search-o1的卓越表现:进一步引入文档内推理模块后的Search-o1,在大多数任务上超越了RAgent-QwQ-32B,尤其在GPQA、数学和编码任务上取得了显著的性能提升。
检索文档数量的影响
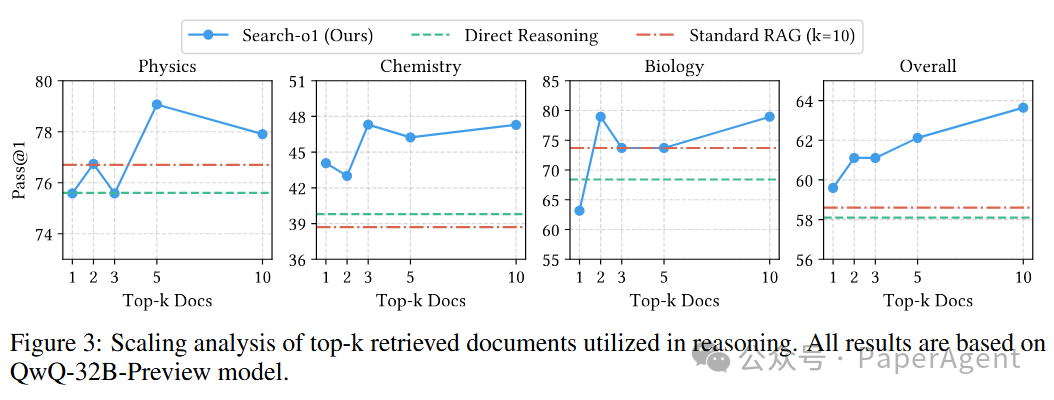
研究发现,Search-o1能够有效利用增加的检索文档数量,进一步提升复杂推理任务的处理能力。即使只检索一篇文档,Search-o1也能够超过直接推理和标准RAG模型,显示出自主检索和文档精炼策略的高效性。
开放域问答任务
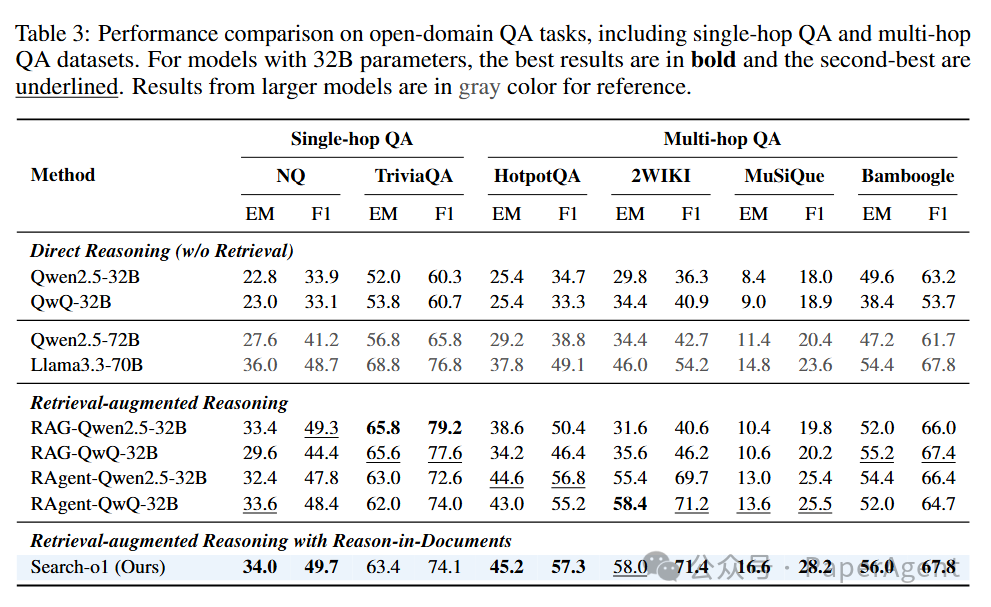
在开放域问答任务中,尤其是多跳问答任务,Search-o1表现尤为突出,平均准确率提升了近30%,充分展示了其在知识密集型任务中的优势。而在单跳任务中,虽然提升不显著,但这也表明多跳任务更需要动态知识检索的支持。
结语:迈向更可信赖的智能系统
Search-o1 不仅提升了大型推理模型在复杂任务中的表现,更为智能系统的可靠性和适用性奠定了坚实的基础。通过自主知识检索和精炼整合,Search-o1有效解决了知识不足的问题,显著增强了推理模型的可信度和实用性。未来,随着这一框架的进一步优化和推广,我们可以赋予类o1的推理模型更多的工具,而不仅局限于Search这一个工具,在更多复杂问题的解决中展现出更强大的能力。
(文:PaperAgent)